Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Integrazione con il registro degli schemi di AWS Glue
Queste sezioni descrivono le integrazioni con il registro degli schemi di AWS Glue. Gli esempi riportati in questa sezione mostrano uno schema con formato di dati AVRO. Per altri esempi, inclusi schemi con formato di dati JSON, consulta i test di integrazione e ReadMe le informazioni nel repository open source di Schema Registry. AWS Glue
Argomenti
Caso d'uso: connessione del registro degli schemi ad Amazon MSK o Apache Kafka
Supponiamo che tu stia scrivendo dati su un argomento Apache Kafka e che possa seguire questi passaggi per iniziare.
Crea un cluster Amazon Streaming gestito per Apache Kafka (Amazon MSK) o Apache Kafka con almeno un argomento. Se si crea un cluster Amazon MSK, è possibile utilizzare il Console di gestione AWS. Segui queste istruzioni: Nozioni di base per l'uso di Amazon MSK nella Guida per gli sviluppatori di Amazon Managed Streaming for Apache Kafka.
Segui il passaggio Installazione delle SerDe librerie sopra.
Per creare registri dello schema, schemi o versioni, segui le istruzioni riportate nella sezione Guida introduttiva al registro degli schemi di questo documento.
Inizia i tuoi produttori e consumatori a utilizzare lo Schema Registry per scrivere e leggere record to/from sull'argomento Amazon MSK o Apache Kafka. È possibile trovare esempi di codice per produttori e consumatori nel ReadMe file delle librerie Serde
. La libreria del registro degli schemi del produttore serializzerà automaticamente il record e aggiungerà un ID della versione dello schema al record. Se lo schema di questo record è stato inserito o se la registrazione automatica è attivata, lo schema risulterà registrato nel registro degli schemi.
Il consumer che legge dall'argomento Amazon MSK o Apache Kafka, utilizzando la libreria del registro degli schemi di AWS Glue, cercherà automaticamente lo schema dal registro degli schemi.
Caso d'uso: integrazione del flusso di dati Amazon Kinesis con il registro degli schemi di AWS Glue
Per questa integrazione è necessario disporre di un flusso dei dati Amazon Kinesis. Per ulteriori informazioni, consulta Nozioni di base su Amazon Kinesis Data Streams nella Guida per gli sviluppatori di Amazon Kinesis Data Streams.
Esistono due modi per interagire con i dati in un flusso dei dati Kinesis.
Tramite le librerie Kinesis Producer Library (KPL) e Kinesis Client Library (KCL) in Java. Il supporto multilingue non viene fornito.
Tramite
PutRecordsPutRecord, eGetRecordsKinesis APIs Data Streams disponibile in. AWS SDK per Java
Se attualmente utilizzi le KPL/KCL librerie, ti consigliamo di continuare a utilizzare quel metodo. Come mostrato negli esempi, esistono versioni KCL e KPL aggiornate con il registro degli schemi integrato. Altrimenti, puoi usare il codice di esempio per sfruttare lo AWS Glue Schema Registry se usi direttamente il KDS. APIs
L'integrazione del registro degli schemi è disponibile solo con KPL v0.14.2 o versioni successive e con KCL v2.3 o versioni successive. L'integrazione del registro degli schemi con il formato di dati JSON è disponibile solo con KPL v0.14.8 o versioni successive e con KCL v2.3.6 o versioni successive.
Interazione con i dati utilizzando Kinesis SDK V2
Questa sezione descrive l'interazione con Kinesis utilizzando Kinesis SDK V2
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Interazione con i dati utilizzando le librerie KPL/KCL
Questa sezione descrive l'integrazione di Kinesis Data Streams con Schema Registry utilizzando le librerie. KPL/KCL Per ulteriori informazioni sull'utilizzo di KPL/KCL, consulta Sviluppo di produttori utilizzando Amazon Kinesis Producer Library nella Guida per gli sviluppatori di Amazon Kinesis Data Streams.
Impostazione del registro degli schemi in KPL
Definisci la definizione dello schema per i dati, il formato dei dati e il nome dello schema creati nel registro degli schemi di AWS Glue.
