Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Sviluppa e testa i AWS Glue lavori localmente utilizzando un'immagine Docker
Per una piattaforma di dati pronta per la produzione, il processo di sviluppo e la CI/CD pipeline dei AWS Glue lavori sono un argomento chiave. Puoi sviluppare e testare AWS Glue lavori in modo flessibile in un contenitore Docker. AWS Glue ospita immagini Docker su Docker Hub per configurare l'ambiente di sviluppo con utilità aggiuntive. Puoi usare il tuo IDE, notebook o REPL preferito utilizzando la libreria ETL. AWS Glue Questo argomento descrive come sviluppare e testare i job della AWS Glue versione 5.0 in un contenitore Docker utilizzando un'immagine Docker.
Immagini Docker disponibili
Le seguenti immagini Docker sono disponibili per AWS Glue Amazon ECR
-
Per la AWS Glue versione 5.0:
public.ecr.aws/glue/aws-glue-libs:5 -
Per la AWS Glue versione 4.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01 -
Per la AWS Glue versione 3.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 -
Per la AWS Glue versione 2.0:
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01
Nota
AWS Glue Le immagini Docker sono compatibili sia con x86_64 che con arm64.
In questo esempio, utilizziamo public.ecr.aws/glue/aws-glue-libs:5 ed eseguiamo il container su un computer locale (Mac, Windows o Linux). Questa immagine del contenitore è stata testata per AWS Glue i job Spark della versione 5.0. L'immagine contiene quanto segue:
-
Amazon Linux 2023
-
AWS Glue Libreria ETL
-
Apache Spark 3.5.4
-
Librerie in formato tabella aperta; Apache Iceberg 1.7.1, Apache Hudi 0.15.0 e Delta Lake 3.3.0
-
AWS Glue Client Data Catalog
-
Amazon Redshift connettore per Apache Spark
-
Amazon DynamoDB connettore per Apache Hadoop
Per configurare il container, estrai l'immagine da ECR Public Gallery e quindi esegui il container. Questo argomento illustra come eseguire il container con i seguenti metodi, a seconda delle esigenze:
-
spark-submit -
REPL shell
(pyspark) -
pytest -
Visual Studio Code
Prerequisiti
Prima di iniziare, verifica che Docker sia installato e che il daemon Docker sia in esecuzione. Per istruzioni sull'installazione, consulta la documentazione Docker per Mac
Per ulteriori informazioni sulle restrizioni relative allo sviluppo locale AWS Glue del codice, consulta Restrizioni allo sviluppo locale.
Configurazione AWS
Per abilitare le chiamate AWS API dal contenitore, configura AWS le credenziali seguendo i passaggi seguenti. Nelle sezioni seguenti, utilizzeremo questo profilo AWS denominato.
-
Apri
cmdsu Windows o su un terminale Mac/Linux ed esegui il seguente comando in un terminale:PROFILE_NAME="<your_profile_name>"
Nelle sezioni seguenti, utilizziamo questo profilo AWS denominato.
Se stai eseguendo Docker su Windows, scegli l'icona Docker (fai clic con il pulsante destro del mouse) e scegli Passa ai container Linux prima di estrarre l'immagine.
Esegui il comando seguente per estrarre l'immagine da ECR Public:
docker pull public.ecr.aws/glue/aws-glue-libs:5
Esegui il container
Ora puoi eseguire un container utilizzando questa immagine. Puoi scegliere una delle opzioni seguenti in base alle tue esigenze.
spark-submit
È possibile eseguire uno script di AWS Glue lavoro eseguendo il spark-submit comando sul contenitore.
-
Scrivi il tuo script e salvalo come
sample.pynell'esempio riportato di seguito, quindi salvalo nella directory/local_path_to_workspace/src/utilizzando i seguenti comandi:$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME} -
Queste variabili vengono usate nel comando docker run riportato di seguito. Il codice di esempio (sample.py) utilizzato nel comando spark-submit riportato di seguito è incluso nell'appendice alla fine di questo argomento.
