Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS Glue componenti
AWS Glue fornisce una console e operazioni API per configurare e gestire il carico di lavoro di estrazione, trasformazione e caricamento (ETL). È possibile utilizzare le operazioni API tramite diversi linguaggi specifici e il comando ( SDKs). AWS Command Line Interface AWS CLIPer informazioni sull'utilizzo di AWS CLI, vedere AWS CLI Command Reference.
AWS Glue utilizza il AWS Glue Data Catalog per archiviare i metadati relativi a fonti di dati, trasformazioni e destinazioni. Il catalogo dati sostituisce il metastore Apache Hive. AWS Glue Jobs system Fornisce un'infrastruttura gestita per la definizione, la pianificazione e l'esecuzione delle operazioni ETL sui dati. Per ulteriori informazioni sull' AWS Glue API, consulta. AWS Glue API
AWS Glue console
La AWS Glue console viene utilizzata per definire e orchestrare il flusso di lavoro ETL. La console richiama diverse operazioni API nel AWS Glue Data Catalog e AWS Glue Jobs system per eseguire le seguenti attività:
-
Definisci AWS Glue oggetti come lavori, tabelle, crawler e connessioni.
-
Pianificare l'esecuzione dei crawler.
-
Definire eventi o programmi per i trigger di processo.
-
Cerca e filtra gli elenchi di oggetti. AWS Glue
-
Modificare gli script di trasformazione.
AWS Glue Data Catalog
AWS Glue Data Catalog È il tuo archivio persistente di metadati tecnici nel AWS Cloud.
Ogni AWS account ne ha uno AWS Glue Data Catalog per AWS regione. Ogni catalogo dati è una raccolta altamente scalabile di tabelle organizzate in database. Una tabella è la rappresentazione dei metadati di una raccolta di dati strutturati o semistrutturati archiviati in fonti come Amazon RDS, Apache Hadoop Distributed File System, Amazon Service e altre. OpenSearch AWS Glue Data Catalog Fornisce un repository uniforme in cui diversi sistemi possono archiviare e trovare metadati per tenere traccia dei dati nei silos di dati. È quindi possibile utilizzare i metadati per eseguire query e trasformare i dati in modo coerente su un'ampia varietà di applicazioni.
Utilizzi il Data Catalog insieme alle AWS Identity and Access Management policy e a Lake Formation per controllare l'accesso alle tabelle e ai database. In questo modo, consenti a diversi gruppi nella tua azienda di pubblicare in modo sicuro i dati per la più ampia organizzazione proteggendo allo stesso tempo le informazioni sensibili in modo altamente granulare.
Il Data Catalog, insieme CloudTrail a Lake Formation, offre anche funzionalità complete di audit e governance, con tracciamento delle modifiche allo schema e controlli di accesso ai dati. Questo contribuisce a garantire che i dati non vengono modificati impropriamente o condivisi inavvertitamente.
Per informazioni su come proteggere e controllare ila AWS Glue Data Catalog, consulta:
-
AWS Lake Formation – Per ulteriori informazioni, consulta Cos'è AWS Lake Formation? nella Guida per gli sviluppatori di AWS Lake Formation .
-
CloudTrail— Per ulteriori informazioni, consulta What Is CloudTrail? nella Guida AWS CloudTrail per l'utente.
Di seguito sono riportati altri AWS servizi e progetti open source che utilizzano: AWS Glue Data Catalog
-
Amazon Athena – Per ulteriori informazioni, consulta Comprensione di tabelle, database e catalogo dati nella Guida per l'utente di Amazon Athena.
-
Amazon Redshift Spectrum – Per ulteriori informazioni, consulta Utilizzo di Amazon Redshift Spectrum per eseguire query su dati esterni nella Guida per gli sviluppatori di Amazon Redshift.
-
Amazon EMR – Per ulteriori informazioni, consulta Utilizzo di policy basate su risorse per l'accesso Amazon EMR ad AWS Glue Data Catalog nella Guida alla gestione di Amazon EMR.
-
AWS Glue Data Catalog client per Apache Hive metastore — Per ulteriori informazioni su questo GitHub progetto, consulta AWS Glue Data Catalog Client
for Apache Hive Metastore.
