Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Piano di controllo Kubernetes
Suggerimento
Esplora le
Il piano di controllo Kubernetes è composto da Kubernetes API Server, Kubernetes Controller Manager, Scheduler e altri componenti necessari per il funzionamento di Kubernetes. I limiti di scalabilità di questi componenti variano a seconda di ciò che viene eseguito nel cluster, ma le aree con il maggiore impatto sulla scalabilità includono la versione di Kubernetes, l'utilizzo e la scalabilità dei singoli nodi.
Puoi eseguire il piano di controllo del cluster in una delle due modalità per soddisfare diversi requisiti di carico di lavoro:
-
Modalità standard: per impostazione predefinita, tutti i cluster EKS utilizzano la modalità Standard. Il piano di controllo si ridimensiona automaticamente verso l'alto e verso il basso in base alle esigenze del carico di lavoro. La modalità standard alloca dinamicamente una capacità sufficiente del piano di controllo ed è l'opzione consigliata per la maggior parte dei casi d'uso.
-
Modalità Provisioned: se i carichi di lavoro non possono tollerare la variabilità delle prestazioni dovuta alla scalabilità del piano di controllo o se richiedono una capacità del piano di controllo molto elevata, è possibile utilizzare la modalità Provisioned. Con la modalità Provisioned, è possibile preallocare la capacità del piano di controllo che è sempre pronta a gestire requisiti impegnativi. Ottieni prestazioni costanti e prevedibili.
Con la modalità EKS Provisioned, puoi scegliere tra una serie di livelli di scalabilità (XL, 2XL, 4XL e 8XL). Con ogni livello, si ottengono prestazioni elevate e prevedibili dal piano di controllo del cluster. La modalità Provisioned è particolarmente utile per i seguenti casi d'uso:
-
Performance-critical carichi di lavoro
-
Large-scale operazioni di intelligenza artificiale e apprendimento automatico
-
Eventi attesi ad alta richiesta
-
Ambienti che richiedono coerenza tra allestimento e produzione
Con la modalità Provisioned, è possibile preallocare in anticipo la capacità del piano di controllo e beneficiare di un Service Level Agreement (SLA) migliorato al 99,99% misurato a intervalli di 1 minuto. Per ulteriori informazioni sulla modalità EKS Provisioned, comprese le specifiche dei livelli e i prezzi, consulta EKS Provisioned Control Plane nella Guida per l'utente EKS.
Limita il carico di lavoro e l'interruzione dei nodi
Importante
Per evitare di raggiungere i limiti delle API sul piano di controllo, è necessario limitare i picchi di scalabilità che aumentano le dimensioni del cluster con percentuali a due cifre alla volta (ad esempio da 1000 nodi a 1100 nodi o da 4000 a 4500 pod contemporaneamente).
Il piano di controllo EKS si ridimensionerà automaticamente man mano che il cluster cresce, ma ci sono dei limiti alla velocità di scalabilità. Quando crei per la prima volta un cluster EKS, Control Plane non sarà immediatamente in grado di scalare fino a centinaia di nodi o migliaia di pod. Per saperne di più su come EKS ha apportato miglioramenti alla scalabilità, consulta questo post sul blog
La scalabilità di applicazioni di grandi dimensioni richiede che l'infrastruttura si adatti per diventare completamente pronte (ad esempio, sistemi di bilanciamento del carico di riscaldamento). Per controllare la velocità di scalabilità, assicurati di eseguire il ridimensionamento in base alle metriche corrette per la tua applicazione. Il ridimensionamento della CPU e della memoria potrebbe non prevedere con precisione i vincoli dell'applicazione e l'utilizzo di metriche personalizzate (ad esempio richieste al secondo) in Kubernetes Horizontal Pod Autoscaler (HPA) potrebbe essere un'opzione di scalabilità migliore.
Per utilizzare una metrica personalizzata, consulta gli esempi nella documentazione di Kubernetes.
