Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Connessioni Redshift
Puoi usare AWS Glue for Spark per leggere e scrivere su tabelle nei database Amazon Redshift. Quando si connette ai database Amazon Redshift, AWS Glue sposta i dati tramite Amazon S3 per ottenere il massimo throughput, utilizzando SQL e comandi Amazon Redshift. COPY UNLOAD In AWS Glue 4.0 e versioni successive, puoi utilizzare l'integrazione Amazon Redshift per Apache Spark per leggere e scrivere con ottimizzazioni e funzionalità specifiche di Amazon Redshift oltre a quelle disponibili durante la connessione tramite versioni precedenti.
Scopri come AWS Glue sta semplificando più che mai per gli utenti di Amazon Redshift la migrazione a AWS Glue per l'integrazione dei dati senza server e l'ETL.
Configurazione delle connessioni Redshift
Per utilizzare i cluster Amazon Redshift in AWS Glue, sono necessari alcuni prerequisiti:
-
Una directory Amazon S3 da utilizzare per l'archiviazione temporanea durante la lettura e la scrittura sul database.
-
Un Amazon VPC che consente la comunicazione tra il cluster Amazon Redshift, il job AWS Glue e la directory Amazon S3.
-
Autorizzazioni IAM appropriate sul job AWS Glue e sul cluster Amazon Redshift.
Configurazione dei ruoli IAM
Configurazione del ruolo per il cluster Amazon Redshift
Il tuo cluster Amazon Redshift deve essere in grado di leggere e scrivere su Amazon S3 per integrarsi con AWS Glue jobs. Per consentire ciò, puoi associare i ruoli IAM al cluster Amazon Redshift a cui desideri connetterti. Il tuo ruolo dovrebbe disporre di una policy che consenta la lettura e la scrittura nella tua directory temporanea di Amazon S3. Il tuo ruolo dovrebbe avere un rapporto di fiducia che consenta al servizio redshift.amazonaws.com di AssumeRole.
Associazione di un ruolo IAM ad Amazon Redshift
Prerequisiti: un bucket o una directory Amazon S3 utilizzato per l'archiviazione temporanea dei file.
-
Identifica le autorizzazioni Amazon S3 che occorreranno al cluster Amazon Redshift. Quando si spostano dati da e verso un cluster Amazon Redshift, i job AWS Glue emettono istruzioni COPY e UNLOAD su Amazon Redshift. Se il tuo job modifica una tabella in Amazon Redshift, AWS Glue emetterà anche istruzioni CREATE LIBRARY. Per informazioni sulle autorizzazioni specifiche di Amazon S3 necessarie ad Amazon Redshift per eseguire queste istruzioni, consulta la documentazione di Amazon Redshift: Amazon Redshift: Permissions to access other Resources. AWS
Nella console IAM, crea una policy IAM con le autorizzazioni necessarie. Per ulteriori informazioni sulla creazione di una policy, consulta la pagina Creazione di policy IAM.
Da IAM, crea un ruolo e un rapporto di fiducia che consenta ad Amazon Redshift di assumere il ruolo. Segui le istruzioni nella documentazione IAM Per creare un ruolo per un servizio (console) AWS
Quando ti viene chiesto di scegliere un caso d'uso del AWS servizio, scegli «Redshift - Personalizzabile».
Quando ti viene chiesto di collegare una policy, scegli la policy che hai definito in precedenza.
Nota
Per ulteriori informazioni sulla configurazione dei ruoli per Amazon Redshift, consulta Autorizzazione di Amazon Redshift ad AWS accedere ad altri servizi per tuo conto nella documentazione di Amazon Redshift.
Da Amazon Redshift, associa il ruolo al tuo cluster Amazon Redshift. Segui le istruzioni nella documentazione di Amazon Redshift.