Facoltativamente, puoi configurare l'oggetto
GlueSchemaRegistryConfiguration.Trasferisci l'oggetto dello schema a
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Impostazione della libreria client di Kinesis
Svilupperai un consumer Kinesis Client Library in Java. Per ulteriori informazioni su, consulta Sviluppo di app Consumer Kinesis Client Library in Java nella Guida per gli sviluppatori di Amazon Kinesis Data Streams.
Crea un'istanza di
GlueSchemaRegistryDeserializerpassando un oggettoGlueSchemaRegistryConfiguration.Passa
GlueSchemaRegistryDeserializeraretrievalConfig.glueSchemaRegistryDeserializer.Accedi allo schema dei messaggi in arrivo chiamando
kinesisClientRecord.getSchema().GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Interazione con i dati utilizzando Kinesis Data Streams APIs
Questa sezione descrive l'integrazione di Kinesis Data Streams con Schema Registry utilizzando Kinesis Data Streams. APIs
Aggiorna queste dipendenze di Maven:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>Nel produttore, aggiungi le informazioni sull'intestazione dello schema utilizzando il l'API
PutRecordsoPutRecordin Kinesis Data Streams.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);Nel produttore, utilizza l'API
PutRecordsoPutRecordper inserire il record nel flusso dei dati.Nel consumer, rimuovi il record dello schema dall'intestazione e serializza un record dello schema Avro.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Interazione con i dati utilizzando Kinesis Data Streams APIs
Di seguito è riportato un codice di esempio per l'utilizzo di and. PutRecords GetRecords APIs
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Caso d'uso: Servizio gestito da Amazon per Apache Flink
Apache Flink è un diffuso framework open source e motore di elaborazione distribuito per calcoli con stato su flussi dei dati illimitati e limitati. Amazon Managed Service per Apache Flink è un AWS servizio completamente gestito che consente di creare e gestire applicazioni Apache Flink per elaborare dati di streaming.
Apache Flink open source fornisce una serie di origini e sink. Ad esempio, le origini dati predefinite includono la lettura da file, directory e socket e l'inserimento di dati da raccolte e iteratori. I DataStream connettori Apache Flink forniscono codice per consentire ad Apache Flink di interfacciarsi con vari sistemi di terze parti, come Apache Kafka o Kinesis, come sorgenti. and/or
Per ulteriori informazioni, consulta la Guida per sviluppatori di Amazon Kinesis Data Analytics.
Connettore Apache Flink Kafka
Apache Flink fornisce un connettore per flusso dei dati Apache Kafka per la lettura e la scrittura di dati su argomenti Kafka con garanzie exactly-once. Il consumer Kafka di Flink, FlinkKafkaConsumer, fornisce l'accesso alla lettura da uno o più argomenti di Kafka. Il produttore Kafka di Apache Flink, FlinkKafkaProducer, consente di scrivere un flusso di record su uno o più argomenti Kafka. Per ulteriori informazioni, consulta Apache Kafka Connector
Connettore di flussi Apache Flink Kinesis
Il connettore del flusso dei dati Kinesis consente di accedere ai Amazon Kinesis Data Streams. FlinkKinesisConsumerSi tratta di una fonte di dati di streaming parallela che utilizza una sola volta per abbonarsi a più flussi Kinesis all'interno della stessa area di AWS servizio e può gestire in modo trasparente il ripartizionamento dei flussi mentre il processo è in esecuzione. Ogni sottoattività del consumer è responsabile del recupero dei record di dati da più partizioni Kinesis. Il numero di partizioni recuperate da ogni sottoattività cambierà man mano che le partizioni vengono chiuse e create da Kinesis. FlinkKinesisProducer utilizza Kinesis Producer Library (KPL) per inserire i dati da un flusso Apache Flink in un flusso Kinesis. Per ulteriori informazioni, consulta Amazon Kinesis Streams Connector
Per ulteriori informazioni, consulta il AWS Gluerepository Github di schema
Integrazione con Apache Flink
La SerDes libreria fornita con Schema Registry si integra con Apache Flink. Per utilizzare Apache Flink, sarà necessario implementare le interfacce SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema e GlueSchemaRegistryAvroDeserializationSchema, che possono essere collegate ai connettori Apache Flink.