Ridimensiona nodi e pod in modo sicuro
Sostituisci le istanze a esecuzione prolungata
La sostituzione regolare dei nodi mantiene il cluster integro evitando variazioni di configurazione e problemi che si verificano solo dopo tempi di attività prolungati (ad esempio perdite di memoria lente). La sostituzione automatizzata ti fornirà procedure e procedure ottimali per gli aggiornamenti dei nodi e le patch di sicurezza. Se ogni nodo del cluster viene sostituito regolarmente, è necessaria una minore fatica per mantenere processi separati per la manutenzione continua.
Usa le impostazioni time to live (TTL) di Karpenter per sostituire le istanze dopo che sono state in esecuzione per un determinato periodo di tempo. I gruppi di nodi autogestiti possono utilizzare l'max-instance-lifetimeimpostazione per ciclare automaticamente i nodi. I gruppi di nodi gestiti non dispongono attualmente di questa funzionalità, ma puoi tenere traccia della richiesta qui GitHub
Rimuovi i nodi sottoutilizzati
Puoi rimuovere i nodi quando non hanno carichi di lavoro in esecuzione utilizzando la soglia di scalabilità inferiore in Kubernetes Cluster Autoscaler con --scale-down-utilization-thresholdttlSecondsAfterEmpty
Utilizza i budget per le interruzioni dei pod e lo spegnimento sicuro dei nodi
La rimozione di pod e nodi da un cluster Kubernetes richiede ai controller di aggiornare più risorse (ad esempio). EndpointSlices Questa operazione frequente o troppo rapida può causare limitazioni del server API e interruzioni delle applicazioni man mano che le modifiche si propagano ai controller. I Pod Disruption Budgets
Client-Side Usa Cache quando esegui Kubectl
L'uso inefficiente del comando kubectl può aggiungere ulteriore carico al Kubernetes API Server. Dovresti evitare di eseguire script o automazioni che utilizzano kubectl ripetutamente (ad esempio in un ciclo for) o di eseguire comandi senza una cache locale.
