Contribuisci a migliorare questa pagina
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per contribuire a questa guida per l'utente, scegli il GitHub link Modifica questa pagina nel riquadro destro di ogni pagina.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ulteriori informazioni relative allo spostamento zonale in controller di ripristino delle applicazioni Amazon (ARC)
Kubernetes dispone di funzionalità native che consentono di rendere le applicazioni più resistenti a eventi come il deterioramento dello stato di integrità o il deterioramento di una zona di disponibilità (AZ). Quando esegui i carichi di lavoro in un cluster Amazon EKS, è possibile migliorare ulteriormente la tolleranza ai guasti e il ripristino delle applicazioni dell’ambiente applicativo utilizzando lo spostamento zonale o lo spostamento zonale automatico del controller di ripristino delle applicazioni Amazon (ARC). Lo spostamento zonale ARC è progettato per essere una misura temporanea che consente di spostare il traffico di una risorsa lontano da una AZ interessata fino alla scadenza dello spostamento zonale o all’annullamento dello stesso. È possibile estendere lo spostamento zonale, se necessario.
Puoi avviare uno spostamento di zona per un cluster EKS oppure puoi consentire AWS di spostare il traffico per te abilitando lo spostamento automatico di zona. Questo spostamento aggiorna il flusso di traffico di rete da est a ovest nel cluster per considerare solo gli endpoint di rete per i pod in esecuzione su nodi worker in AZ integre. Inoltre, qualsiasi ALB o NLB che gestisce il traffico in ingresso per le applicazioni nel cluster EKS indirizzerà automaticamente il traffico verso le destinazioni nelle AZ integre. Per i clienti che cercano gli obiettivi di disponibilità più elevati, nel caso in cui una zona AZ sia compromessa, può essere importante consentire di indirizzare tutto il traffico lontano dalla AZ compromessa fino a quando non si ripristina. Per questo, puoi anche abilitare ALB o NLB con spostamento zonale ARC.
Comprensione del flusso di traffico di rete est-ovest tra i pod
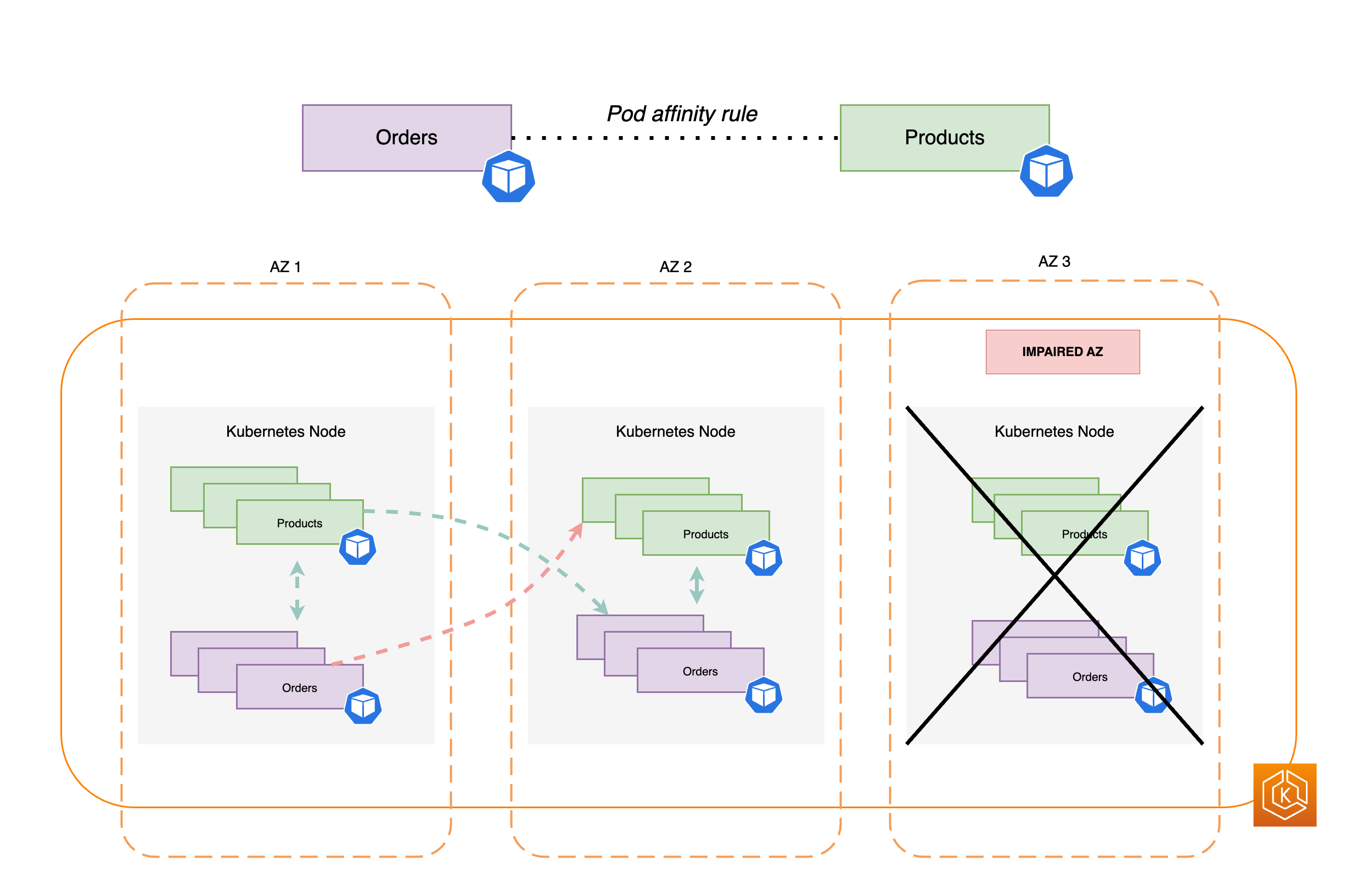
Il diagramma seguente illustra due esempi di carichi di lavoro, Ordini e Prodotti. Lo scopo di questo esempio è mostrare come comunicano carichi di lavoro e Pod in diverse AZ.
