Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio con AWS Glue Parametri di osservabilità
Nota
I parametri di osservabilità AWS Glue sono disponibili in AWS Glue 4.0 e versioni successive.
Utilizza i parametri AWS Glue di osservabilità per generare approfondimenti su ciò che accade all'interno di AWS Glue per i processi di Apache Spark e migliorare la classificazione e l'analisi dei problemi. I parametri di osservabilità vengono visualizzati tramite i pannelli di controllo Amazon CloudWatch e possono essere utilizzati per aiutare a eseguire l'analisi delle cause principali degli errori e diagnosticare i rallentamenti delle prestazioni. È possibile ridurre il tempo impiegato per il debug dei problemi su larga scala così da poterti concentrare sulla risoluzione dei problemi in modo più rapido ed efficace.
AWS GlueL'osservabilità fornisce Amazon CloudWatch metriche classificate nei seguenti quattro gruppi:
-
Affidabilità (ad esempio, classi di errori): identifica facilmente i motivi di errore più comuni in un determinato intervallo di tempo che potresti voler risolvere.
-
Prestazioni (ad esempio, asimmetria): individua un ostacolo prestazionale e applica tecniche di ottimizzazione. Ad esempio, quando riscontri un peggioramento delle prestazioni a causa dell'asimmetria del processo, potresti voler abilitare l'esecuzione delle query adattive Spark e ottimizzare la soglia di unione skew.
-
Throughput (ovvero, per source/sink throughput): monitora le tendenze delle letture e scritture dei dati. Puoi anche configurare Amazon CloudWatch allarmi per anomalie.
-
Utilizzo delle risorse (ad esempio, personale, utilizzo della memoria e del disco): individuazione efficiente dei processi con un basso utilizzo della capacità. Potresti voler abilitare il dimensionamento automatico AWS Glue per questi processi.
Nozioni di base su AWS Glue Parametri di osservabilità
Nota
I nuovi parametri sono abilitati per impostazione predefinita nella console AWS Glue Studio.
Per configurare le metriche di osservabilità in AWS Glue Studio:
-
Accedi alla console AWS Glue e scegli processi ETL dal menu della console.
-
Scegli un processo facendo clic sul suo nome nella sezione I tuoi processi.
-
Seleziona la scheda Job details (Dettagli del processo).
-
Scorri verso il basso e scegli Proprietà avanzate, quindi Parametri di osservabilità del processo.
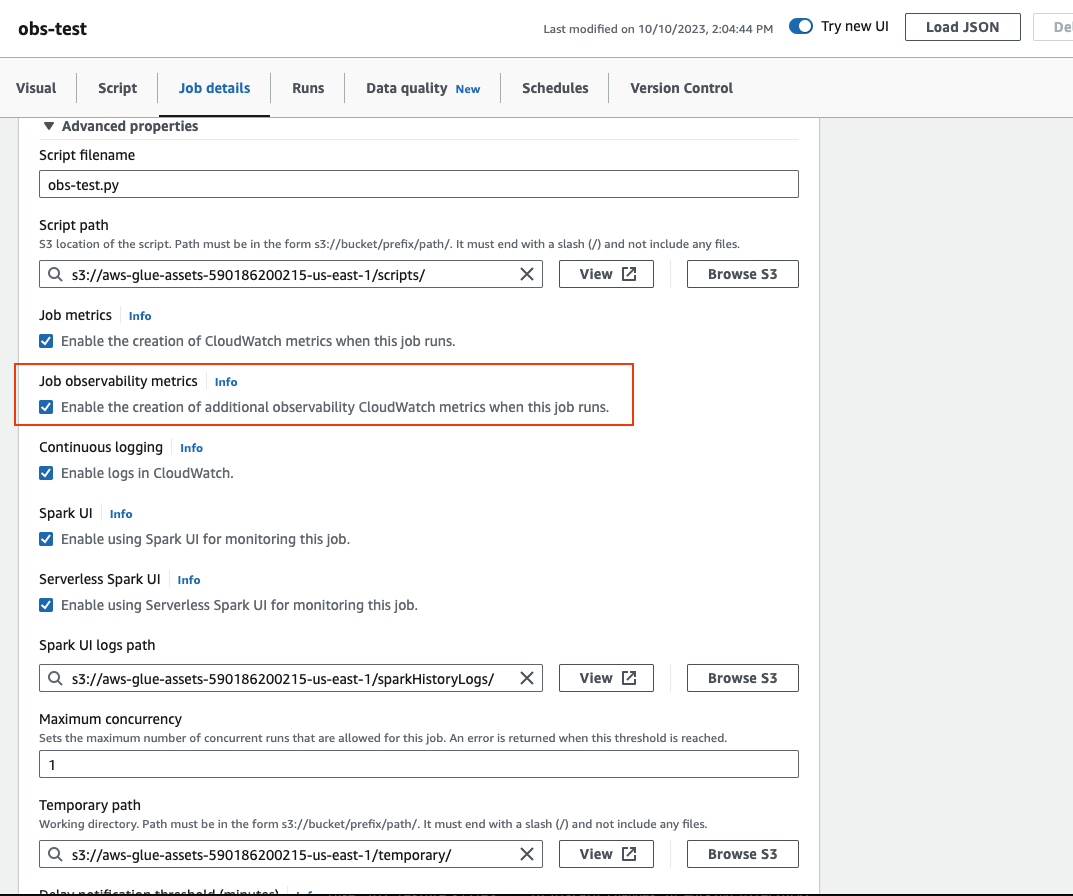
Per abilitare AWS Glue Metriche di osservabilità utilizzando AWS CLI:
-
Aggiungi alla mappa
--default-argumentsil seguente valore-chiave nel file JSON di input:--enable-observability-metrics, true
Utilizzo AWS Glue osservabilità
Poiché le metriche AWS Glue di osservabilità vengono fornite tramite Amazon CloudWatch, puoi utilizzare la Amazon CloudWatch console, l'SDK o l'API per interrogare i AWS CLI datapoint delle metriche di osservabilità. Consulta Utilizzo dell'osservabilità Glue per monitorare l'utilizzo delle risorse per ridurre i costi
Utilizzo AWS Glue osservabilità in Amazon CloudWatch console
Per interrogare e visualizzare le metriche in Amazon CloudWatch console:
-
Apri la Amazon CloudWatch console e scegli Tutte le metriche.
-
In Spazi dei nomi personalizzati, seleziona AWS Glue.
-
Scegli Parametri di osservabilità del processo, Parametri di osservabilità per origine oppure Parametri di osservabilità per Sink.
-
Cerca il nome specifico del parametro, il nome del processo, l'ID di esecuzione del processo e selezionali.
