Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configurazione di un target per un'integrazione zero-ETL
Esistono diverse opzioni offerte AWS Glue durante la configurazione di un target per un'integrazione zero-ETL. L'obiettivo può essere un Amazon Redshift data warehouse crittografato o un'architettura Lakehouse di Amazon. SageMaker
Prima di selezionare la destinazione per l'integrazione Zero-ETL, è necessario configurare una delle seguenti risorse di destinazione. Le opzioni di configurazione per una destinazione in un'integrazione Zero-ETL includono:
Un bucket Amazon S3 per uso generico che utilizza l'architettura Lakehouse di Amazon. SageMaker Per informazioni, consulta Configurazione di un target bucket S3 per uso generico.
Un bucket Amazon S3 Tables che utilizza l'architettura Lakehouse di Amazon. SageMaker Per informazioni, consulta Configurazione di un target del bucket Amazon S3 Tables.
Uno storage Amazon Redshift gestito che utilizza l'architettura Lakehouse di Amazon. SageMaker Per informazioni, consulta Configurazione di un target di storage gestito Amazon Redshift.
Un Amazon Redshift data warehouse identificato da un namespace Redshift. Per informazioni, consulta Configurazione di un obiettivo di data warehouse Amazon Redshift.
Nota
Non è possibile modificare la destinazione di un'integrazione Zero-ETL dopo la creazione.
Configurazione di un target bucket S3 per uso generico
Questa sezione descrive i prerequisiti e i passaggi di configurazione per configurare un bucket S3 generico come storage per il tuo target in un'integrazione zero-ETL, utilizzando l'architettura Lakehouse di Amazon. SageMaker
Prima di creare un'integrazione zero-ETL con l'architettura Lakehouse di SageMaker Amazon utilizzando lo storage S3 generico, devi completare le seguenti attività di configurazione:
Configura un AWS Glue database
Fornire la policy RBAC del catalogo
Creare un ruolo IAM
Associa il ruolo di destinazione, KMS (opzionale) e la connessione (opzionale) alla risorsa di destinazione
(Facoltativo) Configura le proprietà della tabella di destinazione
Configurazione di un AWS Glue database
Per configurare un database di destinazione nel Data Catalog con una posizione del bucket per uso generico Amazon S3:
Nella home page della AWS Glue console, seleziona Database in Data Catalog.
Scegliere Aggiungi database in alto a destra. Se è stato già creato un database, assicurarsi che sia impostata la posizione con l'URI di Amazon S3 per il database.
Inserire un nome e una Posizione (URI Amazon S3). Si prega di notare che la posizione è necessaria per l'integrazione Zero-ETL. Al termine, fare clic su Crea database.
Nota
Il bucket Amazon S3 per uso generico deve trovarsi nella stessa regione del database. AWS Glue
Per informazioni sulla creazione di un nuovo database in AWS Glue, consulta Guida introduttiva al Data Catalog.
È possibile anche usare la CLI create-database per creare il database in AWS Glue. Tenere presente che LocationUri in --database-input è obbligatorio.
Ottimizzazione delle tabelle Iceberg
Una volta creata una tabella AWS Glue nel database di destinazione, puoi abilitare la compattazione per velocizzare le query in Amazon Athena. Per informazioni sulla configurazione delle risorse (Ruolo IAM) per la compattazione, consultare Prerequisiti per l'ottimizzazione delle tabelle.
Fornire una policy RBAC (Resource Based Access) per il catalogo
Per le integrazioni che utilizzano un AWS Glue database, aggiungi le seguenti autorizzazioni alla politica RBAC del catalogo per consentire le integrazioni tra origine e destinazione.
Nota
Per le integrazioni tra account, sia l'utente che crea la politica dei ruoli di integrazione che la politica delle risorse del catalogo devono consentire l'accesso alla risorsa. glue:CreateInboundIntegration Per lo stesso account è sufficiente una policy in materia di risorse o una policy di ruolo che consenta a glue:CreateInboundIntegration l'utilizzo della risorsa. Entrambi gli scenari devono comunque consentire a glue.amazonaws.com per glue:AuthorizeInboundIntegration.
