Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS Glue concetti
AWS Glue è un servizio ETL (extract, transform, load) completamente gestito che consente di spostare facilmente i dati tra diverse fonti di dati e destinazioni. I componenti principali sono:
-
Catalogo dati: un archivio di metadati che contiene definizioni di tabelle, definizioni di processi e altre informazioni di controllo per i flussi di lavoro ETL.
-
Crawler: programmi che si connettono alle origini dati, deducono gli schemi per i dati e creano definizioni di tabelle di metadati nel Catalogo dati.
-
Processi ETL: la logica aziendale per estrarre i dati dalle origini dati, trasformarli utilizzando script Apache Spark e caricarli nelle destinazioni.
-
Trigger: meccanismi per avviare l'esecuzione dei processi in base a pianificazioni o eventi.
Il flusso di lavoro tipico consiste nel:
-
Definire origini dati e destinazioni dati nel Catalogo dati.
-
Usare i crawler per popolare il Catalogo dati con i metadati delle tabelle provenienti dalle origini dati.
-
Definire i processi ETL con script di trasformazione per spostare ed elaborare i dati.
-
Eseguire processi on-demand o basati su trigger.
-
Monitorare le prestazioni lavorative utilizzando i pannelli di controllo.
Il diagramma seguente mostra l'architettura di un AWS Glue ambiente.
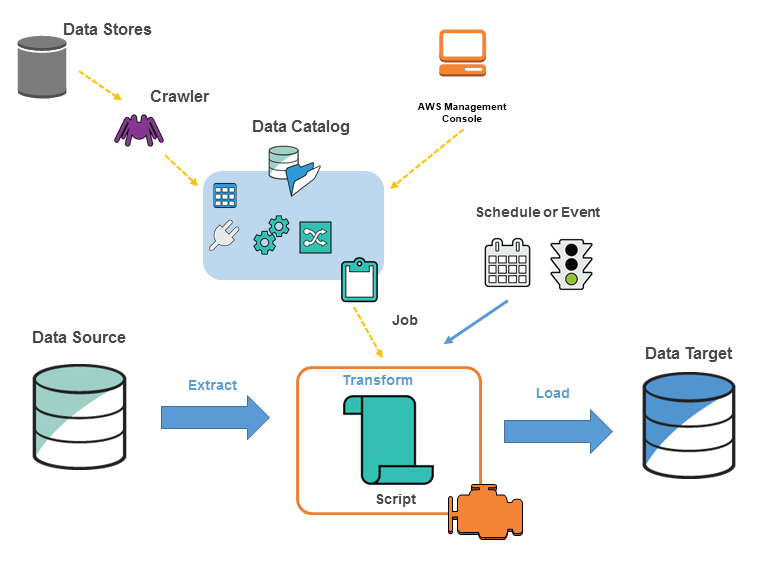
Si definiscono i lavori AWS Glue per eseguire il lavoro necessario per estrarre, trasformare e caricare i dati (ETL) da un'origine dati a una destinazione dati. In genere, si svolgono le azioni seguenti:
-
Per le origini dei datastore, si definisce un crawler per popolare il AWS Glue Data Catalog con definizioni di tabelle di metadati. Si punta il crawler a un datastore e il crawler crea le definizioni di tabelle nel catalogo dati. Per le origini di streaming, è possibile definire manualmente le tabelle del catalogo dati e specificare le proprietà del flusso dei dati.
Oltre alle definizioni delle tabelle, AWS Glue Data Catalog contiene altri metadati necessari per definire i job ETL. Si utilizzano questi metadati quando si definisce un processo per trasformare i dati.
AWS Glue può generare uno script per trasformare i dati. In alternativa, puoi fornire lo script nella AWS Glue console o nell'API.
-
È possibile eseguire il processo on demand oppure configurarlo affinché si avvii al verificarsi di un trigger specifico. Il trigger può essere una pianificazione basata sul tempo o un evento.
Durante l'esecuzione del processo, uno script estrae i dati dall'origine dati, li trasforma e li carica sulla destinazioni dati. Lo script viene eseguito in un ambiente Apache Spark in AWS Glue.
Importante
Le tabelle e i database in AWS Glue sono oggetti in AWS Glue Data Catalog. Essi contengono metadati, non dati provenienti da un datastore.
|
I dati basati su testo, ad esempio CSVs, devono essere codificati |
AWS Glue terminologia
AWS Glue si basa sull'interazione di diversi componenti per creare e gestire il flusso di lavoro di estrazione, trasformazione e caricamento (ETL).
AWS Glue Data Catalog
L'archivio persistente di metadati in. AWS Glue Contiene definizioni di tabelle, definizioni di processi e altre informazioni di controllo per la gestione AWS Glue dell'ambiente. Ogni AWS account ne ha uno AWS Glue Data Catalog per regione.
Classificatore
Determina lo schema dei tuoi dati. AWS Glue fornisce classificatori per tipi di file comuni, come CSV, JSON, AVRO, XML e altri. Fornisce inoltre classificatori per i più comuni sistemi di gestione di database relazionali utilizzando una connessione JDBC. Puoi scrivere un classificatore personalizzato usando un pattern grok o specificando un tag di riga in un documento XML.
