Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Connettore DynamoDB con supporto Spark DataFrame
Il connettore DynamoDB con supporto DataFrame Spark consente di leggere e scrivere su tabelle in DynamoDB utilizzando le API Spark. DataFrame I passaggi di configurazione del connettore sono gli stessi del connettore e sono disponibili qui. DynamicFrame-based
Per caricare la libreria dei DataFrame-based connettori, assicurati di collegare una connessione DynamoDB al job Glue.
Nota
L'interfaccia utente della console Glue attualmente non supporta la creazione di una connessione DynamoDB. Puoi usare Glue CLI (CreateConnection) per creare una connessione DynamoDB:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
Dopo aver creato la connessione DynamoDB, puoi collegarla al tuo lavoro Glue tramite CLI CreateJob(UpdateJob,) o direttamente nella pagina «Dettagli del lavoro»:
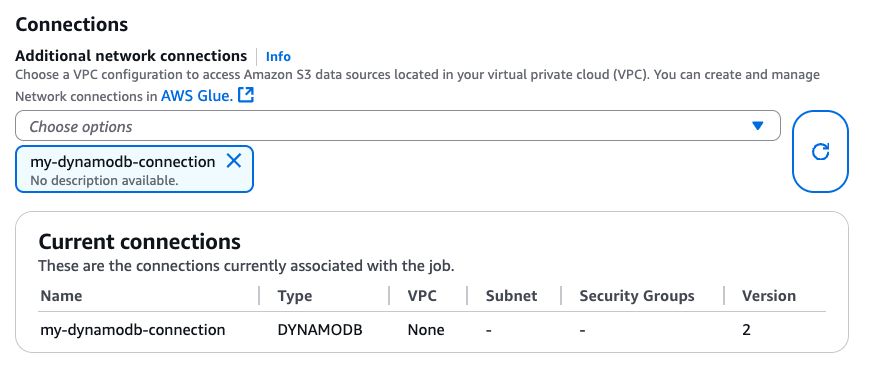
Dopo esserti assicurato che una connessione con DYNAMODB Type sia collegata al tuo lavoro Glue, puoi utilizzare le seguenti operazioni di lettura, scrittura ed esportazione dal connettore. DataFrame-based
Lettura e scrittura su DynamoDB con il connettore DataFrame-based
I seguenti esempi di codice mostrano come leggere e scrivere su tabelle DynamoDB tramite il connettore. DataFrame-based Mostrano la lettura da una tabella e la scrittura su un'altra tabella.
Utilizzo dell'esportazione DynamoDB tramite il connettore DataFrame-based
L'operazione di esportazione è preferita all'operazione di lettura per tabelle DynamoDB di dimensioni superiori a 80 GB. I seguenti esempi di codice mostrano come leggere da una tabella, esportare in S3 e stampare il numero di partizioni tramite il connettore. DataFrame-based
Nota
La funzionalità di esportazione DynamoDB è disponibile tramite l'oggetto Scala. DynamoDBExport Gli utenti Python possono accedervi tramite l'interoperabilità JVM di Spark o utilizzare l'SDK AWS per Python (boto3) con l'API DynamoDB. ExportTableToPointInTime
Opzioni di configurazione
Opzioni di lettura
| Opzione | Description | Predefinita |
|---|---|---|
dynamodb.input.tableName |
Nome della tabella DynamoDB (obbligatorio) | - |
dynamodb.throughput.read |
Le unità di capacità di lettura (RCU) da utilizzare. Se non specificato, dynamodb.throughput.read.ratio viene utilizzato per il calcolo. |
- |
dynamodb.throughput.read.ratio |
Il rapporto tra unità di capacità di lettura (RCU) da utilizzare | 0,5 |
dynamodb.table.read.capacity |
La capacità di lettura della tabella su richiesta utilizzata per il calcolo della velocità effettiva. Questo parametro è valido solo nelle tabelle di capacità su richiesta. L'impostazione predefinita sono le unità di lettura a throughput caldo. | - |
dynamodb.splits |
Definisce il numero di segmenti utilizzati nelle operazioni di scansione parallela. Se non viene fornito, il connettore calcolerà un valore predefinito ragionevole. | - |
dynamodb.consistentRead |
Se utilizzare letture fortemente coerenti | FALSE |
dynamodb.input.retry |
Definisce quanti tentativi eseguiamo quando esiste un'eccezione riprovabile. | 10 |
Opzioni di scrittura
| Opzione | Description | Predefinita |
