Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un flusso di lavoro di abbinamento basato su regole con il tipo di regola Avanzata
Prerequisiti
Prima di creare un flusso di lavoro di abbinamento basato su regole, devi:
-
Creare una mappatura dello schema. Per ulteriori informazioni, consulta Creazione di una mappatura dello schema.
-
Se utilizzi Connect Customer Customer Profiles come destinazione di output, assicurati di aver configurato le autorizzazioni appropriate.
La procedura seguente illustra come creare un flusso di lavoro di abbinamento basato su regole con il tipo di regola avanzata utilizzando la AWS Entity Resolution console o l'API. CreateMatchingWorkflow
- Console
-
Per creare un flusso di lavoro di abbinamento basato su regole con Avanzata tipo di regola utilizzando la console
-
Accedi a Console di gestione AWS e apri la AWS Entity Resolution console all'indirizzo https://console.aws.amazon.com/entityresolution/
. -
Nel riquadro di navigazione a sinistra, in Flussi di lavoro, scegli Corrispondenza.
-
Nella pagina Flussi di lavoro corrispondenti, nell'angolo in alto a destra, scegli Crea flusso di lavoro corrispondente.
-
Per il passaggio 1: Specificare i dettagli del flusso di lavoro corrispondente, procedi come segue:
-
Immettete un nome del flusso di lavoro corrispondente e una descrizione opzionale.
-
Per l'immissione dei dati Regione AWS, scegli un AWS Glue database, la AWS Glue tabella e quindi la mappatura dello schema corrispondente.
È possibile aggiungere fino a 19 input di dati.
Nota
Per utilizzare le regole avanzate, le mappature dello schema devono soddisfare i seguenti requisiti:
-
Ogni campo di input deve essere mappato su una chiave di corrispondenza univoca, a meno che i campi non siano raggruppati insieme.
-
Se i campi di input sono raggruppati, possono condividere la stessa chiave di abbinamento.
Ad esempio, la seguente mappatura dello schema sarebbe valida per le regole avanzate:
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }In questo caso, i
lastNamecampifirstNameand sono raggruppati e condividono la stessa chiave di corrispondenza del nome, che è consentita.Rivedi le mappature dello schema e aggiornale per seguire questa regola di corrispondenza uno a uno, a meno che i campi non siano raggruppati correttamente, per utilizzare le regole avanzate.
-
Se la tabella di dati ha una colonna DELETE, il tipo di mappatura dello schema deve essere
Stringe non puoi avere un and.matchKeygroupName
-
-
L'opzione Normalizza dati è selezionata per impostazione predefinita, in modo che gli input di dati vengano normalizzati prima della corrispondenza. Se non desiderate normalizzare i dati, deselezionate l'opzione Normalizza dati.
Nota
La normalizzazione è supportata solo per i seguenti scenari in Create schema mapping:
-
Se i seguenti sottotipi di nome sono raggruppati: Nome, Secondo nome, Cognome.
-
Se i seguenti sottotipi di indirizzo sono raggruppati: Indirizzo 1, Indirizzo 2, Indirizzo 3, Città, Stato, Paese, Codice postale.
-
Se i seguenti sottotipi di telefono sono raggruppati: Numero di telefono, Prefisso telefonico del paese.
-
-
Per specificare le autorizzazioni di accesso al servizio, scegli un'opzione e intraprendi l'azione consigliata.
Opzione Azione consigliata Crea e utilizza un nuovo ruolo di servizio -
AWS Entity Resolution crea un ruolo di servizio con la politica richiesta per questa tabella.
-
Il nome del ruolo di servizio predefinito è
entityresolution-matching-workflow-<timestamp>. -
È necessario disporre delle autorizzazioni per creare ruoli e allegare politiche.
-
Se i dati di input sono crittografati, puoi scegliere l'opzione Questi dati sono crittografati con una chiave KMS e quindi inserire una AWS KMS chiave che verrà utilizzata per decrittografare i dati di input.
Usa un ruolo di servizio esistente -
Scegli il nome di un ruolo di servizio esistente dall'elenco a discesa.
