Contribuisci a migliorare questa pagina
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Per contribuire a questa guida per l'utente, scegli il GitHub link Modifica questa pagina nel riquadro destro di ogni pagina.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitora il traffico dei carichi di lavoro Kubernetes con Container Network Observability
Amazon EKS offre funzionalità avanzate di osservabilità della rete che forniscono informazioni più approfondite sull'ambiente di rete dei container. Queste funzionalità ti aiutano a comprendere, monitorare e risolvere meglio il tuo panorama di rete Kubernetes in. AWS Con una migliore osservabilità della rete di container, puoi sfruttare metriche granulari relative alla rete per un migliore rilevamento proattivo delle anomalie nel traffico del cluster, nei flussi cross-AZ e nei servizi. AWS Utilizzando queste metriche, puoi misurare le prestazioni del sistema e visualizzare le metriche sottostanti utilizzando il tuo stack di osservabilità preferito.
Inoltre, Amazon EKS ora fornisce visualizzazioni di monitoraggio della rete nella AWS console che accelerano e migliorano la risoluzione precisa dei problemi per un'analisi più rapida delle cause principali. Puoi anche sfruttare queste funzionalità visive per individuare i principali interlocutori e i flussi di rete che causano ritrasmissioni e timeout di ritrasmissione, eliminando i punti ciechi durante gli incidenti.
Queste funzionalità sono abilitate da Amazon CloudWatch Network Flow Monitor.
Casi d’uso
Misura le prestazioni della rete per rilevare anomalie
Diversi team si basano su uno stack di osservabilità che consente loro di misurare le prestazioni del sistema, visualizzare le metriche del sistema e allarmarsi nel caso in cui venga superata una soglia specifica. L'osservabilità della rete di container in EKS si allinea a questo aspetto, esponendo le metriche chiave del sistema che è possibile analizzare per ampliare l'osservabilità delle prestazioni di rete del sistema a livello di pod e nodo di lavoro.
Sfrutta le visualizzazioni della console per una risoluzione dei problemi più precisa
In caso di allarme proveniente dal sistema di monitoraggio, potresti voler concentrarti sul cluster e sul carico di lavoro da cui ha avuto origine il problema. A tale scopo, puoi sfruttare le visualizzazioni della console EKS che restringono l'ambito di indagine a livello di cluster e accelerano la divulgazione dei flussi di rete responsabili della maggior parte delle ritrasmissioni, dei timeout di ritrasmissione e del volume di dati trasferiti.
Tieni traccia dei migliori oratori nel tuo ambiente Amazon EKS
Molti team utilizzano EKS come base per le proprie piattaforme, rendendolo il punto focale dell'attività di rete di un ambiente applicativo. Utilizzando le funzionalità di monitoraggio della rete di questa funzionalità, puoi monitorare quali carichi di lavoro sono responsabili della maggior parte del traffico (misurato in base al volume di dati) all'interno del cluster, tra le AZ, nonché del traffico verso destinazioni esterne all'interno ( AWS DynamoDB e S3) e oltre il AWS cloud (Internet o on-premise). Inoltre, è possibile monitorare le prestazioni di ciascuno di questi flussi in base alle ritrasmissioni, ai timeout di ritrasmissione e ai dati trasferiti.
Funzionalità
-
Metriche delle prestazioni: questa funzionalità consente di acquisire le metriche di sistema relative alla rete per pod e nodi di lavoro direttamente dall'agente Network Flow Monitor (NFM) in esecuzione nel cluster EKS.
-
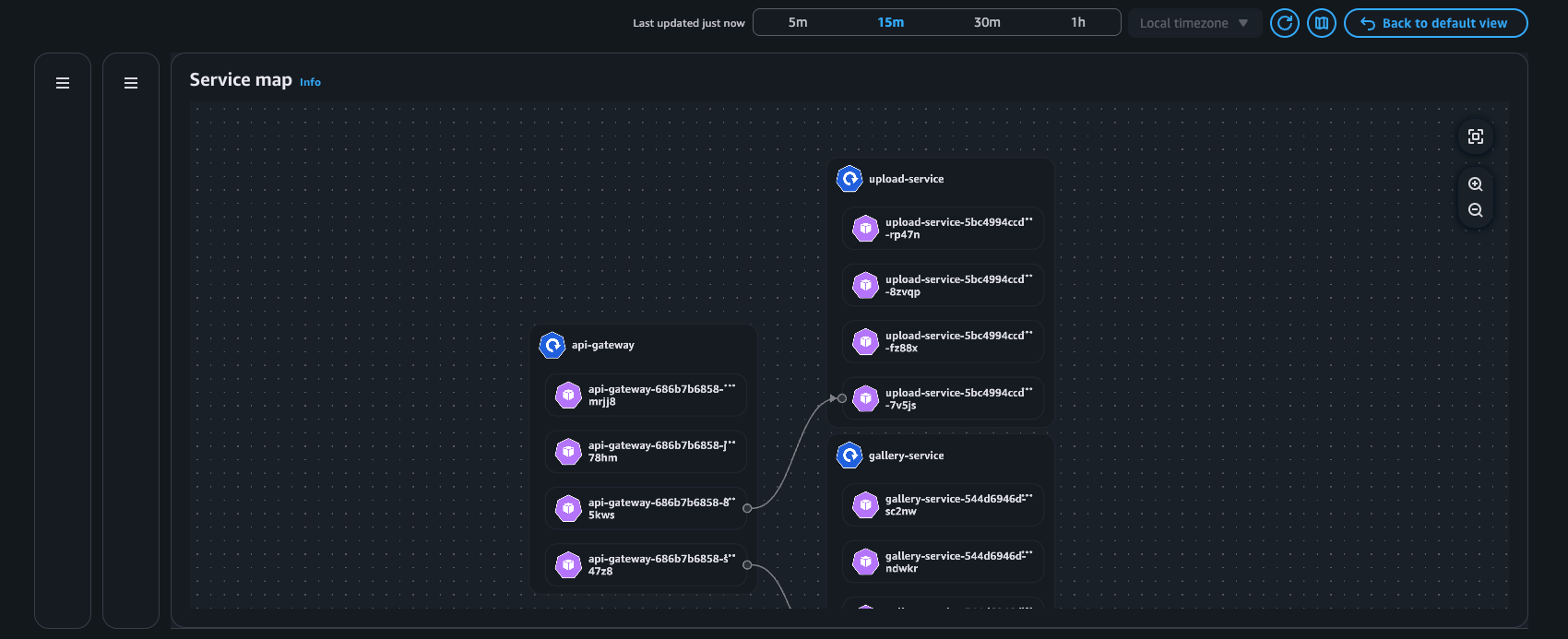
Mappa dei servizi: questa funzionalità visualizza dinamicamente l'intercomunicazione tra i carichi di lavoro nel cluster, consentendo di divulgare rapidamente le metriche chiave (ritrasmissioni - RT, timeout di ritrasmissione - RTO e dati trasferiti - DT) associate ai flussi di rete tra pod comunicanti.
