Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Valutazione della qualità dei dati per i processi ETL in AWS Glue Studio
In questo tutorial, si inizierà a usare Qualità dei dati di AWS Glue in AWS Glue Studio. Si imparerà come:
-
Creare regole utilizzando il generatore di regole Data Quality Definition Language (DQDL).
-
Specificare le azioni di qualità dei dati, i dati da emettere e la posizione di output dei risultati della qualità dei dati.
-
Esaminare i risultati della qualità dei dati.
Per fare pratica con un esempio, consulta il post sul blog Getting started with AWS Glue Data Quality for ETL pipelines
Passaggio 1: aggiunta del nodo Valuta la qualità dei dati al processo visivo
In questo passaggio, verrà aggiunto il nodo di valutazione della qualità dei dati all'editor del processo visivo.
Aggiunta del nodo di qualità dei dati
-
Nella console AWS Glue Studio, scegli Visual con un'origine e una destinazione dalla sezione Crea lavoro, quindi scegli Crea.
-
Scegliere un nodo al quale desideri applicare la trasformazione della qualità dei dati. In genere, si tratta di un nodo di trasformazione o di un'origine dati.
-
Aprire il pannello delle risorse a sinistra scegliendo l'icona “+”. È inoltre possibile digitare Valuta la qualità dei dati nella barra di ricerca e quindi scegliere Valuta la qualità dei dati dai risultati della ricerca.
-
L'editor del processo visivo mostrerà il nodo di trasformazione Valuta la qualità dei dati che si dirama dal nodo selezionato. Sul lato destro della console, la scheda Transform (Trasforma) è aperta automaticamente. Se è necessario modificare il nodo padre, scegliere la scheda Proprietà del nodo, quindi scegliere il nodo padre dal menu a discesa.
Quando si sceglie un nuovo nodo principale, viene stabilita una nuova connessione tra il nodo principale e il nodo Evaluate Data Quality (Valuta la qualità dei dati). Rimuovere tutti i nodi principali indesiderati. È possibile collegare un solo nodo principale a un nodo Evaluate Data Quality (Valuta la qualità dei dati).
-
La trasformazione Valuta la qualità dei dati supporta più padri per consentire di convalidare le regole di qualità dei dati su più set di dati. Le regole che supportano più set di dati includono ReferentialIntegrity DatasetMatch,, SchemaMatch RowCountMatch, e AggregateMatch.
Se si aggiungono più input alla trasformazione Valuta la qualità dei dati, è necessario selezionare l'input “primario”. L'input primario è il set di dati del quale desideri convalidare la qualità dei dati. Tutti gli altri nodi o input vengono trattati come riferimenti.
È possibile utilizzare la trasformazione Valuta la qualità dei dati per identificare record specifici che non hanno superato i controlli di qualità dei dati. Ti consigliamo di scegliere il set di dati primario perché le nuove colonne che segnalano i record non validi vengono aggiunte a tale set di dati.
-
È possibile specificare degli alias per le origini dati di input. Gli alias forniscono un altro modo per fare riferimento alla sorgente di input quando si utilizza la ReferentialIntegrity regola. Poiché è possibile designare una sola origine dati come origine principale, ogni ulteriore origine dati che aggiungi richiederà un alias.
Nell'esempio seguente, la ReferentialIntegrity regola specifica l'origine dati di input tramite il nome dell'alias ed esegue un one-to-one confronto con l'origine dati principale.
Rules = [ ReferentialIntegrity “Aliasname.name” = 1 ]
Fase 2: creazione di una regola con DQDL
In questa fase, viene creata una regola tramite DQDL. Per questo tutorial, verrà creata una singola regola utilizzando il tipo di regola Completezza. Questo tipo di regola verifica la percentuale di valori completi (non nulli) in una colonna rispetto a una determinata espressione. Per ulteriori informazioni sull'utilizzo di DQDL, consultare la pagina DQDL.
-
Nella scheda Trasforma, aggiungere un Tipo di regola facendo clic sul pulsante Inserisci. Questa operazione aggiunge il tipo di regola all'editor di regole, nel quale è possibile inserire i parametri per la regola.