|---|---|---|
dynamodb.output.tableName |
Nome della tabella DynamoDB (obbligatorio) | - |
dynamodb.throughput.write |
Le unità di capacità di scrittura (WCU) da utilizzare. Se non specificato, dynamodb.throughput.write.ratio viene utilizzato per il calcolo. |
- |
dynamodb.throughput.write.ratio |
Il rapporto tra unità di capacità di scrittura (WCU) da utilizzare | 0,5 |
dynamodb.table.write.capacity |
La capacità di scrittura della tabella su richiesta utilizzata per il calcolo della velocità effettiva. Questo parametro è valido solo nelle tabelle di capacità su richiesta. L'impostazione predefinita sono le unità di scrittura con throughput caldo. | - |
dynamodb.item.size.check.enabled |
Se vero, il connettore calcola la dimensione dell'elemento e interrompe l'operazione se la dimensione supera la dimensione massima, prima di scrivere nella tabella DynamoDB. | TRUE |
dynamodb.output.retry |
Definisce il numero di tentativi da eseguire in presenza di un'eccezione riutilizzabile. | 10 |
Opzioni di esportazione
| Opzione | Description | Predefinita |
|---|---|---|
dynamodb.export |
Se impostato su, ddb abilita il connettore di esportazione AWS Glue DynamoDB dove verrà richiamato un ExportTableToPointInTimeRequet nuovo connettore durante il AWS processo Glue. Verrà generata una nuova esportazione con la posizione passata da dynamodb.s3.bucket e dynamodb.s3.prefix. Se impostato su, s3 abilita il connettore di esportazione AWS Glue, DynamoDB, ma salta la creazione di una nuova esportazione DynamoDB e utilizza invece l'and dynamodb.s3.bucket come posizione Amazon S3 dynamodb.s3.prefix del passato esportato da quella tabella. |
ddb |
dynamodb.tableArn |
La tabella DynamoDB da cui leggere. Obbligatorio se dynamodb.export è impostato su ddb. |
|
dynamodb.simplifyDDBJson |
Se impostato sutrue, esegue una trasformazione per semplificare lo schema della struttura JSON di DynamoDB presente nelle esportazioni. |
FALSE |
dynamodb.s3.bucket |
Il bucket S3 per archiviare i dati temporanei durante l'esportazione in DynamoDB (obbligatorio) | |
dynamodb.s3.prefix |
Il prefisso S3 per archiviare dati temporanei durante l'esportazione in DynamoDB | |
dynamodb.s3.bucketOwner |
Indicare il proprietario del bucket necessario per l'accesso ad Amazon S3 su più account | |
dynamodb.s3.sse.algorithm |
Tipo di crittografia utilizzato nel bucket in cui verranno archiviati i dati temporanei. I valori validi sono AES256 e KMS. |
|
dynamodb.s3.sse.kmsKeyId |
L'ID della chiave AWS KMS gestita utilizzata per crittografare il bucket S3 in cui verranno archiviati i dati temporanei (se applicabile). | |
dynamodb.exportTime |
Un point-in-time in cui deve essere effettuata l'esportazione. Valori validi: stringhe che rappresentano istanti. ISO-8601 |
Opzioni generali
| Opzione | Description | Predefinita |
|---|---|---|
dynamodb.sts.roleArn |
Il ruolo IAM (ARN) da assumere per l'accesso tra account diversi | - |
dynamodb.sts.roleSessionName |
Nome della sessione STS | glue-dynamodb-sts-session |
dynamodb.sts.region |
Regione per il client STS (per l'assunzione di ruoli interregionali) | Uguale all'opzione region |