Aggiunta di una dipendenza del registro degli schemi di AWS Glue nell'applicazione Apache Flink
Per impostare le dipendenze di integrazione sul registro degli schemi di AWS Glue nell'applicazione Apache Flink:
Aggiungi la dipendenza al file
pom.xml.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Integrazione di Kafka o Amazon MSK con Apache Flink
È possibile usare Servizio gestito da Amazon per Apache Flink per Apache Flink con Kafka come origine o Kafka come sink.
Kafka come fonte
Il diagramma seguente mostra l'integrazione di Flusso di dati Kinesis con Servizio gestito da Amazon per Apache Flink per Apache Flink, con Kafka come origine.
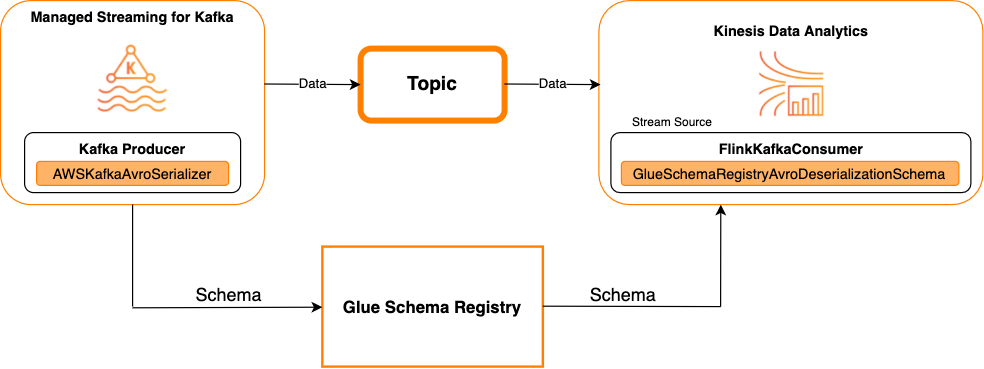
Kafka come sink
Il diagramma seguente mostra l'integrazione di Flusso di dati Kinesis con Servizio gestito da Amazon per Apache Flink per Apache Flink, con Kafka come sink.
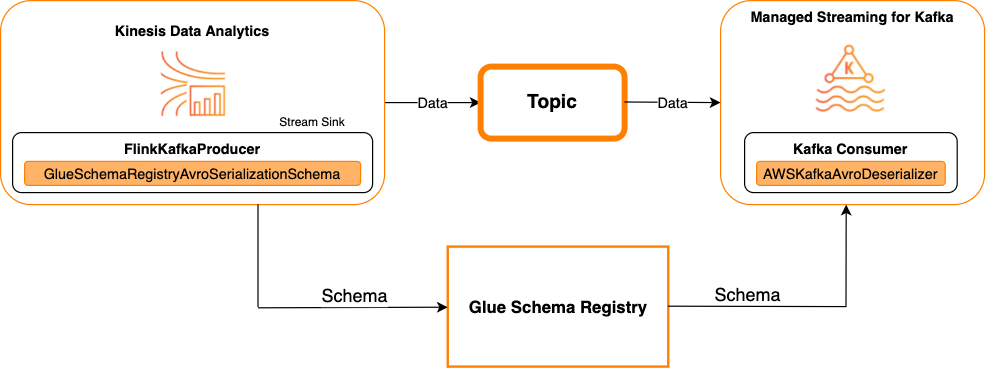
Per integrare Kafka (o Amazon MSK) con Servizio gestito da Amazon per Apache Flink per Apache Flink, con Kafka come origine o Kafka come sink, apporta le modifiche al codice riportate di seguito. Aggiungi i blocchi di codice in grassetto al codice corrispondente nelle sezioni analoghe.
Se Kafka è la fonte, utilizza il codice deserializzatore (blocco 2). Se Kafka è il sink, utilizza il codice serializzatore (blocco 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Integrazione di Kinesis Data Streams con Apache Flink
È possibile utilizzare Servizio gestito da Amazon per Apache Flink per Apache Flink con Flusso di dati Kinesis come origine o sink.
Kinesis Data Streams come fonte
Il diagramma seguente mostra l'integrazione di Flusso di dati Kinesis con Servizio gestito per Apache Flink per Apache Flink, con Flusso di dati Kinesis come origine.