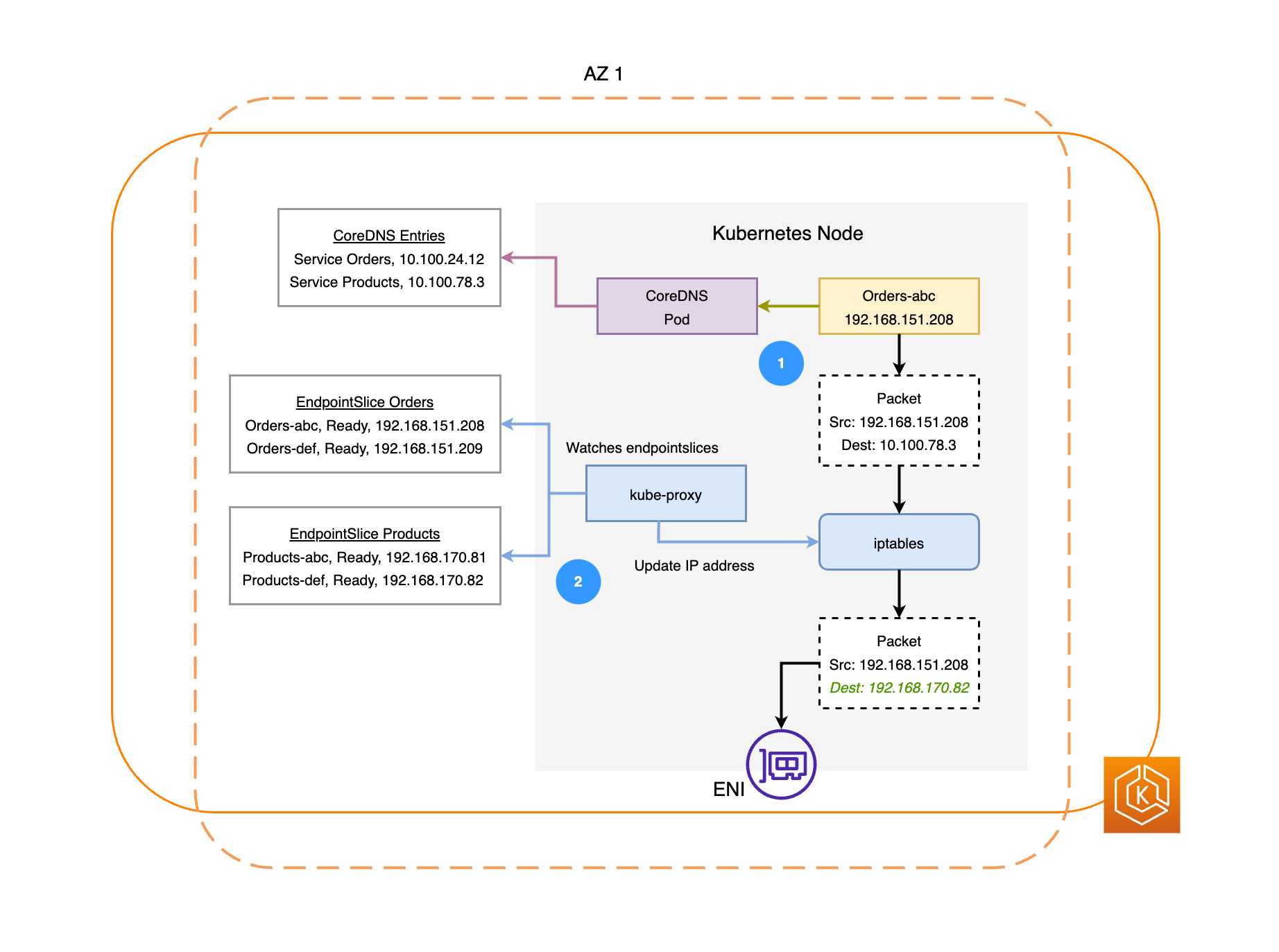
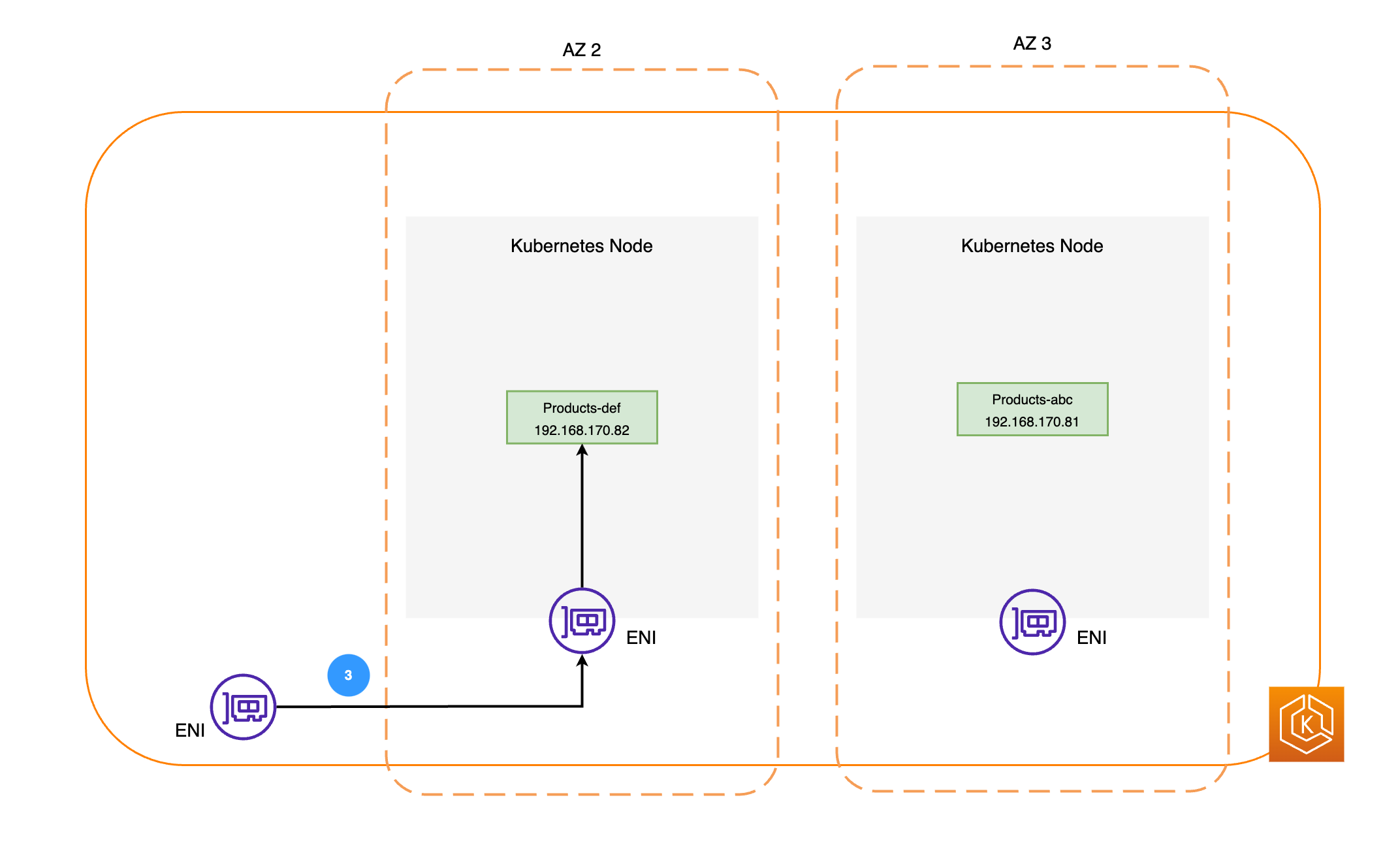
-
Affinché gli Ordini comunichino con i Prodotti, gli Ordini devono prima risolvere il nome DNS del servizio di destinazione. Ordini comunica con CoredNS per recuperare l’indirizzo IP virtuale (IP cluster) per quel servizio. Dopo che Ordini ha risolto il nome del servizio Prodotti, invia il traffico a quell’indirizzo IP di destinazione.
