Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Uso di notebook Jupyter in hosting autonomo
Puoi ospitare e gestire Jupyter o JupyterLab notebook su un'istanza Amazon EC2 o sul tuo cluster Amazon EKS come notebook Jupyter con hosting autonomo. Puoi quindi eseguire carichi di lavoro interattivi con i notebook Jupyter in hosting autonomo. Le sezioni seguenti illustrano il processo di configurazione e implementazione di un notebook Jupyter in hosting autonomo su un cluster Amazon EKS.
Creazione di un notebook Jupyter in hosting autonomo su un cluster EKS
Creare un gruppo di sicurezza
Prima di poter creare un endpoint interattivo ed eseguire un Jupyter o un notebook con hosting autonomo, è necessario creare un gruppo di sicurezza per controllare il traffico tra il JupyterLab notebook e l'endpoint interattivo. Per utilizzare la console Amazon EC2 o l'SDK Amazon EC2 per creare il gruppo di sicurezza, consulta i passaggi in Creare un gruppo di sicurezza nella Guida per l'utente di Amazon EC2. Dovresti creare il gruppo di sicurezza nel VPC in cui desideri installare il server notebook.
Per seguire l'esempio di questa guida, utilizza lo stesso VPC del cluster Amazon EKS. Se desideri ospitare il tuo notebook in un VPC diverso dal VPC del tuo cluster Amazon EKS, potresti dover creare una connessione peering tra i due. VPCs Per i passaggi per creare una connessione peering tra due VPCs, consulta Creare una connessione peering VPC nella Amazon VPC Getting Started Guide.
È necessario l'ID del gruppo di sicurezza per creare un endpoint interattivo Amazon EMR su EKS nella fase successiva.
Creazione di un endpoint interattivo Amazon EMR su EKS
Dopo aver creato un gruppo di sicurezza per il notebook, utilizza le fasi indicate in Creazione di un endpoint interattivo per il cluster virtuale per creare un endpoint interattivo. È necessario fornire l'ID del gruppo di sicurezza che hai creato per il notebook in Creare un gruppo di sicurezza.
Inserisci l'ID di sicurezza al posto di quello nelle seguenti impostazioni di your-notebook-security-group-id configurazione sostitutiva:
--configuration-overrides '{ "applicationConfiguration": [ { "classification": "endpoint-configuration", "properties": { "notebook-security-group-id": "your-notebook-security-group-id" } } ], "monitoringConfiguration": { ...'
Recupero dell'URL del server gateway dell'endpoint interattivo
Dopo aver creato un endpoint interattivo, recupera l'URL del server gateway con il comando describe-managed-endpoint nella AWS CLI. Questo URL è indispensabile per connettere il notebook all'endpoint. L'URL del server gateway è un endpoint privato.
aws emr-containers describe-managed-endpoint \ --regionregion\ --virtual-cluster-idvirtualClusterId\ --idendpointId
Inizialmente, l'endpoint si trova nello stato CREATING. Dopo alcuni minuti, passa allo stato ACTIVE. Quando è nello stato ACTIVE, l'endpoint è pronto per l'uso.
Prendi nota dell'attributo serverUrl che il comando aws emr-containers
describe-managed-endpoint restituisce dall'endpoint attivo. È necessario questo URL per connettere il notebook all'endpoint quando si distribuisce un Jupyter o un notebook ospitato autonomamente. JupyterLab
Recupero di un token di autenticazione per la connessione all'endpoint interattivo
Per connetterti a un endpoint interattivo da un Jupyter o da un JupyterLab notebook, devi generare un token di sessione con l'API. GetManagedEndpointSessionCredentials Il un token funge da prova di autenticazione per connetterti al server dell'endpoint interattivo.
Il comando seguente viene spiegato più nel dettaglio di seguito con un esempio di output.
aws emr-containers get-managed-endpoint-session-credentials \ --endpoint-identifierendpointArn\ --virtual-cluster-identifiervirtualClusterArn\ --execution-role-arnexecutionRoleArn\ --credential-type "TOKEN" \ --duration-in-secondsdurationInSeconds\ --regionregion
endpointArn-
L'ARN del tuo endpoint. Puoi trovare l'ARN nel risultato di una chiamata
describe-managed-endpoint. virtualClusterArn-
L'ARN del cluster virtuale.
executionRoleArn-
L'ARN del ruolo di esecuzione.
durationInSeconds-
La durata in secondi per la quale il token è valido. La durata predefinita è 15 minuti (
900) e il massimo è 12 ore (43200). region-
La stessa regione dell'endpoint.
L'output dovrebbe essere simile all'esempio seguente. Prendi nota del session-token
{
"id": "credentialsId",
"credentials": {
"token": "session-token"
},
"expiresAt": "2022-07-05T17:49:38Z"
}Esempio: implementa un notebook JupyterLab
Una volta completati i passaggi precedenti, puoi provare questa procedura di esempio per distribuire un JupyterLab notebook nel cluster Amazon EKS con il tuo endpoint interattivo.
-
Crea uno spazio dei nomi per eseguire il server notebook.