Nota
Quando modifichi le regole, assicurarsi che le regole siano racchiuse tra parentesi e che siano separate da virgole. Ad esempio, un'espressione di regola completa avrà il seguente aspetto:
Rules= [ Completeness "year">0.8, Completeness "month">0.8 ]Questo esempio specifica il parametro di completezza per le colonne denominate "anno" e "mese". Affinché la regola venga soddisfatta, queste colonne devono essere complete per più dell'80% o devono contenere dati in oltre l'80% delle istanze per ogni rispettiva colonna.
In questo esempio, cercare e inserire il tipo di regola Completezza. Questa operazione aggiunge il tipo di regola all'editor di regole. Questo tipo di regola ha la seguente sintassi:
Completeness <COL_NAME> <EXPRESSION>.La maggior parte dei tipi di regole richiede la specifica di un'espressione come parametro al fine di creare una risposta booleana. Per ulteriori informazioni sulle espressioni DQDL supportate, consultare la pagina DQDL expressions. Successivamente, aggiungere il nome della colonna.
-
Nel generatore di regole DQDL, selezionare la scheda Schema. Usare la barra di ricerca per individuare il nome della colonna nello schema di input. Lo schema di input visualizza il nome della colonna e il tipo di dati.
-
Nell'editor di regole, fare clic sulla destra del tipo di regola per inserire il cursore nel punto in cui verrà inserita la colonna. In alternativa, è possibile digitare il nome della colonna nella regola.
Ad esempio, dall'elenco di colonne nell'elenco dello schema di input, fai clic sul pulsante Inserisci accanto alla colonna (in questo esempio, anno). Questa operazione aggiunge la colonna alla regola.
-
Quindi, nell'editor di regole, aggiungere un'espressione per valutare la regola. Poiché il tipo Completezza verifica la percentuale di valori completi (non nulli) in una colonna rispetto a una determinata espressione, immettere un'espressione come
> 0.8. Questa regola controlla se la colonna contiene almeno l'80% di valori completi (non nulli).
Passaggio 3: configurazione degli output di qualità dei dati
Dopo aver creato le regole di qualità dei dati, è possibile selezionare opzioni aggiuntive per specificare l'output del nodo della qualità dei dati.
-
In Output della trasformazione della qualità dei dati, scegliere tra le seguenti opzioni:
-
Dati originali: scegliere di emettere i dati di input originali. Quando si sceglie questa opzione, al job viene aggiunto un nuovo nodo figlio «rowLevelOutcomes». Lo schema corrisponde allo schema del set di dati primario trasmesso come input alla trasformazione. Questa opzione è utile se si desidera soltanto trasmettere i dati e far sì che il processo abbia esito negativo se si verificano problemi di qualità.
Un altro caso d'uso è quando si desidera rilevare record non validi che non hanno superato i controlli di qualità dei dati. Per rilevare i record non validi, scegliere l'opzione Aggiungi nuove colonne per indicare gli errori di qualità dei dati. Questa azione aggiunge quattro nuove colonne allo schema della trasformazione «rowLevelOutcomes».
-
DataQualityRulesPass(array di stringhe): fornisce una serie di regole che hanno superato i controlli di qualità dei dati.
-
DataQualityRulesFail(array di stringhe) — Fornisce una serie di regole che non hanno superato i controlli di qualità dei dati.
-
DataQualityRulesSkip(array di stringhe) — Fornisce una serie di regole che sono state ignorate. Le seguenti regole non possono identificare i record di errore perché vengono applicate a livello di set di dati.
-
AggregateMatch
-
ColumnCount
-
ColumnExists
-
ColumnNamesMatchPattern
-
CustomSql
-
RowCount
-
RowCountMatch
-
StandardDeviation
-
Media
-
ColumnCorrelation
-
-
DataQualityEvaluationResult— Fornisce lo stato «Passato» o «Non riuscito» a livello di riga. Tenere presente che i risultati complessivi possono essere non riusciti, ma un determinato record potrebbe essere riuscito. Ad esempio, la RowCount regola potrebbe non essere riuscita, ma tutte le altre regole potrebbero aver avuto successo. In questi casi, lo stato di questo campo è “Riuscito”.
-
-
-
Risultati della qualità dei dati: scegliere di visualizzare le regole configurate e il loro stato di riuscita o non riuscita. Questa opzione è utile se desideri scrivere i risultati su Amazon S3 o altri database.