-
Il kube-proxy viene eseguito su ogni nodo del cluster e controlla continuamente i servizi. EndpointSlices
Quando viene creato un servizio, un servizio EndpointSlice viene creato e gestito in background dal controller. EndpointSlice Ciascuno EndpointSlice ha un elenco o una tabella di endpoint che contiene un sottoinsieme di indirizzi Pod, insieme ai nodi su cui sono in esecuzione. Il kube-proxy imposta le regole di routing per ciascuno di questi endpoint di pod utilizzando iptablessui nodi. Il kube-proxy è anche responsabile di una forma base di bilanciamento del carico, che consiste nel reindirizzare il traffico destinato all’indirizzo IP del cluster di un servizio per inviarlo invece direttamente all’indirizzo IP di un pod. Il kube-proxy esegue questa operazione riscrivendo l’indirizzo IP di destinazione sulla connessione in uscita. -
Quindi, i pacchetti di rete sono inviati al pod dei prodotti in AZ 2 utilizzando ENI sui rispettivi nodi, come mostrato nel diagramma precedente.
Comprensione dello spostamento zonale ARC in Amazon EKS
Se il tuo ambiente presenta un deterioramento di AZ, è possibile avviare uno spostamento zonale per l’ambiente del cluster EKS. In alternativa, puoi consentire di gestire AWS al posto tuo il traffico variabile con lo spostamento automatico zonale. Con lo spostamento automatico zonale, AWS monitora lo stato generale della zona a zona e risponde a un potenziale deterioramento della zona Z spostando automaticamente il traffico dall'area AZ compromessa nell'ambiente del cluster.
Dopo che il cluster Amazon EKS ha abilitato lo spostamento zonale con ARC, puoi avviare uno spostamento zonale o abilitare lo spostamento automatico di zona utilizzando la console ARC, la AWS CLI o le API zonal shift e zonal autoshift. Durante uno spostamento zonale EKS, è eseguito automaticamente quanto segue:
-
Tutti i nodi della zona AZ interessata sono isolati. Ciò impedisce al sistema di pianificazione Kubernetes di pianificare nuovi pod su nodi in una zona AZ non integra.
-
Se utilizzi i gruppi di nodi gestiti, il ribilanciamento delle zone di disponibilità è sospeso e il gruppo Auto Scaling è aggiornato per garantire che i nuovi nodi del piano dati EKS siano lanciati solo in AZ integre.
-
I nodi all’interno di AZ non integra non sono terminati e i pod non sono espulsi dai nodi. In questo modo, quando uno spostamento zonale scade o è annullato, il traffico può essere restituito in tutta sicurezza ad AZ per sfruttarne la piena capacità.
-
Il EndpointSlice controller trova tutti gli endpoint Pod nell'area AZ compromessa e li rimuove da quella pertinente. EndpointSlices Ciò garantisce che solo gli endpoint dei pod in AZ integre siano destinati a ricevere il traffico di rete. Quando uno spostamento zonale viene annullato o scade, il EndpointSlice controller lo aggiorna EndpointSlices per includere gli endpoint nella AZ ripristinata.
I seguenti diagrammi forniscono una panoramica di alto livello su come uno spostamento zonale EKS garantisce che solo gli endpoint dei pod integri siano presi di mira nell’ambiente del cluster.