-
Nella scheda Parametri nel grafico, configura la statistica, il periodo e altre opzioni che preferisci.
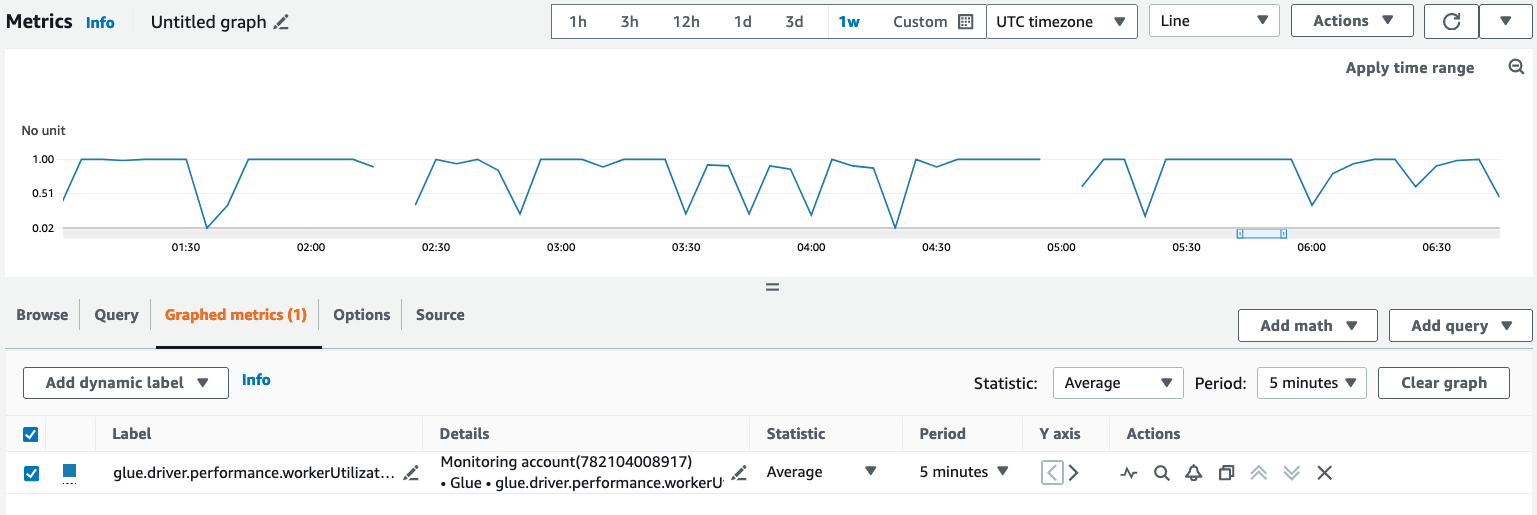
Per interrogare una metrica di osservabilità utilizzando AWS CLI:
-
Crea un file JSON di definizione dei parametri e sostituisci
your-Glue-job-nameeyour-Glue-job-run-idcon quelli pertinenti.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
Eseguire il comando
get-metric-data:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
Parametri di osservabilità
AWS GlueL'osservabilità profila e invia le seguenti metriche Amazon CloudWatch ogni 30 secondi e alcune di queste metriche possono essere visibili nella pagina AWS Glue Studio Job Runs Monitoring.
| Metrica | Description | Categoria |
|---|---|---|
| glue.driver.skewness.stage |
Categoria parametro: job_performance Indice di asimmetria di esecuzione delle fasi spark: questa metrica è un indicatore della durata massima dell'attività in una determinata fase rispetto alla durata media dell'attività in questa fase. Rileva l'asimmetria di esecuzione, che potrebbe essere causata dall'asimmetria dei dati di input o da una trasformazione (ad es. join asimmetrico). I valori di questo parametro rientrano nell'intervallo [0, infinito], dove 0 indica il rapporto tra il tempo di esecuzione massimo e quello medio delle attività. Tra tutte le attività nella fase, è inferiore a un determinato fattore di asimmetria della stessa. Il fattore di asimmetria dello stadio predefinito è `5` e può essere sovrascritto tramite spark conf: spark.metrics.conf.driver.source.glue.job Performance.skewnessFactor Un valore di asimmetria della fase pari a 1 significa che il rapporto è il doppio del fattore di asimmetria della fase. Il valore dell'asimmetria della fase viene aggiornato ogni 30 secondi per riflettere l'asimmetria corrente. Il valore alla fine della fase riflette l'asimmetria della fase finale. Questa metrica a livello di fase viene utilizzata per calcolare la metrica a livello di lavoro Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (job_performance) Statistiche valide: media, massimo, minimo, percentuale Unità: numero |
job_performance |
| glue.driver.skewness.job |
Categoria parametro: job_performance L'asimmetria del lavoro è l'asimmetria ponderata massima di tutte le fasi. L'asimmetria della fase (glue.driver.skewness.stage) viene ponderata in base alla durata della fase. In questo modo si evita il caso limite in cui una fase molto asimmetrica viene eseguita per un periodo molto breve rispetto ad altre fasi (quindi la sua asimmetria non è significativa per le prestazioni complessive del processo e non vale la pena cercare di correggerla). Questo parametro viene aggiornato al completamento di ogni fase, perciò l'ultimo valore riflette l'effettiva asimmetria complessiva del processo. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (job_performance) Statistiche valide: media, massimo, minimo, percentuale Unità: numero |
job_performance |
| glue.succeed.ALL |
Categoria parametro: errore Numero totale di processi eseguiti con successo, per completare il quadro delle categorie di errori Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (count) e ObservabilityGroup (error) Statistiche valide: SOMMA Unità: numero |
error |
| glue.error.ALL |