Esegui il comando seguente per eseguire il comando
spark-submitsul container per inviare una nuova applicazione Spark:$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_spark_submit \ public.ecr.aws/glue/aws-glue-libs:5 \ spark-submit /home/hadoop/workspace/src/$SCRIPT_FILE_NAME -
(Facoltativo) Configura
spark-submitin modo che corrisponda all'ambiente in uso. Ad esempio, puoi trasferire le dipendenze con la configurazione--jars. Per ulteriori informazioni, consulta Caricamento dinamico delle proprietà Sparknella documentazione di Spark.
Shell REPL (Pyspark)
Puoi eseguire la shell REPL (read-eval-print loops) per lo sviluppo interattivo. Esegui il comando seguente per eseguire il PySpark comando sul contenitore per avviare la shell REPL:
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
Vedrai l'output seguente:
Python 3.11.6 (main, Jan 9 2025, 00:00:00) [GCC 11.4.1 20230605 (Red Hat 11.4.1-2)] on linux Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.5.4-amzn-0 /_/ Using Python version 3.11.6 (main, Jan 9 2025 00:00:00) Spark context Web UI available at None Spark context available as 'sc' (master = local[*], app id = local-1740643079929). SparkSession available as 'spark'. >>>
Con questa shell REPL è possibile programmare ed eseguire test in modo interattivo.
Pytest
Per i test unitari, puoi utilizzare pytest gli script di lavoro di AWS Glue Spark. Esegui i comandi seguenti per la preparazione.
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
Esegui il seguente comando per eseguire pytest usando docker run:
$ docker run -i --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pytest \ public.ecr.aws/glue/aws-glue-libs:5 \ -c "python3 -m pytest --disable-warnings"
Una volta che pytest avrà terminato l'esecuzione dei test di unità, il risultato sarà simile al seguente:
============================= test session starts ============================== platform linux -- Python 3.11.6, pytest-8.3.4, pluggy-1.5.0 rootdir: /home/hadoop/workspace plugins: integration-mark-0.2.0 collected 1 item tests/test_sample.py . [100%] ======================== 1 passed, 1 warning in 34.28s =========================
Configurazione del container per l'utilizzo di Visual Studio Code
Per configurare il container con Visual Studio Code, completa i seguenti passaggi:
Installare Visual Studio Code.
Installare Python
. Installare Visual Studio Code Remote - Containers
(Visual Studio Code Remote - Container) Aprire la cartella del WorkSpace in Visual Studio Code.
Premi
Ctrl+Shift+P(Windows/Linux) oCmd+Shift+P(Mac).Tipo
Preferences: Open Workspace Settings (JSON).Premere Invio.
Incollare il seguente codice JSON e salvarlo.
{ "python.defaultInterpreterPath": "/usr/bin/python3.11", "python.analysis.extraPaths": [ "/usr/lib/spark/python/lib/py4j-0.10.9.7-src.zip:/usr/lib/spark/python/:/usr/lib/spark/python/lib/", ] }
Per configurare il container:
-
Eseguire il container Docker.
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark -
Avviare Visual Studio Code.
-
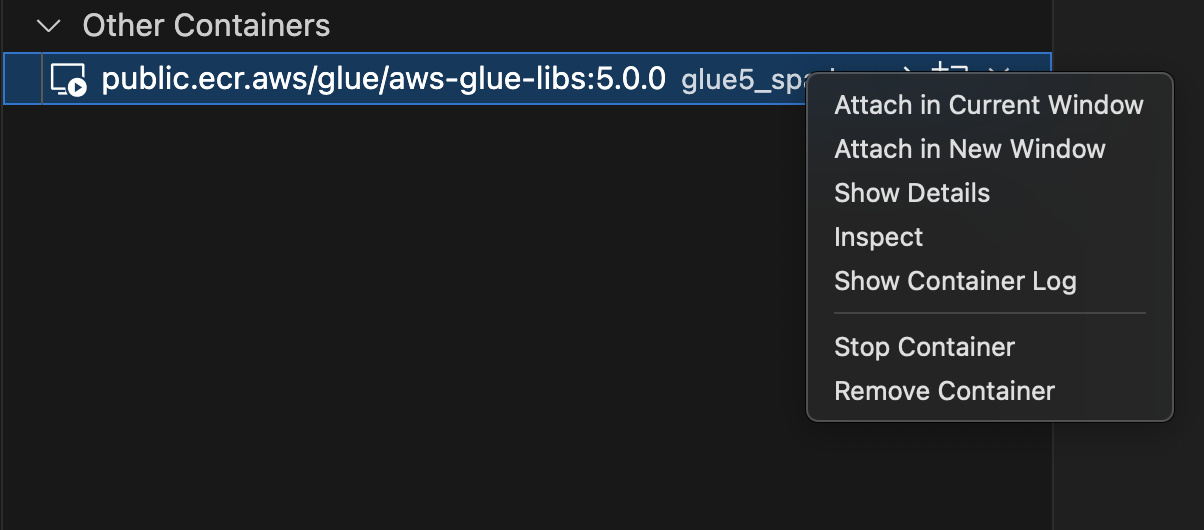
Scegliere Remote Explorer nel menu a sinistra, quindi
amazon/aws-glue-libs:glue_libs_4.0.0_image_01. -
Right-click e scegli Allega nella finestra corrente.