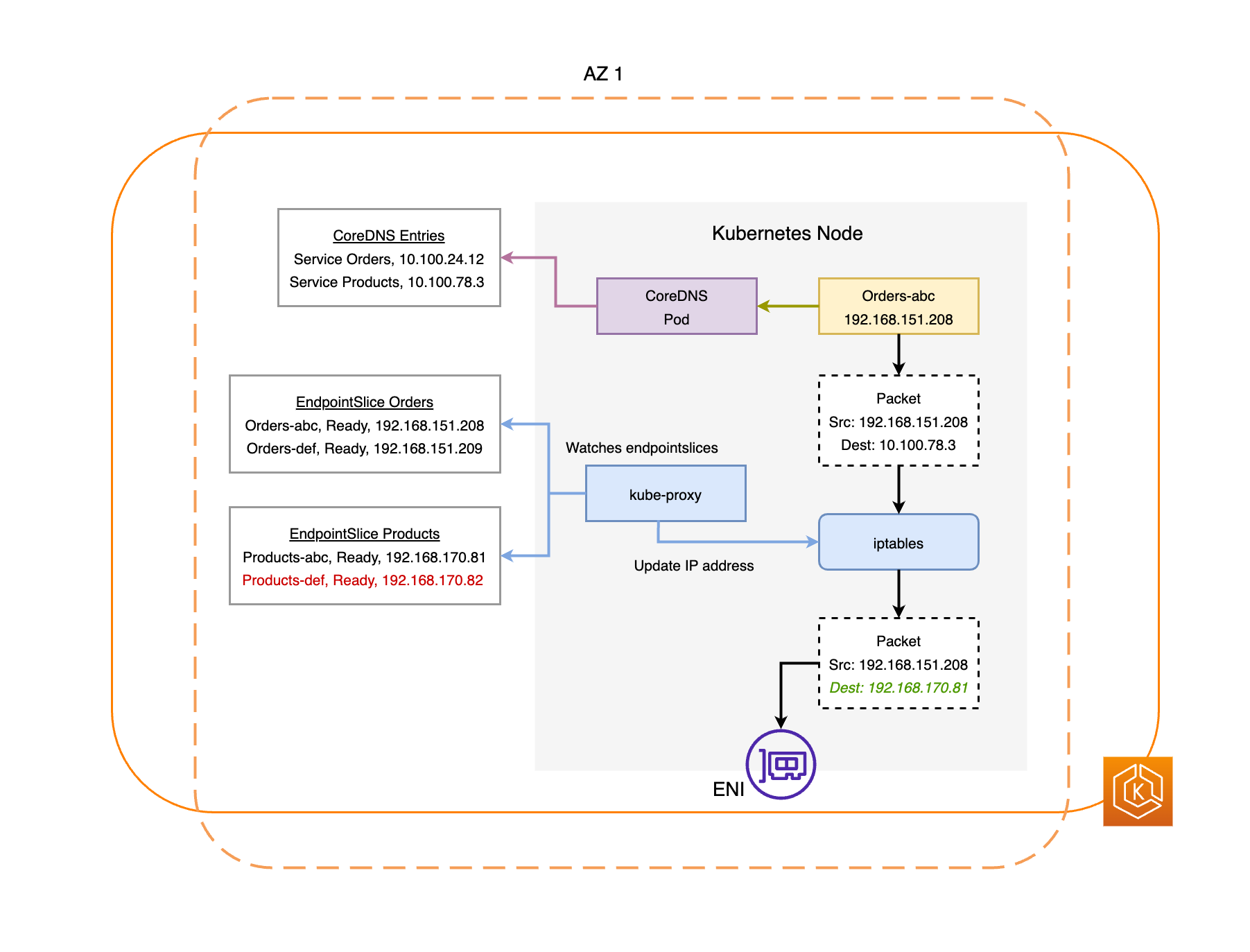
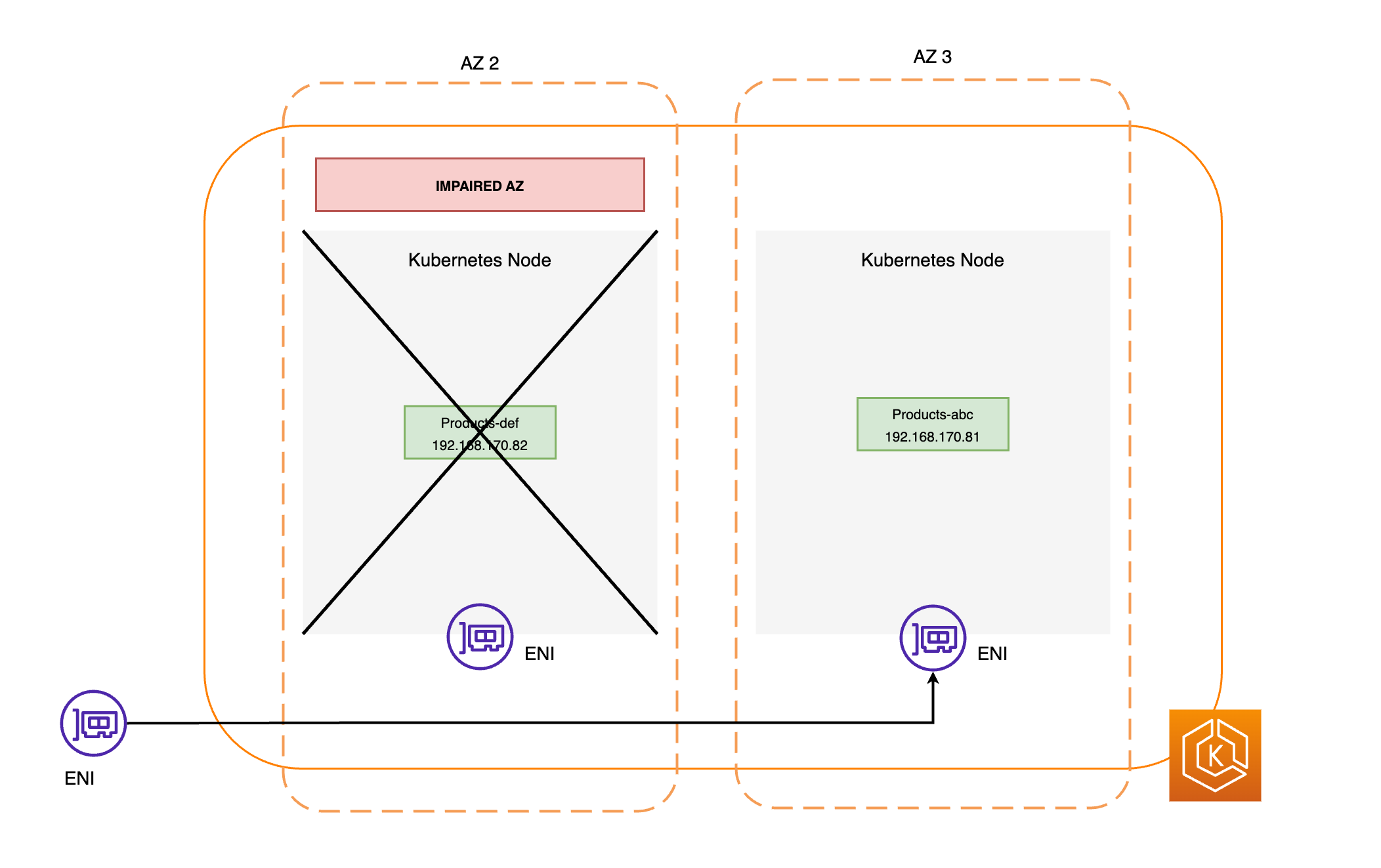
Requisiti per lo spostamento zonale EKS
Affinché lo spostamento zonale funzioni correttamente con EKS, è necessario configurare in anticipo l’ambiente del cluster in modo che sia resiliente a una compromissione di AZ. Di seguito è riportato un elenco di opzioni di configurazione che aiutano a garantire la resilienza.
-
Provisioning dei nodi worker del cluster su più AZ
-
Consulta a una capacità di elaborazione sufficiente per consentire la rimozione di una singola AZ
-
Pre-scale i tuoi Pod, incluso CoredNS, in ogni zona
-
Distribuisci più repliche di pod su tutte le AZ, per assicurarti che, quando ti sposti da una sola AZ, avrai comunque una capacità sufficiente
-
Effettua la co-locazione di pod interdipendenti o correlati nella stessa AZ
-
Verifica che il tuo ambiente cluster funzioni come previsto senza una AZ avviando manualmente uno spostamento zonale dalla zona AZ. In alternativa, è possibile abilitare lo spostamento zonale automatico e fare affidamento sulle esecuzioni pratiche di spostamento automatico. I test con spostamenti zonali manuali o pratici non sono necessari affinché lo spostamento zonale funzioni in EKS, ma sono fortemente consigliati.
Esegui il provisioning dei nodi workerEKS in più zone di disponibilità
AWS Le regioni hanno più sedi separate con data center fisici, note come zone di disponibilità (AZ). Le AZ sono progettate per essere isolate fisicamente l’una dall’altra per evitare impatti simultanei che potrebbero interessare un’intera regione. Quando si effettua il provisioning di un cluster EKS, si consiglia di distribuire i nodi di lavoro su più AZ in una regione. Ciò contribuisce a rendere l’ambiente cluster più resiliente alla compromissione di una singola AZ e consente di mantenere un’elevata disponibilità per le applicazioni eseguite nelle altre AZ. Quando si avvia uno spostamento di zona rispetto alla zona di zona interessata, la rete interna al cluster dell'ambiente EKS si aggiorna automaticamente per utilizzare solo AZ integre, per contribuire a mantenere un'elevata disponibilità del cluster.
La garanzia di disporre di una configurazione multi-AZ per l’ambiente EKS migliora l’affidabilità complessiva del sistema. Tuttavia, gli ambienti multi-AZ influenzano il modo in cui i dati delle applicazioni sono trasferiti ed elaborati, il che a sua volta ha un impatto sui costi di rete dell’ambiente. In particolare, il traffico in uscita frequente tra le zone (traffico distribuito tra le AZ) può avere un impatto importante sui costi relativi alla rete. È possibile applicare diverse strategie per controllare la quantità di traffico tra le zone tra i pod nel cluster EKS e ridurre i costi associati. Per ulteriori informazioni su come ottimizzare i costi di rete durante l’esecuzione di ambienti EKS ad alta disponibilità, consulta queste best practice
Il diagramma seguente illustra un ambiente EKS ad alta disponibilità con tre AZ integre.
