Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Aggiornamenti generativi dell'intelligenza artificiale per Apache Spark in AWS Aderenza
Spark Upgrades in AWS Glue consente ai data engineer e agli sviluppatori di aggiornare e migrare i job AWS Glue Spark esistenti alle ultime release di Spark utilizzando l'intelligenza artificiale generativa. I data engineer possono utilizzarlo per AWS scansionare i lavori di Glue Spark, generare piani di aggiornamento, eseguire piani e convalidare gli output. Riduce i tempi e i costi degli aggiornamenti di Spark automatizzando il lavoro indifferenziato di identificazione e aggiornamento degli script, delle configurazioni, delle dipendenze, dei metodi e delle funzionalità di Spark.
Come funziona
Quando utilizzi l'analisi degli aggiornamenti, AWS Glue identifica le differenze tra le versioni e le configurazioni nel codice del lavoro per generare un piano di aggiornamento. Il piano di aggiornamento descrive tutte le modifiche al codice e le fasi di migrazione richieste. Successivamente, AWS Glue crea ed esegue l'applicazione aggiornata in un ambiente per convalidare le modifiche e genera un elenco di modifiche al codice per la migrazione del lavoro. È possibile visualizzare lo script aggiornato insieme al riepilogo che descrive in dettaglio le modifiche proposte. Dopo aver eseguito i tuoi test, accetta le modifiche e il lavoro AWS Glue verrà aggiornato automaticamente alla versione più recente con il nuovo script.
Il processo di analisi degli aggiornamenti può richiedere un po' di tempo per il completamento, in funzione della complessità del processo e del carico di lavoro. I risultati dell'analisi dell'aggiornamento verranno archiviati nel percorso Amazon S3 specificato, che può essere esaminato per comprendere l'aggiornamento ed eventuali problemi di compatibilità. Dopo aver esaminato i risultati dell'analisi dell'aggiornamento, si può decidere se procedere con l'aggiornamento effettivo o apportare le modifiche necessarie al processo prima dell'aggiornamento.
Prerequisiti
I seguenti prerequisiti sono necessari per utilizzare l'intelligenza artificiale generativa per aggiornare i lavori in AWS Glue:
-
AWS Glue 2 PySpark jobs: solo i lavori AWS Glue 2 possono essere aggiornati a AWS Glue 5.
-
Le autorizzazioni IAM sono necessarie per avviare l'analisi, esaminare i risultati e aggiornare il processo. Per ulteriori informazioni, consultare gli esempi nella sezione Permissions seguente.
-
Se si utilizza AWS KMS per crittografare gli artefatti di analisi, sono necessarie autorizzazioni aggiuntive AWS AWS KMS . Per ulteriori informazioni, consultare gli esempi nella sezione AWS KMS policy seguente.
Permissions
-
Aggiornare la policy IAM del chiamante con la seguente autorizzazione:
-
Aggiornare il ruolo di esecuzione del processo in fase di aggiornamento per includere la seguente policy in linea:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }Ad esempio, se si utilizza il percorso
s3://amzn-s3-demo-bucket/upgraded-resultdi Amazon S3, la policy sarà:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
AWS KMS policy
Per passare la tua AWS KMS chiave personalizzata all'avvio di un'analisi, consulta la sezione seguente per configurare le autorizzazioni appropriate sulle chiavi. AWS KMS
Questa politica garantisce di disporre sia delle autorizzazioni di crittografia che di decrittografia sulla chiave. AWS KMS
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
Esecuzione di un'analisi degli aggiornamenti e applicazione dello script di aggiornamento
È possibile eseguire un'analisi degli aggiornamenti, che genererà un piano di aggiornamento su un processo selezionato dalla vista Processi.
-
Da Jobs, selezionate un job AWS Glue 2.0, quindi scegliete Esegui analisi di aggiornamento dal menu Azioni.