Seleziona l'opzione evidenziata nella console Amazon Redshift per configurare questa impostazione:
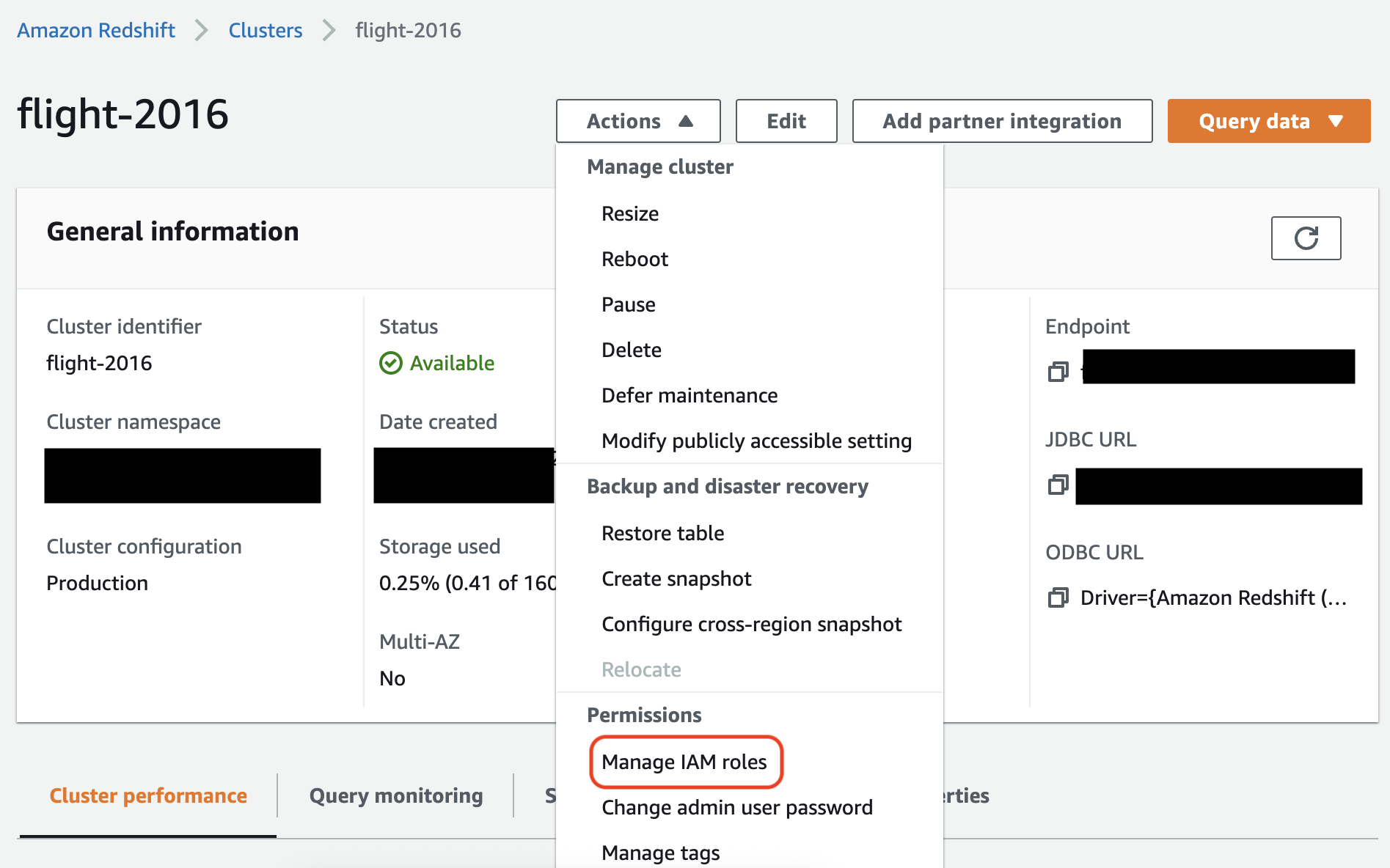
Nota
Per impostazione predefinita, i lavori AWS Glue passano le credenziali temporanee di Amazon Redshift create utilizzando il ruolo che hai specificato per eseguire il lavoro. Non è consigliabile utilizzare queste credenziali. Per motivi di sicurezza, queste credenziali scadono dopo 1 ora.
Imposta il ruolo per AWS Glue job
Il job AWS Glue richiede un ruolo per accedere al bucket Amazon S3. Non sono necessarie le autorizzazioni IAM per il cluster Amazon Redshift, il tuo accesso è controllato dalla connettività in Amazon VPC e dalle credenziali del database.
Configurazione di Amazon VPC
Per configurare l'accesso ai datastore Amazon Redshift
Accedi a AWS Management Console e apri la console Amazon Redshift all'indirizzo. https://console.aws.amazon.com/redshiftv2/
-
Nel pannello di navigazione a sinistra, seleziona Cluster.
-
Seleziona il nome del cluster al quale desideri accedere da AWS Glue.
-
Nella sezione Proprietà cluster scegli un gruppo di sicurezza in Gruppi di sicurezza VPC per permettere l'uso a AWS Glue. Registra il nome del gruppo di sicurezza scelto per riferimenti futuri. La scelta del gruppo di sicurezza apre l'elenco Gruppi di sicurezza della console Amazon EC2.