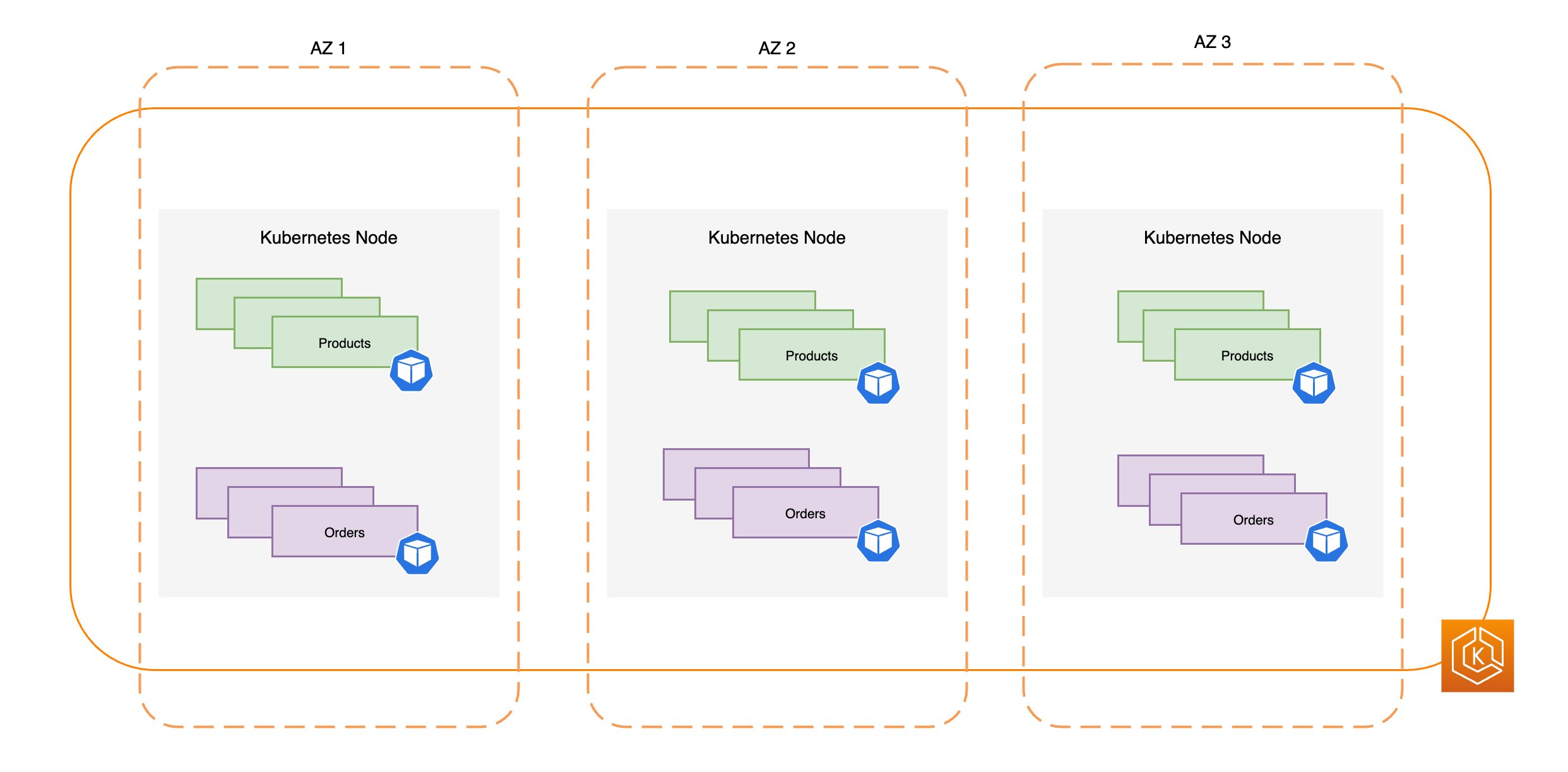
Il diagramma seguente illustra come un ambiente EKS con tre AZ sia resiliente a una compromissione di AZ e rimanga altamente disponibile perché rimangono due AZ integre.
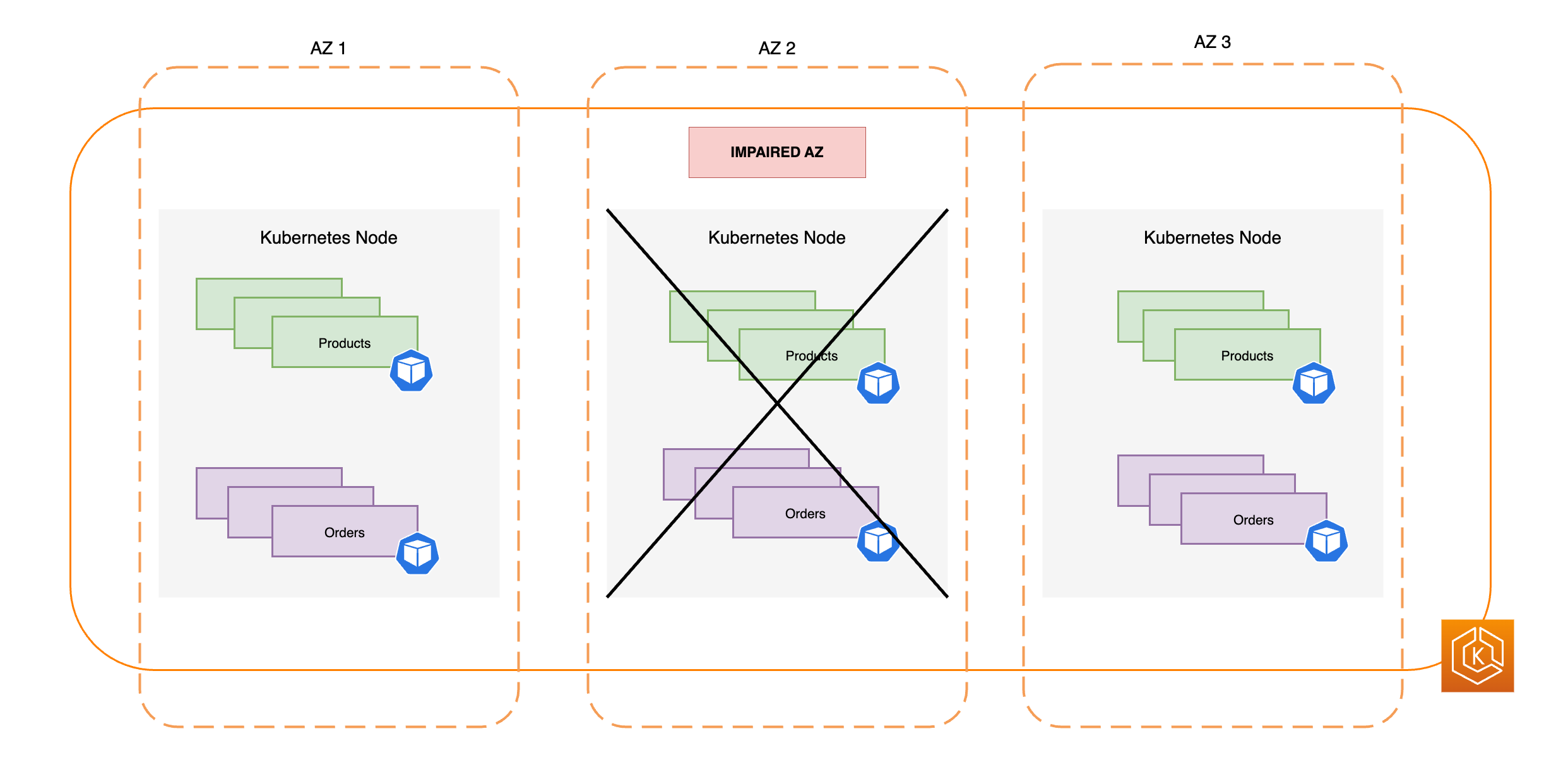
Consulta a una capacità di elaborazione sufficiente per resistere alla rimozione di una singola zona di disponibilità
Per ottimizzare l’utilizzo delle risorse e i costi per l’infrastruttura di elaborazione nel piano dati EKS, è consigliabile allineare la capacità di elaborazione ai requisiti del carico di lavoro. Tuttavia, se tutti i nodi worker sono a piena capacità, è necessario aggiungere nuovi nodi worker al piano dati EKS prima di poter pianificare nuovi pod. Quando si eseguono carichi di lavoro critici, in genere è buona norma impiegare una capacità ridondante online per gestire scenari quali aumenti improvvisi del carico e problemi di integrità dei nodi. Se prevedi di utilizzare lo spostamento zonale, intendi rimuovere un’intera AZ di capacità in caso di compromissione. Ciò significa che è necessario regolare la capacità di elaborazione ridondante in modo che sia sufficiente a gestire il carico anche con una delle AZ offline.