AWS Glue crawler e classificatori
AWS Glue consente inoltre di configurare crawler in grado di scansionare i dati in tutti i tipi di repository, classificarli, estrarne le informazioni sullo schema e archiviare automaticamente i metadati in. AWS Glue Data Catalog AWS Glue Data Catalog Possono quindi essere utilizzati per guidare le operazioni ETL.
Per informazioni su come configurare i crawler e i classificatori, consulta l'articolo Utilizzo dei crawler per compilare il Catalogo dati. Per informazioni su come programmare crawler e classificatori utilizzando l'API, consulta. AWS Glue API crawler e classificatori
AWS Glue Operazioni ETL
Utilizzando i metadati nel Data Catalog, AWS Glue puoi generare automaticamente script Scala o PySpark (l'API Python per Apache Spark) AWS Glue con estensioni che puoi usare e modificare per eseguire varie operazioni ETL. Ad esempio, puoi estrarre, pulire e trasformare dati grezzi, quindi memorizzare il risultato in un diverso archivio, dove può essere interrogato e analizzato. Tale script potrebbe convertire un file CSV in una struttura dati relazionale e salvarlo in Amazon Redshift.
Per ulteriori informazioni su come utilizzare le funzionalità ETL, consulta. AWS Glue Script di programmazione Spark
Streaming di ETL in AWS Glue
AWS Glue consente di eseguire operazioni ETL sullo streaming di dati utilizzando processi in esecuzione continua. AWS Glue streaming ETL è basato sul motore di streaming strutturato Apache Spark e può importare flussi da Amazon Kinesis Data Streams, Apache Kafka e Amazon Managed Streaming for Apache Kafka (Amazon MSK). Streaming ETL può pulire e trasformare i dati di streaming e caricarli in Amazon S3 o in archivi dati JDBC. Usa Streaming ETL in AWS Glue per elaborare dati di eventi come flussi IoT, clickstream e log di rete.
Se si conosce lo schema dell'origine dati di streaming, è possibile specificarlo in una tabella del catalogo dati. In caso contrario, è possibile abilitare il rilevamento dello schema nel processo ETL di streaming. Il processo determina automaticamente lo schema dai dati in entrata.
Il job ETL di streaming può utilizzare sia trasformazioni AWS Glue integrate che trasformazioni native di Apache Spark Structured Streaming. Per ulteriori informazioni, consulta Operazioni sullo streaming DataFrames /Datasets sul sito Web
Per ulteriori informazioni, consulta Aggiunta di processi di streaming ETL in AWS Glue.
Il sistema dei lavori AWS Glue
AWS Glue Jobs system Fornisce un'infrastruttura gestita per orchestrare il flusso di lavoro ETL. È possibile creare lavori AWS Glue che automatizzino gli script utilizzati per estrarre, trasformare e trasferire dati in posizioni diverse. I processi possono essere programmati e concatenati oppure possono essere attivati da eventi quali l'arrivo di nuovi dati.
Per ulteriori informazioni sull'utilizzo di AWS Glue Jobs system, vedere. Monitoraggio AWS Glue Per informazioni sulla programmazione tramite l'API AWS Glue Jobs system , consulta API dei processi.
Componenti ETL visivi
AWS Glue ti consente di creare lavori ETL attraverso una tela visiva che puoi manipolare.