-
Scegli il gruppo di sicurezza da modificare e passa alla scheda In entrata.
-
Aggiungi una regola autoreferenziale per permettere ai componenti di AWS Glue di comunicare tra loro. In particolare, aggiungi o verifica che sia presente una regola con Tipo
All TCP, ProtocolloTCP, Intervallo porte che include tutte le porte e Origine corrispondente al nome del gruppo di sicurezza indicato da ID gruppo.La regola in entrata è simile alla seguente:
Tipo Protocollo Intervallo porte Origine Tutte le regole TCP
TCP
0–65535
database-security-group
Ad esempio:
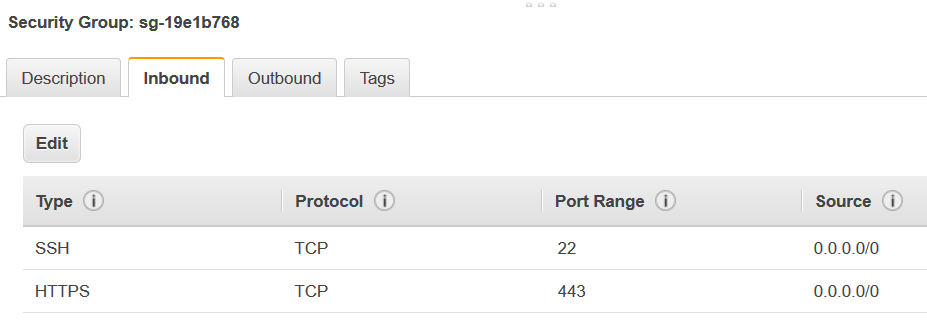
-
Aggiungi una regola anche per il traffico in uscita. Quindi, apri il traffico in uscita per tutte le porte, ad esempio:
Tipo Protocollo Intervallo porte Destinazione All Traffic
ALL
ALL
0.0.0. 0/0
In alternativa, crea una regola autoreferenziale in cui Tipo
All TCP, Protocollo sta perTCPe Intervallo porte include tutte le porte, la cui Destinazione ha lo stesso nome del gruppo di sicurezza dell'ID gruppo. Se usi un endpoint VPC Amazon S3, aggiungi anche una regola HTTPS per l'accesso di Amazon S3.s3-prefix-list-idÈ necessario nella regola del gruppo di sicurezza per consentire il traffico dal VPC all'endpoint VPC Amazon S3.Esempio:
Tipo Protocollo Intervallo porte Destinazione Tutte le regole TCP
TCP
0–65535
security-groupHTTPS
TCP
443
s3-prefix-list-id
Configurazione AWS Aderenza
Dovrai creare una connessione AWS Glue Data Catalog che fornisca informazioni sulla connessione Amazon VPC.
Per configurare la connettività Amazon Redshift Amazon VPC su AWS Glue nella console
-
Crea una connessione a Catalogo dati seguendo i passaggi indicati nella sezione Aggiungere una AWS Glue connessione. Dopo aver creato la connessione, mantieni il nome della connessione per il passaggio successivo.
connectionNameQuando selezioni un Tipo di connessione, seleziona Amazon Redshift.
Quando selezioni un Cluster Redshift, seleziona il tuo cluster in base al nome.
Fornisci informazioni di connessione predefinite per un utente Amazon Redshift sul tuo cluster.
Le impostazioni di Amazon VPC verranno configurate automaticamente.
Nota
Quando crei una connessione Amazon Redshift tramite l'SDK AWS , dovrai fornire manualmente il valore
PhysicalConnectionRequirementsper il tuo Amazon VPC. -
Nella configurazione del lavoro AWS Glue, fornisci
connectionNameuna connessione di rete aggiuntiva.
Esempio: lettura da tabelle Amazon Redshift
È possibile leggere da cluster Amazon Redshift e ambienti Amazon Redshift serverless.
Prerequisiti: una tabella Amazon Redshift da cui desideri leggere. Segui i passaggi della sezione precedente, Configurazione delle connessioni Redshift dopodiché dovresti avere l'URI Amazon S3 per una directory temporanea temp-s3-dir e un ruolo IAM,rs-role-name, (nell'accountrole-account-id).
Esempio: scrittura su tabelle Amazon Redshift
È possibile scrivere su cluster Amazon Redshift e ambienti Amazon Redshift serverless.