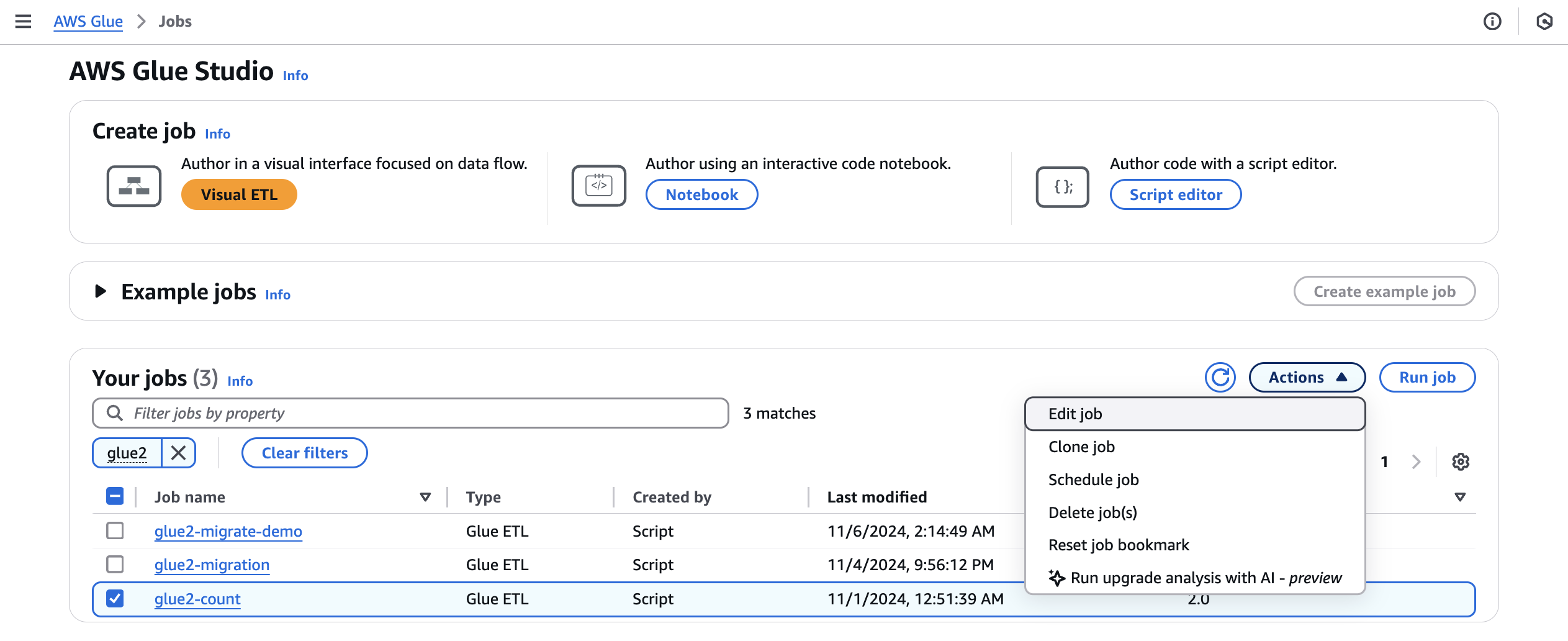
-
Nel modale, selezionare un percorso per memorizzare il piano di aggiornamento generato nel Percorso dei risultati. Questo deve essere il bucket Amazon S3 a cui si può accedere e su cui scrivere.
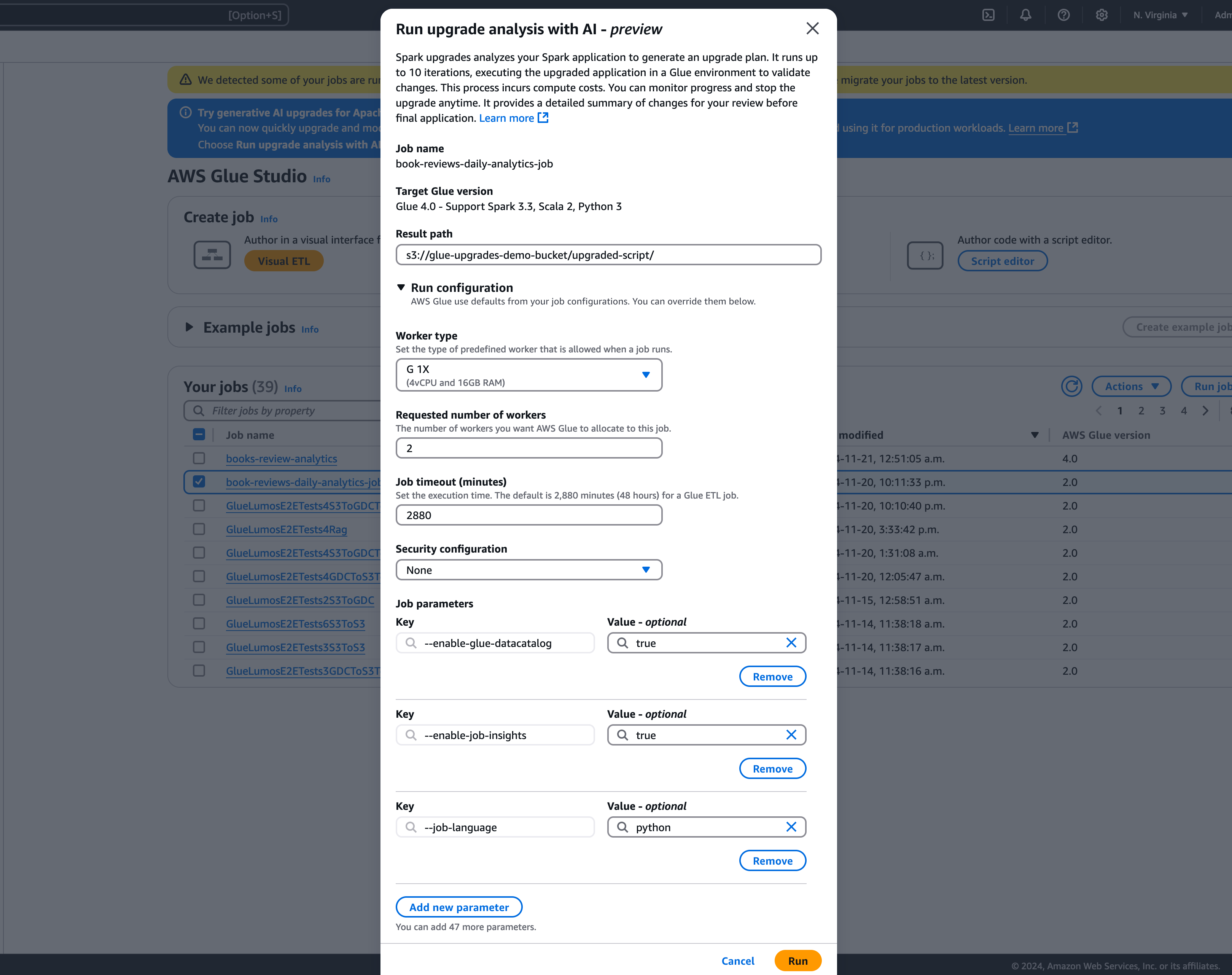
-
Configurare le opzioni aggiuntive, se necessario:
-
Configurazione di esecuzione - opzionale: la configurazione di esecuzione è un'impostazione opzionale che consente di personalizzare vari aspetti delle esecuzioni di convalida eseguite durante l'analisi degli aggiornamenti. Questa configurazione viene utilizzata per eseguire lo script aggiornato e consente di selezionare le proprietà dell'ambiente di calcolo (tipo di worker, numero di worker, ecc.). È necessario utilizzare gli account di sviluppatore non di produzione per eseguire le convalide su set di dati di esempio prima di esaminare, accettare le modifiche e applicarle agli ambienti di produzione. La configurazione di esecuzione include i seguenti parametri personalizzabili:
-
Tipo di worker: è possibile specificare il tipo di worker da utilizzare per le esecuzioni di convalida, in modo da scegliere le risorse di calcolo appropriate in base ai requisiti.
-
Numero di worker: è possibile definire il numero di worker da assegnare per le esecuzioni di convalida, in modo da scalare le risorse in base alle esigenze del carico di lavoro.
-
Timeout del processo (in minuti): questo parametro consente di impostare un limite di tempo per le esecuzioni di convalida, assicurando che i processi terminino dopo una durata specificata per evitare un consumo eccessivo di risorse.
-
Configurazione della sicurezza: è possibile configurare le impostazioni di sicurezza, come la crittografia e il controllo degli accessi, per garantire la protezione dei dati e delle risorse durante le esecuzioni di convalida.
-
Parametri di processo aggiuntivi: se necessario, è possibile aggiungere nuovi parametri di processo per personalizzare ulteriormente l'ambiente di esecuzione per le esecuzioni di convalida.
Sfruttando la configurazione di esecuzione, è possibile personalizzare le esecuzioni di convalida in base ai requisiti specifici. Ad esempio, è possibile configurare le esecuzioni di convalida per utilizzare un set di dati più piccolo, che consente di completare l'analisi più rapidamente e di ottimizzare i costi. Questo approccio garantisce che l'analisi degli aggiornamenti venga eseguita in modo efficiente, riducendo al minimo l'utilizzo delle risorse e i costi associati durante la fase di convalida.