-
Tabella dei flussi: con questa tabella, puoi monitorare i migliori oratori nei carichi di lavoro Kubernetes del tuo cluster da tre diverse angolazioni: visualizzazione del AWS servizio, visualizzazione del cluster e visualizzazione esterna. Per ogni vista, puoi vedere le ritrasmissioni, i timeout di ritrasmissione e i dati trasferiti tra il pod di origine e la sua destinazione.
-
AWS visualizzazione del servizio: mostra i migliori oratori ai AWS servizi (DynamoDB e S3)
-
Visualizzazione cluster: mostra i migliori oratori all'interno del cluster (da est ← a → ovest)
-
Vista esterna: mostra i migliori oratori alle destinazioni esterne al cluster all'esterno AWS
-
Nozioni di base
Per iniziare, abilita Container Network Observability nella console EKS per un cluster nuovo o esistente. Ciò automatizzerà la creazione delle dipendenze di Network Flow Monitor (NFM) (risorse Scope and Monitor). Inoltre, dovrai installare il componente aggiuntivo Network Flow Monitor Agent. In alternativa, puoi installare queste dipendenze utilizzando le API EKS (per il componente aggiuntivo) AWS CLI, le APINFM o Infrastructure as Code (come Terraform).
Quando si utilizza Network Flow Monitor in EKS, è possibile mantenere il flusso di lavoro e lo stack tecnologico di osservabilità esistenti, sfruttando al contempo una serie di funzionalità aggiuntive che consentono di comprendere e ottimizzare ulteriormente il livello di rete del proprio ambiente EKS. Puoi saperne di più sui prezzi di Network Flow Monitor qui.
Prerequisiti e note importanti
-
Come accennato in precedenza, se abilitate Container Network Observability dalla console EKS, le dipendenze delle risorse NFM sottostanti (Scope e Monitor) verranno create automaticamente per vostro conto e sarete guidati attraverso il processo di installazione del componente aggiuntivo EKS per NFM.
-
Se desideri abilitare questa funzionalità utilizzando Infrastructure as Code (IaC) come Terraform, dovrai definire le seguenti dipendenze nel tuo IaC: NFM Scope, NFM Monitor, componente aggiuntivo EKS per NFM. Inoltre, dovrai concedere le autorizzazioni pertinenti al componente aggiuntivo EKS utilizzando Pod Identity o IAM roles for service accounts (IRSA).
-
È necessario eseguire una versione minima di 1.1.0 per il componente aggiuntivo EKS dell'agente NFM.
-
È necessario utilizzare la versione 6.21.0 o successiva di Terraform AWS Provider
per il supporto delle risorse di Network Flow Monitor.
Autorizzazioni IAM richieste
Componente aggiuntivo EKS per l'agente NFM
Puoi utilizzare la policy CloudWatchNetworkFlowMonitorAgentPublishPolicyAWS gestita con Pod Identity. Questa policy contiene le autorizzazioni per l'agente NFM a inviare report di telemetria (metriche) a un endpoint Network Flow Monitor.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect" : "Allow", "Action" : [ "networkflowmonitor:Publish" ], "Resource" : "*" } ] }
Osservabilità della rete dei container nella console EKS
Le seguenti autorizzazioni sono necessarie per abilitare la funzionalità e visualizzare la mappa dei servizi e la tabella dei flussi nella console.
{ "Version" : "2012-10-17", "Statement" : [ { "Effect": "Allow", "Action": [ "networkflowmonitor:ListScopes", "networkflowmonitor:ListMonitors", "networkflowmonitor:GetScope", "networkflowmonitor:GetMonitor", "networkflowmonitor:CreateScope", "networkflowmonitor:CreateMonitor", "networkflowmonitor:TagResource", "networkflowmonitor:StartQueryMonitorTopContributors", "networkflowmonitor:StopQueryMonitorTopContributors", "networkflowmonitor:GetQueryStatusMonitorTopContributors", "networkflowmonitor:GetQueryResultsMonitorTopContributors" ], "Resource": "*" } ] }
Utilizzo di AWS CLI, API EKS e API NFM
#!/bin/bash # Script to create required Network Flow Monitor resources set -e CLUSTER_NAME="my-eks-cluster" CLUSTER_ARN="arn:aws:eks:{Region}:{Account}:cluster/{ClusterName}" REGION="us-west-2" AGENT_NAMESPACE="amazon-network-flow-monitor" echo "Creating Network Flow Monitor resources..." # Check if Network Flow Monitor agent is running in the cluster echo "Checking for Network Flow Monitor agent in cluster..." if kubectl get pods -n "$AGENT_NAMESPACE" --no-headers 2>/dev/null | grep -q "Running"; then echo "Network Flow Monitor agent exists and is running in the cluster" else echo "Network Flow Monitor agent not found. Installing as EKS addon..." aws eks create-addon \ --cluster-name "$CLUSTER_NAME" \ --addon-name "$AGENT_NAMESPACE" \ --region "$REGION" echo "Network Flow Monitor addon installation initiated" fi # Get Account ID ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) echo "Cluster ARN: $CLUSTER_ARN" echo "Account ID: $ACCOUNT_ID" # Check for existing scope echo "Checking for existing Network Flow Monitor Scope..." EXISTING_SCOPE=$(aws networkflowmonitor list-scopes --region $REGION --query 'scopes[0].scopeArn' --output text 2>/dev/null || echo "None") if [ "$EXISTING_SCOPE" != "None" ] && [ "$EXISTING_SCOPE" != "null" ]; then echo "Using existing scope: $EXISTING_SCOPE" SCOPE_ARN=$EXISTING_SCOPE else echo "Creating new Network Flow Monitor Scope..." SCOPE_RESPONSE=$(aws networkflowmonitor create-scope \ --targets "[{\"targetIdentifier\":{\"targetId\":{\"accountId\":\"${ACCOUNT_ID}\"},\"targetType\":\"ACCOUNT\"},\"region\":\"${REGION}\"}]" \ --region $REGION \ --output json) SCOPE_ARN=$(echo $SCOPE_RESPONSE | jq -r '.scopeArn') echo "Scope created: $SCOPE_ARN" fi # Create Network Flow Monitor with EKS Cluster as local resource echo "Creating Network Flow Monitor..." MONITOR_RESPONSE=$(aws networkflowmonitor create-monitor \ --monitor-name "${CLUSTER_NAME}-monitor" \ --local-resources "type=AWS::EKS::Cluster,identifier=${CLUSTER_ARN}" \ --scope-arn "$SCOPE_ARN" \ --region $REGION \ --output json) MONITOR_ARN=$(echo $MONITOR_RESPONSE | jq -r '.monitorArn') echo "Monitor created: $MONITOR_ARN" echo "Network Flow Monitor setup complete!" echo "Monitor ARN: $MONITOR_ARN" echo "Scope ARN: $SCOPE_ARN" echo "Local Resource: AWS::EKS::Cluster (${CLUSTER_ARN})"
Utilizzo dell'infrastruttura come codice (IaC)
Terraform
Se utilizzi Terraform per gestire la tua infrastruttura AWS cloud, puoi includere le seguenti configurazioni di risorse per abilitare l'osservabilità della rete di contenitori per il tuo cluster.