Categoria parametro: errore Numero totale di errori di esecuzione del processo, per completare il quadro delle categorie di errori Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (count) e ObservabilityGroup (error) Statistiche valide: SOMMA Unità: numero |
error |
| glue.error.[error category] |
Categoria parametro: errore Questo insieme di parametri viene aggiornato solo se l'esecuzione di un processo fallisce. La categorizzazione degli errori facilita la classificazione e il debug. Quando l'esecuzione di un processo fallisce, la causa dell'errore viene classificata e il parametro della categoria di errore corrispondente viene impostato su 1. Ciò consente di eseguire l'analisi degli errori nel corso tempo, nonché quella relativa a tutti i processi, per identificare le categorie di errore più comuni e risolverle. AWS Glue include 28 categorie di errore, tra cui OUT_OF_MEMORY (driver ed executor), AUTORIZZAZIONE, SINTASSI e LIMITAZIONE (DELLA LARGHEZZA DI BANDA DELLA RETE). Le categorie di errore includono anche COMPILAZIONE, AVVIO e TIMEOUT. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (count) e ObservabilityGroup (error) Statistiche valide: SOMMA Unità: numero |
error |
| glue.driver.workerUtilization |
Categoria parametro: resource_utilization La percentuale dei worker allocati che vengono effettivamente utilizzati. Se non va bene, può essere utile il dimensionamento automatico. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media, massimo, minimo, percentuale Unità: percentuale |
resource_utilization |
| glue.driver.memory.heap.[available | used] |
Categoria parametro: resource_utilization La memoria heap del driver disponibile/utilizzata durante l'esecuzione del processo. Ciò è utile per comprendere le tendenze di utilizzo della memoria, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguirne il debug. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: byte |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
Categoria parametro: resource_utilization La memoria heap del driver utilizzata (%) durante l'esecuzione del processo. Ciò è utile per comprendere le tendenze di utilizzo della memoria, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguirne il debug. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| glue.driver.memory.non-heap.[available | used] |
Categoria parametro: resource_utilization La memoria non heap del driver disponibile/utilizzata durante l'esecuzione del processo. Ciò è utile per comprendere le tendenze di utilizzo della memoria, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguirne il debug. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: byte |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
Categoria parametro: resource_utilization La memoria non heap del driver utilizzata (%) durante l'esecuzione del processo. Ciò è utile per comprendere le tendenze di utilizzo della memoria, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguirne il debug. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| glue.driver.memory.total.[available | used] |
Categoria parametro: resource_utilization La memoria totale del driver disponibile/utilizzata durante l'esecuzione del processo. Ciò è utile per comprendere le tendenze di utilizzo della memoria, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguirne il debug. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: byte |
resource_utilization |
| glue.driver.memory.total.used.percentage |