-
Impostazioni di output della qualità dei dati (opzionale): scegliere Impostazioni di output della qualità dei dati per visualizzare il campo Posizione dei risultati della qualità dei dati. Quindi, fare clic su Sfoglia per cercare una posizione Amazon S3 da impostare come destinazione dell'output della qualità dei dati.
Passaggio 4. Configurazione delle operazioni di qualità dei dati
Puoi utilizzare le azioni per pubblicare metriche CloudWatch o interrompere i lavori in base a criteri specifici. Le operazioni sono disponibili solo dopo aver creato una regola. Se si sceglie questa opzione, gli stessi parametri vengono pubblicati anche su Amazon EventBridge. È possibile utilizzare queste opzioni per creare avvisi di notifica.
-
In caso di errore del set di regole: è possibile scegliere cosa fare se un set di regole ha esito negativo mentre il processo è in esecuzione. Se si desidera che il processo abbia esito negativo se la qualità dei dati non va a buon fine, è possibile scegliere quando far fallire il processo selezionando una delle seguenti opzioni. Per impostazione predefinita, questa operazione non è selezionata e l'esecuzione del processo sarà completata anche se le regole di qualità dei dati hanno esito negativo.
-
Nessuno: se si sceglie Nessuno (impostazione predefinita), il processo non ha esito negativo e continua a essere eseguito nonostante gli errori del set di regole.
-
Abbandonare il processo dopo il caricamento dei dati sulla destinazione: il processo ha esito negativo e non viene salvato alcun dato. Per salvare i risultati, scegliere una posizione Amazon S3 in cui salvare i risultati sulla qualità dei dati.
-
Abbandonare il processo senza caricare i dati sulla destinazione: questa opzione determina immediatamente l'esito negativo del processo quando si verifica un errore di qualità dei dati. Non carica alcuna destinazione dati, inclusi i risultati della trasformazione di qualità dei dati.
-
Passaggio 5: visualizzazione dei risultati della qualità dei dati
Dopo aver eseguito il processo, visualizzare i risultati relativi alla qualità dei dati facendo clic sulla scheda Qualità dei dati.
-
Per ogni esecuzione di processo, visualizzare i risultati della qualità dei dati. Ogni nodo mostra lo stato della qualità dei dati e i dettagli dello stato. Scegliere un nodo per visualizzare tutte le regole e lo stato di ciascuna regola.
-
Fare clic su Scarica risultati per scaricare un file CSV contenente informazioni sull'esecuzione del processo e sui risultati relativi alla qualità dei dati.
-
Se si hanno più di una esecuzione di processo con risultati di qualità dei dati, è possibile filtrare i risultati per intervallo di data e ora. Scegliere Filtra per intervallo di data e ora per espandere la finestra del filtro.
-
È possibile scegliere un intervallo relativo o un intervallo assoluto. Per gli intervalli assoluti, utilizzare il calendario per selezionare i valori di data e ora per l'ora di inizio e l'ora di fine. Al termine, scegliere Applica.
Qualità dei dati automatica
Quando crei un lavoro AWS Glue ETL con Amazon S3 come destinazione, AWS Glue ETL abilita automaticamente una regola di qualità dei dati che verifica se i dati caricati hanno almeno una colonna. Questa regola è progettata per garantire che i dati caricati non siano vuoti o danneggiati. Tuttavia, se questa regola ha esito negativo, il processo non avrà esito negativo; si noterà invece una riduzione del punteggio della qualità dei dati. Inoltre, per impostazione predefinita, è abilitato il rilevamento delle anomalie, che monitora il numero di colonne nei dati. Se ci sono variazioni o anomalie nel conteggio delle colonne, AWS Glue ETL ti informerà di queste anomalie. Questa funzione aiuta a identificare potenziali problemi con i dati e ad adottare le azioni appropriate. Per visualizzare la regola Data Quality e la relativa configurazione, puoi fare clic sulla destinazione Amazon S3 nel job AWS Glue ETL. La configurazione della regola verrà visualizzata, come mostrato nella seguente schermata.
