Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo AWS Glue con AWS Lake Formation per un controllo granulare degli accessi
Panoramica di
Con AWS la versione 5.0 e successive di Glue, puoi sfruttare AWS Lake Formation per applicare controlli di accesso granulari alle tabelle di Data Catalog supportate da S3. Questa capacità consente di configurare i controlli di accesso a livello di tabella, riga, colonna e cella per read query all'interno dei processi di AWS Glue per Apache Spark. Consulta le seguenti sezioni per saperne di più su Lake Formation e su come usarlo con AWS Glue.
GlueContextil controllo degli accessi a livello di tabella con AWS Lake Formation autorizzazioni supportate in Glue 4.0 o versioni precedenti non è supportato in Glue 5.0. Usare il nuovo controllo granulare degli accessi (FGAC) nativo di Spark in Glue 5.0. Si notino i seguenti dettagli:
Se hai bisogno di un controllo degli accessi a grana fine (FGAC) per row/column /cell access control, dovrai migrare da /Glue in Glue 4.0 e versioni precedenti al dataframe Spark
GlueContextin DynamicFrame Glue 5.0. Per alcuni esempi, consultare Migrazione da GlueContext/Glue DynamicFrame Spark DataFrame.Se hai bisogno del controllo Full Table Access (FTA), puoi sfruttare FTA con DynamicFrames AWS Glue 5.0. Puoi anche migrare all'approccio Spark nativo per funzionalità aggiuntive come set di dati distribuiti resilienti (RDD), librerie personalizzate e funzioni definite dall'utente (UDF) con tabelle. AWS Lake Formation Per esempi, vedi Migrazione da AWS Glue 4.0 a AWS Glue 5.0.
Se non è necessario il FGAC, non occorre eseguire la migrazione al dataframe Spark e le funzionalità di
GlueContext, come i segnalibri di processo e i predicati push down, continueranno a funzionare.I processi con FGAC un minimo di 4 worker: un driver utente, un driver di sistema, un esecutore di sistema e un esecutore utente in standby.
L'utilizzo di AWS AWS Lake Formation Glue with comporta costi aggiuntivi.
In che modo AWS Glue funziona con AWS Lake Formation
L'utilizzo di AWS Glue with Lake Formation ti consente di applicare un livello di autorizzazioni su ogni lavoro Spark per applicare il controllo delle autorizzazioni di Lake Formation quando AWS Glue esegue i lavori. AWS Glue utilizza i profili di risorse Spark