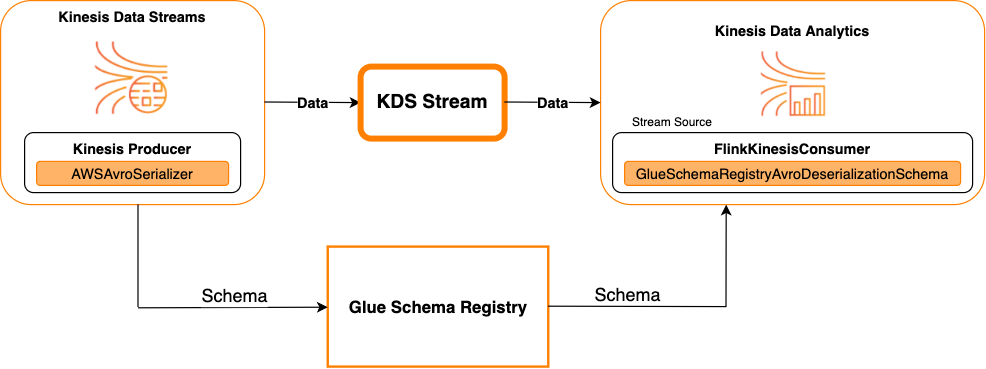
Kinesis Data Streams come sink
Il diagramma seguente mostra l'integrazione di Flusso di dati Kinesis con Servizio gestito per Apache Flink per Apache Flink, con Flusso di dati Kinesis come sink.
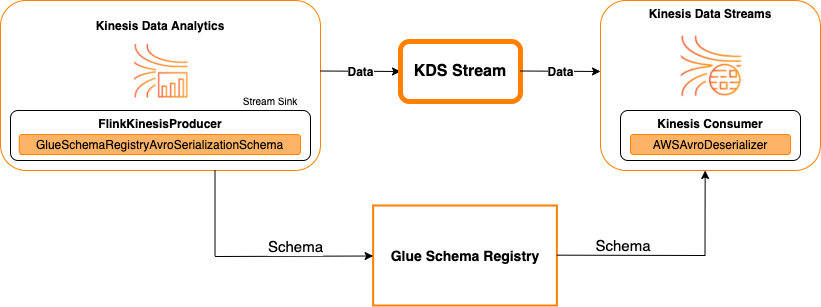
Per integrare Flusso di dati Kinesis con Servizio gestito per Apache Flink per Apache Flink, con Flusso di dati Kinesis come origine o Flusso di dati Kinesis come sink, apporta le modifiche al codice riportate di seguito. Aggiungi i blocchi di codice in grassetto al codice corrispondente nelle sezioni analoghe.
Se Kinesis Data Streams è l'origine, utilizza il codice deserializzatore (blocco 2). Se Kinesis Data Streams il sink, utilizza il codice serializzatore (blocco 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Caso d'uso: integrazione con AWS Lambda
Caso d'uso: AWS Glue Data Catalog
Le tabelle AWS Glue supportano gli schemi che è possibile specificare manualmente o facendo riferimento al registro degli schemi di AWS Glue. Il registro degli schemi si integra con il catalogo dati per consentire l'utilizzo facoltativo degli schemi memorizzati nel registro degli schemi durante la creazione o l'aggiornamento di tabelle o partizioni AWS Glue nel catalogo dati. Per identificare una definizione dello schema nel registro degli schemi, è necessario conoscere almeno l'ARN dello schema di cui fa parte. Una versione di uno schema, che contiene una definizione dello schema, può essere referenziata dal relativo UUID o numero di versione. C'è sempre una versione dello schema, la versione "più recente", che può essere cercata senza conoscere il suo numero di versione o UUID.
Chiamando le operazioni CreateTable o UpdateTable, passerai una struttura TableInput che contiene un StorageDescriptor, che può avere un SchemaReference a uno schema esistente nel registro degli schemi. Allo stesso modo, quando si chiama GetTable o GetPartition APIs, la risposta può contenere lo schema e ilSchemaReference. Quando una tabella o una partizione è stata creata utilizzando riferimenti allo schema, il catalogo dati tenterà di recuperare lo schema per questo riferimento. Nel caso in cui non sia in grado di trovare lo schema nel registro degli schemi, restituisce uno schema vuoto nella risposta GetTable; in caso contrario, la risposta conterrà sia lo schema che il riferimento allo schema.