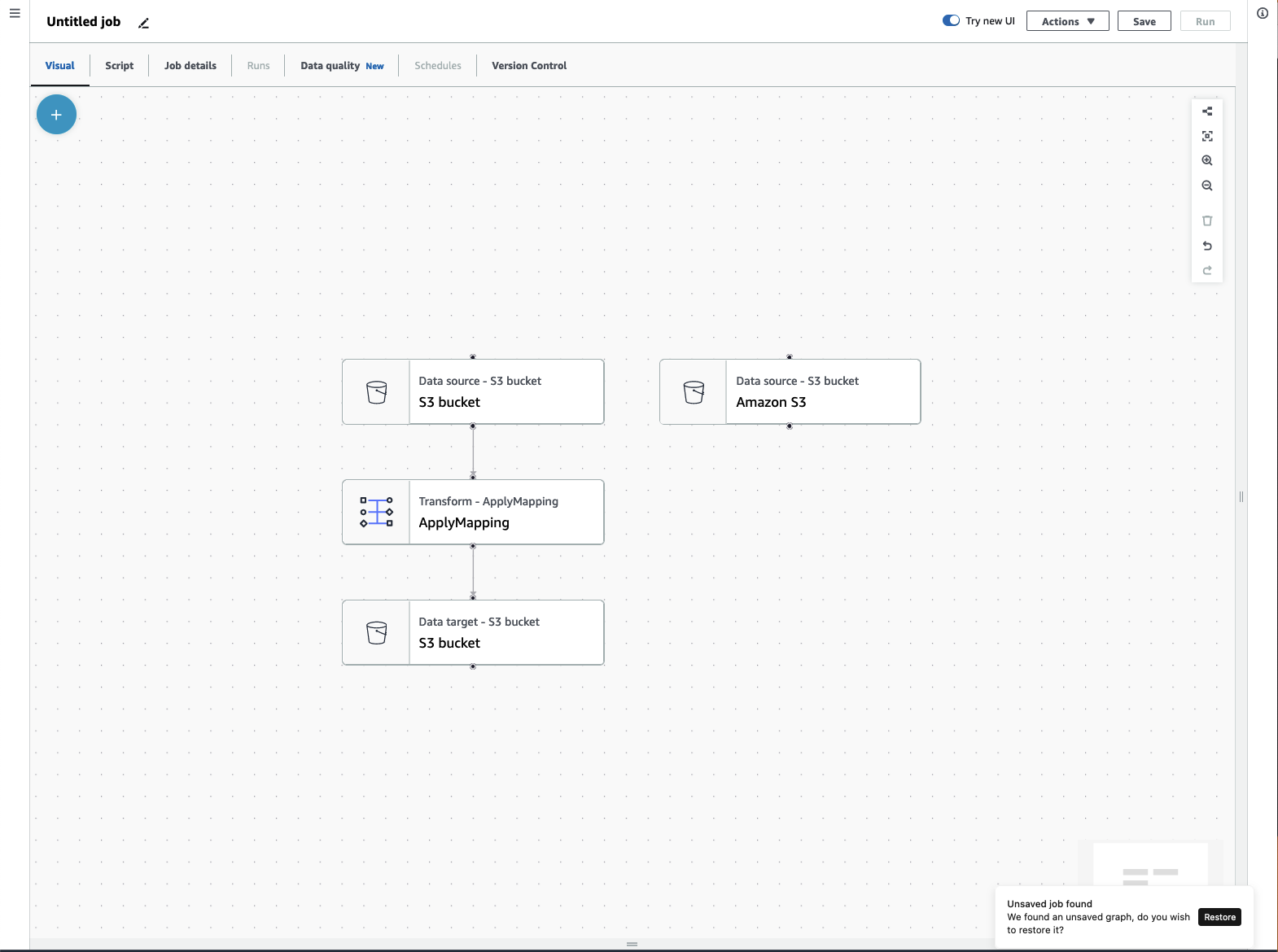
Menu dei processi ETL
Le opzioni di menu nella parte superiore del canvas consentono di accedere alle varie visualizzazioni e ai dettagli di configurazione relativi al processo.
-
Visivo: il canvas dell'editor di processo visivo. Da qui è possibile aggiungere nodi per creare un processo.
-
Script: la rappresentazione tramite script del tuo lavoro ETL. AWS Glue genera lo script in base alla rappresentazione visiva del tuo lavoro. È inoltre possibile modificare lo script o scaricarlo.
Nota
Se scegli di modificare lo script, l'esperienza di creazione del processo viene convertita in modo permanente in modalità di solo script. Successivamente, non è più possibile utilizzare l'editor visivo per modificare il processo. È necessario aggiungere tutte le origini, le trasformazioni e le destinazioni del processo e apportare tutte le modifiche necessarie con l'editor visivo prima di scegliere di modificare lo script.