Quando si ridimensionano le risorse di elaborazione, il processo di aggiunta di nuovi nodi al piano dati EKS richiede del tempo. Ciò può avere implicazioni sulle prestazioni e sulla disponibilità in tempo reale delle applicazioni, soprattutto in caso di una compromissione zonale. Il tuo ambiente EKS dovrebbe essere in grado di assorbire il peso della perdita di una AZ senza compromettere l’esperienza degli utenti finali o dei clienti. Ciò significa ridurre al minimo o eliminare il ritardo tra il momento in cui è necessario un nuovo pod e quello in cui è effettivamente pianificato su un nodo worker.
Inoltre, in caso di compromissione zonale, dovresti cercare di mitigare il rischio di incorrere in un limite di capacità di elaborazione che impedirebbe l’aggiunta di nuovi nodi necessari al piano dati EKS nelle AZ integre.
Per ridurre il rischio di questi potenziali impatti negativi, consigliamo di fornire una capacità di elaborazione eccessiva in alcuni nodi di lavoro di ciascuna delle AZ. In questo modo, il sistema di pianificazione Kubernetes dispone di una capacità pre-esistente disponibile per il posizionamento di nuovi pod, il che è particolarmente importante quando si perde una delle AZ nel proprio ambiente.
Esegui e distribuisci più repliche di pod tra le zone di disponibilità
Kubernetes ti consente di pre-scalare i carichi di lavoro eseguendo più istanze (repliche di pod) di una singola applicazione. L’esecuzione di più repliche di pod per un’applicazione elimina i singoli punti di guasto e aumenta le prestazioni complessive riducendo il carico di sovraccarico su una singola replica. Tuttavia, per garantire un’elevata disponibilità e una migliore tolleranza ai guasti per le applicazioni, si consiglia di eseguire più repliche dell’applicazione e di distribuirle su diversi domini di guasto, noti anche come domini di topologia. I domini di guasto in questo scenario sono le zone di disponibilità. Utilizzando i vincoli di diffusione della topologia
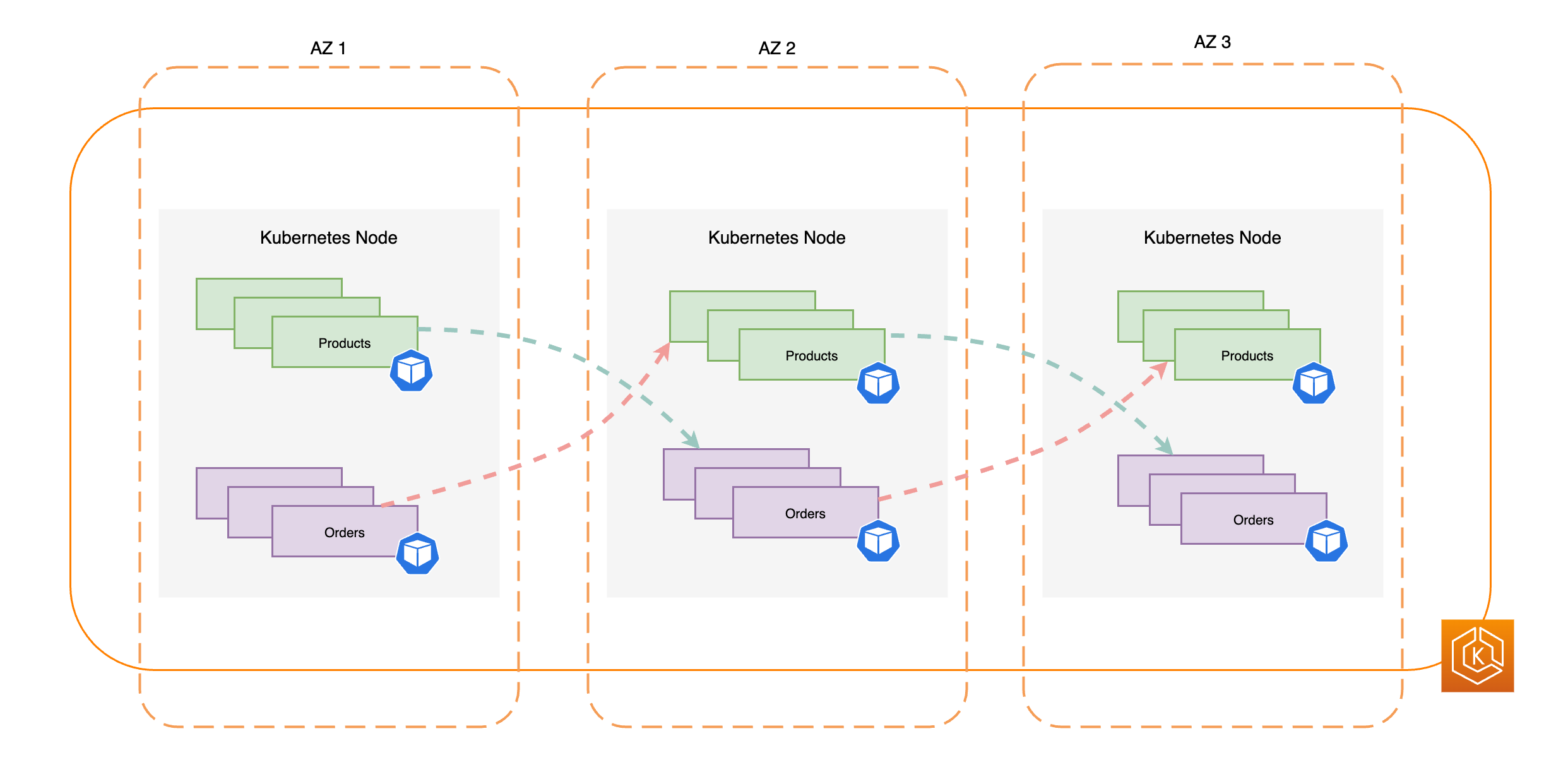
Il diagramma seguente illustra un ambiente EKS con un flusso di traffico da est a ovest quando tutte le AZ sono integre.