Categoria parametro: resource_utilization La memoria totale del driver utilizzata (%) durante l'esecuzione del processo. Ciò è utile per comprendere le tendenze di utilizzo della memoria, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguirne il debug. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| colla. ALL.memory.heap. [disponibile | usato] |
Categoria parametro: resource_utilization La memoria available/used heap degli esecutori. ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: byte |
resource_utilization |
| colla. ALL.memory.heap.used.percentage |
Categoria parametro: resource_utilization La memoria heap degli executor utilizzata (%). ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| colla. ALL.memory.non-heap. [disponibile | usato] |
Categoria parametro: resource_utilization La memoria non heap degli available/used esecutori. ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: byte |
resource_utilization |
| colla. ALL.memory.non-heap.used.percentage |
Categoria parametro: resource_utilization La memoria non heap degli executor utilizzata (%). ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| colla. ALL.memory.total. [disponibile | usato] |
Categoria parametro: resource_utilization La memoria available/used totale degli esecutori. ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: byte |
resource_utilization |
| colla. ALL.memory.total.used.percentage |
Categoria parametro: resource_utilization La memoria totale degli executor utilizzata (%). ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| glue.driver.disk.[available_GB | used_GB] |
Categoria parametro: resource_utilization Lo spazio su disco del driver durante l'esecuzione del processo. available/used Ciò è utile per comprendere le tendenze di utilizzo del disco, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguire il debug di quelli relativi alla presenza di spazio non sufficiente sul disco. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: gigabyte |
resource_utilization |
| glue.driver.disk.used.percentage] |
Categoria parametro: resource_utilization Lo spazio su disco del driver durante l'esecuzione del processo. available/used Ciò è utile per comprendere le tendenze di utilizzo del disco, soprattutto nel tempo, il che può contribuire a evitare potenziali errori e a eseguire il debug di quelli relativi alla presenza di spazio non sufficiente sul disco. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| colla. ALL.disk. [Available_GB | Used_GB] |
Categoria parametro: resource_utilization Lo spazio su available/used disco degli esecutori. ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: gigabyte |
resource_utilization |
| colla. ALL.disk.used.percentage |
Categoria parametro: resource_utilization Lo spazio su disco available/used /usato (%) degli esecutori. ALL significa tutti gli executor. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge) e ObservabilityGroup (resource_utilization) Statistiche valide: media Unità: percentuale |
resource_utilization |
| glue.driver.bytesRead |
Categoria parametro: velocità di trasmissione effettiva Il numero di byte letti per ogni origine di input in questa esecuzione del processo e per TUTTE le origini. È possibile così comprendere il volume dei dati e le relative variazioni nel tempo, il che consente di risolvere problemi come l'asimmetria dei dati. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge), (resource_utilization) e Source ObservabilityGroup (posizione dei dati di origine) Statistiche valide: media Unità: byte |