Prerequisiti: un cluster Amazon Redshift e segui i passaggi della Configurazione delle connessioni Redshift sezione precedente, dopodiché dovresti avere l'URI Amazon S3 per una directory temporanea e un ruolo rs-role-name IAMtemp-s3-dir,, (nell'account). role-account-id Avrai anche bisogno di un DynamicFrame del quale desideri scrivere il contenuto nel database.
Indicazioni di riferimento alle opzione di connessione ad Amazon Redshift
Le opzioni di connessione di base utilizzate per tutte le connessioni JDBC AWS Glue per configurare informazioni come url user e password sono coerenti per tutti i tipi JDBC. Per ulteriori informazioni sui parametri JDBC standard, consulta la pagina Indicazioni di riferimento alle opzioni di connessione a JDBC.
Il tipo di connessione Amazon Redshift richiede alcune opzioni di connessione aggiuntive:
-
"redshiftTmpDir": (obbligatorio) il percorso Amazon S3 in cui i dati temporanei possono essere caricati durante la copia dal database. -
"aws_iam_role": (facoltativo) l'ARN di un ruolo IAM. Il job AWS Glue passerà questo ruolo al cluster Amazon Redshift per concedere al cluster le autorizzazioni necessarie per completare le istruzioni del job.
Opzioni di connessione aggiuntive disponibili in AWS Glue 4.0+
Puoi anche passare le opzioni per il nuovo connettore Amazon Redshift tramite le opzioni di connessione AWS Glue. Per un elenco completo delle opzioni di connettori supportate, consulta la sezione Parametri SQL Spark in Integrazione di Amazon Redshift per Apache Spark.
Per comodità, ribadiamo di seguito alcune nuove opzioni:
| Nome | Obbligatorio | Predefinita | Description |
|---|---|---|---|
| autopushdown |
No | TRUE | Applica il pushdown di predicati e query acquisendo e analizzando i piani logici di Spark per le operazioni SQL. Le operazioni vengono tradotte in una query SQL e quindi eseguite in Amazon Redshift per migliorare le prestazioni. |
| autopushdown.s3_result_cache |
No | FALSE | Memorizza nella cache la query SQL per scaricare i dati sulla mappatura dei percorsi di Amazon S3 in memoria, in modo che la stessa query non debba essere eseguita nuovamente nella stessa sessione di Spark. Supportato solo quando |
| unload_s3_format |
No | PARQUET | PARQUET: scarica i risultati della query in formato Parquet. TESTO: scarica i risultati della query in formato testo delimitato da barra verticale. |
| sse_kms_key |
No | N/A | La AWS SSE-KMS chiave da utilizzare per la crittografia durante |
| extracopyoptions |
No | N/A | Un elenco di opzioni ulteriori da aggiungere al comando È importante notare che, poiché queste opzioni vengono aggiunte alla fine del comando |
| cvsnullstring (sperimentale) |
No | NULL | Il valore di stringa da scrivere per i valori null quando si utilizza il |
Questi nuovi parametri possono essere utilizzati nei seguenti modi.
Nuove opzioni per il miglioramento delle prestazioni
Il nuovo connettore introduce alcune nuove opzioni di miglioramento delle prestazioni:
-
autopushdown: abilitato per impostazione predefinita. -
autopushdown.s3_result_cache: disabilitato per impostazione predefinita. -
unload_s3_format:PARQUETper impostazione predefinita.
Per informazioni sull'utilizzo di queste opzioni, consultare Integrazione di Amazon Redshift per Apache Spark. Si consiglia di non attivare
autopushdown.s3_result_cache quando si eseguono operazioni di lettura e scrittura miste perché i risultati memorizzati nella cache potrebbero contenere informazioni obsolete. L'opzione unload_s3_format è impostata su PARQUET per impostazione predefinita per il comando UNLOAD per migliorare le prestazioni e ridurre i costi di archiviazione. Per utilizzare il comportamento predefinito del comando UNLOAD, reimposta l'opzione su TEXT.
Nuova opzione di crittografia per la lettura
Per impostazione predefinita, i dati nella cartella temporanea utilizzata da AWS Glue durante la lettura dei dati dalla tabella Amazon Redshift vengono crittografati tramite la crittografia SSE-S3. Per utilizzare le chiavi gestite dai clienti di AWS Key Management Service (AWS KMS) per crittografare i dati, puoi impostare da ("sse_kms_key"
→ kmsKey) dove proviene KSMKey l'ID della chiave AWS KMS, anziché l'opzione di impostazione precedente ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") nella AWS Glue versione 3.0.