Puoi eseguire le seguenti operazioni dalla console AWS Glue.
Per eseguire queste operazioni e creare, aggiornare o visualizzare le informazioni sullo schema, è necessario assegnare un ruolo IAM all'utente chiamante che fornisce le autorizzazioni per l'API GetSchemaVersion.
Aggiunta di una tabella o aggiornamento dello schema di una tabella
L'aggiunta di una nuova tabella da uno schema esistente associa la tabella a una versione specifica dello schema. Una volta registrate le nuove versioni dello schema, è possibile aggiornare la definizione della tabella dalla pagina View table (Visualizza tabella) nella console AWS Glue o utilizzando l'API UpdateTable azione (Python: update_table).
Aggiunta di una tabella da uno schema esistente
Puoi creare una tabella AWS Glue da una versione dello schema nel registro utilizzando la console AWS Glue o l'API CreateTable.
API AWS Glue
Chiamando l'API CreateTable, passerai un TableInput che contiene una StorageDescriptor, che può avere un SchemaReference a uno schema esistente nel registro degli schemi.
Console AWS Glue
Per creare una tabella dalla consoleAWS Glue:
-
Accedi a Console di gestione AWS e apri la AWS Glue console all'indirizzo https://console.aws.amazon.com/glue/
. Nel pannello di navigazione, in Data catalog (Catalogo dati), seleziona Tables (Tabelle).
Nel menu Add Tables (Aggiungi tabelle), scegli Add table from existing schema (Aggiungi tabella da schema esistente).
Configura le proprietà della tabella e il datastore come indicato nella Guida per gli sviluppatori di AWS Glue.
Nella pagina Choose a Glue schema (Scegli uno schema di Glue), seleziona il Registry (Registro) in cui si trova lo schema.
Scegli Schema name (Nome schema) e seleziona la Version (Versione) dello schema da applicare.
Esamina l'anteprima dello schema e scegli Next (Successivo).
Rivedi e crea la tabella.
Lo schema e la versione applicati alla tabella vengono visualizzati nella colonna Glue schema (Schema di Glue) nell'elenco delle tabelle. È possibile visualizzare la tabella per vedere ulteriori dettagli.
Aggiornamento dello schema per una tabella
Quando una nuova versione dello schema diventa disponibile, si consiglia di aggiornare lo schema di una tabella utilizzando l'API UpdateTable azione (Python: update_table) o la console AWS Glue.
Importante
Aggiornando lo schema per una tabella esistente con uno schema AWS Glue specificato manualmente, il nuovo schema a cui si fa riferimento nel registro degli schemi potrebbe essere incompatibile. Questo potrebbe comportare la non riuscita dei processi.
API AWS Glue
Chiamando l'API UpdateTable, passerai un TableInput che contiene una StorageDescriptor, che può avere un SchemaReference a uno schema esistente nel registro degli schemi.
Console AWS Glue
Per aggiornare lo schema di una tabella dalla console AWS Glue:
-
Accedi a Console di gestione AWS e apri la AWS Glue console all'indirizzo https://console.aws.amazon.com/glue/
. Nel pannello di navigazione, in Data catalog (Catalogo dati), seleziona Tables (Tabelle).
Visualizza la tabella nell'elenco delle tabelle.
Fai clic su Update schema (Aggiorna schema) nella casella che ti informa di una nuova versione.
Esamina le differenze tra lo schema attuale e quello nuovo.
Scegli Show all schema differences (Mostra tutte le differenze di schema) per ulteriori dettagli.
Scegli Save table (Salva tabella) per accettare la nuova versione.
Caso d'uso: streaming AWS Glue
Lo streaming AWS Glue consuma dati provenienti da fonti di streaming ed esegue operazioni ETL prima di scrivere su un sink di output. L'origine di streaming di input può essere specificata utilizzando una tabella dati o direttamente specificando la configurazione di origine.
Lo streaming AWS Glue supporta una tabella del catalogo dati per la sorgente di streaming creata con lo schema presente nel Registro degli schemi di AWS Glue. È possibile creare uno schema nel Registro degli schemi di AWS Glue e creare una tabella AWS Glue con una sorgente di streaming utilizzando questo schema. Questa tabella AWS Glue può essere utilizzata come input per un processo di streaming AWS Glue per la deserializzazione dei dati nel flusso di input.