-
Crea un file localmente,
notebook.yaml, con i contenuti seguenti. I contenuti del file sono descritti di seguito.apiVersion: v1 kind: Pod metadata: name: jupyter-notebook namespace:namespacespec: containers: - name: minimal-notebook image: jupyter/all-spark-notebook:lab-3.1.4 # open source image ports: - containerPort: 8888 command: ["start-notebook.sh"] args: ["--LabApp.token=''"] env: - name: JUPYTER_ENABLE_LAB value: "yes" - name: KERNEL_LAUNCH_TIMEOUT value: "400" - name: JUPYTER_GATEWAY_URL value: "serverUrl" - name: JUPYTER_GATEWAY_VALIDATE_CERT value: "false" - name: JUPYTER_GATEWAY_AUTH_TOKEN value: "session-token"Se stai implementando un notebook Jupyter su un cluster solo per Fargate, etichetta il pod di Jupyter con un'etichetta
rolecome mostrato nell'esempio seguente:... metadata: name: jupyter-notebook namespace: default labels: role:example-role-name-labelspec: ...namespace-
Lo spazio dei nomi Kubernetes in cui viene implementato il notebook.
serverUrl-
L'attributo
serverUrlche il comandodescribe-managed-endpointha restituito in Recupero dell'URL del server gateway dell'endpoint interattivo. session-token-
L'attributo
session-tokenche il comandoget-managed-endpoint-session-credentialsha restituito in Recupero di un token di autenticazione per la connessione all'endpoint interattivo. KERNEL_LAUNCH_TIMEOUT-
La quantità di tempo espressa in secondi per cui l'endpoint interattivo attende che il kernel raggiunga lo stato RUNNING. Garantisci un tempo sufficiente per il completamento dell'avvio del kernel impostando il timeout di avvio del kernel su un valore appropriato (massimo 400 secondi).
KERNEL_EXTRA_SPARK_OPTS-
Facoltativamente, puoi trasmettere configurazioni Spark aggiuntive per i kernel Spark. Imposta questa variabile di ambiente con i valori come proprietà di configurazione Spark, come mostrato nell'esempio seguente:
- name: KERNEL_EXTRA_SPARK_OPTS value: "--conf spark.driver.cores=2 --conf spark.driver.memory=2G --conf spark.executor.instances=2 --conf spark.executor.cores=2 --conf spark.executor.memory=2G --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.shuffleTracking.enabled=true --conf spark.dynamicAllocation.minExecutors=1 --conf spark.dynamicAllocation.maxExecutors=5 --conf spark.dynamicAllocation.initialExecutors=1 "
-
Implementa una specifica di pod nel cluster Amazon EKS:
kubectl apply -f notebook.yaml -nnamespaceQuesto avvierà un JupyterLab notebook minimale collegato al tuo endpoint interattivo Amazon EMR su EKS. Attendi che il pod raggiunga lo stato RUNNING. Puoi verificarne lo stato con il comando seguente:
kubectl get pod jupyter-notebook -nnamespaceQuando il pod è pronto, il
get podcomando restituisce un output simile a questo:NAME READY STATUS RESTARTS AGE jupyter-notebook 1/1 Running 0 46s -
Collega il gruppo di sicurezza del notebook al nodo in cui il notebook è pianificato.
-
Per prima cosa, identifica il nodo in cui il pod
jupyter-notebookè pianificato con il comandodescribe pod.kubectl describe pod jupyter-notebook -nnamespace Apri la console Amazon EKS a https://console.aws.amazon.com/eks/home#/clusters
. -
Passa alla scheda Calcolo del cluster Amazon EKS e seleziona il nodo identificato dal comando
describe pod. Seleziona l'ID dell'istanza per il nodo. -
Nel menu Azioni, seleziona Sicurezza > Modifica gruppi di sicurezza per allegare il gruppo di sicurezza creato in Creare un gruppo di sicurezza.