-
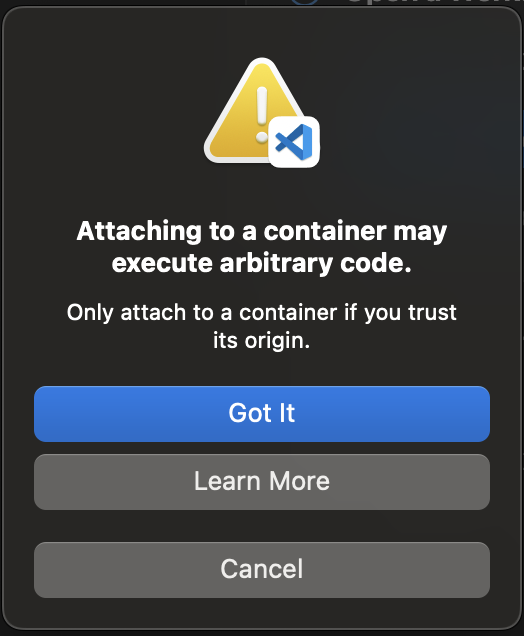
Se viene visualizzata la seguente finestra di dialogo, seleziona Capito.
-
Aprire
/home/handoop/workspace/.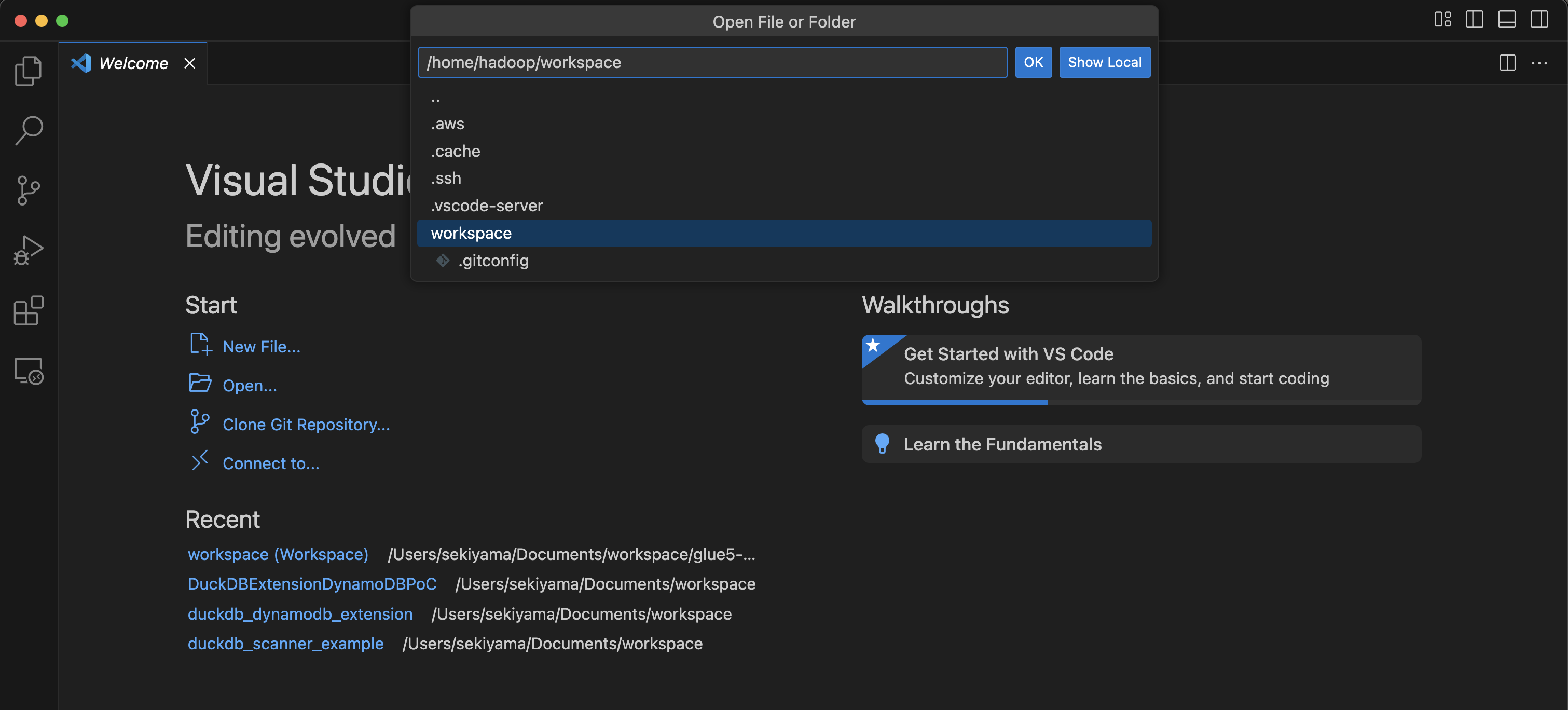
-
Crea uno AWS Glue PySpark script e scegli Esegui.
Visualizzerai l'esecuzione corretta dello script.
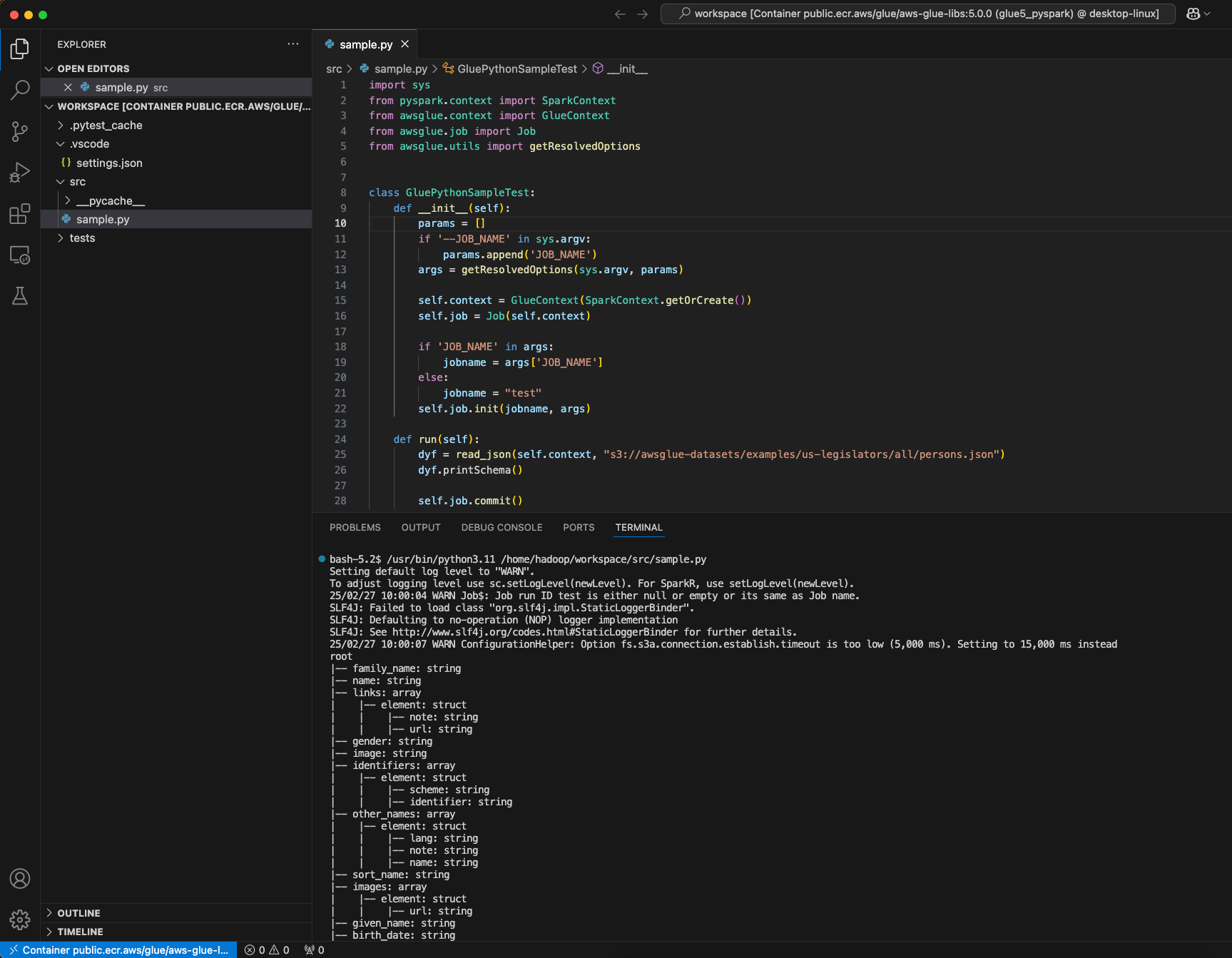
Modifiche tra l'immagine Docker AWS Glue 4.0 e AWS Glue 5.0
Le principali modifiche tra l'immagine Docker AWS Glue 4.0 e AWS Glue 5.0:
-
Nella AWS Glue versione 5.0, esiste un'unica immagine contenitore per i lavori in batch e in streaming. Ciò differisce da Glue 4.0, dove era presente un'immagine per i processi in batch e un'altra per quelli in streaming.
-
Nella AWS Glue versione 5.0, il nome utente predefinito del contenitore è
hadoop. Nella AWS Glue versione 4.0, il nome utente predefinito eraglue_user. -
Nella AWS Glue versione 5.0, diverse librerie aggiuntive, JupyterLab tra cui Livy, sono state rimosse dall'immagine. Puoi installarle manualmente.