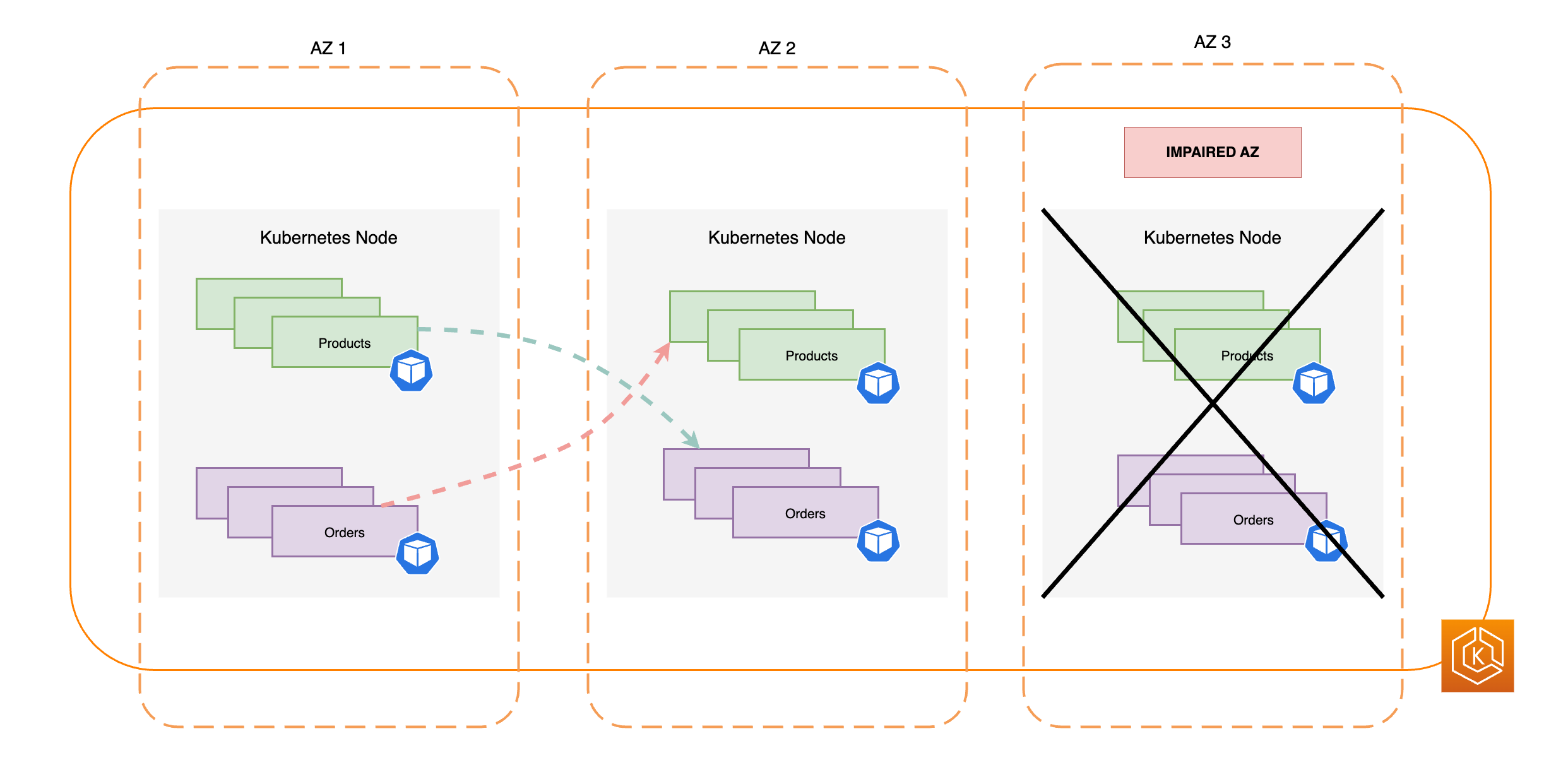
Il diagramma seguente illustra un ambiente EKS con un flusso di traffico da est a ovest in cui una singola AZ ha subito un guasto ed è stato avviato uno spostamento zonale.
Il seguente frammento di codice è un esempio di come configurare il carico di lavoro con più repliche in Kubernetes.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
Soprattutto, è consigliabile eseguire più repliche del software del server DNS (CoreDNS/kube-dns) e applicare vincoli di diffusione della topologia simili, se non sono configurati di default. Ciò aiuta a garantire che, in caso di una singola compromissione di AZ, si disponga di un numero sufficiente di pod DNS in AZ integre per continuare a gestire le richieste di rilevamento servizi per altri pod comunicanti nel cluster. Il componente aggiuntivo EKS CoreDNS dispone di impostazioni predefinite per i pod CoreDNS che assicurano che, se sono disponibili nodi in più AZ, siano distribuiti nelle zone di disponibilità del cluster. Se si desidera, è possibile sostituire queste impostazioni predefinite con le proprie configurazioni personalizzate.
Quando installi CoreDNS con HelmreplicaCount nel file values.yamltopologySpreadConstraints nello stesso file values.yaml. Il seguente frammento di codice illustra come configurare CoreDNS per eseguire tale operazione.
values.yaml CoredNS Helm
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
In caso di compromissione di AZ, è possibile assorbire l’aumento del carico sui pod CoreDNS, utilizzando un sistema di scalabilità automatica per CoreDNS. Il numero di istanze DNS necessarie dipende dal numero di carichi di lavoro in esecuzione nel cluster. CoreDNS è legato alla CPU, il che gli consente di scalare in base alla CPU utilizzando l’Horizontal Pod Autoscaler (HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
In alternativa, EKS può gestire la scalabilità automatica dell’implementazione CoreDNS nella versione del componente aggiuntivo EKS di CoreDNS. Questo autoscaler di CoreDNS monitora continuamente lo stato del cluster, incluso il numero di nodi e core CPU. Sulla base di tali informazioni, il controller regola dinamicamente il numero di repliche dell’implementazione CoreDNS in un cluster EKS.
Per abilitare la configurazione di scalabilità automatica nel componente aggiuntivo CoredNS EKS, utilizzare la seguente impostazione di configurazione:
{ "autoScaling": { "enabled": true } }
Puoi anche usare NodeLocal DNS
Co-locare i pod interdipendenti nella stessa zona di disponibilità
In genere, le applicazioni hanno carichi di lavoro distinti che devono comunicare tra loro per completare con successo un processo end-to-end. Se queste applicazioni distinte sono distribuite su diverse AZ e non sono co-locate nella stessa AZ, una singola violazione della AZ può influire sul processo end-to-end. Ad esempio, se l’applicazione A ha più repliche in AZ 1 e AZ 2, ma l’applicazione B ha tutte le repliche in AZ 3, la perdita di AZ 3 influirà sui processi end-to-end tra i due carichi di lavoro, l’applicazione A e l’applicazione B. Se combini i vincoli di diffusione della topologia con l’affinità dei pod, puoi migliorare la resilienza dell’applicazione distribuendo i pod su tutte le AZ. Inoltre, ciò configura una relazione tra determinati pod per garantire che siano co-locati.