Un punto da notare qui è quando lo schema nel Registro degli schemi AWS Glue cambia, è necessario riavviare il processo di streaming AWS Glue in modo da riflettere i cambiamenti nello schema.
Caso d'uso: flussi Apache Kafka
L'API di Apache Kafka Streams è una libreria client per l'elaborazione e l'analisi dei dati memorizzati in Apache Kafka. Questa sezione descrive l'integrazione di Apache Kafka Streams con il registro degli schemi di AWS Glue, che consente di gestire e applicare gli schemi sulle applicazioni di streaming di dati. Per ulteriori informazioni su Apache Kafka Streams, consulta Apache Kafka Streams
Integrazione con le librerie SerDes
Esiste una classe di GlueSchemaRegistryKafkaStreamsSerde con cui è possibile configurare un'applicazione Streams.
Codice di esempio di applicazione di flussi Kafka
Per utilizzare il registro degli schemi di AWS Glue all'interno di un'applicazione Apache Kafka Streams:
Configura l'applicazione Kafka Streams.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Crea un flusso dall'argomento avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Elabora i record di dati (nell'esempio vengono filtrati i record il cui valore favorite_color è rosa o in cui il valore amount è 15).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Scrivi i risultati nell'argomento avro-output.
result.to("avro-output");Avvia l'applicazione Apache Kafka Streams.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Risultati dell'implementazione
Questi risultati mostrano il processo di filtraggio dei record che sono stati filtrati nel passaggio 3 in base a favorite_color come "rosa" o valore come "15.0".
Record prima del filtraggio:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Record dopo il filtraggio:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Caso d'uso: Apache Kafka Connect
L'integrazione di Apache Kafka Connect con il registro degli schemi di AWS Glue consente di ottenere informazioni sullo schema dai connettori. I convertitori Apache Kafka specificano il formato dei dati all'interno di Apache Kafka e come tradurli in dati Apache Kafka Connect. Ogni utente di Apache Kafka Connect dovrà configurare questi convertitori in base al formato desiderato dei dati quando vengono caricati o memorizzati in Apache Kafka. In questo modo, è possibile definire i propri convertitori per tradurre i dati di Apache Kafka Connect nel tipo utilizzato nel registro degli schemi di AWS Glue (ad esempio: Avro) e utilizzare il nostro serializzatore per registrare il suo schema ed eseguire la serializzazione. I convertitori sono anche in grado di utilizzare il nostro deserializzatore per deserializzare i dati ricevuti da Apache Kafka e convertirli nuovamente in dati Apache Kafka Connect. Di seguito è riportato un diagramma di flusso di lavoro di esempio.
