Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo di EMR Serverless conAWS Lake Formationper un controllo granulare degli accessi
Panoramica di
Con le versioni 7.2.0 e successive di Amazon EMR, sfrutta AWS Lake Formation per applicare controlli di accesso granulari alle tabelle di Data Catalog supportate da S3. Questa funzionalità consente di configurare i controlli di accesso a livello di tabella, riga, colonna e cella per read le query all'interno dei job Amazon EMR Serverless Spark. Per configurare un controllo granulare degli accessi per i processi batch e le sessioni interattive di Apache Spark, usa EMR Studio. Consulta le seguenti sezioni per saperne di più su Lake Formation e su come utilizzarlo con EMR Serverless.
L'utilizzo di Amazon EMR Serverless AWS Lake Formation comporta costi aggiuntivi. Per ulteriori informazioni, consulta i prezzi di Amazon EMR.
Come funziona EMR Serverless conAWS Lake Formation
L'utilizzo di EMR Serverless con Lake Formation ti consente di applicare un livello di autorizzazioni su ogni lavoro Spark per applicare il controllo delle autorizzazioni di Lake Formation quando EMR Serverless esegue i lavori. EMR Serverless utilizza i profili di risorse Spark per creare due profili per eseguire i
Quando utilizzi la capacità preinizializzata con Lake Formation, ti suggeriamo di avere almeno due driver Spark. Ogni Formation-enabled job Lake utilizza due driver Spark, uno per il profilo utente e uno per il profilo di sistema. Per ottenere prestazioni ottimali, utilizza il doppio del numero di driver per Lake Formation-enabled Jobs rispetto a chi non utilizza Lake Formation.
Quando esegui i job Spark su EMR Serverless, considera anche l'impatto dell'allocazione dinamica sulla gestione delle risorse e sulle prestazioni del cluster. La configurazione spark.dynamicAllocation.maxExecutors del numero massimo di esecutori per profilo di risorsa si applica agli esecutori utente e di sistema. Se si configura tale numero in modo che sia uguale al numero massimo consentito di executor, l'esecuzione del job potrebbe bloccarsi a causa di un tipo di executor che utilizza tutte le risorse disponibili, impedendo all'altro executor di eseguire i job di job.
Per non esaurire le risorse, EMR Serverless imposta il numero massimo predefinito di esecutori per profilo di risorsa al 90% del valore. spark.dynamicAllocation.maxExecutors È possibile sovrascrivere questa configurazione quando si specifica spark.dynamicAllocation.maxExecutorsRatio un valore compreso tra 0 e 1. Inoltre, configurate anche le seguenti proprietà per ottimizzare l'allocazione delle risorse e le prestazioni complessive:
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
Di seguito è riportata una panoramica di alto livello su come EMR Serverless ottiene l'accesso ai dati protetti dalle politiche di sicurezza di Lake Formation.
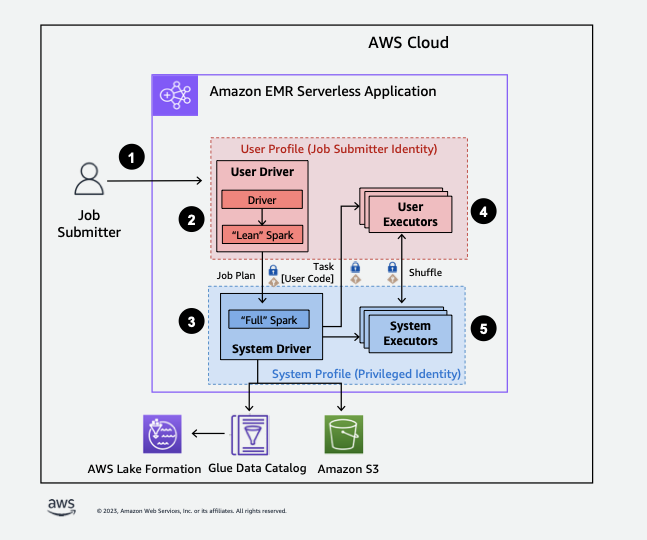
-
Un utente invia un job Spark a un'applicazione EMR AWS Lake Formation Serverless abilitata.
-
EMR Serverless invia il lavoro a un driver utente ed esegue il lavoro nel profilo utente. Il driver utente esegue una versione snella di Spark che non è in grado di avviare attività, richiedere esecutori, accedere a S3 o al catalogo di Glue. Costruisce un piano per il processo.
-
EMR Serverless imposta un secondo driver chiamato driver di sistema e lo esegue nel profilo di sistema (con un'identità privilegiata). EMR Serverless configura un canale TLS crittografato tra i due driver per la comunicazione. Il driver utente utilizza il canale per inviare i piani per il processo al driver di sistema. Il driver di sistema non esegue il codice inviato dall'utente. Esegue Spark completo e comunica con S3 e il catalogo dati per l'accesso ai dati. Richiede esecutori e compila il piano per il processo in una sequenza di fasi di esecuzione.
-
EMR Serverless esegue quindi le fasi sugli executor con il driver utente o il driver di sistema. Il codice utente in qualsiasi fase viene eseguito esclusivamente sugli esecutori dei profili utente.
-
Le fasi che leggono i dati dalle tabelle del Data Catalog protette da AWS Lake Formation o che applicano filtri di sicurezza vengono delegate agli esecutori di sistema.