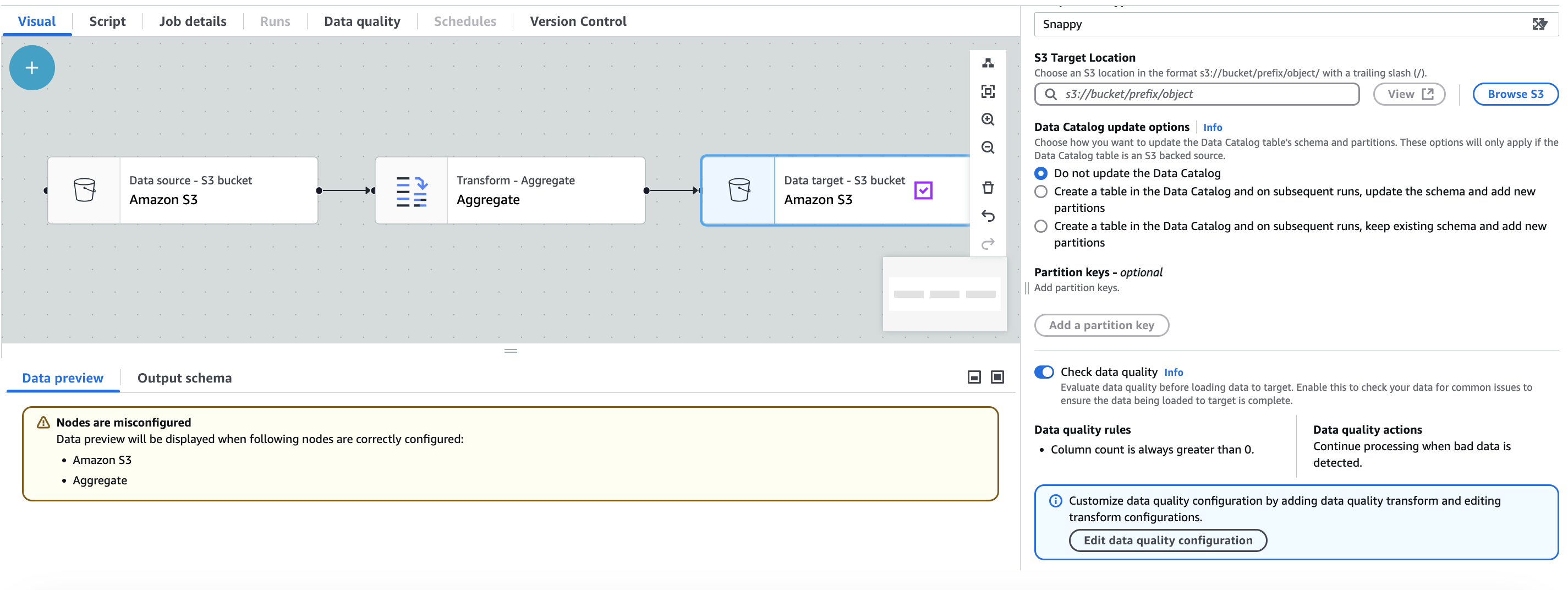
È possibile aggiungere ulteriori regole sulla qualità dei dati selezionando Modifica configurazione della qualità dei dati.
Parametri aggregati
Per creare dashboard, potrebbero essere necessari parametri aggregati come il numero di record passati, non riusciti, ignorati a livello di regola o a livello di set di regole. Per ottenere i parametri aggregati e i parametri delle regole per ciascuna regola, abilitare innanzitutto i Parametri aggregati aggiungendo l'opzione publishAggregatedMetrics alla funzione EvaluateDataQuality.
Le opzioni possibili per additional_options publishAggregatedMetrics sono ENABLED e DISABLED. Ad esempio:
EvaluateDataQualityMultiframe = EvaluateDataQuality().process_rows( frame=medicare_dyf, ruleset=EvaluateDataQuality_ruleset, publishing_options={ "dataQualityEvaluationContext": "EvaluateDataQualityMultiframe", "enableDataQualityCloudWatchMetrics": False, "enableDataQualityResultsPublishing": False, }, additional_options={"publishAggregatedMetrics.status": "ENABLED"}, )
Se non specificato, il publishAggregatedMetrics.status è DISABLED per impostazione predefinita e i parametri delle regole e i parametri aggregati verranno ora calcolati. Questa funzionalità è attualmente supportata nelle AWS Glue Interactive Sessions e nei job Glue ETL. Questa funzionalità non è supportata in Glue Catalog Data Quality APIs.