-
Dettagli del processo: la scheda Dettagli del processo consente di configurare il processo impostandone le proprietà. Sono disponibili proprietà di base, come nome e descrizione del processo, ruolo IAM, tipo di processo, versione di AWS Glue, lingua, tipo di worker, numero di worker, segnalibro del processo, esecuzione flessibile, numero di ritirati e timeout del processo, così come alcune proprietà avanzate, come connessioni, librerie, parametri di processo e tag.
-
Esecuzioni: dopo l'esecuzione del processo, è possibile accedere a questa scheda per visualizzare i processi eseguiti in passato.
-
Qualità dei dati: la qualità dei dati consente di valutare e monitorare la qualità delle risorse di dati. Puoi saperne di più su come utilizzare la qualità dei dati in questa scheda e aggiungere una trasformazione della qualità dei dati al tuo processo.
-
Pianificazioni: i processi che hai pianificato vengono visualizzati in questa scheda. Se non esistono pianificazioni collegate a questo processo, questa scheda non è accessibile.
-
Controllo della versione: puoi utilizzare Git con il tuo processo configurandolo in un repository Git.
Pannelli ETL visivi
Quando lavori nel canvas, sono disponibili diversi pannelli che ti aiutano a configurare i nodi o a visualizzare l'anteprima dei dati e visualizzare lo schema di output.
-
Proprietà: il pannello Proprietà viene visualizzato quando si sceglie un nodo nel canvas.
-
Anteprima dei dati: il pannello di anteprima dei dati fornisce un'anteprima dell'output dei dati in modo da poter prendere decisioni prima di eseguire il processo ed esaminare l'output.
-
Schema di output: la scheda Schema di output consente di visualizzare e modificare lo schema dei nodi di trasformazione.
Ridimensionamento dei pannelli
È possibile ridimensionare il pannello Proprietà sul lato destro dello schermo e il pannello inferiore che contiene le schede Anteprima dati e Schema di output facendo clic sul bordo del pannello e trascinandolo a sinistra e a destra o su e giù.
-
Pannello delle proprietà: ridimensiona il pannello delle proprietà facendo clic sul bordo del canvas sul lato destro dello schermo e trascinandolo verso sinistra per aumentarne la larghezza. Per impostazione predefinita, il pannello è compresso, mentre quando viene selezionato un nodo il pannello delle proprietà si apre alla dimensione predefinita.
-
Pannello Anteprima dei dati e Schema di output: ridimensiona il pannello inferiore facendo clic sul bordo inferiore del canvas nella parte inferiore dello schermo e trascinandolo verso l'alto per aumentarne l'altezza. Per impostazione predefinita, il pannello è compresso, mentre quando viene selezionato un nodo il pannello inferiore si apre alla dimensione predefinita.
Canvas del processo
È possibile aggiungere, rimuovere e move/reorder nodi direttamente nell'area di disegno di Visual ETL. Puoi immaginarlo come uno spazio di lavoro per creare un processo ETL completamente funzionale, a partire da un'origine dati fino alla destinazione dati.
Quando lavori con i nodi sul canvas, hai a disposizione una barra degli strumenti che può aiutarti a ingrandire e ridurre le dimensioni, rimuovere nodi, creare o modificare connessioni tra i nodi, cambiare l'orientamento del flusso di processo e annullare o ripetere un'operazione.

La barra degli strumenti mobile è ancorata al bordo in alto a destra del canvas e contiene diverse immagini che eseguono altrettante operazioni:
-
Icona del layout: la prima icona nella barra degli strumenti è l'icona del layout. Per impostazione predefinita, la direzione dei processi visivi è dall'alto verso il basso. Riorganizza la direzione del processo visivo disponendo i nodi orizzontalmente da sinistra a destra. Facendo nuovamente clic sull'icona del layout, la direzione torna dall'alto verso il basso.
-
Icona Ricentra: questa icona consente di modificare la visualizzazione del canvas centrandola. È possibile utilizzarla con processi di grandi dimensioni per tornare alla posizione centrale.
-
Icona Ingrandisci: questa icona consente di aumentare la dimensione dei nodi sul canvas.
-
Icona Riduci: questa icona consente di ridurre la dimensione dei nodi sul canvas.
