Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esegui la migrazione dei programmi Apache Spark a AWS Glue
Apache Spark è una piattaforma open source per carichi di lavoro di calcolo distribuiti eseguiti su set di dati di grandi dimensioni. AWS Glue sfrutta le capacità di Spark per fornire un'esperienza ottimizzata per ETL. Puoi migrare i programmi Spark per sfruttare AWS Glue le nostre funzionalità. AWS Glue offre gli stessi miglioramenti delle prestazioni che ti aspetteresti da Apache Spark su Amazon EMR.
Esegui codice Spark
Il codice Spark nativo può essere eseguito in un AWS Glue ambiente pronto all'uso. Gli script sono spesso sviluppati modificando iterativamente un pezzo di codice, un flusso di lavoro adatto per una sessione interattiva. Tuttavia, il codice esistente è più adatto all'esecuzione in un AWS Glue job, il che consente di pianificare e ottenere in modo coerente log e metriche per ogni esecuzione di script. Puoi caricare e modificare uno script esistente tramite la console.
-
Acquisisci la fonte del tuo script. Per questo esempio, si utilizzerà uno script di esempio dal repository Apache Spark. Esempio di Binarizer
-
Nella AWS Glue console, espandi il riquadro di navigazione a sinistra e seleziona ETL > Jobs
Nel panello Create job (crea processo), seleziona Spark script editor (editor di script di Spark). Apparirà una sezione Options (opzioni). Sotto Options (opzioni) , seleziona Upload and edit an existing script (carica e modifica uno script esistente).
Apparirà una sezione File upload (caricamento file). Sotto a File upload (caricamento file), fai clic su Choose file (seleziona file). Apparirà il tuo selettore di file di sistema. Accedi al percorso in cui hai effettuato il salvataggio di
binarizer_example.py, selezionalo e conferma della selezione.Verrà visualizzato un pulsante Create (crea) nell’intestazione del pannello Create job (crea processo). Fai clic sul pulsante.
-
Il tuo browser accederà all'editor di script. Nell'intestazione, fai clic sul sulla scheda Job details (dettagli processo). Imposta il Nome e il Ruolo IAM. Per indicazioni sui ruoli AWS Glue IAM, consultaConfigurazione delle autorizzazioni IAM per AWS Glue.
Facoltativo: imposta Requested number of workers (numero di worker richiesti) su
2e Number of retries (numero di tentativi) su1. Queste opzioni sono utili quando si eseguono lavori di produzione, ma la loro riduzione semplificherà la tua esperienza durante il test di una funzionalità.Nella barra del titolo, fai clic su Save (salva), quindi Run (esegui)
-
Passa alla scheda Runs (esecuzioni). Vedrai un pannello corrispondente all’esecuzione del processo. Attendi alcuni minuti e la pagina dovrebbe essere aggiornata automaticamente per mostrare Succeeded (elaborazione riuscita) sotto a Run status (stato dell’esecuzione).
-
Dovrai esaminare l’output per confermare che lo script Spark è stato eseguito come previsto. Questo script di esempio di Apache Spark dovrebbe scrivere una stringa nel flusso di output. Puoi trovarlo navigando su Output logs (registri di output) sotto a Cloudwatch logs(registri di Cloudwatch) nel pannello dell'esecuzione del processo riuscito. Ricorda l'id di esecuzione del processo, un id generato sotto l’etichetta Id che inizia con