-
Nella AWS Glue versione 5.0, tutte le librerie Iceberg, Hudi e Delta sono precaricate di default e la variabile di ambiente
DATALAKE_FORMATSnon è più necessaria. Prima della AWS Glue 4.0, la variabileDATALAKE_FORMATSdi ambiente veniva utilizzata per specificare quali formati di tabella specifici dovevano essere caricati.
L'elenco precedente è specifico dell'immagine Docker. Per ulteriori informazioni sugli aggiornamenti AWS Glue 5.0, consulta Introduzione alla AWS Glue versione 5.0 per Apache Spark
Considerazioni
Tieni presente che le seguenti funzionalità non sono supportate quando usi l'immagine del AWS Glue contenitore per sviluppare script di lavoro localmente.
-
AWS Glue Parquet writer (utilizzo del formato Parquet in AWS Glue)
-
La proprietà personalizzata JdbcDriverS3Path per caricare il driver JDBC dal percorso Amazon S3
-
AWS Lake Formation vendita di credenziali basata su autorizzazioni
Appendice: aggiunta di driver JDBC e librerie Java
Per aggiungere un driver JDBC attualmente non disponibile nel container, puoi creare una nuova directory nel workspace con i file JAR necessari e montare la directory in /opt/spark/jars/ nel comando docker run. I file JAR presenti nella director /opt/spark/jars/ all'interno del container vengono aggiunti automaticamente al percorso di classe Spark e saranno disponibili per l'uso durante l'esecuzione del processo.
Ad esempio, usa il seguente comando docker run per aggiungere i jar dei driver JDBC alla shell REPL. PySpark
docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -v $WORKSPACE_LOCATION/jars/:/opt/spark/jars/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_jdbc \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
Come evidenziato in Considerazioni, l'opzione di customJdbcDriverS3Path connessione non può essere utilizzata per importare un driver JDBC personalizzato da Amazon S3 nelle immagini dei container. AWS Glue