Abilitazione di Lake Formation in Amazon EMR
Per abilitare Lake Formation, imposta spark.emr-serverless.lakeformation.enabled la true spark-defaults sottoclassificazione per il parametro di configurazione di runtime durante la creazione di un'applicazione EMR Serverless.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
Puoi anche abilitare Lake Formation quando crei una nuova applicazione in EMR Studio. Scegli Use Lake Formation per un controllo granulare degli accessi, disponibile in Configurazioni aggiuntive.
Inter-worker la crittografia è abilitata per impostazione predefinita quando si utilizza Lake Formation con EMR Serverless, quindi non è necessario abilitare nuovamente in modo esplicito la crittografia tra lavoratori.
Attivazione dei lavori di Lake Formation per Spark
Per abilitare Lake Formation per i singoli job Spark, imposta su spark.emr-serverless.lakeformation.enabled true durante l'utilizzospark-submit.
--conf spark.emr-serverless.lakeformation.enabled=true
Autorizzazioni IAM per il ruolo di runtime del processo
Le autorizzazioni di Lake Formation controllano l'accesso alle risorse di AWS Glue Data Catalog, alle sedi Amazon S3 e ai dati sottostanti in tali sedi. Le autorizzazioni IAM controllano l'accesso alle API e alle risorse di Lake Formation e AWS Glue. Anche se disponi dell'autorizzazione di Lake Formation per accedere a una tabella nel Data Catalog (SELECT), l'operazione fallisce se non disponi dell'autorizzazione IAM per il funzionamento dell'API glue:Get*.
Di seguito è riportato un esempio di policy su come fornire le autorizzazioni IAM per accedere a uno script in S3, caricare i log su S3, le autorizzazioni dell'API AWS Glue e l'autorizzazione per accedere a Lake Formation.
Configurazione delle autorizzazioni di Lake Formation per il ruolo di runtime del processo
Innanzitutto, registrare la posizione della tabella Hive con Lake Formation. Poi, creare le autorizzazioni per il ruolo di runtime del processo nella tabella desiderata. Per maggiori dettagli su Lake Formation, consulta What isAWS Lake Formation? nella Guida per gli AWS Lake Formation sviluppatori.
Dopo aver configurato le autorizzazioni di Lake Formation, invia i lavori Spark su Amazon EMR Serverless. Per ulteriori informazioni sui job Spark, consulta gli esempi di Spark.
Invio di un'esecuzione di processo
Dopo aver completato la configurazione delle sovvenzioni Lake Formation, puoi inviare lavori Spark su EMR Serverless. La sezione che segue mostra esempi di come configurare e inviare le proprietà del job run.
Requisiti per l'autorizzazione
Tabelle non registrate inAWS Lake Formation
Per le tabelle non registrate conAWS Lake Formation, il ruolo di job runtime accede sia al AWS Glue Data Catalog che ai dati della tabella sottostante in Amazon S3. Ciò richiede che il ruolo di job runtime disponga delle autorizzazioni IAM appropriate per le operazioni di AWS Glue e Amazon S3.
Tabelle registrate inAWS Lake Formation
Per le tabelle registrate conAWS Lake Formation, il ruolo di job runtime accede ai metadati di AWS Glue Data Catalog, mentre le credenziali temporanee fornite da Lake Formation accedono ai dati della tabella sottostante in Amazon S3. Le autorizzazioni Lake Formation necessarie per eseguire un'operazione dipendono dalle chiamate API di AWS Glue Data Catalog e Amazon S3 avviate dal job Spark e possono essere riassunte come segue:
-
L'autorizzazione DESCRIBE consente al ruolo di runtime di leggere i metadati di tabelle o database nel Data Catalog
-
L'autorizzazione ALTER consente al ruolo di runtime di modificare i metadati di tabelle o database nel Data Catalog
-
L'autorizzazione DROP consente al ruolo di runtime di eliminare i metadati di tabelle o database dal Data Catalog
-
L'autorizzazione SELECT consente al ruolo di runtime di leggere i dati della tabella da Amazon S3
-
L'autorizzazione INSERT consente al ruolo di runtime di scrivere dati di tabella su Amazon S3
-
L'autorizzazione DELETE consente al ruolo di runtime di eliminare i dati della tabella da Amazon S3
Nota
Lake Formation valuta le autorizzazioni senza fretta quando un job Spark chiama AWS Glue per recuperare i metadati della tabella e Amazon S3 per recuperare i dati della tabella. I lavori che utilizzano un ruolo di runtime con autorizzazioni insufficienti non falliranno finché Spark non effettuerà una chiamata AWS Glue o Amazon S3 che richiede l'autorizzazione mancante.
Nota
Nella seguente matrice di tabelle supportata:
-
Le operazioni contrassegnate come Supported utilizzano esclusivamente le credenziali di Lake Formation per accedere ai dati delle tabelle per le tabelle registrate con Lake Formation. Se le autorizzazioni di Lake Formation sono insufficienti, l'operazione non ricorrerà alle credenziali del ruolo di runtime. Per le tabelle non registrate con Lake Formation, le credenziali del ruolo di job runtime accedono ai dati della tabella.
-
Le operazioni contrassegnate come Supportate con autorizzazioni IAM sulla posizione Amazon S3 non utilizzano le credenziali di Lake Formation per accedere ai dati delle tabelle sottostanti in Amazon S3. Per eseguire queste operazioni, il ruolo di job runtime deve disporre delle autorizzazioni IAM di Amazon S3 necessarie per accedere ai dati della tabella, indipendentemente dal fatto che la tabella sia registrata con Lake Formation.