Recupero dei risultati dei parametri aggregati
Quando additionalOptions "publishAggregatedMetrics.status": "ENABLED", è possibile ottenere i risultati in due punti:
-
AggregatedMetricseRuleMetricsvengono restituiti tramiteGetDataQualityResult()quando si fornisce ilresultIddoveAggregatedMetricseRuleMetricsincludono:Parametri aggregati:
Righe totali elaborate
Righe totali riuscite
Righe totali non riuscite
Totale regole elaborate
Totale regole riuscite
Totale regole non riuscite

Inoltre, a livello di regola, vengono forniti seguenti parametri:
Parametri delle regole:
Righe riuscite
Righe non riuscite
Righe ignorate
Righe totali elaborate
-
AggregatedMetricsviene restituito come frame di dati aggiuntivo e il frame di datiRuleOutcomesviene aumentato per includereRuleMetrics.
Implementazione esemplificativa
L'esempio seguente mostra come implementare i parametri aggregati in Scala:
// Script generated for node Evaluate Data Quality val EvaluateDataQuality_node1741974822533_ruleset = """ # Example rules: Completeness "colA" between 0.4 and 0.8, ColumnCount > 10 Rules = [ IsUnique "customer_identifier", RowCount > 10, Completeness "customer_identifier" > 0.5 ] """ val EvaluateDataQuality_node1741974822533 = EvaluateDataQuality.processRows(frame=ChangeSchema_node1742850392012, ruleset=EvaluateDataQuality_node1741974822533_ruleset, publishingOptions=JsonOptions("""{"dataQualityEvaluationContext": "EvaluateDataQuality_node1741974822533", "enableDataQualityCloudWatchMetrics": "true", "enableDataQualityResultsPublishing": "true"}"""), additionalOptions=JsonOptions("""{"compositeRuleEvaluation.method":"ROW","observations.scope":"ALL","performanceTuning.caching":"CACHE_NOTHING", "publishAggregatedMetrics.status": "ENABLED"}""")) println("--------------------------------ROW LEVEL OUTCOMES--------------------------------") val rowLevelOutcomes_node = EvaluateDataQuality_node1741974822533("rowLevelOutcomes") rowLevelOutcomes_node.show(10) println("--------------------------------RULE LEVEL OUTCOMES--------------------------------") val ruleOutcomes_node = EvaluateDataQuality_node1741974822533("ruleOutcomes") ruleOutcomes_node.show() println("--------------------------------AGGREGATED METRICS--------------------------------") val aggregatedMetrics_node = EvaluateDataQuality_node1741974822533("aggregatedMetrics") aggregatedMetrics_node.show()
Risultati di esempio
I risultati vengono restituiti come segue:
{ "Rule": "IsUnique \"customer_identifier\"", "Outcome": "Passed", "FailureReason": null, "EvaluatedMetrics": { "Column.customer_identifier.Uniqueness": 1 }, "EvaluatedRule": "IsUnique \"customer_identifier\"", "PassedCount": 10, "FailedCount": 0, "SkippedCount": 0, "TotalCount": 10 } { "Rule": "RowCount > 10", "Outcome": "Failed", "FailureReason": "Value: 10 does not meet the constraint requirement!", "EvaluatedMetrics": { "Dataset.*.RowCount": 10 }, "EvaluatedRule": "RowCount > 10", "PassedCount": 0, "FailedCount": 0, "SkippedCount": 10, "TotalCount": 10 } { "Rule": "Completeness \"customer_identifier\" > 0.5", "Outcome": "Passed", "FailureReason": null, "EvaluatedMetrics": { "Column.customer_identifier.Completeness": 1 }, "EvaluatedRule": "Completeness \"customer_identifier\" > 0.5", "PassedCount": 10, "FailedCount": 0, "SkippedCount": 0, "TotalCount": 10 }
I parametri aggregati sono i seguenti:
{ "TotalRowsProcessed": 10, "PassedRows": 10, "FailedRows": 0, "TotalRulesProcessed": 3, "RulesPassed": 2, "RulesFailed": 1 }