È possibile accedere alle Impostazioni del catalogo in Data Catalog. Fornire quindi le seguenti autorizzazioni e inserire le informazioni mancanti.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Creazione di un ruolo IAM di destinazione
Creare un ruolo IAM con le seguenti autorizzazioni e relazioni di fiducia:
{ "Version": "2012-10-17", "Statement": [ { "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::amzn-s3-bucket", "Effect": "Allow" }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/*", "Effect": "Allow" }, { "Action": [ "glue:GetDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Effect": "Allow" }, { "Action": [ "glue:CreateTable", "glue:GetTable", "glue:GetTables", "glue:DeleteTable", "glue:UpdateTable", "glue:GetTableVersion", "glue:GetTableVersions", "glue:GetResourcePolicy" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name", "arn:aws:glue:us-east-1:111122223333:table/database-name/*" ], "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Aggiungi la seguente politica di attendibilità per consentire al AWS Glue servizio di assumere il ruolo:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Associa il ruolo di destinazione, KMS (opzionale) e Connection (opzionale) alla risorsa di destinazione
Associa il ruolo di destinazione sopra riportato alla risorsa di destinazione, ad esempio il AWS Glue database. Facoltativamente, per il database di destinazione è possibile configurare KMS per crittografare i dati prima dell'archiviazione nella tabella iceberg di destinazione e Connection ARN per accedere al bucket S3. AWS Glue Ciò consentirà di accedere AWS Glue ai dati sulla posizione S3 di destinazione utilizzando il ruolo fornito e, facoltativamente, di crittografarli utilizzando la chiave KMS fornita. Se il bucket S3 di destinazione è configurato per essere accessibile utilizzando un determinato VPC, è possibile associare l'ARN di connessione per consentire l'esecuzione dell'elaborazione AWS Glue all'interno di quel VPC. Per ulteriori informazioni sulla configurazione di un VPC, consulta Creare un VPC.
Oppure utilizzando la AWS Glue CLI/API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --target-processing-properties '{"RoleArn": "arn:aws:iam::123456789012:role/gmi_target_role"}' \ --region us-east-1
(Facoltativo) Configura le proprietà della tabella di destinazione
Facoltativamente, è possibile configurare le proprietà della tabella di destinazione per le tabelle di destinazione che verranno sincronizzate con la destinazione.
Puoi configurare queste impostazioni nella sezione Impostazioni di output del flusso di lavoro per la creazione dell'integrazione nella AWS Glue console:

Quando si seleziona Specificare chiavi di partizione personalizzate, è possibile configurare le chiavi di partizione e le relative specifiche di funzione e conversione:

Se l'origine e la destinazione si trovano nello stesso account, questa configurazione può essere eseguita come parte del flusso di lavoro di creazione dell'integrazione dall'interfaccia utente della console. AWS Glue Ma se la destinazione si trova in un account diverso, è necessario completare questa configurazione prima di creare l'integrazione. Quando si utilizza la CLI o l'API, è necessario eseguire questa operazione prima di richiamare l'API Create-Integration anche quando sia l'origine che la destinazione si trovano nello stesso account. AWS Glue l'interfaccia utente della console incapsula semplicemente questa chiamata API per lo stesso scenario di account.
Se non è configurato, verranno utilizzati i valori predefiniti durante la sincronizzazione della tabella. Questa configurazione può anche essere modificata in qualsiasi momento dopo la creazione dell'integrazione.
Nota
Se questa proprietà viene aggiornata dopo la creazione dell'integrazione, potrebbe attivare una risincronizzazione completa della tabella quando la configurazione aggiornata è in conflitto con la configurazione esistente. Ad esempio, aggiornando la tabella «un-nesting» da 'No-Unnest' a 'Full-Unnest' o cambiando la colonna della partizione.