kubectldispone di una cache lato client che memorizza nella cache le informazioni di rilevamento dal cluster per ridurre la quantità di chiamate API richieste. La cache è abilitata per impostazione predefinita e viene aggiornata ogni 10 minuti.
Se esegui kubectl da un contenitore o senza una cache lato client, potresti riscontrare problemi di limitazione delle API. Si consiglia di conservare la cache del cluster montandola per evitare di effettuare chiamate API non necessarie. --cache-dir
Disabilita la compressione kubectl
La disabilitazione della compressione kubectl nel file kubeconfig può ridurre l'utilizzo dell'API e della CPU del client. Per impostazione predefinita, il server comprime i dati inviati al client per ottimizzare la larghezza di banda della rete. Ciò aumenta il carico della CPU sul client e sul server per ogni richiesta e la disabilitazione della compressione può ridurre il sovraccarico e la latenza se si dispone di una larghezza di banda adeguata. Per disabilitare la compressione puoi usare il --disable-compression=true flag o il set disable-compression: true nel tuo file kubeconfig.
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
Shard Cluster Autoscaler
Kubernetes Cluster Autoscaler è stato testato per scalare
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
Priorità ed equità delle API
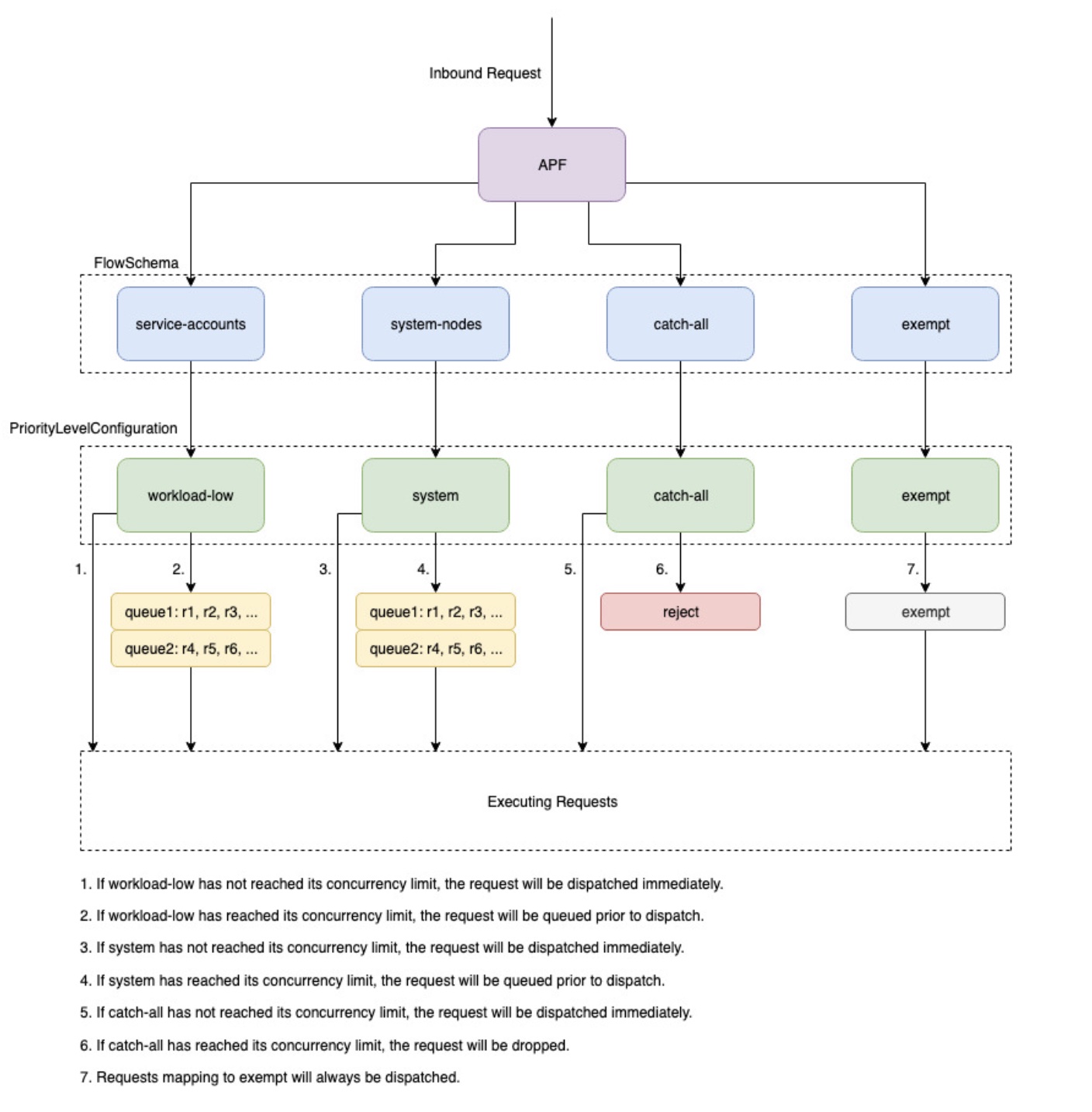
Panoramica di
Per proteggersi dal sovraccarico durante i periodi di aumento delle richieste, l'API Server limita il numero di richieste in arrivo che può avere in sospeso in un determinato momento. Una volta superato questo limite, l'API Server inizierà a rifiutare le richieste e restituirà ai client un codice di risposta HTTP 429 per «Troppe richieste». È preferibile che il server lasci cadere le richieste e che i client riprovino più tardi piuttosto che non avere limiti sul lato server sul numero di richieste e sovraccaricare il piano di controllo, il che potrebbe comportare un peggioramento delle prestazioni o l'indisponibilità.