-
-
Configurazione della crittografia - (opzionale):
-
Abilitare la crittografia degli artefatti di aggiornamento: abilitare la crittografia a riposo durante la scrittura dei dati nel percorso dei risultati. Se non si desidera crittografare gli elementi di aggiornamento, lasciare questa opzione deselezionata.
-
-
-
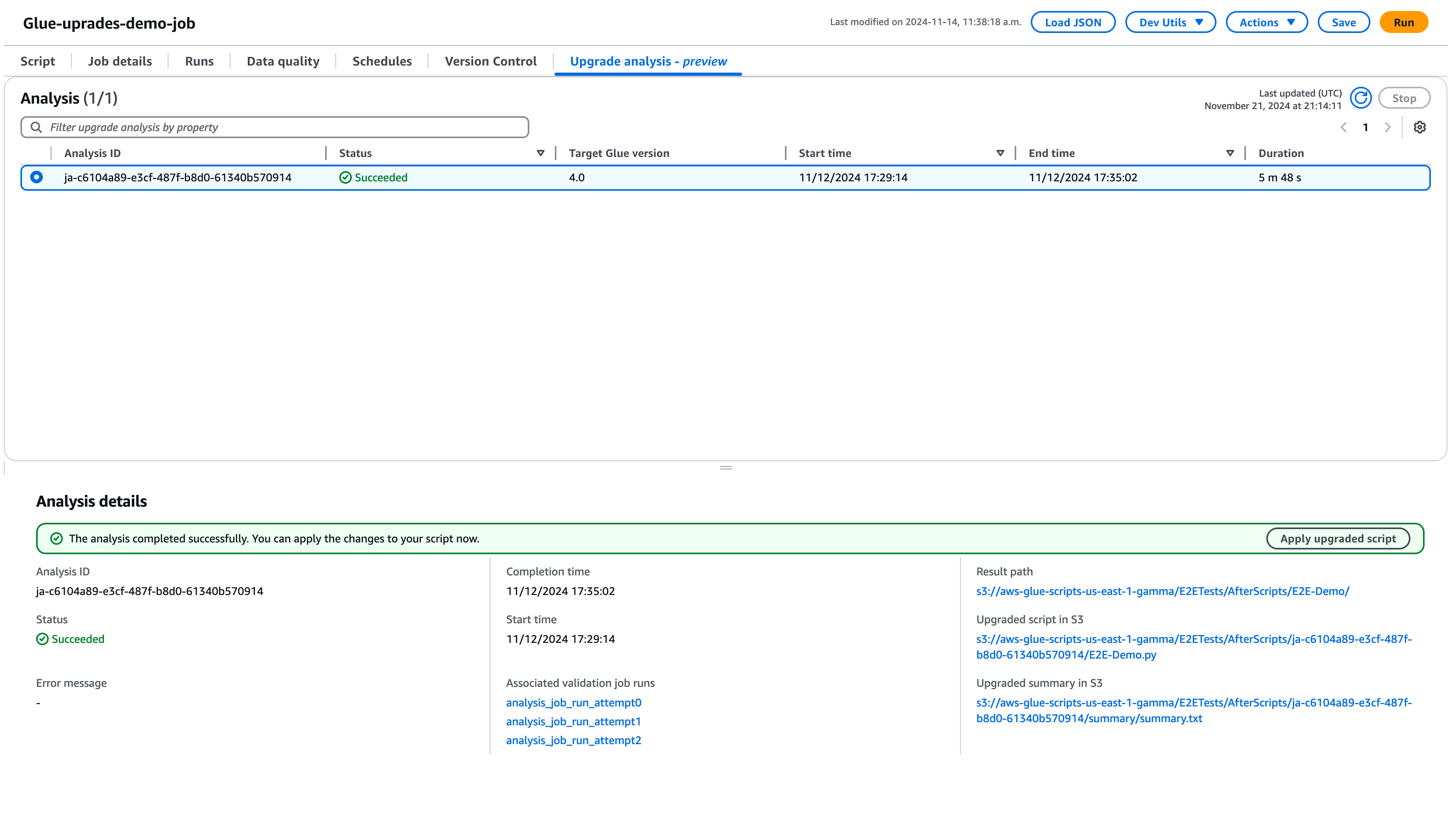
Scegliere Esegui per avviare l'analisi degli aggiornamenti. Mentre l'analisi è in esecuzione, è possibile visualizzare i risultati nella scheda Analisi dell'aggiornamento. La finestra dei dettagli dell'analisi mostrerà informazioni sull'analisi e collegamenti agli artefatti di aggiornamento.