-
Se stai implementando Jupyter Notebook Pod su AWS Fargate, crea un pod da applicare
SecurityGroupPolicyal notebook Jupyter con l'etichetta del ruolo:cat >my-security-group-policy.yaml <<EOF apiVersion: vpcresources.k8s.aws/v1beta1 kind: SecurityGroupPolicy metadata: name:example-security-group-policy-namenamespace: default spec: podSelector: matchLabels: role:example-role-name-labelsecurityGroups: groupIds: -your-notebook-security-group-idEOF
-
-
Ora esegui il port-forward in modo da poter accedere localmente all'interfaccia: JupyterLab
kubectl port-forward jupyter-notebook 8888:8888 -nnamespaceUna volta che è in esecuzione, accedi al tuo browser locale e visita
localhost:8888per vedere l' JupyterLab interfaccia:
-
Da JupyterLab, crea un nuovo taccuino Scala. Ecco un frammento di codice di esempio che puoi eseguire per approssimare il valore di Pi:
import scala.math.random import org.apache.spark.sql.SparkSession /** Computes an approximation to pi */ val session = SparkSession .builder .appName("Spark Pi") .getOrCreate() val slices = 2 // avoid overflow val n = math.min(100000L * slices, Int.MaxValue).toInt val count = session.sparkContext .parallelize(1 until n, slices) .map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y <= 1) 1 else 0 }.reduce(_ + _) println(s"Pi is roughly ${4.0 * count / (n - 1)}") session.stop()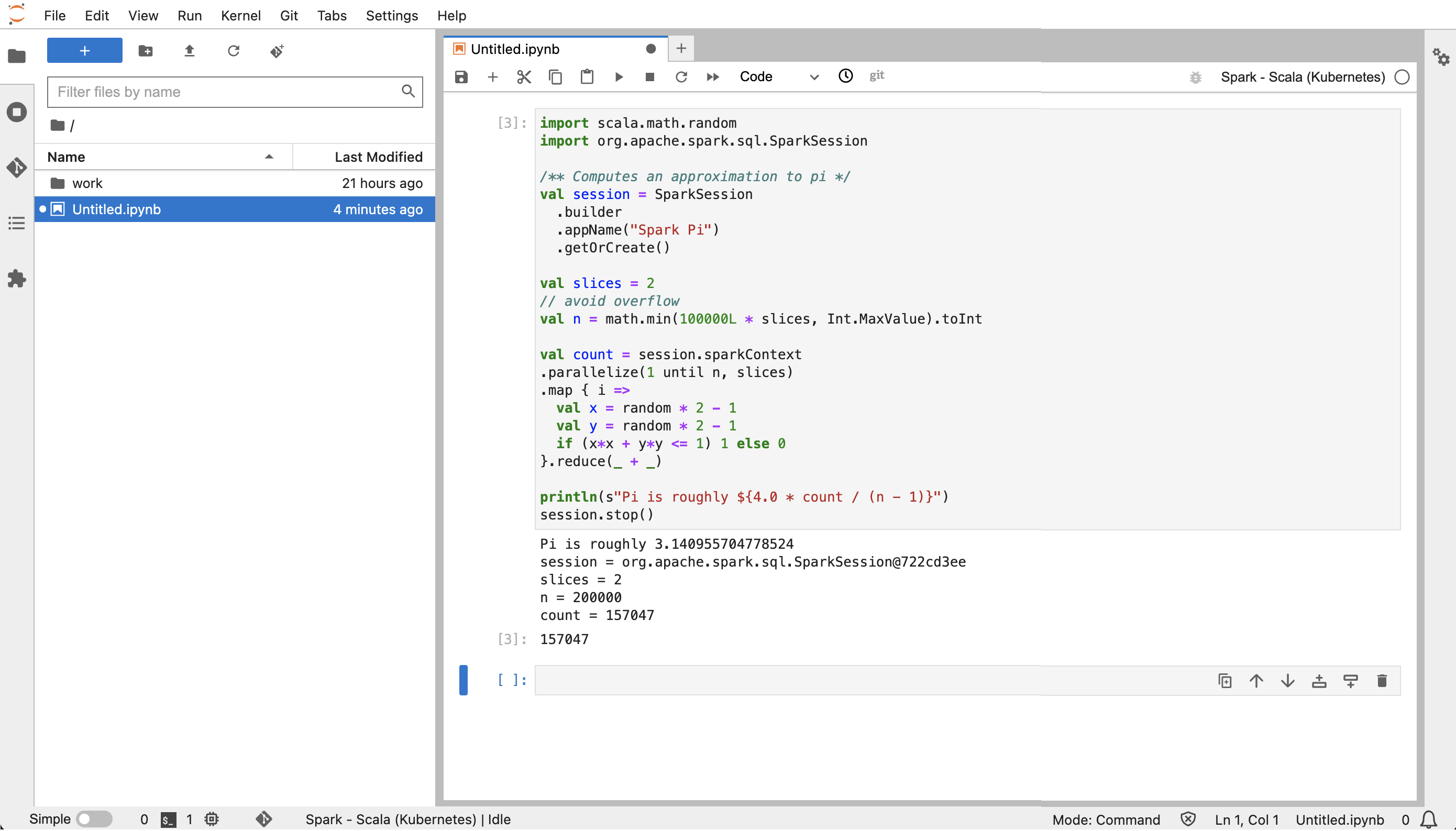
Eliminazione di un notebook Jupyter in hosting autonomo
Quando è il momento di eliminare il notebook in hosting autonomo, puoi eliminare anche l'endpoint interattivo e il gruppo di sicurezza. Esegui le azioni nell'ordine seguente:
-
Utilizza il comando seguente per eliminare il pod
jupyter-notebook:kubectl delete pod jupyter-notebook -nnamespace -
Quindi, elimina l'endpoint interattivo con il comando
delete-managed-endpoint. La procedura per l'eliminazione di un endpoint interattivo è riportata in Eliminazione di un endpoint interattivo. Inizialmente, l'endpoint si troverà nello stato TERMINATING. Una volta ripulite tutte le risorse, passa allo stato TERMINATED. -
Se non intendi utilizzare il gruppo di sicurezza dei notebook che hai creato in Creare un gruppo di sicurezza per altre implementazioni di notebook Jupyter, puoi eliminarlo. Per ulteriori informazioni, consulta Eliminazione di un gruppo di sicurezza nella Guida per l'utente di Amazon EC2.