Di seguito è riportata una panoramica di alto livello su come AWS Glue ottiene l'accesso ai dati protetti dalle politiche di sicurezza di Lake Formation.
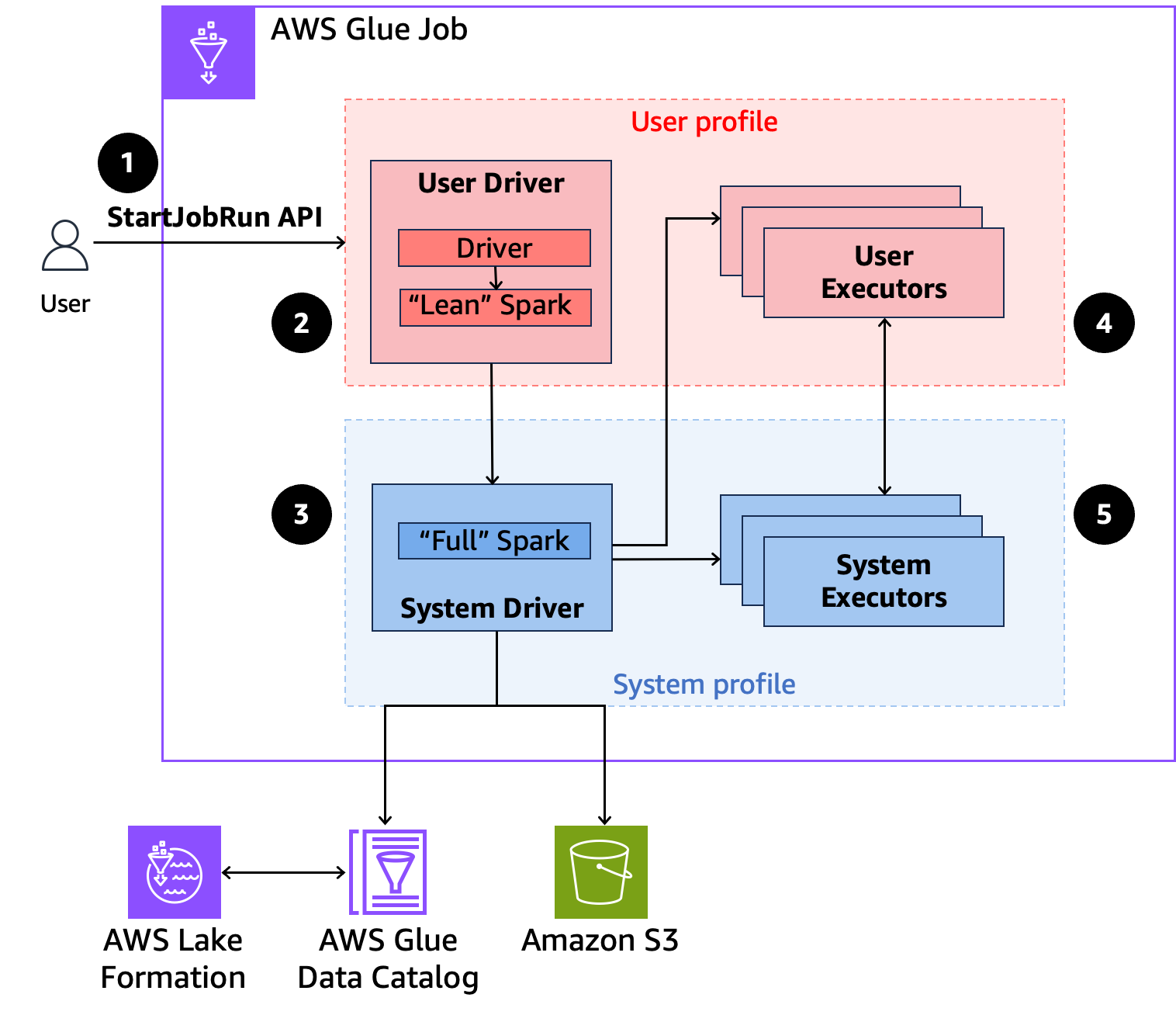
-
Un utente chiama l'
StartJobRunAPI su un job AWS Lake Formation-enabled AWS Glue. -
AWS Glue invia il lavoro a un driver utente ed esegue il lavoro nel profilo utente. Il driver utente esegue una versione snella di Spark che non è in grado di avviare attività, richiedere esecutori, accedere a S3 o al catalogo di Glue. Costruisce un piano per il processo.
-
AWS Glue imposta un secondo driver chiamato driver di sistema e lo esegue nel profilo di sistema (con un'identità privilegiata). AWS Glue imposta un canale TLS crittografato tra i due driver per la comunicazione. Il driver utente utilizza il canale per inviare i piani per il processo al driver di sistema. Il driver di sistema non esegue il codice inviato dall'utente. Esegue Spark completo e comunica con S3 e il catalogo dati per l'accesso ai dati. Richiede esecutori e compila il piano per il processo in una sequenza di fasi di esecuzione.
-
AWS Glue esegue quindi le fasi sugli executor con il driver utente o il driver di sistema. Il codice utente in qualsiasi fase viene eseguito esclusivamente sugli esecutori dei profili utente.
-
Le fasi che leggono i dati dalle tabelle del Data Catalog protette da AWS Lake Formation o che applicano filtri di sicurezza vengono delegate agli esecutori di sistema.
Requisito minimo dei worker
Un Formation-enabled job Lake in AWS Glue richiede un minimo di 4 lavoratori: un driver utente, un driver di sistema, un esecutore di sistema e un esecutore utente in standby. Questo è un aumento rispetto al minimo di 2 lavoratori richiesti per i lavori standard di AWS Glue.
Un Formation-enabled job Lake in AWS Glue utilizza due driver Spark, uno per il profilo di sistema e l'altro per il profilo utente. Analogamente, anche gli esecutori sono divisi in due profili:
Esecutori di sistema: gestiscono le attività in cui vengono applicati i filtri dati di Lake Formation.
Esecutori utente: vengono richiesti dal driver di sistema in base alle esigenze.