L'elenco dei ruoli viene visualizzato se si dispone delle autorizzazioni per elencare i ruoli.
Se non disponi delle autorizzazioni per elencare i ruoli, puoi inserire l'Amazon Resource Name (ARN) del ruolo che desideri utilizzare.
Se non ci sono ruoli di servizio esistenti, l'opzione Usa un ruolo di servizio esistente non è disponibile.
-
Visualizza il ruolo di servizio scegliendo il link esterno View in IAM.
Per impostazione predefinita, AWS Entity Resolution non tenta di aggiornare la politica esistente sui ruoli per aggiungere le autorizzazioni necessarie.
-
-
(Facoltativo) Per abilitare i tag per la risorsa, scegliete Aggiungi nuovo tag, quindi immettete la coppia Chiave e Valore.
-
Scegli Next (Successivo).
-
-
Per la fase 2: Scegli la tecnica di abbinamento:
-
Per Metodo di abbinamento, scegli la Rule-basedcorrispondenza.
-
Per Tipo di regola, scegli Avanzate.
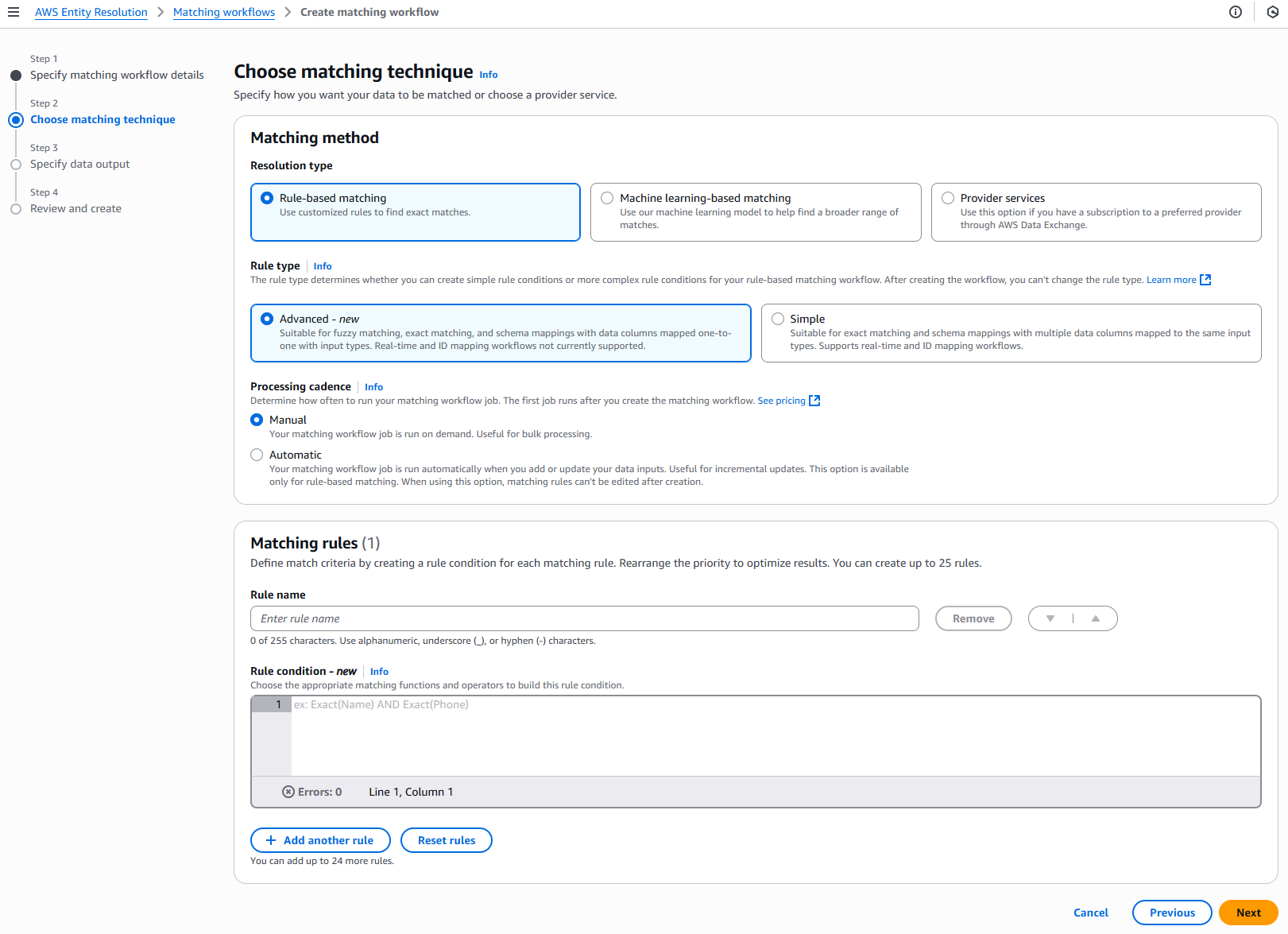
-
Per Processing cadence, selezionate una delle seguenti opzioni.