jr_.Si aprirà la CloudWatch console, impostata per visualizzare i contenuti del gruppo di AWS Glue log predefinito
/aws-glue/jobs/output, filtrati in base ai contenuti dei flussi di log per l'ID di esecuzione del processo. Ogni worker avrà generato un flusso di log, mostrato in righe sotto Log streams (Flussi di log). Un worker dovrebbe aver eseguito il codice richiesto. Sarà necessario aprire tutti i flussi di log per identificare il worker corretto. Una volta trovato il worker giusto, dovresti vedere l'output dello script, come mostrato nell'immagine seguente: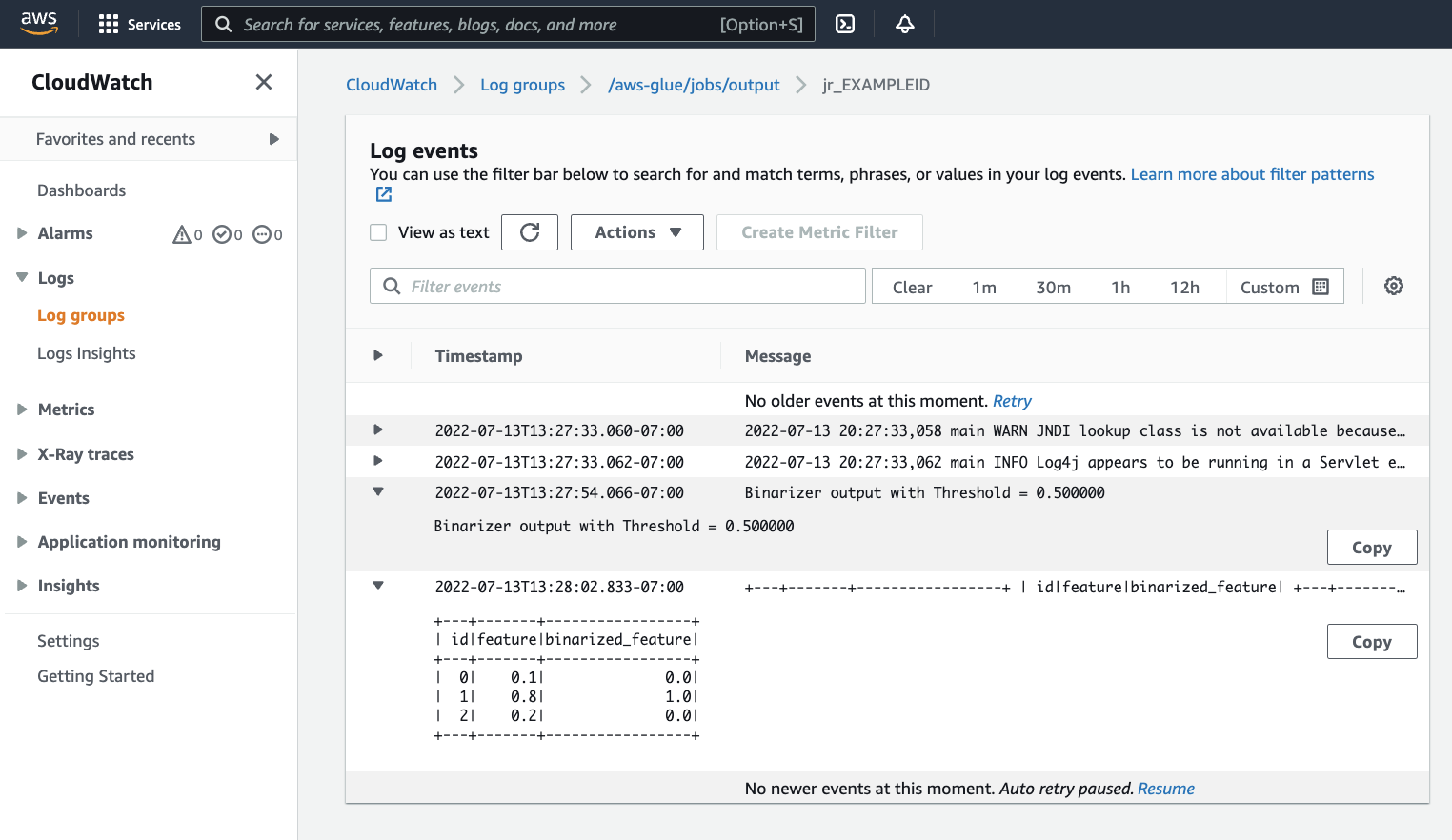
Procedure comuni necessarie per la migrazione dei programmi Spark
Convalida il supporto della versione di Spark
AWS Glue le versioni di rilascio definiscono la versione di Apache Spark e Python disponibile per il job. AWS Glue Puoi trovare AWS Glue le nostre versioni e il loro supporto all'indirizzo. AWS Glue versioni Potrebbe essere necessario aggiornare il programma Spark per renderlo compatibile con una versione più recente di Spark per accedere a determinate caratteristiche di AWS Glue .
Includi librerie di terze parti
Molti programmi Spark esistenti avranno dipendenze, sia da artefatti privati che pubblici. AWS Glue supporta le dipendenze in stile JAR per processi Scala così come le dipendenze Wheel e pure-Python per i processi Python.
Python : per informazioni sulle dipendenze Python, consulta Usare le librerie Python con Glue AWS
Le dipendenze Python comuni sono fornite nell' AWS Glue ambiente, inclusa la libreria Pandas comunemente richiesta.--additional-python-modules. Per informazioni su questi argomenti, consulta Utilizzo dei parametri del lavoro nei lavori AWS Glue.
È possibile fornire dipendenze Python aggiuntive con l’argomento del processo --extra-py-files. Se state migrando un job da un programma Spark, questo parametro è una buona opzione perché è funzionalmente equivalente al --py-files flag in ed è soggetto alle stesse PySpark limitazioni. Per ulteriori informazioni sul parametro --extra-py-files, consulta Inclusione di file Python con funzionalità native PySpark.
Per i nuovi processi, è possibile gestire le dipendenze Python con l’argomento del processo --additional-python-modules. L'utilizzo di questo argomento consente un'esperienza di gestione delle dipendenze più approfondita. Questo parametro supporta le dipendenze dello stile Wheel, incluse quelle con associazioni di codice native compatibili con Amazon Linux 2.
Scala
È possibile fornire dipendenze Scala aggiuntive con l’argomento del processo --extra-jars. Le dipendenze devono essere ospitate in Amazon S3 e il valore dell'argomento deve essere un elenco delimitato da virgole di percorsi Amazon S3 senza spazi. Potresti trovare più semplice gestire la configurazione riorganizzando le dipendenze prima di ospitarle e configurarle. AWS Glue Le dipendenze JAR contengono bytecode Java, che può essere generato da qualsiasi linguaggio JVM. È possibile utilizzare altri linguaggi JVM, come Java, per scrivere dipendenze personalizzate.