Poiché i lavori Spark sono di natura pigra, AWS Glue riserva il 10% del totale dei lavoratori (minimo 1), dopo aver detratto i due driver, agli esecutori degli utenti.
Tutti i Formation-enabled job Lake hanno l'auto-scaling abilitato, il che significa che gli user executor verranno avviati solo quando necessario.
Per un esempio di configurazione, consultare Considerazioni e limitazioni.
Autorizzazioni IAM per il ruolo di runtime del processo
Le autorizzazioni di Lake Formation controllano l'accesso alle risorse di AWS Glue Data Catalog, alle sedi Amazon S3 e ai dati sottostanti in tali sedi. Le autorizzazioni IAM controllano l'accesso alle API e alle risorse di Lake Formation e AWS Glue. Anche se disponi dell'autorizzazione di Lake Formation per accedere a una tabella nel Data Catalog (SELECT), l'operazione fallisce se non disponi dell'autorizzazione IAM per il funzionamento dell'API glue:Get*.
Di seguito è riportato un esempio di policy su come fornire le autorizzazioni IAM per accedere a uno script in S3, caricare i log su S3, le autorizzazioni dell'API AWS Glue e l'autorizzazione per accedere a Lake Formation.
Configurazione delle autorizzazioni di Lake Formation per il ruolo di runtime del processo
Innanzitutto, registrare la posizione della tabella Hive con Lake Formation. Poi, creare le autorizzazioni per il ruolo di runtime del processo nella tabella desiderata. Per maggiori dettagli su Lake Formation, vedi What is AWS Lake Formation? nella Guida per gli AWS Lake Formation sviluppatori.
Dopo aver impostato le autorizzazioni di Lake Formation, è possibile inviare processi Spark su AWS Glue.
Invio di un'esecuzione di processo
Dopo aver completato l'impostazione delle sovvenzioni Lake Formation, puoi inviare lavori Spark su AWS Glue. Per eseguire i processi Iceberg, è necessario fornire le seguenti configurazioni Spark. Per eseguire la configurazione tramite i parametri del processo Glue, inserire il seguente parametro:
Chiave:
--confValore:
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
Utilizzo di una sessione interattiva
Dopo aver completato l'impostazione delle AWS Lake Formation sovvenzioni, puoi utilizzare Interactive Sessions on AWS Glue. È necessario fornire le seguenti configurazioni di Spark tramite il comando magic %%configure prima di eseguire il codice.
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
FGAC per AWS Notebook Glue 5.0 o sessioni interattive
Per abilitare Fine-Grained Access Control (FGAC) in AWS Glue devi specificare le configurazioni Spark richieste per Lake Formation come parte di %%configure magic prima di creare la prima cella.
Specificarlo in un secondo momento utilizzando le chiamate SparkSession.builder().conf("").get() o SparkSession.builder().conf("").create() non sarà sufficiente. Questa è una modifica rispetto al comportamento di AWS Glue 4.0.
Open-table supporto per il formato
AWS La versione 5.0 o successiva di Glue include il supporto per il controllo granulare degli accessi basato su Lake Formation. AWS Glue supporta i tipi di tabelle Hive e Iceberg. Nella tabella seguente sono descritte tutte le operazioni supportate.
| Operazioni | Hive | Iceberg |
|---|---|---|
| Comandi DDL | Solo con autorizzazioni del ruolo IAM | Solo con autorizzazioni del ruolo IAM |
| Query incrementali | Non applicabile | Completamente supportata |
| Query temporali | Non applicabile a questo formato di tabella | Completamente supportata |
| Tabelle dei metadati | Non applicabile a questo formato di tabella | Supportata, ma alcune tabelle sono nascoste. Per ulteriori informazioni, consultare Considerazioni e limitazioni. |
DML INSERT |
Solo con autorizzazioni IAM | Solo con autorizzazioni IAM |
| AGGIORNAMENTO DML | Non applicabile a questo formato di tabella | Solo con autorizzazioni IAM |
DML DELETE |
Non applicabile a questo formato di tabella | Solo con autorizzazioni IAM |
| Operazioni di lettura | Completamente supportata | Completamente supportata |
| Stored procedure | Non applicabile | Supportata con le eccezioni di register_table e migrate. Per ulteriori informazioni, consultare Considerazioni e limitazioni. |