Il meccanismo utilizzato da Kubernetes per configurare il modo in cui queste richieste in entrata vengono suddivise tra diversi tipi di richiesta si chiama API Priority and Fairness.--max-requests-inflight --max-mutating-requests-inflight EKS utilizza i valori predefiniti di 400 e 200 richieste per questi flag, consentendo l'invio di un totale di 600 richieste in un determinato momento. Tuttavia, poiché ridimensiona il piano di controllo a dimensioni maggiori in risposta all'aumento dell'utilizzo e all'abbandono del carico di lavoro, aumenta di conseguenza la quota di richieste in volo fino al 2000 (soggetta a modifiche). APF specifica in che modo queste quote di richieste in volo sono ulteriormente suddivise tra diversi tipi di richieste. Tieni presente che i piani di controllo EKS sono altamente disponibili con almeno 2 server API registrati in ciascun cluster. Ciò significa che il numero totale di richieste in entrata che il cluster può gestire è il doppio (o superiore se ulteriormente ridimensionato orizzontalmente) rispetto alla quota di volo impostata per kube-apiserver. Ciò equivale a diverse migliaia di cluster EKS più grandi. requests/second
Due tipi di oggetti Kubernetes, chiamati PriorityLevelConfigurations e FlowSchemas, configurano il modo in cui il numero totale di richieste viene suddiviso tra diversi tipi di richieste. Questi oggetti vengono gestiti automaticamente dal server API ed EKS utilizza la configurazione predefinita di questi oggetti per la versione secondaria di Kubernetes specificata. PriorityLevelConfigurations rappresentano una frazione del numero totale di richieste consentite. Ad esempio, al workload-high PriorityLevelConfiguration viene allocato 98 su un totale di 600 richieste. La somma delle richieste assegnate a tutte PriorityLevelConfigurations sarà pari a 600 (o leggermente superiore a 600 perché il server API arrotonderà per eccesso se a un determinato livello viene concessa una frazione di una richiesta). Per verificare la presenza del PriorityLevelConfigurations cluster e il numero di richieste assegnate a ciascuno, è possibile eseguire il comando seguente. Queste sono le impostazioni predefinite di EKS 1.32:
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_nominal_limit_seats apiserver_flowcontrol_nominal_limit_seats{priority_level="catch-all"} 13 apiserver_flowcontrol_nominal_limit_seats{priority_level="exempt"} 0 apiserver_flowcontrol_nominal_limit_seats{priority_level="global-default"} 49 apiserver_flowcontrol_nominal_limit_seats{priority_level="leader-election"} 25 apiserver_flowcontrol_nominal_limit_seats{priority_level="node-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="system"} 74 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-high"} 98 apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245
Il secondo tipo di oggetto è. FlowSchemas Le richieste del server API con un determinato set di proprietà sono classificate nello stesso gruppo FlowSchema. Queste proprietà includono l'utente autenticato o gli attributi della richiesta, come il gruppo API, lo spazio dei nomi o la risorsa. A specifica FlowSchema anche a quale PriorityLevelConfiguration tipo di richiesta deve essere mappato. I due oggetti insieme dicono: «Voglio che questo tipo di richiesta venga conteggiata per questa quota di richieste in volo». Quando una richiesta raggiunge il server API, quest'ultimo controllerà ciascuna di esse FlowSchemas finché non ne troverà una che corrisponda a tutte le proprietà richieste. Se più richieste FlowSchemas corrispondono a una richiesta, il server API sceglierà quella FlowSchema con la precedenza di corrispondenza più piccola specificata come proprietà nell'oggetto.
La mappatura di FlowSchemas to PriorityLevelConfigurations può essere visualizzata utilizzando questo comando:
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations può avere un tipo di Queue, Reject o Exempt. Per i tipi Queue e Reject, viene applicato un limite al numero massimo di richieste in entrata per quel livello di priorità, tuttavia il comportamento varia quando viene raggiunto tale limite. Ad esempio, il workload-high PriorityLevelConfiguration utilizza il tipo Queue e dispone di 98 richieste che possono essere utilizzate dai controller relativi a controller-manager, endpoint-controller, scheduler, eks e dai pod in esecuzione nello spazio dei nomi del sistema kube. Poiché viene utilizzato il tipo Queue, l'API Server tenterà di conservare le richieste in memoria e spera che il numero di richieste in entrata scenda al di sotto di 98 prima che queste richieste scadano. Se una determinata richiesta scade in coda o se troppe richieste sono già in coda, l'API Server non ha altra scelta che abbandonare la richiesta e restituire al client un 429. Tieni presente che l'accodamento può impedire a una richiesta di ricevere un 429, ma comporta il compromesso di una maggiore latenza end-to-end sulla richiesta.