velocità di trasmissione effettiva |
| glue.driver.[recordsRead | filesRead] |
Categoria parametro: velocità di trasmissione effettiva Il numero di records/files letture per sorgente di input in questo processo e per TUTTE le fonti. È possibile così comprendere il volume dei dati e le relative variazioni nel tempo, il che consente di risolvere problemi come l'asimmetria dei dati. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge), (resource_utilization) e Source ObservabilityGroup (posizione dei dati di origine) Statistiche valide: media Unità: numero |
velocità di trasmissione effettiva |
| glue.driver.partitionsRead |
Categoria parametro: velocità di trasmissione effettiva Il numero di partizioni lette per ogni origine di input di Amazon S3 in questa esecuzione del processo e per TUTTE le origini. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge), (resource_utilization) e Source ObservabilityGroup (posizione dei dati di origine) Statistiche valide: media Unità: numero |
velocità di trasmissione effettiva |
| glue.driver.bytesWrittten |
Categoria parametro: velocità di trasmissione effettiva Il numero di byte scritti per ogni sink di output in questa esecuzione del processo e per TUTTI i sink. È possibile così comprendere il volume dei dati e il modo in cui evolve nel tempo, il che consente di risolvere problemi come l'asimmetria dell'elaborazione. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge), (resource_utilization) e Sink ObservabilityGroup (posizione dei dati del sink) Statistiche valide: media Unità: byte |
velocità di trasmissione effettiva |
| glue.driver.[recordsWritten | filesWritten] |
Categoria parametro: velocità di trasmissione effettiva Il numero di sink records/files scritti per uscita in questa esecuzione di processo e per TUTTI i sink. È possibile così comprendere il volume dei dati e il modo in cui evolve nel tempo, il che consente di risolvere problemi come l'asimmetria dell'elaborazione. Dimensioni valide: JobName (il nome del AWS Glue Job), JobRunId ( JobRun ID. o ALL), Type (gauge), (resource_utilization) e Sink ObservabilityGroup (posizione dei dati del sink) Statistiche valide: media Unità: numero |
velocità di trasmissione effettiva |
Categorie di errore
| Categorie di errore | Description |
|---|---|
| COMPILATION_ERROR | Gli errori si verificano durante la compilazione del codice Scala. |
| CONNECTION_ERROR | Si verificano errori durante la connessione a un servizio, ecc. service/remote host/database |
| DISK_NO_SPACE_ERROR |
Gli errori si verificano quando non c'è più spazio su disco driver/executor. |
| OUT_OF_MEMORY_ERROR | Gli errori si verificano quando non c'è più spazio in memoria driver/executor. |
| IMPORT_ERROR | Gli errori si verificano durante l'importazione delle dipendenze. |
| INVALID_ARGUMENT_ERROR | Gli errori sorgono quando gli argomenti di input sono invalid/illegal. |
| PERMISSION_ERROR | Gli errori si verificano in mancanza di autorizzazioni per il servizio, per i dati, ecc. |
| RESOURCE_NOT_FOUND_ERROR |
Gli errori si verificano quando i dati, la posizione, ecc. non esistono. |
| QUERY_ERROR | Gli errori derivano dall'esecuzione delle query di Spark SQL. |
| SYNTAX_ERROR | Gli errori si verificano quando nello script è presente un errore di sintassi. |