Ambito NFM
data "aws_caller_identity" "current" {} resource "aws_networkflowmonitor_scope" "example" { target { region = "us-east-1" target_identifier { target_type = "ACCOUNT" target_id { account_id = data.aws_caller_identity.current.account_id } } } tags = { Name = "example" } }
Monitor NFM
resource "aws_networkflowmonitor_monitor" "example" { monitor_name = "eks-cluster-name-monitor" scope_arn = aws_networkflowmonitor_scope.example.scope_arn local_resource { type = "AWS::EKS::Cluster" identifier = aws_eks_cluster.example.arn } remote_resource { type = "AWS::Region" identifier = "us-east-1" # this must be the same region that the cluster is in } tags = { Name = "example" } }
Componente aggiuntivo EKS per NFM
resource "aws_eks_addon" "example" { cluster_name = aws_eks_cluster.example.name addon_name = "aws-network-flow-monitoring-agent" }
Come funziona?
Metriche delle prestazioni
Parametri del sistema
Se utilizzi strumenti di terze parti (3P) per monitorare il tuo ambiente EKS (come Prometheus e Grafana), puoi acquisire le metriche di sistema supportate direttamente dall'agente Network Flow Monitor. Queste metriche possono essere inviate allo stack di monitoraggio per ampliare la misurazione delle prestazioni di rete del sistema a livello di pod e nodo di lavoro. Le metriche disponibili sono elencate nella tabella, in Metriche di sistema supportate.
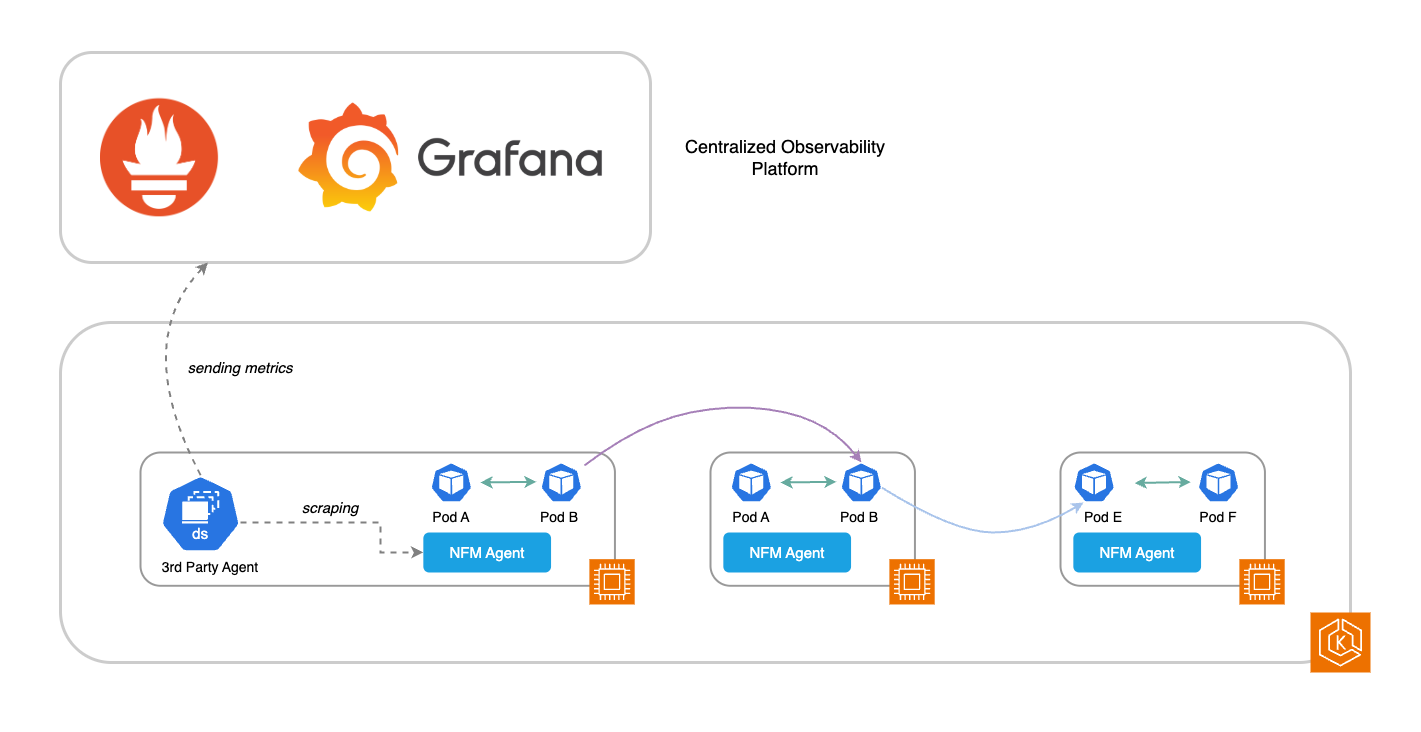
Per abilitare queste metriche, sovrascrivete le seguenti variabili di ambiente utilizzando le variabili di configurazione durante il processo di installazione (vedi:): https://aws.amazon.com/blogs/containers/amazon-eks-add-ons-advanced-configuration/
OPEN_METRICS: Enable or disable open metrics. Disabled if not supplied Type: String Values: [“on”, “off”] OPEN_METRICS_ADDRESS: Listening IP address for open metrics endpoint. Defaults to 127.0.0.1 if not supplied Type: String OPEN_METRICS_PORT: Listening port for open metrics endpoint. Defaults to 80 if not supplied Type: Integer Range: [0..65535]
Metriche a livello di flusso
Inoltre, Network Flow Monitor acquisisce i dati del flusso di rete insieme alle metriche del livello di flusso: ritrasmissioni, timeout di ritrasmissione e dati trasferiti. Questi dati vengono elaborati da Network Flow Monitor e visualizzati nella console EKS per far emergere il traffico nell'ambiente del cluster e il relativo rendimento in base a queste metriche del livello di flusso.