-
Scegliete Manuale per eseguire un flusso di lavoro su richiesta per un aggiornamento collettivo
-
Scegli Automatico per eseguire un flusso di lavoro non appena nuovi dati sono presenti nel tuo bucket S3
Nota
Se scegli Automatico, assicurati di avere EventBridge le notifiche Amazon attivate per il tuo bucket S3. Per istruzioni su come abilitare Amazon EventBridge tramite la console S3, consulta Enabling Amazon EventBridge nella Amazon S3 User Guide.
-
-
Per le regole di abbinamento, inserisci un nome per la regola e quindi crea la condizione della regola scegliendo le funzioni e gli operatori di corrispondenza appropriati dall'elenco a discesa in base al tuo obiettivo.
Puoi creare fino a 25 regole.
Nota
AWS Entity Resolution supporta anche la corrispondenza transitiva, che elabora i record su tutti i livelli di regole per connettere i gruppi di match in modo transitivo. La corrispondenza transitiva è disponibile come funzionalità. API-only Quando la corrispondenza transitiva è abilitata, il modificatore EmptyValues=Ignora non è supportato. Per ulteriori informazioni, consulta Utilizzo della corrispondenza transitiva.
È necessario combinare una funzione di corrispondenza fuzzy (Cosine, Levenshtein o Soundex) con una funzione di corrispondenza esatta (Exact,) utilizzando l'operatore AND. ExactManyToMany
È possibile utilizzare la tabella seguente per decidere quale tipo di funzione o operatore utilizzare, a seconda dell'obiettivo.
Il tuo obiettivo Funzione o operatore consigliato Modificatore opzionale consigliato Pro Abbina stringhe identiche su dati accurati ma non su valori vuoti. Esatto EmptyValues=Processo Abbina stringhe identiche su dati accurati e ignora i valori vuoti. Esatto () matchKeyEmptyValues=Ignora Abbina più record tra le chiavi di abbinamento. Adatto per abbinamenti flessibili. Limite: 15 match keys ExactManyToMany( matchKey,matchKey, ...)n/a Misura la somiglianza tra le rappresentazioni numeriche dei dati ma non corrisponde su valori vuoti. Adatto per testo, numeri o una combinazione di entrambi. Coseno EmptyValues=Processo Semplice, efficiente.
Funziona bene con testi lunghi se combinato con la TF-IDF ponderazione.
Ideale per una corrispondenza esatta basata sulle parole.
Misura la somiglianza tra le rappresentazioni numeriche dei dati e ignora i valori vuoti. Coseno (,,...) matchKeythresholdEmptyValues=Ignora Gestisce bene gli errori di battitura, gli errori di ortografia e le trasposizioni.
Efficace su un'ampia gamma di tipi di PII.
Ideale per stringhe brevi (ad esempio nomi o numeri di telefono).