Utilizzo della CLI o dell'API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --table-nametable-name\ --target-table-config '{ "UnnestSpec":"TOPLEVEL"|"FULL"|"NOUNNEST", "PartitionSpec": [ { "FieldName":"string", "FunctionSpec":"string", "ConversionSpec":"string"} ... ], "TargetTableName":"string" }' \ --region us-east-1
Dopo aver configurato l'architettura Lakehouse di Amazon SageMaker con lo storage bucket Amazon S3 per uso generico, puoi procedere con il completamento della configurazione dell'integrazione. Configurazione dell'integrazione con la destinazione
Configurazione di un target del bucket Amazon S3 Tables
Questa sezione descrive i prerequisiti e i passaggi di configurazione per configurare Amazon S3 Tables come destinazione per l'integrazione zero-ETL, utilizzando l'architettura lakehouse di Amazon. SageMaker
Prima di creare un'integrazione Zero-ETL con Tabelle Amazon S3 come destinazione, è necessario completare le seguenti attività di configurazione:
Configurazione del bucket di tabelle Amazon S3 (e integrazione dei servizi di analisi)
Fornire la policy RBAC del catalogo
Creare un ruolo IAM
Associa il ruolo di destinazione, KMS (opzionale) e la connessione (opzionale) alla risorsa di destinazione
(Facoltativo) Configura le proprietà della tabella di destinazione
Configurazione del bucket di tabelle Amazon S3 (con integrazione dei servizi di analisi)
Creare un bucket Tabelle S3 nel proprio account seguendo le istruzioni in Nozioni di base su Tabelle Amazon S3.
Abilita le integrazioni di Analytics con il tuo bucket S3-Table seguendo queste istruzioni: Integrazione dei servizi con AWS Amazon S3 Tables.
Questo creerà un nuovo catalogo S3-Table in. AWS Lake Formation
Fornire la policy RBAC del catalogo
È necessario aggiungere le seguenti autorizzazioni alla Policy RBAC del catalogo per consentire le integrazioni tra l'origine e la destinazione del catalogo Tabelle Amazon S3.
La politica delle risorse di Target AWS Glue Catalog deve includere le autorizzazioni AWS Glue di servizio per. AuthorizeInboundIntegration Inoltre, è richiesta l'CreateInboundIntegrationautorizzazione sul principale di origine che crea l'integrazione o nella politica AWS Glue delle risorse di destinazione.
Nota
In uno scenario con più account, sia la politica delle risorse principale di origine che quella delle risorse AWS Glue del catalogo di destinazione devono includere glue:CreateInboundIntegration le autorizzazioni sulla risorsa.
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
Nota
Sostituiscila s3tablescatalogs3tablescatalog
Creare un ruolo IAM
Creare un ruolo IAM con le seguenti autorizzazioni e relazioni di fiducia:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3tables:ListTableBuckets", "s3tables:GetTableBucket", "s3tables:GetTableBucketEncryption", "s3tables:GetNamespace", "s3tables:CreateNamespace", "s3tables:ListNamespaces", "s3tables:CreateTable", "s3tables:DeleteTable", "s3tables:GetTable", "s3tables:GetTableEncryption", "s3tables:ListTables", "s3tables:GetTableMetadataLocation", "s3tables:UpdateTableMetadataLocation", "s3tables:GetTableData", "s3tables:PutTableData" ], "Resource": "arn:aws:s3tables:us-east-1:111122223333:bucket/s3-table-bucket", "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
Aggiungi la seguente policy di fiducia nel ruolo IAM di destinazione per consentire a AWS Glue Service di assumerla:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Nota
Assicurarsi che non sia presente un'istruzione DENY esplicita per questo ruolo IAM di destinazione nella policy delle risorse del bucket S3-Tables. Un DENY esplicito sovrascriverebbe qualsiasi autorizzazione ALLOW e impedirebbe il corretto funzionamento dell'integrazione.
Associa il ruolo di destinazione, KMS (opzionale) e Connection (opzionale) alla risorsa di destinazione
Associa il ruolo target di cui sopra alla risorsa di destinazione. Facoltativamente, è possibile configurare KMS per crittografare i dati prima dell'archiviazione nella tabella iceberg di destinazione e Connection ARN per accedere al bucket S3 di destinazione. Se il bucket S3 di destinazione è configurato per essere accessibile utilizzando un determinato VPC, è possibile associare l'ARN di connessione per consentire l'esecuzione dell'elaborazione AWS Glue all'interno di quel VPC. Per ulteriori informazioni sulla configurazione di un VPC, consulta Creare un VPC.
Utilizzo della AWS Glue CLI/API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --target-processing-properties '{ "RoleArn": "arn:aws:iam::123456789012:role/target_role" }' \ --region us-east-1
(Facoltativo) Configura le proprietà della tabella di destinazione
Facoltativamente, è possibile configurare le proprietà della tabella di destinazione per le tabelle di destinazione che verranno sincronizzate con la destinazione. Si applicano le stesse regole descritte nella sezione sugli obiettivi S3 per uso generico.