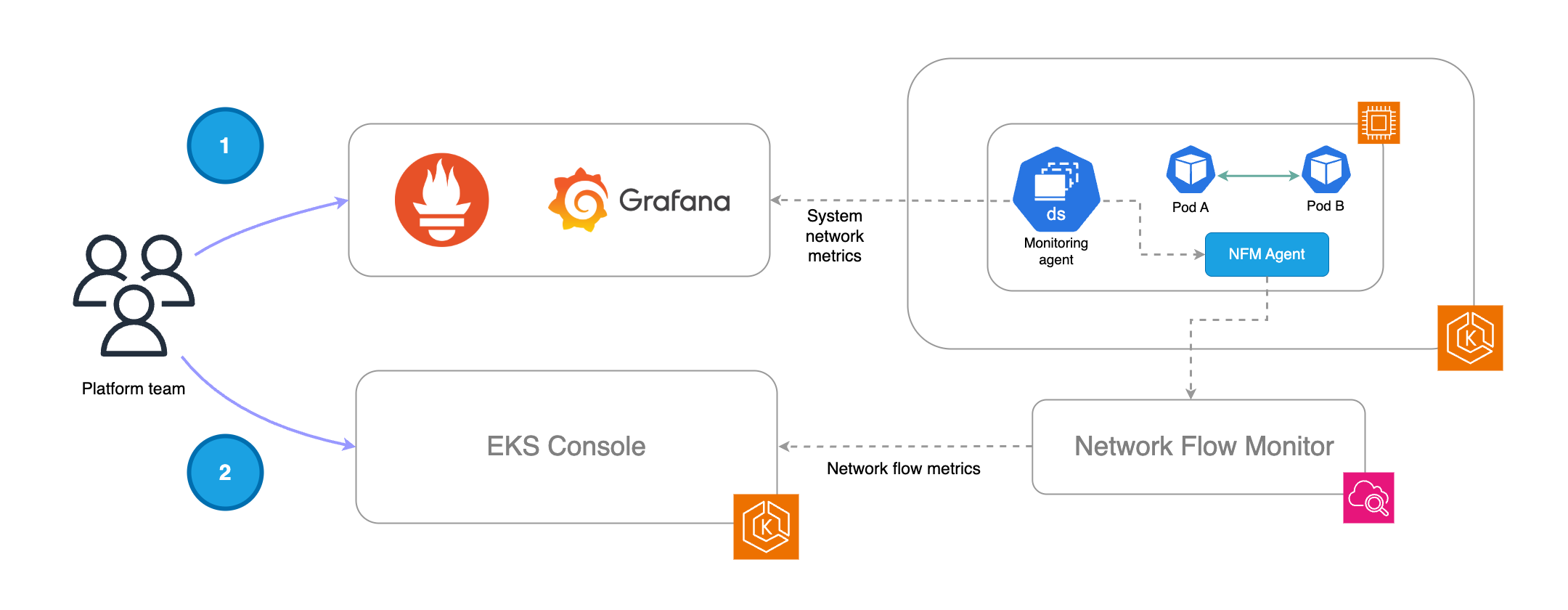
Il diagramma seguente illustra un flusso di lavoro in cui entrambi i tipi di metriche (sistema e livello di flusso) possono essere sfruttati per ottenere una maggiore intelligenza operativa.
-
Il team della piattaforma può raccogliere e visualizzare le metriche di sistema nel proprio stack di monitoraggio. Una volta attivati gli avvisi, possono rilevare anomalie di rete o problemi che influiscono sui pod o sui nodi di lavoro utilizzando le metriche di sistema fornite dall'agente NFM.
-
Come passaggio successivo, i team della piattaforma possono sfruttare le visualizzazioni native della console EKS per restringere ulteriormente l'ambito delle indagini e accelerare la risoluzione dei problemi in base alle rappresentazioni dei flussi e alle metriche associate.
Nota importante: l'acquisizione delle metriche di sistema dall'agente NFM e il processo con cui l'agente NFM invia le metriche a livello di flusso al backend NFM sono processi indipendenti.