-
Percorso dei risultati: è qui che vengono archiviati il riepilogo dei risultati e lo script di aggiornamento.
-
Script aggiornato in Amazon S3: la posizione dello script di aggiornamento in Amazon S3. È possibile visualizzare lo script prima di applicare l'aggiornamento.
-
Riepilogo dell'aggiornamento in Amazon S3: la posizione del riepilogo dell'aggiornamento in Amazon S3. È possibile visualizzare il riepilogo dell'aggiornamento prima di applicarlo.
-
-
Una volta completata con successo l'analisi dell'aggiornamento, è possibile applicare lo script di aggiornamento per aggiornare automaticamente il processo scegliendo Applica script aggiornato.
Una volta applicata, la versione AWS Glue verrà aggiornata alla 4.0. È possibile visualizzare lo script nella scheda Script.
Comprendere il riepilogo dell'aggiornamento
Questo esempio dimostra il processo di aggiornamento di un lavoro AWS Glue dalla versione 2.0 alla versione 4.0. Il processo di esempio legge i dati di prodotto da un bucket Amazon S3, applica diverse trasformazioni ai dati utilizzando Spark SQL e quindi salva i risultati trasformati in un bucket Amazon S3.
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

In base al riepilogo, ci sono quattro modifiche proposte da AWS Glue per aggiornare correttamente lo script da AWS Glue 2.0 a AWS Glue 4.0:
-
Configurazione SQL di Spark (spark.sql.adaptive.enabled): questa modifica serve a ripristinare il comportamento dell'applicazione quando una nuova funzionalità per l'esecuzione adattiva delle query Spark SQL viene introdotta a partire da Spark 3.2. Si può ispezionare questa modifica alla configurazione e abilitarla o disabilitarla ulteriormente secondo le preferenze.
-
DataFrame Modifica dell'API: l'opzione path non può coesistere con altre DataFrameReader operazioni come
load(). Per mantenere il comportamento precedente, AWS Glue ha aggiornato lo script per aggiungere una nuova configurazione SQL (OptionBehavior.enabledspark.sql.legacy.path). -
Modifica dell'API SQL di Spark: il comportamento di
strfmtinformat_string(strfmt, obj, ...)è stato aggiornato in modo da non consentire0$come primo argomento. Per garantire la compatibilità, AWS Glue ha modificato lo script da utilizzare invece1$come primo argomento. -
Modifica dell'API SQL di Spark: la funzione
unbase64non consente input di stringhe in formato errato. Per mantenere il comportamento precedente, AWS Glue ha aggiornato lo script per utilizzare latry_to_binaryfunzione.
Interruzione di un'analisi di aggiornamento in corso
È possibile annullare un'analisi dell'aggiornamento in corso o semplicemente interromperla.
-
Scegliere la scheda Analisi dell'aggiornamento.
-
Selezionare il processo in esecuzione, poi scegliere Interrompi. Questo interromperà l'analisi. È quindi possibile eseguire un'altra analisi degli aggiornamenti sullo stesso processo.

Considerazioni
Quando inizi a utilizzare Spark Upgrades, ci sono diversi aspetti importanti da considerare per un utilizzo ottimale del servizio.
-
Ambito e limitazioni del servizio: la versione corrente si concentra sugli aggiornamenti PySpark del codice dalle versioni 2.0 alla versione 5.0 di AWS Glue. Al momento, il servizio gestisce PySpark codice che non si basa su dipendenze di libreria aggiuntive. È possibile eseguire aggiornamenti automatici per un massimo di 10 processi contemporaneamente in un AWS account, in modo da aggiornare in modo efficiente più processi mantenendo al contempo la stabilità del sistema.
-
Sono supportati solo i PySpark lavori.
-
L'analisi degli aggiornamenti scadrà dopo 24 ore.
-
È possibile eseguire solo un'analisi di aggiornamento attiva alla volta per un singolo processo. A livello di account, possono essere eseguite fino a 10 analisi degli aggiornamenti attive nello stesso momento.
-
-
Ottimizzazione dei costi durante il processo di aggiornamento: poiché Spark Upgrades utilizza l'intelligenza artificiale generativa per convalidare il piano di aggiornamento attraverso più iterazioni, con ogni iterazione eseguita come processo AWS Glue nel tuo account, è essenziale ottimizzare le configurazioni di esecuzione del processo di convalida per ridurre i costi. A tal fine, consigliamo di specificare una configurazione di esecuzione all'avvio di un'analisi degli aggiornamenti nel modo seguente:
-
Usare account di sviluppo non di produzione e selezionare esempi di set di dati fittizi che rappresentino i dati di produzione ma di dimensioni più piccole per la convalida con Spark Upgrades.