Con le regole di affinità dei pod
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Il diagramma seguente mostra diversi pod che sono stati co-locati sullo stesso nodo utilizzando le regole di affinità dei pod.
Verifica che il tuo ambiente cluster sia in grado di gestire la perdita di una AZ
Dopo aver completato i requisiti descritti nelle sezioni precedenti, il passaggio successivo consiste nel verificare di disporre di una capacità di elaborazione e carico di lavoro sufficiente per gestire la perdita di una AZ. Per eseguire tale operazione è possibile avviare manualmente uno spostamento zonale in EKS. In alternativa, è possibile abilitare lo spostamento zonale automatico e configurare le sessioni pratiche, che consentono anche di verificare che le applicazioni funzionino come previsto con una AZ in meno nell’ambiente cluster.
Domande frequenti
Qual è il vantaggio di utilizzare questa funzionalità?
Utilizzando lo spostamento zonale ARC o lo spostamento zonale automatico nel cluster EKS, è possibile mantenere meglio la disponibilità delle applicazioni Kubernetes automatizzando il processo di ripristino rapido che consiste nello spostamento del traffico di rete interno al cluster da una zona AZ compromessa. Con ARC, è possibile evitare passaggi lunghi e complicati, che possono portare a un periodo di recupero prolungato in caso di eventi AZ compromessi.
Come funziona questa funzionalità con altri servizi? AWS
EKS si integra con ARC, che fornisce l'interfaccia principale in cui eseguire le operazioni di ripristino. AWS Per garantire che il traffico all’interno del cluster sia indirizzato in modo appropriato lontano da una zona di disponibilità compromessa, EKS apporta modifiche all’elenco degli endpoint di rete per i pod in esecuzione sul piano dati Kubernetes. Se utilizzi Elastic Load Balancing per instradare il traffico esterno verso il cluster, è possibile registrare i bilanciatori del carico con ARC e avviare uno spostamento zonale su di essi per impedire che il traffico fluisca verso la zona AZ deteriorata. Lo spostamento zonale funziona anche con i gruppi di Amazon EC2 Auto Scaling creati da gruppi di nodi gestiti da EKS. Per evitare che una AZ compromessa sia utilizzata per nuovi pod Kubernetes o avvii di nodi, EKS rimuove la AZ compromessa dai gruppi Auto Scaling.
In che modo questa funzionalità è diversa dalle protezioni Kubernetes predefinite?
Tale funzionalità funziona in combinazione con diverse protezioni integrate di Kubernetes che aiutano la resilienza delle applicazioni dei clienti. È possibile configurare le sonde readiness e liveness di pod che decidono quando un Pod deve ricevere traffico. Quando queste sonde si guastano, Kubernetes rimuove questi pod come obiettivi di un servizio e il traffico non è più inviato al pod. Sebbene ciò sia utile, non è semplice per i clienti configurare tali controlli dell’integrità in modo da garantire che abbiano esito negativo in caso di deterioramento di una AZ. La funzione di spostamento zonale ARC fornisce una rete di sicurezza aggiuntiva che ti aiuta a isolare completamente una AZ deteriorata quando le protezioni native di Kubernetes non erano sufficienti. Lo spostamento zonale offre anche un modo semplice per testare la prontezza operativa e la resilienza dell’architettura.
Posso AWS avviare un cambio di zona per mio conto?
Sì, se desideri un modo completamente automatizzato di utilizzare lo spostamento zonale ARC, puoi abilitare lo spostamento zonale automatico ARC. Con l'autoshift zonale, puoi contare sul monitoraggio dello stato delle AZ AWS per il tuo cluster EKS e per avviare automaticamente un cambiamento di zona quando viene rilevata una compromissione della zona di zona.
Cosa succede se utilizzo questa funzionalità e i miei nodi worker e i miei carichi di lavoro non sono predimensionati?
Se non si esegue una pre-scalabilità e si affida al provisioning di nodi o pod aggiuntivi durante uno spostamento zonale, si rischia un ripristino ritardato. Il processo di aggiunta di nuovi nodi al piano dati di Kubernetes richiede del tempo, il che può influire sulle prestazioni e sulla disponibilità in tempo reale delle applicazioni, soprattutto in caso di compromissione zonale. Inoltre, in caso di compromissione zonale, potresti riscontrare un potenziale limite di capacità di elaborazione che potrebbe impedire l’aggiunta dei nuovi nodi necessari alle AZ integre.
Se i carichi di lavoro non sono pre-scalati e distribuiti su tutte le AZ del cluster, una compromissione zonale potrebbe influire sulla disponibilità di un’applicazione che è eseguita solo sui nodi worker nelle AZ interessate. Per mitigare il rischio di un’interruzione completa della disponibilità dell’applicazione, EKS dispone di un sistema a prova di guasto per l’invio del traffico agli endpoint di pod in una zona compromessa se il carico di lavoro ha tutti i suoi endpoint in una AZ non integra. Tuttavia, consigliamo vivamente di pre-scalare e distribuire le applicazioni su tutte le AZ per mantenere la disponibilità in caso di problemi zonali.
Come funziona se sto eseguendo un’applicazione stateful?
Se stai eseguendo un’applicazione stateful, devi valutarne la tolleranza ai guasti, in base al tuo caso d’uso e all’architettura. Se disponi di un' active/standby architettura o di un pattern, potrebbero esserci casi in cui l'attivo si trova in una zona AZ compromessa. A livello di applicazione, se lo standby non è attivato, è possibile che si verifichino problemi con l’applicazione. Inoltre, potresti riscontrare problemi quando sono avviati nuovi pod Kubernetes in AZ integre, poiché non saranno in grado di collegarsi ai volumi persistenti limitati alla AZ compromessa.
Questa funzionalità funziona con Karpenter?
Questa funzionalità funziona con EKS Fargate?
Questa funzionalità non funziona con EKS Fargate. Per impostazione predefinita, quando EKS Fargate riconosce un evento di integrità zonale, i pod preferiranno essere eseguiti nelle altre AZ.
Il piano di controllo Kubernetes gestito da EKS ne risentirà?
No, per impostazione predefinita Amazon EKS esegue ed effettua il dimensionamento di istanze del piano di controllo Kubernetes in molteplici AZ per garantire un’elevata disponibilità. Lo spostamento zonale ARC e lo spostamento zonale automatico agiscono solo sul piano dati Kubernetes.
Ci sono dei costi associati a questa nuova funzionalità?
È possibile utilizzare uno spostamento zonale ARC e uno spostamento zonale automatico nel cluster EKS senza costi aggiuntivi. Tuttavia, continuerai a pagare per le istanze assegnate e consigliamo vivamente di pre-scalare il tuo piano dati Kubernetes prima di utilizzare questa funzionalità. È necessario considerare un equilibrio tra costi e disponibilità delle applicazioni.
Risorse aggiuntive