Utilizzo della CLI o dell'API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --table-nametable-name\ --target-table-config '' \ --region us-east-1
Dopo aver configurato lo storage Amazon S3-Tables utilizzando l'architettura Lakehouse di SageMaker Amazon, puoi procedere Configurazione dell'integrazione con la destinazione al completamento della configurazione dell'integrazione.
Configurazione di un target di storage gestito Amazon Redshift
Questa sezione descrive i prerequisiti e i passaggi di configurazione per configurare uno storage Amazon Redshift gestito (RMS) come destinazione per l'integrazione zero-ETL, utilizzando l'architettura lakehouse di Amazon. SageMaker
Prima di creare un'integrazione zero-ETL con un'architettura Lakehouse di Amazon SageMaker utilizzando lo storage gestito Redshift, devi completare le seguenti attività di configurazione:
Configura un cluster o un gruppo di lavoro Serverless Amazon Redshift
Registra l' Amazon Redshift integrazione con Lake Formation
Creazione di un catalogo gestito in Lake Formation
Configurazione delle autorizzazioni IAM
Configurazione dello storage Amazon Redshift gestito
Per configurare lo storage Amazon Redshift gestito per l'integrazione Zero-ETL:
Crea o utilizza un Amazon Redshift cluster o un gruppo di lavoro Serverless esistente. Assicurati che il
enable_case_sensitive_identifierparametro sia attivato per il Amazon Redshift gruppo di lavoro o il cluster di destinazione affinché l'integrazione abbia successo. Per ulteriori informazioni sull'attivazione della distinzione tra maiuscole e minuscole, consulta Attivare la distinzione tra maiuscole e minuscole per il data warehouse nella guida alla Amazon Redshift gestione.Registrare un'integrazione da Redshift nel catalogo in AWS Lake Formation. Vedi Registrazione di Amazon Redshift cluster e namespace nel Data Catalog.
Crea un catalogo federato o gestito in. AWS Lake Formation Per ulteriori informazioni, consulta:
Configurare le autorizzazioni IAM per il ruolo di destinazione. Il ruolo richiede le autorizzazioni per accedere alle risorse di Redshift e Lake Formation. Il ruolo dovrebbe avere almeno:
Autorizzazioni di accesso al cluster o gruppo di lavoro Redshift
Autorizzazioni per accedere al catalogo Lake Formation
Autorizzazioni per creare e gestire tabelle nel catalogo
CloudWatch e CloudWatch registra le autorizzazioni per il monitoraggio
Dopo aver configurato il catalogo Amazon SageMaker Lakehouse con lo storage Amazon Redshift gestito, puoi procedere con il Configurazione dell'integrazione con la destinazione completamento della configurazione dell'integrazione.
Configurazione di un obiettivo di data warehouse Amazon Redshift
Questa sezione descrive i prerequisiti e i passaggi di configurazione per configurare un Amazon Redshift data warehouse come destinazione per l'integrazione zero-ETL.
Prima di creare un'integrazione zero-ETL con un obiettivo di Amazon Redshift data warehouse, è necessario completare le seguenti attività di configurazione:
Configurare un Amazon Redshift cluster o un gruppo di lavoro Serverless
Configurazione della distinzione tra maiuscole e minuscole
Configurazione delle autorizzazioni IAM
Configurazione del Amazon Redshift data warehouse
Per configurare un Amazon Redshift data warehouse per l'integrazione Zero-ETL:
Andare alla console Amazon Redshift
e fare clic su Crea cluster o utilizzare un cluster esistente. Per creare un Amazon Redshift cluster, vedi Creazione di un cluster. Per un gruppo di lavoro Amazon Redshift serverless, fare clic su Crea gruppo di lavoro. Per creare un gruppo di lavoro Amazon Redshift serverless, consulta Creazione di un gruppo di lavoro con uno spazio dei nomi. Se crei un nuovo cluster, scegli una dimensione del cluster appropriata e assicurarsi che il cluster sia crittografato. Per Serverless, configurare le impostazioni del gruppo di lavoro in base alle proprie esigenze.