Conta il numero minimo di modifiche necessarie per cambiare una parola in un'altra, ma non corrispondere su valori vuoti. Adatto per testi con lievi differenze di ortografia. Levenstein EmptyValues=Processo Conta il numero minimo di modifiche necessarie per cambiare una parola in un'altra e ignora i valori vuoti. Levenstein (,,...) matchKeythresholdEmptyValues=Ignora Confronta e abbina le stringhe di testo in base a quanto sembrano simili ma non corrispondono su valori vuoti. Adatto per testi con variazioni ortografiche o di pronuncia. Soundex EmptyValues=Processo Efficace per la corrispondenza fonetica, identificando parole dal suono simile.
Veloce e poco costoso dal punto di vista computazionale.
Ottimo per abbinare nomi con pronunce simili ma ortografie diverse.
Confronta e abbina le stringhe di testo in base alla somiglianza del suono e ignora i valori vuoti. Indice sonoro () matchKeyEmptyValues=Ignora Combina funzioni. E n/a Funzioni separate. OPPURE n/a Raggruppa le condizioni per creare condizioni annidate. (…) n/a Esempio Condizione della regola che corrisponde ai numeri di telefono e all'e-mail
Di seguito è riportato un esempio di condizione della regola che corrisponde ai record relativi ai numeri di telefono (Phone match key) e agli indirizzi e-mail (Email address match key):
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)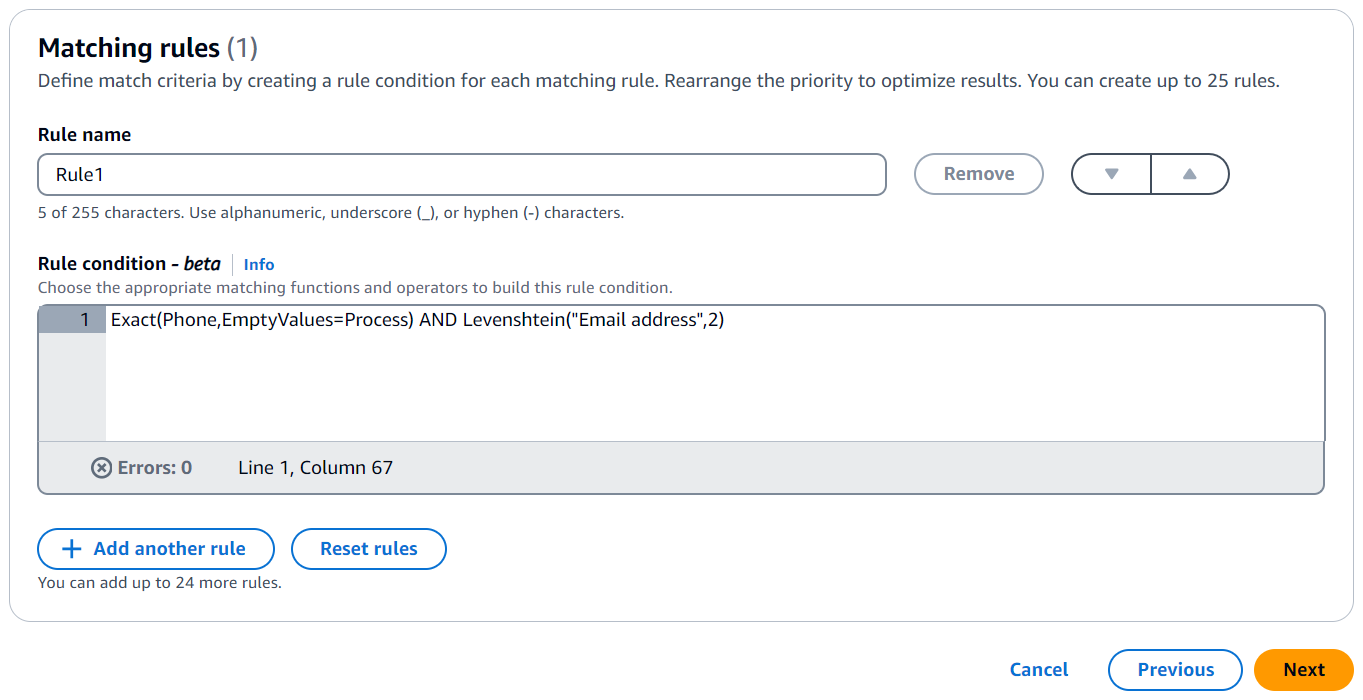
Il tasto Phone match utilizza la funzione Exact matching per abbinare stringhe identiche. Il tasto Phone match elabora i valori vuoti nella corrispondenza utilizzando il modificatore EmptyValues=Process.