-
Icona del cestino: l'icona del cestino rimuove un nodo dal processo visivo. Prima è necessario selezionare un nodo.
-
Icona Annulla: questa icona consente di annullare l'ultima operazione eseguita sul processo visivo.
-
Icona Ripeti: questa icona consente di ripetere l'ultima operazione eseguita sul processo visivo.
Utilizzo della minimappa

Pannello delle risorse
Il pannello delle risorse contiene tutte le origini dati, le operazioni di trasformazione e le connessioni disponibili. Apri il pannello delle risorse sul canvas facendo clic sull'icona "+". Si aprirà il pannello delle risorse.
Per chiudere il pannello delle risorse, fai clic sulla X nell'angolo in alto a destra del pannello delle risorse. In questo modo il pannello rimarrà nascosto fino a quando non lo riaprirai.
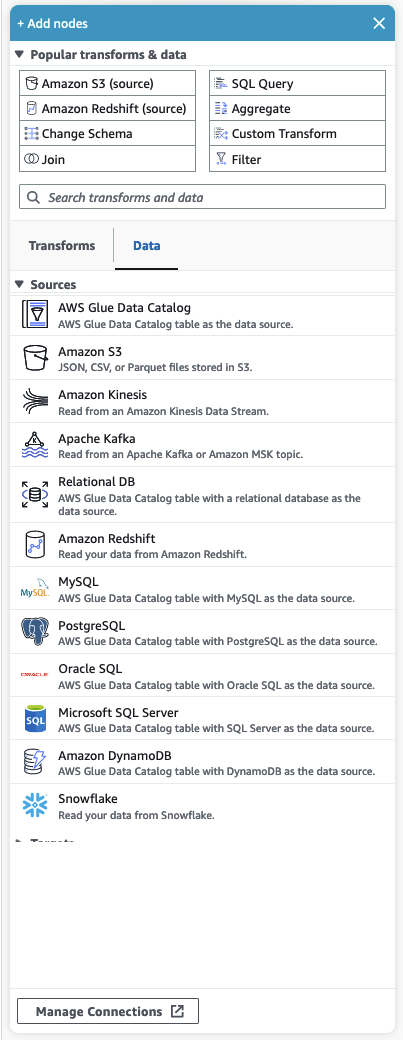
Trasformazioni e dati comuni
Nella parte superiore del pannello è presente una raccolta di Trasformazioni e dati comuni. Questi nodi sono comunemente usati in AWS Glue. Scegline uno per aggiungerlo al canvas. Puoi anche nascondere Trasformazioni e dati comuni facendo clic sul triangolo accanto all'intestazione Trasformazioni e dati comuni.
Nella sezione Trasformazioni e dati comuni, puoi cercare trasformazioni e nodi di origini dati. I risultati vengono visualizzati durante la digitazione. Più lettere aggiungi alla tua query di ricerca, più l'elenco dei risultati si ridurrà. I risultati della ricerca vengono compilati in base alla and/or descrizione del nome del nodo. Scegli il nodo per aggiungerlo al canvas.
Trasformazioni e dati
Esistono due schede che organizzano i nodi in Trasformazioni e Dati.
Trasformazioni: quando si sceglie la scheda Trasformazioni, è possibile selezionare tutte le trasformazioni disponibili. Scegli una trasformazione per aggiungerla al canvas. Puoi anche scegliere Aggiungi trasformazione nella parte inferiore dell'elenco Trasformazioni; questa operazione aprirà una nuova pagina alla documentazione per la creazione di Trasformazioni visive personalizzate. Seguendo i passaggi potrai creare trasformazioni personalizzate. Le trasformazioni verranno quindi visualizzate nell'elenco delle trasformazioni disponibili.
Dati: la scheda dati contiene tutti i nodi per Origini e Destinazioni. È possibile nascondere le origini e le destinazioni facendo clic sul triangolo accanto all'intestazione Origini o Destinazioni. È possibile visualizzare le origini e le destinazioni facendo nuovamente clic sul triangolo. Scegli un nodo di origine o di destinazione per aggiungerlo al canvas. È inoltre possibile scegliere Gestisci connessioni per aggiungere una nuova connessione. Si aprirà la pagina Connettori nella console.