Connessione
Un oggetto del catalogo dati che contiene le proprietà necessarie per connettersi a un particolare archivio dati.
Crawler
Programma che si connette a un datastore (di origine o di destinazione), avanza attraverso un elenco di classificatori ordinato per priorità per determinare lo schema dei dati e quindi crea tabelle di metadati nel AWS Glue Data Catalog.
Database
Set di definizioni di tabelle del catalogo dati associate organizzate in un gruppo logico.
Datastore, origine dati, target dati
Un datastore è un repository per archiviare i dati in modo permanente. Alcuni esempi includono bucket Amazon S3 e database relazionali. Un'origine dati è un datastore utilizzato come input per un processo o una trasformazione. Un target dati è un datastore su cui scrive un processo o una trasformazione.
Endpoint di sviluppo
Un ambiente che puoi usare per sviluppare e testare i tuoi script ETL. AWS Glue
Frame dinamico
Una tabella distribuita che supporta dati nidificati come strutture e array. Ogni record è auto descrittivo, progettato per la flessibilità dello schema con dati semi-strutturati. Ogni record contiene sia i dati, sia lo schema che li descrive. È possibile utilizzare sia frame dinamici che Apache Spark DataFrames negli script ETL e convertirli da uno all'altro. I frame dinamici forniscono una serie di trasformazioni avanzate per la pulizia dei dati e l'ETL.
Processo
Logica di business necessaria per eseguire il lavoro ETL. È composto da uno script di trasformazione, da origini dati e da destinazioni dati. Le esecuzioni dei processi sono avviate tramite trigger pianificabili o attivabili tramite eventi.
Pannello di controllo per le prestazioni del processo
AWS Glue fornisce una dashboard di esecuzione completa per i lavori ETL. Nel pannello di controllo vengono visualizzate informazioni sulle esecuzioni dei processi in un intervallo di tempo specifico.
Interfaccia notebook
Un'esperienza notebook migliorata con una configurazione in un solo clic per semplificare la creazione di processi e l'esplorazione dei dati. Il notebook e le connessioni vengono configurati automaticamente per te. È possibile utilizzare l'interfaccia per notebook basata su Jupyter Notebook per sviluppare, eseguire il debug e distribuire in modo interattivo script e flussi di lavoro utilizzando l'infrastruttura ETL Apache Spark senza server. AWS Glue Nell'ambiente notebook, è possibile anche eseguire query ad hoc, analisi dei dati e visualizzazione (ad esempio tabelle e grafici).
Script
Codice che estrae i dati dalle fonti, li trasforma e li carica in obiettivi. AWS Glue genera PySpark o script Scala.
Tabella
Definizione di metadati che rappresenta i tuoi dati. Sia che i dati siano in un file Amazon Simple Storage Service (Amazon S3), in una tabella Amazon Relational Database Service (Amazon RDS) o in un altro set di dati, una tabella definisce lo schema dei dati. Una tabella in AWS Glue Data Catalog è composta dai nomi delle colonne, dalle definizioni dei tipi di dati, dalle informazioni sulle partizioni e da altri metadati relativi a un set di dati di base. Lo schema dei dati è rappresentato nella definizione della tabella. AWS Glue I dati effettivi rimangono nell'archivio dati originale, che si tratti di un file o di una tabella di database relazionale. AWS Glue cataloga i file e le tabelle del database relazionale in. AWS Glue Data Catalog Questi fungono da origini e destinazioni quando si crea un processo ETL.
Trasformazione
Logica di codice utilizzata per modificare i dati in un formato diverso.
Trigger
Avvia un processo ETL. È possibile definire i trigger sulla base di un orario programmato o di un evento.
Editor visivo dei processi
L'editor visivo del processo è un'interfaccia grafica che consente di creare, eseguire e monitorare in modo semplice processi di estrazione, trasformazione e caricamento (ETL) in AWS Glue. Puoi comporre visivamente flussi di lavoro di trasformazione dei dati, eseguirli senza problemi sul motore ETL serverless basato su AWS Glue Apache Spark e ispezionare lo schema e i risultati dei dati in ogni fase del lavoro.
Worker
Con AWS Glue, paghi solo per il tempo necessario all'esecuzione del processo ETL. Non ci sono risorse da gestire, quindi non ti vengono addebitati costi anticipati e tariffe per il tempo di avvio o di arresto. Ti viene addebitata una tariffa oraria basata sul numero di unità di elaborazione dati (o DPUs) utilizzate per eseguire il processo ETL. Una singola unità di elaborazione dati (DPU) viene anche definita lavoratore. AWS Glue viene fornito con diversi tipi di worker per aiutarvi a selezionare la configurazione più adatta ai vostri requisiti di latenza lavorativa e costi. I worker sono disponibili nelle configurazioni Standard, G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, G.025X e nelle configurazioni R.1X, R.2X, R.8X e R.8X ottimizzate per la memoria.
