Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Pianificazione di crawling incrementale per l'aggiunta di nuove partizioni
È possibile configurare Crawler di AWS Glue ed eseguire ricerche di indicizzazione incrementali per aggiungere solo nuove partizioni allo schema della tabella. Quando il crawler viene eseguito per la prima volta, esegue un crawling completo per elaborare l'intera origine dati per registrare lo schema completo e tutte le partizioni esistenti in AWS Glue Data Catalog.
I crawling successivi a quello iniziale saranno incrementali; in questi, il crawler identifica e aggiunge solo le nuove partizioni introdotte dopo il crawling precedente. Questo approccio consente tempi di crawling più rapidi, in quanto il crawler non deve più elaborare l'intera origine dati per ogni esecuzione, ma si concentra invece solo sulle nuove partizioni.
Nota
I crawling incrementali non rilevano modifiche o eliminazioni di partizioni esistenti. Questa configurazione è più adatta per origini dati con uno schema stabile. Se si verifica una modifica importante dello schema una tantum, è consigliabile impostare temporaneamente il crawler in modo che esegua un crawling completo per acquisire il nuovo schema con precisione, e quindi tornare alla modalità di crawling incrementale.
Il diagramma seguente mostra che con l'impostazione di crawling abilitata, il crawler rileverà e aggiungerà solo la cartella appena aggiunta, month=March, al catalogo.
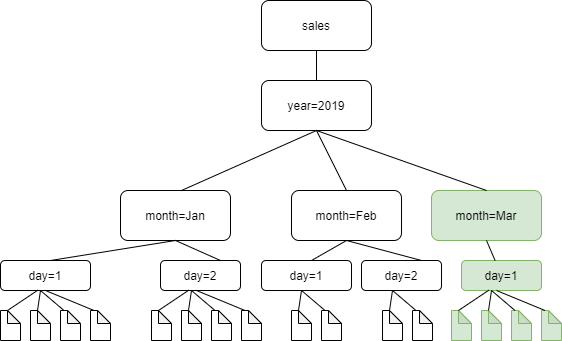
Segui questi passaggi per aggiornare il crawler per eseguire crawling incrementali:
Note e restrizioni
Quando questa opzione è attivata, non è possibile modificare gli archivi dati di destinazione Amazon S3 quando si modifica il crawler. Questa opzione influisce su alcune impostazioni di configurazione del crawler. Quando è attivata, impone il comportamento di aggiornamento e di eliminazione del crawler a LOG. Ciò significa che:
-
Se rileva oggetti con schemi non compatibili, il crawler non aggiungerà gli oggetti nel Data Catalog e aggiungerà questi dettagli come log in Logs. CloudWatch
-
Non aggiornerà gli oggetti eliminati nel catalogo dati.