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
Supporta l' IAM-based URL JDBC
Il nuovo connettore supporta un URL IAM-based JDBC, quindi non è necessario inserire un segreto or. user/password Con un URL IAM-based JDBC, il connettore utilizza il ruolo Job Runtime per accedere all'origine dati di Amazon Redshift.
Fase 1: collegamento della seguente politica minima obbligatoria al ruolo di runtime del processo AWS Glue.
Passaggio 2: utilizza l'URL IAM-based JDBC come segue. Specifica una nuova opzione DbUser con il nome utente Amazon Redshift con cui ti stai connettendo.
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
Nota
DynamicFrameAttualmente A supporta solo un URL IAM-based JDBC con un
DbUser nel flusso di lavoro. GlueContext.create_dynamic_frame.from_options
Migrazione da AWS Aderenza dalla versione 3.0 alla versione 4.0
In AWS Glue 4.0, i job ETL hanno accesso a un nuovo connettore Amazon Redshift Spark e a un nuovo driver JDBC con diverse opzioni e configurazioni. Il nuovo connettore e driver Amazon Redshift sono stati progettati per le prestazioni e garantiscono la coerenza transazionale dei dati. Questi prodotti sono illustrati nella documentazione di Amazon Redshift. Per ulteriori informazioni, consulta:
Table/column limitazione di nomi e identificatori
Il nuovo connettore e il driver Amazon Redshift Spark hanno un requisito più limitato per il nome della tabella Redshift. Per ulteriori informazioni, consulta Nomi e identificatori per definire il nome della tabella Amazon Redshift. Il flusso di lavoro relativo ai segnalibri del processo potrebbe non funzionare con un nome di tabella che non corrisponde alle regole e con determinati caratteri, ad esempio uno spazio.
Se hai tabelle legacy con nomi non conformi alle regole dei nomi e degli identificatori e riscontri problemi con i segnalibri (processi che rielaborano i vecchi dati delle tabelle Amazon Redshift), ti consigliamo di rinominare le tabelle. Per ulteriori informazioni, consultare Esempi di ALTER TABLE.
Modifica del formato temporale predefinito in Dataframe
Il connettore Spark di AWS Glue versione 3.0 imposta automaticamente tempformat su CSV durante la scrittura su Amazon Redshift. Per continuità, in AWS Glue versione 3.0,
DynamicFrame è ancora impostato su tempformat per l'uso di CSV. Se in precedenza hai utilizzato le API Spark Dataframe direttamente con il connettore Spark di Amazon Redshift, puoi impostare tempformat in modo esplicito su CSV nelle opzioni DataframeReader/Writer. Altrimenti, tempformat è impostato su AVRO nel nuovo connettore Spark.
Modifica di comportamento: associazione del tipo di dati Amazon Redshift REAL al tipo di dati Spark FLOAT anziché DOUBLE
In AWS Glue versione 3.0, Amazon Redshift REAL viene convertito in un tipo
DOUBLE Spark. Il nuovo connettore Amazon Redshift Spark ha aggiornato il comportamento in modo che il tipo
REAL Amazon Redshift venga viene convertito e di nuovo dal tipo FLOAT Spark. Se si dispone di un caso d'uso precedente in cui si desidera ancora che il tipo REAL Amazon Redshift sia mappato a un tipo DOUBLE Spark, è possibile utilizzare la seguente soluzione alternativa:
-
Per un
DynamicFrame, mappa il tipoFloata un tipoDoubleconDynamicFrame.ApplyMapping. Per unDataframe, è necessario usarecast.
Esempio di codice:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
Gestione del tipo di dati VARBYTE
Quando si lavora con tipi di dati AWS Glue 3.0 e Amazon Redshift, AWS Glue 3.0 converte Amazon VARBYTE Redshift in tipo Spark. STRING Tuttavia, il connettore Spark Amazon Redshift più recente non supporta il tipo di dati VARBYTE. Per aggirare questa limitazione, è possibile creare una vista Redshift che trasformi le colonne VARBYTE in un tipo di dati supportato. In seguito, è possibile utilizzare il nuovo connettore per caricare i dati da questa vista anziché dalla tabella originale, in modo da garantire la compatibilità pur mantenendo l'accesso ai dati VARBYTE.
Esempio di query Redshift:
CREATE VIEWview_nameAS SELECT FROM_VARBYTE(varbyte_column, 'hex') FROMtable_name