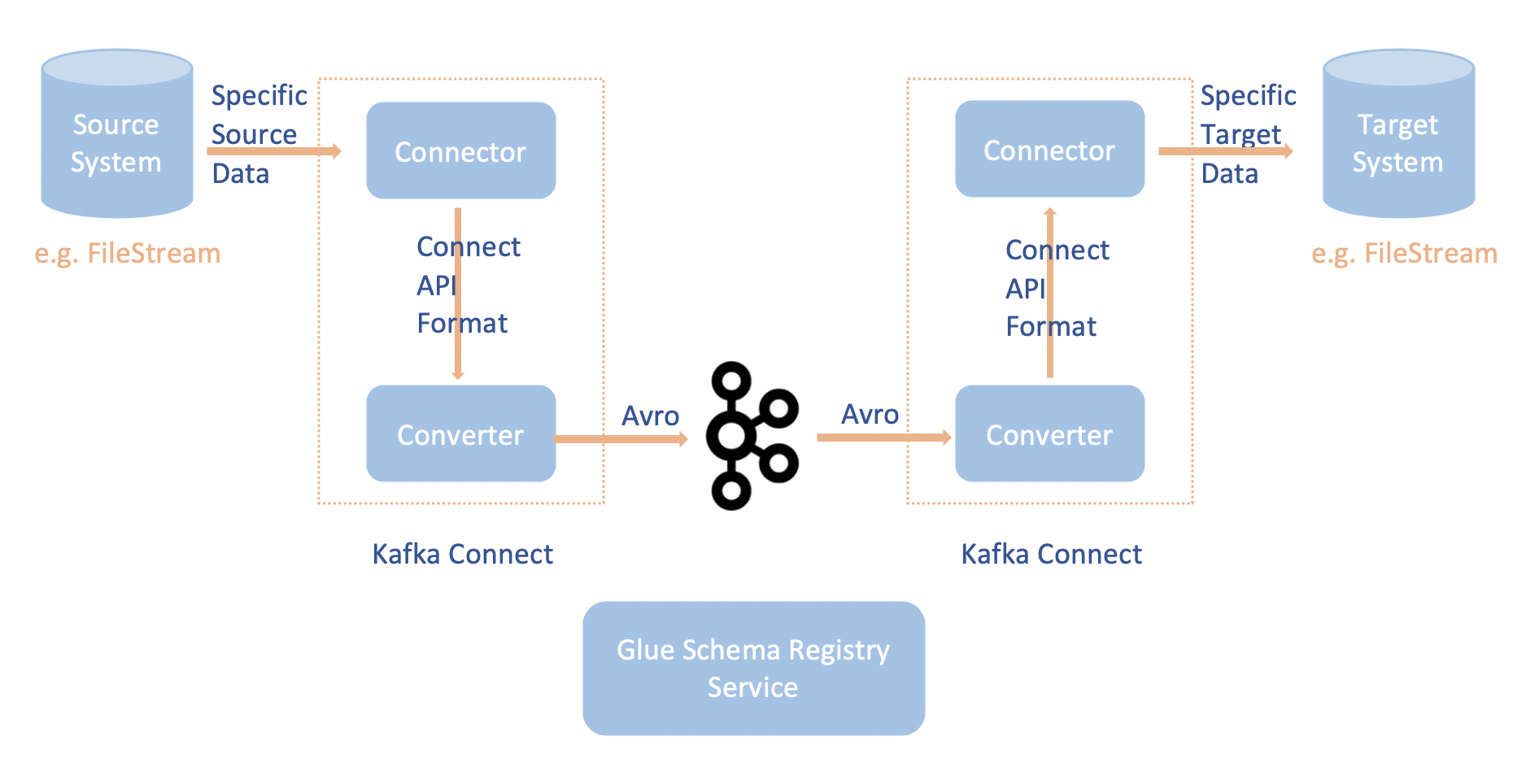
Installare del progetto
aws-glue-schema-registrycon la clonazione del repository Github per il registro degli schemi di AWS Glue. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesSe hai intenzione di utilizzare Apache Kafka Connect in modalità standalone, aggiorna connect-standalone.properties seguendo le istruzioni di seguito per questo passaggio. Se prevedi di utilizzare Apache Kafka Connect in modalità distribuita, connect-avro-distributedaggiorna .properties seguendo le stesse istruzioni.
Aggiungi queste proprietà anche al file delle proprietà di Apache Kafka connect:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDAggiungi il comando seguente alla sezione Launch mode in .sh: kafka-run-class
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Aggiungi il comando seguente alla sezione Launch mode in .sh kafka-run-class
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"L'URL dovrebbe essere simile a questo:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiSe usi bash, esegui i seguenti comandi per configurare il tuo CLASSPATH nel bash_profile. Per qualsiasi altra shell, aggiorna l'ambiente di conseguenza.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Facoltativo) Se vuoi eseguire il test con un'origine file semplice, clona il connettore dell'origine file.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/Sotto la configurazione del connettore di origine, modifica il formato dei dati in Avro, il lettore di file in
AvroFileReadere aggiorna un oggetto Avro di esempio dal percorso del file da cui stai leggendo. Ad esempio:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstalla il connettore di origine.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profileAggiorna le proprietà del sink in
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Avvia il connettore di origine (in questo esempio si tratta di un connettore dell'origine file).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesEsegui il connettore sink (in questo esempio si tratta di un connettore sink di file).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesPer un esempio di utilizzo di Kafka Connect, guarda lo run-local-tests script.sh nella cartella integration-tests nel repository Github
per lo Schema Registry. AWS Glue