Metriche di sistema supportate
Nota importante: le metriche di sistema vengono esportate in formato. OpenMetrics
| Nome parametro | Tipo | Dimensioni | Description |
|---|---|---|---|
|
ingress_flow |
Gauge |
instance_id, iface, pod, namespace, nodo |
Conteggio del flusso TCP in ingresso () TcpPassiveOpens |
|
Flusso_uscita |
Gauge |
instance_id, iface, pod, namespace, node |
Conteggio del flusso TCP in uscita () TcpActiveOpens |
|
pacchetti_in ingresso |
Gauge |
instance_id, iface, pod, namespace, nodo |
Numero di pacchetti in ingresso (delta) |
|
pacchetti_in uscita |
Gauge |
instance_id, iface, pod, namespace, node |
Numero di pacchetti in uscita (delta) |
|
ingress_bytes |
Gauge |
instance_id, iface, pod, namespace, nodo |
Conteggio dei byte in ingresso (delta) |
|
egress_bytes |
Gauge |
instance_id, iface, pod, namespace, nodo |
Conteggio dei byte in uscita (delta) |
|
bw_in_allowance_exceeded |
Gauge |
instance_id, eni, nodo |
Pacchetti queued/dropped dovuti al limite di larghezza di banda in entrata |
|
bw_out_allowance_exceeded |
Gauge |
instance_id, eni, nodo |
Pacchetti queued/dropped dovuti al limite di larghezza di banda in uscita |
|
pps_allowance_exceeded |
Gauge |
instance_id, eni, nodo |
Pacchetti queued/dropped dovuti al limite PPS bidirezionale |
|
conntrack_allowance_exceeded |
Gauge |
instance_id, eni, nodo |
Pacchetti persi a causa del limite di tracciamento della connessione |
|
linklocal_allowance_exceeded |
Gauge |
instance_id, eni, nodo |
I pacchetti sono caduti a causa del limite PPS del servizio proxy locale |
Metriche del livello di flusso supportate
| Nome parametro | Tipo | Description |
|---|---|---|
|
Ritrasmissioni TCP |
Contatore |
Numero di volte in cui un mittente invia nuovamente un pacchetto perso o danneggiato durante la trasmissione. |
|
Timeout di ritrasmissione TCP |
Contatore |
Numero di volte in cui un mittente ha avviato un periodo di attesa per determinare se un pacchetto è andato perso durante il transito. |
|
Dati (byte) trasferiti |
Contatore |
Volume di dati trasferiti tra un'origine e una destinazione per un determinato flusso. |
Mappa dei servizi e tabella dei flussi
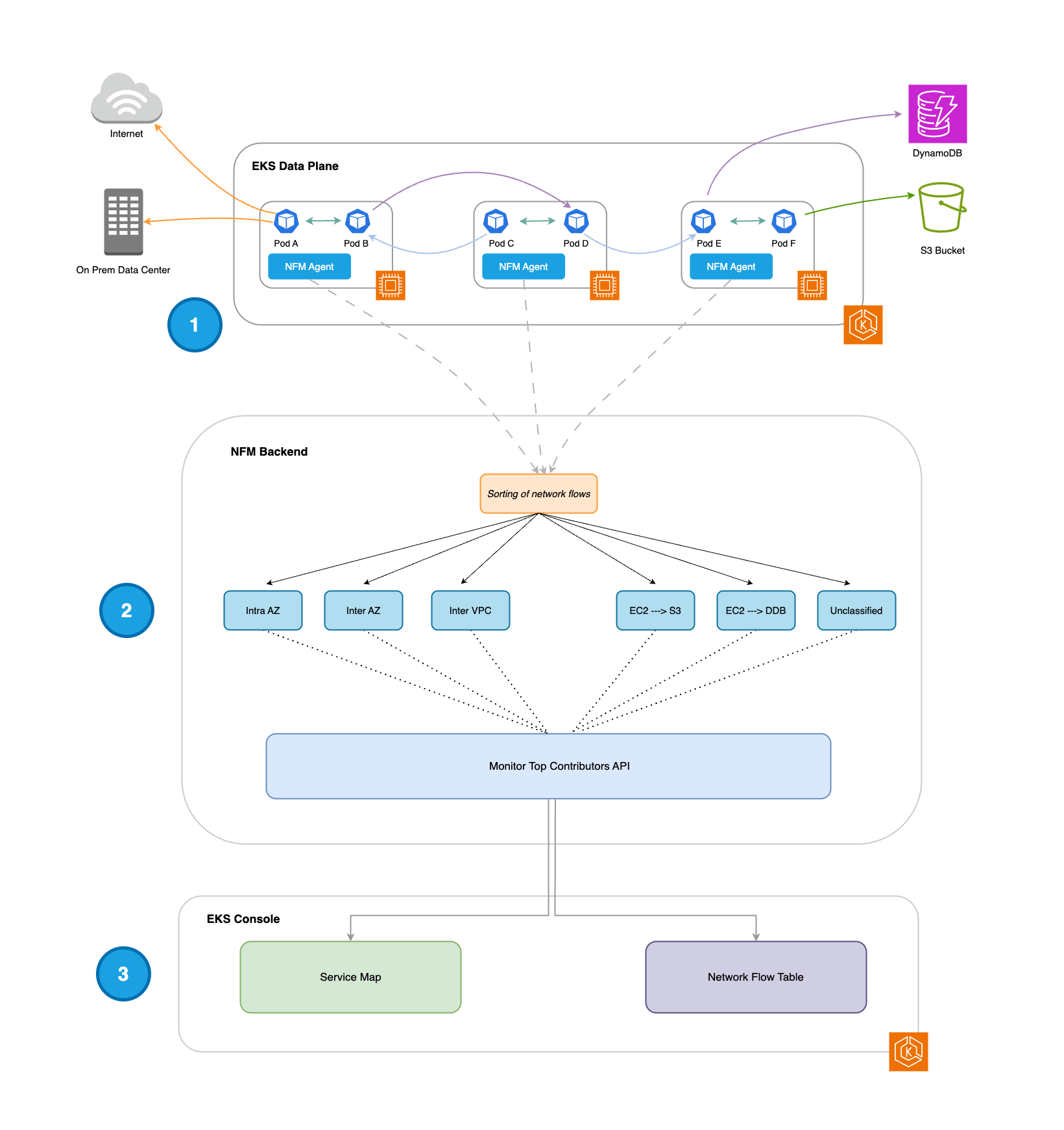
-
Una volta installato, l'agente Network Flow Monitor viene eseguito DaemonSet su ogni nodo di lavoro e raccoglie i primi 500 flussi di rete (in base al volume di dati trasferiti) ogni 30 secondi.
-
Questi flussi di rete sono suddivisi nelle seguenti categorie: Intra AZ, Inter AZ, EC2 → S3, EC2 → DynamoDB (DDB) e Unclassified. A ogni flusso sono associate 3 metriche: ritrasmissioni, timeout di ritrasmissione e dati trasferiti (in byte).