La chiave Email address match utilizza la funzione di corrispondenza di Levenshtein per abbinare i dati con errori di ortografia utilizzando la soglia predefinita dell'algoritmo Levenshtein Distance pari a 2. La chiave Email match non utilizza alcun modificatore opzionale.
L'operatore AND combina la funzione Exact matching e la funzione di matching Levenshtein.
Esempio Condizione della regola utilizzata per eseguire la corrispondenza dei matchkey ExactManyToMany
Di seguito è riportato un esempio di condizione della regola che abbina i record in tre campi dell'indirizzo (HomeAddressmatch key, BillingAddressmatch key e ShippingAddressmatch key) per trovare potenziali corrispondenze controllando se ce ne sono alcune con valori identici.
L'
ExactManyToManyoperatore valuta tutte le possibili combinazioni dei campi di indirizzo specificati per identificare le corrispondenze esatte tra due o più indirizzi. Ad esempio, rileva se gli indirizziHomeAddresscorrispondono a o aBillingAddressoShippingAddressse tutti e tre gli indirizzi corrispondono esattamente.ExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)Esempio Condizione della regola che utilizza il clustering
In Advanced Rule Based Matching with Fuzzy Conditions, il sistema raggruppa innanzitutto i record in cluster in base alle corrispondenze esatte. Una volta formati questi cluster iniziali, il sistema applica filtri di corrispondenza fuzzy per identificare corrispondenze aggiuntive all'interno di ciascun cluster. Per prestazioni ottimali, è necessario selezionare condizioni di corrispondenza esatte in base ai modelli di dati per creare cluster iniziali ben definiti.
Di seguito è riportato un esempio di condizione della regola che combina più corrispondenze esatte con un requisito di corrispondenza fuzzy. Utilizza
ANDgli operatori per verificare che tre campiFullName, Data di nascita (DOB) eAddress, corrispondano esattamente tra i record. Consente inoltre piccole variazioni nelInternalIDcampo utilizzando una distanza di Levenshtein di.1La distanza di Levenshtein misura il numero minimo di modifiche a un carattere necessarie per modificare una stringa in un'altra. Una distanza pari a 1 significaInternalIDsche corrisponderà alla differenza di un solo carattere (ad esempio un singolo errore di battitura, cancellazione o inserimento). Questa combinazione di condizioni consente di identificare i record che molto probabilmente rappresentano la stessa entità, anche se vi sono piccole discrepanze nell'identificatore.Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
Scegli Next (Successivo).
-
-
Per la fase 3: Specificare l'output e il formato dei dati:
-
Per Destinazione e formato di output dei dati, scegli la posizione Amazon S3 per l'output dei dati e se il formato dei dati sarà Dati normalizzati o Dati originali.
-
Per la crittografia, se scegli di personalizzare le impostazioni di crittografia, inserisci la AWS KMS chiave ARN.
-
Visualizza l'output generato dal sistema.
-
Per l'output dei dati, decidi quali campi includere, nascondere o mascherare, quindi intraprendi le azioni consigliate in base ai tuoi obiettivi.
Il tuo obiettivo Azione consigliata Includi campi Mantieni lo stato di output come incluso. Nascondi i campi (escludi dall'output) Scegli il campo Output, quindi scegli Nascondi. Maschera i campi Scegli il campo Output, quindi scegli Hash output. Ripristina le impostazioni precedenti Scegliere Reimposta. -
Scegli Next (Successivo).
-
-
Per il passaggio 4: rivedi e crea:
-
Rivedi le selezioni effettuate per i passaggi precedenti e modificale se necessario.
-
Scegli Create and run (Crea ed esegui).
Viene visualizzato un messaggio che indica che il flusso di lavoro corrispondente è stato creato e che il processo è iniziato.