-
Utilizzo di risorse di elaborazione delle dimensioni corrette, come i lavoratori, e selezione del numero appropriato di G.1X lavoratori per l'elaborazione dei dati di esempio.
-
Attivazione dell'auto-scaling dei job di AWS Glue, se applicabile, per regolare automaticamente le risorse in base al carico di lavoro.
Ad esempio, se il processo di produzione elabora terabyte di dati con 20 G.2X lavoratori, è possibile configurare il processo di aggiornamento per elaborare alcuni gigabyte di dati rappresentativi con 2 lavoratori G.2X e l'auto-scaling abilitato per la convalida.
-
-
Migliori pratiche: consigliamo vivamente di iniziare il percorso di upgrade con lavori non di produzione. Questo approccio consente di acquisire familiarità con il flusso di lavoro di aggiornamento e di comprendere come il servizio gestisce i diversi tipi di modelli di codice Spark.
-
Allarmi e notifiche: quando utilizzi la funzionalità di aggiornamento dell'intelligenza artificiale generativa su un lavoro, assicurati che alarms/notifications le esecuzioni dei job non riusciti siano disattivate. Durante il processo di aggiornamento, potrebbero verificarsi fino a 10 esecuzioni di processi non riusciti nell'account prima che vengano forniti gli artefatti aggiornati.
-
Regole di rilevamento delle anomalie: disattivate le regole di rilevamento delle anomalie sul processo in fase di aggiornamento, poiché i dati scritti nelle cartelle di output durante le esecuzioni intermedie dei processi potrebbero non essere nel formato previsto durante la convalida dell'aggiornamento.
-
Utilizzare l'analisi degli aggiornamenti con processi di idempotenza: utilizzare l'analisi degli aggiornamenti con processi idempotenti per garantire che ogni successivo tentativo di esecuzione del processo di convalida sia simile a quello precedente e non comporti problemi. I processi idempotenti sono processi che possono essere eseguiti più volte con gli stessi dati di input e produrranno ogni volta lo stesso output. Quando si utilizzano gli aggiornamenti di intelligenza artificiale generativa per Apache Spark in AWS Glue, il servizio eseguirà più iterazioni del job come parte del processo di convalida. Durante ogni iterazione, apporterà modifiche al codice e alle configurazioni Spark per convalidare il piano di aggiornamento. Se il processo Spark non è idempotente, eseguirlo più volte con gli stessi dati di input potrebbe causare problemi.
Regioni supportate
Gli aggiornamenti generativi dell'intelligenza artificiale per Apache Spark sono disponibili nelle seguenti regioni:
-
Asia Pacifico: Tokyo (ap-northeast-1), Seul (ap-northeast-2), Mumbai (ap-south-1), Singapore (ap-southeast-1) e Sydney (ap-southeast-2)
-
Nord America: Canada (ca-central-1)
-
Europa: Francoforte (eu-central-1), Stoccolma (eu-north-1), Irlanda (eu-west-1), Londra (eu-west-2) e Parigi (eu-west-3)
-
Sud America: San Paolo (sa-east-1)
-
Stati Uniti: Virginia del Nord (us-east-1), Ohio (us-east-2) e Oregon (us-west-2)
Cross-region inferenza in Spark Upgrades
Spark Upgrades è basato Amazon Bedrock e sfrutta l'inferenza interregionale (CRIS). Con CRIS, Spark Upgrades selezionerà automaticamente la regione ottimale all'interno dell'area geografica (come descritto più dettagliatamente qui) per elaborare la richiesta di inferenza, massimizzare le risorse di calcolo disponibili e la disponibilità dei modelli e fornire la migliore esperienza al cliente. L'utilizzo dell'inferenza tra regioni non prevede costi aggiuntivi.
Cross-region le richieste di inferenza vengono conservate all'interno AWS delle regioni che fanno parte della geografia in cui risiedono originariamente i dati. Ad esempio, una richiesta effettuata negli Stati Uniti viene conservata nelle AWS regioni degli Stati Uniti. Sebbene i dati rimangano archiviati solo nella regione primaria, quando si utilizza l'inferenza tra regioni, i prompt di input e i risultati di output potrebbero spostarsi al di fuori della regione primaria. Tutti i dati verranno trasmessi crittografati attraverso la rete sicura di Amazon.