-
Intra AZ: flussi di rete tra pod nella stessa AZ
-
Inter AZ: flussi di rete tra pod in diverse AZ
-
EC2 → S3: la rete scorre dai pod a S3
-
EC2 → DDB: flussi di rete dai pod al DDB
-
Non classificato: la rete scorre dai pod a Internet o in locale
-
-
I flussi di rete dell'API Network Flow Monitor Top Contributors vengono utilizzati per potenziare le seguenti esperienze nella console EKS:
-
Mappa dei servizi: visualizzazione dei flussi di rete all'interno del cluster (Intra AZ e Inter AZ).
-
Tabella dei flussi: presentazione in tabella dei flussi di rete all'interno del cluster (Intra AZ e Inter AZ), dai pod ai AWS servizi (EC2 → S3 ed EC2 → DDB) e dai pod alle destinazioni esterne (non classificate).
-
I flussi di rete estratti dall'API Top Contributors sono limitati a un intervallo di tempo di 1 ora e possono includere fino a 500 flussi per ciascuna categoria. Per quanto riguarda la mappa dei servizi, ciò significa che è possibile reperire e presentare fino a 1000 flussi dalle categorie di flusso Intra AZ e Inter AZ in un intervallo di tempo di 1 ora. Per quanto riguarda la tabella dei flussi, ciò significa che è possibile reperire e presentare fino a 2500 flussi di rete da tutte e 5 le categorie di flussi di rete in un intervallo di tempo di 2 ore.
Esempio: mappa dei servizi
Visualizzazione della distribuzione
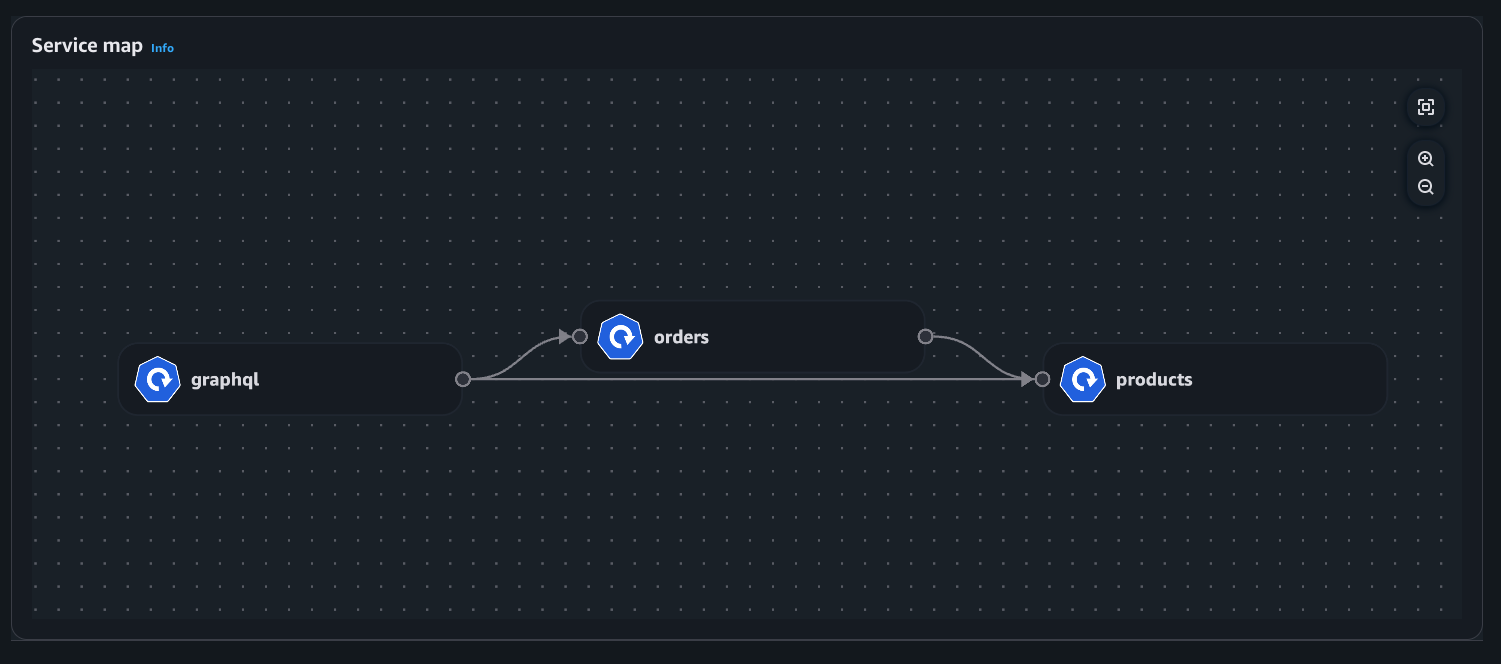
Vista Pod
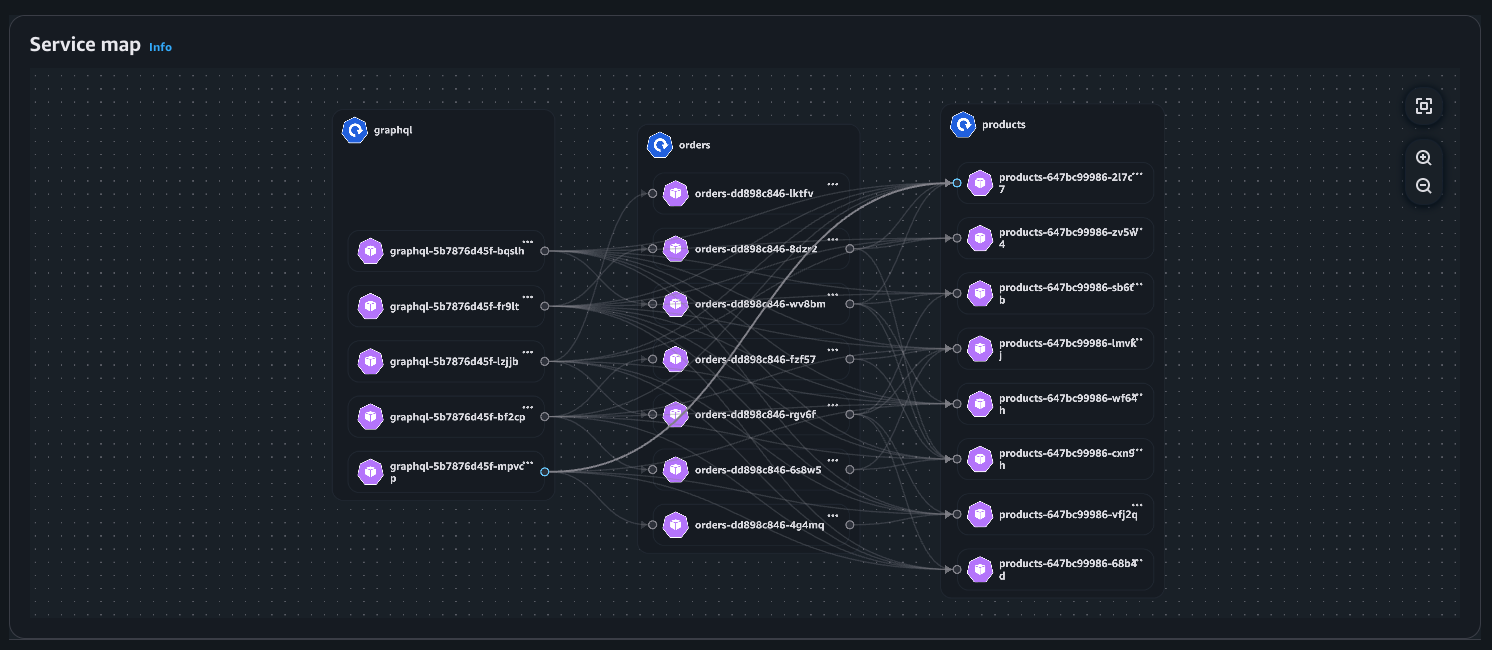
Vista di distribuzione
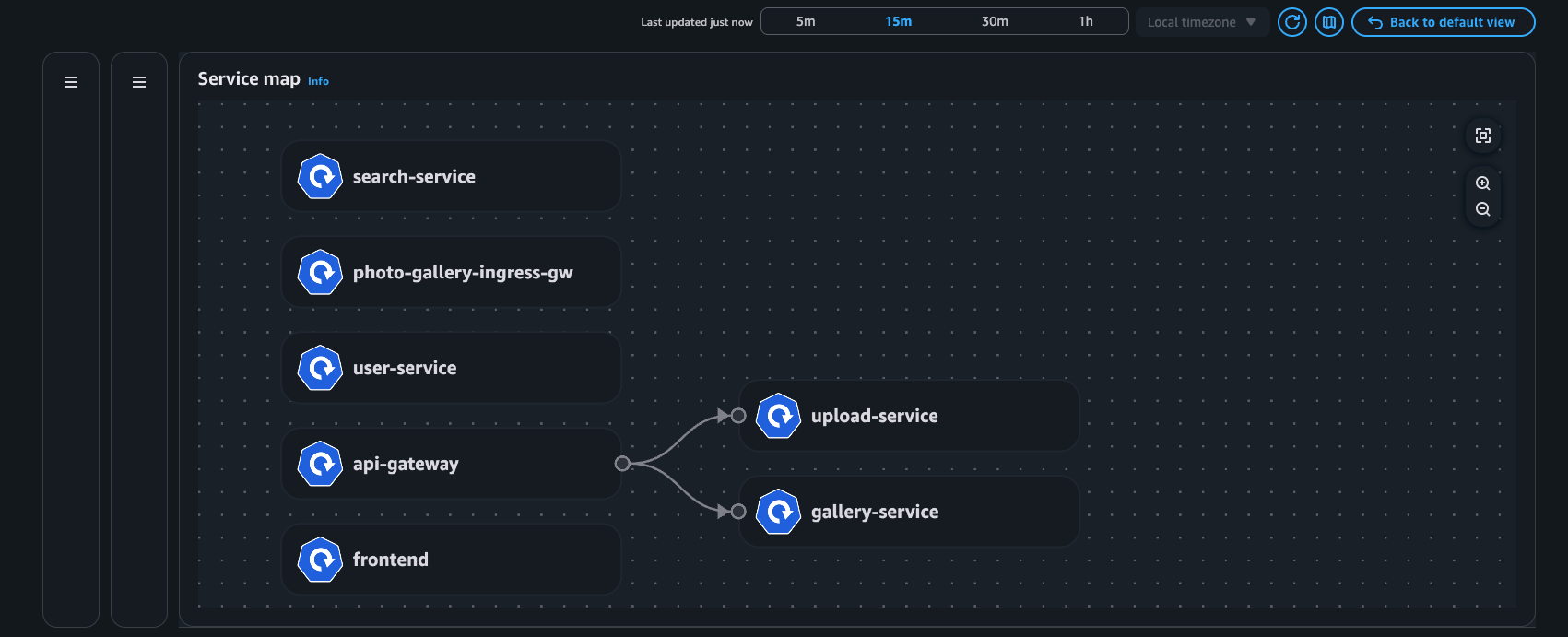
Vista Pod
Esempio: tabella di flusso
AWS visualizzazione del servizio
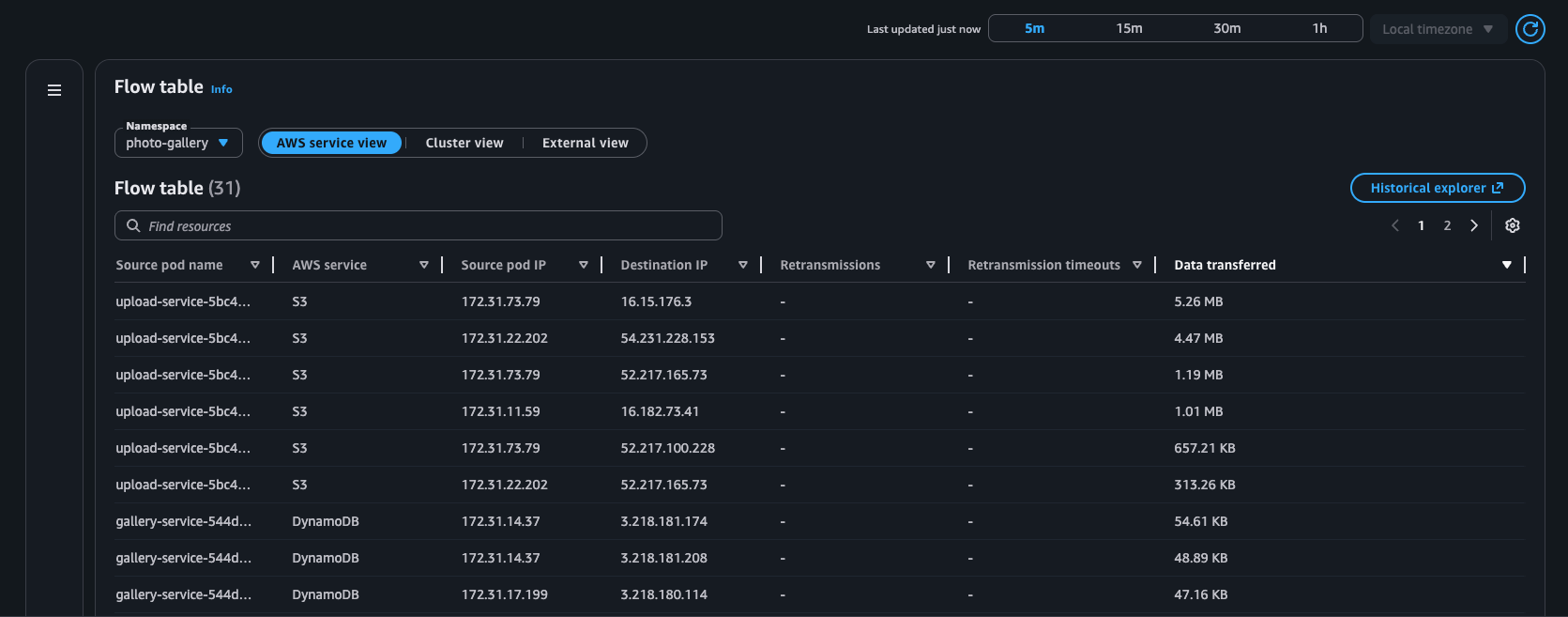
Vista a grappolo
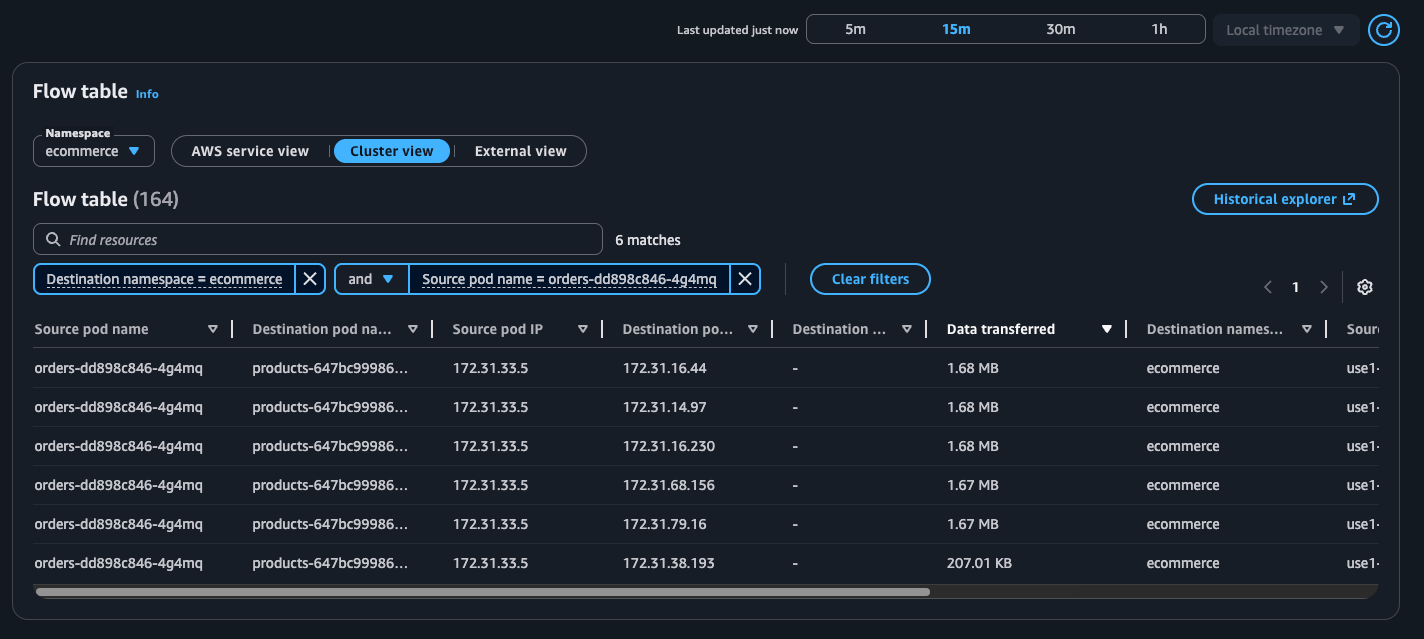
Considerazioni e limitazioni
-
L'osservabilità della rete di contenitori in EKS è disponibile solo nelle regioni in cui è supportato Network Flow Monitor.
-
Le metriche di sistema supportate sono in OpenMetrics formato e possono essere estratte direttamente dall'agente Network Flow Monitor (NFM).
-
Per abilitare l'osservabilità della rete dei container in EKS utilizzando Infrastructure as Code (IaC) come Terraform
, è necessario definire e creare queste dipendenze nelle configurazioni: ambito NFM, monitor NFM e agente NFM. -
Network Flow Monitor supporta fino a circa 5 milioni di flussi al minuto. Si tratta di circa 5.000 istanze EC2 (nodi di lavoro EKS) con l'agente Network Flow Monitor installato. L'installazione di agenti su più di 5000 istanze può influire sulle prestazioni di monitoraggio fino a quando non sarà disponibile capacità aggiuntiva.
-
È necessario eseguire una versione minima di 1.1.0 per il componente aggiuntivo EKS dell'agente NFM.
-
È necessario utilizzare la versione 6.21.0 o successiva di Terraform AWS Provider
per il supporto delle risorse di Network Flow Monitor. -
Per arricchire i flussi di rete con i metadati dei pod, i pod devono funzionare nel proprio spazio dei nomi di rete isolato, non nello spazio dei nomi della rete host.