| THROTTLING_ERROR | Gli errori si verificano quando si supera la limitazione della concorrenza del servizio o il limite della quota di servizio. |
| DATA_LAKE_FRAMEWORK_ERROR | Gli errori derivano da framework data lake supportati nativamente da AWS Glue, come Hudi, Iceberg, ecc. |
| UNSUPPORTED_OPERATION_ERROR | Gli errori si verificano quando si eseguono operazioni non supportate. |
| RESOURCES_ALREADY_EXISTS_ERROR | Gli errori si verificano quando una risorsa da creare o aggiungere esiste già. |
| GLUE_INTERNAL_SERVICE_ERROR | Gli errori si verificano quando c'è un problema interno al servizio AWS Glue. |
| GLUE_OPERATION_TIMEOUT_ERROR | Gli errori si verificano quando un'operazione AWS Glue è in timeout. |
| GLUE_VALIDATION_ERROR | Gli errori si verificano quando un valore richiesto non può essere convalidato per un processo AWS Glue. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | Gli errori sorgono quando lo stesso processo espelle lo stesso bucket di origine e scrive contemporaneamente nella same/different destinazione (concorrenza >1) |
| LAUNCH_ERROR | Gli errori si verificano durante la fase di avvio del processo AWS Glue. |
| DYNAMODB_ERROR | Gli errori generici derivano dal servizio. Amazon DynamoDB |
| GLUE_ERROR | Gli errori generici derivano dal servizio AWS Glue. |
| LAKEFORMATION_ERROR | Gli errori generici derivano dal AWS Lake Formation servizio. |
| REDSHIFT_ERROR | Gli errori generici derivano dal Amazon Redshift servizio. |
| S3_ERROR | Gli errori generici derivano dal servizio Amazon S3. |
| SYSTEM_EXIT_ERROR | Errore generico di uscita dal sistema. |
| TIMEOUT_ERROR | Gli errori generici si verificano quando il processo fallisce per timeout dell'operazione. |
| UNCLASSIFIED_SPARK_ERROR | Gli errori generici derivano da Spark. |
| UNCLASSIFIED_ERROR | Categoria di errore predefinita. |
Limitazioni
Nota
glueContext deve essere inizializzato per poter pubblicare i parametri.
Nella dimensione di origine, il valore corrisponde al percorso o al nome della tabella Amazon S3, a seconda del tipo di origine. Inoltre, se l'origine è JDBC e viene utilizzata l'opzione di query, la stringa di query viene impostata nella dimensione di origine. Se il valore supera i 500 caratteri, viene ridotto per rispettare questo limite. Di seguito sono riportate le limitazioni del valore:
-
Non-ASCII i personaggi verranno rimossi.
Se il nome dell'origine non contiene alcun carattere ASCII, verrà convertito in <non-ASCII input>.
Limitazioni e considerazioni relative ai parametri della velocità di trasmissione effettiva
-
DataFrame e DataFrame-based DynamicFrame (ad esempio JDBC, lettura da parquet su Amazon S3) sono supportati, tuttavia (ad esempio la lettura di csv RDD-based DynamicFrame , json su Amazon S3, ecc.) non sono supportati. Tecnicamente, tutte le letture e le scritture visibili sull'interfaccia utente di Spark sono supportate.
-
Il parametro
recordsReadviene emesso se l'origine dati è una tabella di catalogo e il formato è JSON, CSV, testo o Iceberg. -
I parametri
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWritteneglue.driver.throughput.filesWrittennon sono disponibili nelle tabelle JDBC e Iceberg. -
I parametri potrebbero subire ritardi. Se il lavoro termina in circa un minuto, è possibile che in Metrics non siano presenti metriche di throughput. Amazon CloudWatch