Assicurati che il
enable_case_sensitive_identifierparametro sia attivato per il Amazon Redshift gruppo di lavoro o il cluster di destinazione affinché l'integrazione abbia successo. Per ulteriori informazioni sull’attivazione della distinzione tra maiuscole e minuscole, consulta Turn on case sensitivity for your data warehouse nella Guida alla gestione di Amazon Redshift.Configura le autorizzazioni IAM per consentire all'integrazione Zero-ETL di accedere al tuo data warehouse. Amazon Redshift Sarà necessario creare un ruolo IAM con le seguenti autorizzazioni:
Autorizzazioni per accedere al cluster o al gruppo di lavoro Amazon Redshift
Autorizzazioni per creare e gestire database e tabelle in Amazon Redshift
CloudWatch e CloudWatch registra le autorizzazioni per il monitoraggio
Una volta completata la configurazione del Amazon Redshift gruppo di lavoro o del cluster, è necessario configurare il data warehouse per le integrazioni zero-ETL. Per ulteriori informazioni consultare Nozioni base sulle integrazioni Zero-ETL nella Guida alla gestione di Amazon Redshift.
Nota
Quando si utilizza un Amazon Redshift data warehouse come destinazione, l'integrazione crea uno schema nel database specificato per archiviare i dati replicati. Il nome dello schema deriva dal nome dell'integrazione.
Nota
Il Amazon Redshift gruppo di lavoro o il cluster di destinazione deve avere il enable_case_sensitive_identifier parametro attivato affinché l'integrazione abbia successo.
Dopo aver configurato il Amazon Redshift data warehouse, puoi procedere con il Configurazione dell'integrazione con la destinazione completamento della configurazione dell'integrazione.
Configurazione dell'integrazione con la destinazione
Dopo aver configurato le risorse di origine e di destinazione, segui questi passaggi per completare la configurazione dell'integrazione:
Vai alla pagina «Integrazioni zero-ETL» e avvia il flusso di lavoro per la creazione dell'integrazione.
Seleziona la risorsa di origine configurata nei passaggi precedenti.
Seleziona o specifica la risorsa di destinazione (stesso account o account multiplo) configurata nei passaggi precedenti.
Seleziona il ruolo IAM di destinazione configurato in precedenza.
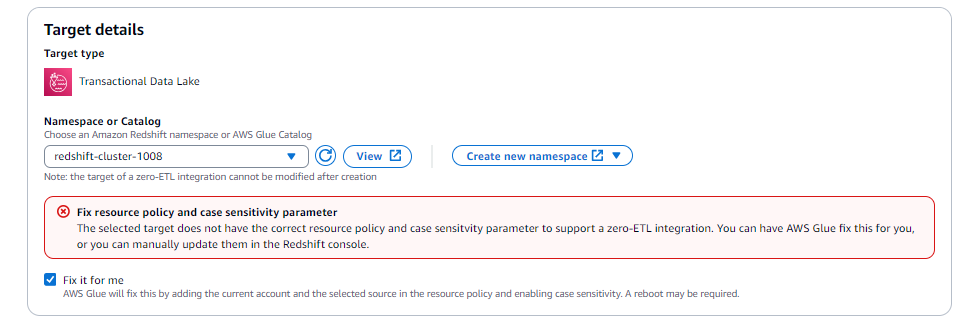
Seleziona l'opzione Fix it for me (disponibile solo quando il target si trova nello stesso account).
Per il normale target Amazon S3 (AWS Glue Database) e S3-Table (Catalog), questo sarà:
Applica un servizio principale autorizzato alla politica delle risorse del catalogo di destinazione.
Applica un ARN principale di AWS Glue origine autorizzato alla politica delle risorse del catalogo di destinazione.
Per l' Amazon Redshift obiettivo, ciò consentirà di:
Applicare un servizio principale autorizzato sul Amazon Redshift cluster o sul gruppo di lavoro Serverless.
Applica un ARN AWS Glue di origine autorizzato al Amazon Redshift cluster o al gruppo di lavoro Serverless.
Associare un nuovo set di parametri con
enable_case_sensitive_identifier = true.
Utilizza quanto segue per creare l'integrazione tramite API o CLI: CreateIntegration API.