-
-
Nella pagina dei dettagli del flusso di lavoro corrispondente, nella scheda Metriche, visualizza quanto segue in Metriche dell'ultimo lavoro:
-
Il Job ID.
-
Lo stato del processo del flusso di lavoro corrispondente: In coda, In corso, Completato, Non riuscito
-
Il tempo di completamento del processo del flusso di lavoro.
-
Il numero di record elaborati.
-
Il numero di record non elaborati.
-
Gli ID di corrispondenza univoci generati.
-
Il numero di record di input.
Puoi anche visualizzare le metriche dei job per i job corrispondenti ai job del flusso di lavoro che sono stati eseguiti in precedenza nella cronologia Job.
-
-
Una volta completato il processo del flusso di lavoro corrispondente (lo stato è completato), puoi andare alla scheda Data output e quindi selezionare la tua sede Amazon S3 per visualizzare i risultati.
-
(Solo tipo di elaborazione manuale) Se hai creato un flusso di lavoro Rule-based corrispondente al tipo di elaborazione manuale, puoi eseguire il flusso di lavoro corrispondente in qualsiasi momento selezionando Esegui flusso di lavoro nella pagina dei dettagli del flusso di lavoro corrispondente.
-
(Solo tipo di elaborazione automatica) Se la tabella di dati ha una colonna DELETE, allora:
-
I record impostati su
truenella colonna DELETE vengono eliminati. -
I record impostati
falsenella colonna DELETE vengono inseriti in S3.
Per ulteriori informazioni, consulta Fase 1: Preparare tabelle di dati di prime parti.
-
-
- API
-
Per creare un flusso di lavoro di abbinamento basato su regole con il Avanzata tipo di regola che utilizza l'API
Nota
Per impostazione predefinita, il flusso di lavoro utilizza l'elaborazione standard (batch). Per utilizzare l'elaborazione incrementale (automatica), è necessario configurarla in modo esplicito.
-
Apri un terminale o un prompt dei comandi per effettuare la richiesta API.
-
Crea una richiesta POST per il seguente endpoint:
/matchingworkflows -
Nell'intestazione della richiesta, imposta su. Content-type application/json
Nota
Per un elenco completo dei linguaggi di programmazione supportati, consulta l'AWS Entity Resolution API Reference.
-
Per il corpo della richiesta, fornisci i seguenti parametri JSON richiesti:
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "stringDove:
-
workflowName(obbligatorio) — Deve essere univoco e deve contenere da 1 a 255 caratteri e corrispondere allo schema [a-z A-Z _0-9-] * -
inputSourceConfig(obbligatorio) — Elenco di 1—20 configurazioni delle sorgenti di ingresso -
outputSourceConfig(richiesto) — Esattamente una configurazione della sorgente di uscita -
resolutionTechniques(obbligatorio) — Imposta su «RULE_MATCHING» come ResolutionType per la corrispondenza basata su regole -
roleArn(obbligatorio) — Ruolo IAM ARN per l'esecuzione del flusso di lavoro -
ruleConditionProperties(obbligatorio): elenco delle condizioni della regola e nome della regola corrispondente.
I parametri opzionali includono:
-
description— Fino a 255 caratteri -
incrementalRunConfig— Configurazione incrementale del tipo di esecuzione -
tags— Fino a 200 coppie chiave-valore
-
-
(Facoltativo) Per utilizzare l'elaborazione incrementale anziché l'elaborazione standard predefinita (batch), aggiungete il seguente parametro al corpo della richiesta:
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
Inviare la richiesta .
-
In caso di successo, riceverai una risposta con il codice di stato 200 e un corpo JSON contenente:
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
Se la chiamata non va a buon fine, potresti ricevere uno di questi errori:
-
400 — ConflictException se il nome del flusso di lavoro esiste già
-
400 — ValidationException se la convalida dell'input non supera
-
402 — ExceedsLimitException se i limiti dell'account vengono superati
-
403 — AccessDeniedException se non disponi di un accesso sufficiente
-
429 — ThrottlingException se la richiesta è stata limitata
-
500 — InternalServerException se si verifica un errore interno del servizio
-
-