Gestisci le credenziali dell'origine dei dati.
I programmi Spark esistenti possono avere una configurazione complessa o personalizzata per estrarre dati dalle loro origini dati. I flussi di autenticazione delle origini dati comuni sono supportati dalle connessioni. AWS Glue Per ulteriori informazioni sulle connessioni AWS Glue , consulta Connessione ai dati.
AWS Glue le connessioni facilitano la connessione del Job a una varietà di tipi di archivi dati in due modi principali: tramite chiamate di metodo alle nostre librerie e impostando la connessione di rete aggiuntiva nella AWS console. Puoi anche chiamare l' AWS SDK dall'interno del tuo job per recuperare informazioni da una connessione.
Chiamate di metodo: AWS Glue le connessioni sono strettamente integrate con AWS Glue
Data Catalog, un servizio che consente di gestire le informazioni sui set di dati, e i metodi disponibili per interagire con le connessioni lo riflettono. AWS Glue Se disponi di una configurazione di autenticazione esistente che desideri riutilizzare, per le connessioni JDBC, puoi accedere alla configurazione della AWS Glue connessione tramite il metodo su. extract_jdbc_conf GlueContext Per ulteriori informazioni, consulta extract_jdbc_conf
Configurazione della console: i AWS Glue job utilizzano AWS Glue le connessioni associate per configurare le connessioni alle sottoreti Amazon VPC. Se gestisci direttamente i tuoi materiali di sicurezza, potrebbe essere necessario fornire un NETWORK tipo «Connessione di rete aggiuntiva» nella AWS console per configurare il routing. Per ulteriori informazioni sull’API di connessione AWS Glue
, consulta API Connessioni.
Se i tuoi programmi Spark hanno un flusso di autenticazione personalizzato o non comune, potresti dover gestire i materiali di sicurezza in modo pratico. Se AWS Glue le connessioni non sembrano adatte, puoi ospitare in modo sicuro i materiali di sicurezza in Secrets Manager e accedervi tramite boto3 o AWS SDK, forniti nel job.
Configurazione di Apache Spark
Le migrazioni complesse spesso alterano la configurazione di Spark per adattarsi ai loro carichi di lavoro. Le versioni moderne di Apache Spark consentono di impostare la configurazione di runtime con. SparkSession AWS Glue Sono disponibili oltre 3.0 jobSparkSession, che possono essere modificati per impostare la configurazione di runtime. Configurazione di Apache Spark
Impostazione della configurazione personalizzata
I programmi Spark migrati possono essere progettati per accettare configurazioni personalizzate. AWS Glue consente di impostare la configurazione a livello di job e job run, tramite gli argomenti del job. Per informazioni su questi argomenti, consulta Utilizzo dei parametri del lavoro nei lavori AWS Glue. Puoi accedere agli argomenti relativi al lavoro nel contesto di un lavoro tramite le nostre librerie. AWS Glue fornisce una funzione di utilità per fornire una visualizzazione coerente tra gli argomenti impostati nel job e gli argomenti impostati durante l'esecuzione del job. Consulta Accesso ai parametri utilizzando getResolvedOptions in Python e AWS GlueScala GlueArgParser APIs in Scala.
Migrazione del codice Java
Come spiegato in Includi librerie di terze parti, le dipendenze possono contenere classi generate da linguaggi JVM, come Java o Scala. Le dipendenze possono includere un metodo main. È possibile utilizzare un main metodo in una dipendenza come punto di ingresso per un AWS Glue processo Scala. Questo permette di scrivere il proprio metodo main in Java o riutilizzare un metodo main elaborato in pacchetti secondo gli standard della tua libreria.
Per utilizzare un metodo main da una dipendenza, esegui le seguenti operazioni: cancella il contenuto del riquadro di modifica fornendo il valore predefinito dell’oggetto GlueApp. Fornisci il nome completo di una classe in una dipendenza come argomento di processo con la chiave--class. A questo punto dovresti essere in grado di attivare un’esecuzione del processo.
Non è possibile configurare l'ordine o la struttura degli argomenti passati al AWS Glue metodo. main Se il codice esistente deve leggere la configurazione impostata AWS Glue, ciò potrebbe causare incompatibilità con il codice precedente. Se utilizzi getResolvedOptions, non avrai nemmeno un luogo ideale per chiamare questo metodo. Prendi in considerazione la possibilità di invocare la tua dipendenza direttamente da un metodo principale generato da AWS Glue. Il seguente script AWS Glue ETL ne mostra un esempio.
import com.amazonaws.services.glue.util.GlueArgParser object GlueApp { def main(sysArgs: Array[String]) { val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) // Invoke static method from JAR. Pass some sample arguments as a String[], one defined inline and one taken from the job arguments, using getResolvedOptions com.mycompany.myproject.MyClass.myStaticPublicMethod(Array("string parameter1", args("JOB_NAME"))) // Alternatively, invoke a non-static public method. (new com.mycompany.myproject.MyClass).someMethod() } }