Consideriamo ora il catch-all FlowSchema che viene mappato al catch-all con il tipo Reject PriorityLevelConfiguration . Se i client raggiungono il limite di 13 richieste in entrata, l'API Server non metterà in coda le richieste e le eliminerà immediatamente con un codice di risposta 429. Infine, le richieste che corrispondono a un PriorityLevelConfiguration tipo Exempt non riceveranno mai un 429 e verranno sempre inviate immediatamente. Viene utilizzato per richieste ad alta priorità come richieste healthz o richieste provenienti dal gruppo system:masters.
Monitoraggio di APF e richieste abbandonate
Per confermare se alcune richieste vengono eliminate a causa di APF, è apiserver_flowcontrol_rejected_requests_total possibile monitorare le metriche del server API per verificare l'impatto e. FlowSchemas PriorityLevelConfigurations Ad esempio, questa metrica mostra che 100 richieste provenienti dagli account di servizio FlowSchema sono state eliminate a causa del timeout delle richieste nelle code con un basso carico di lavoro:
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
Per verificare quanto manca a un determinato numero di 429 secondi la ricezione o se PriorityLevelConfiguration si verifica un aumento della latenza dovuto all'accodamento, puoi confrontare la differenza tra il limite di concorrenza e la concorrenza in uso. In questo esempio, abbiamo un buffer di 100 richieste.
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_nominal_limit_seats.*workload-low' apiserver_flowcontrol_nominal_limit_seats{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_executing_seats.*workload-low' apiserver_flowcontrol_current_executing_seats{flow_schema="service-accounts",priority_level="workload-low"} 145
Per verificare se una determinata richiesta PriorityLevelConfiguration è in coda ma non necessariamente abbandonata, è possibile fare riferimento alla metrica perapiserver_flowcontrol_current_inqueue_requests:
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
Altre metriche utili di Prometheus includono:
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
Consulta la documentazione originale per un elenco completo delle metriche APF.
Prevenzione delle richieste abbandonate
Evita i 429 cambiando il tuo carico di lavoro
Quando APF interrompe le richieste a causa del PriorityLevelConfiguration superamento del numero massimo consentito di richieste in volo, i clienti della zona interessata FlowSchemas possono ridurre il numero di richieste in esecuzione in un determinato momento. Ciò può essere ottenuto riducendo il numero totale di richieste effettuate nel periodo in cui si verificano 429 richieste. Tieni presente che le richieste di lunga durata, come le costose chiamate a elenchi, sono particolarmente problematiche perché vengono conteggiate come richieste in volo per l'intera durata dell'esecuzione. Ridurre il numero di queste costose richieste o ottimizzare la latenza di queste chiamate alla lista (ad esempio, riducendo il numero di oggetti recuperati per richiesta o passando all'utilizzo di una richiesta di controllo) può aiutare a ridurre la concorrenza totale richiesta da un determinato carico di lavoro.
Evita i 429 cambiando le impostazioni APF
avvertimento
Modifica le impostazioni APF predefinite solo se sai cosa stai facendo. Le impostazioni APF non configurate correttamente possono causare la perdita delle richieste del server API e gravi interruzioni del carico di lavoro.
Un altro approccio per prevenire la perdita delle richieste consiste nel modificare le impostazioni predefinite FlowSchemas o PriorityLevelConfigurations installarle sui cluster EKS. EKS installa le impostazioni predefinite upstream per FlowSchemas e PriorityLevelConfigurations per la versione secondaria di Kubernetes specificata. Il server API riconcilierà automaticamente questi oggetti ai valori predefiniti se modificati, a meno che la seguente annotazione sugli oggetti non sia impostata su false:
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
A un livello elevato, le impostazioni APF possono essere modificate in uno dei seguenti modi:
-
Assegna una maggiore capacità in volo alle richieste che ti interessano.
-
Isola le richieste non essenziali o costose che possono ridurre la capacità per altri tipi di richieste.
Ciò può essere ottenuto modificando l'impostazione predefinita FlowSchemas PriorityLevelConfigurations e/o creando nuovi oggetti di questo tipo. Gli operatori possono aumentare i valori di Assured ConcurrencyShares per gli PriorityLevelConfigurations oggetti pertinenti per aumentare la percentuale di richieste in volo che vengono loro assegnate. Inoltre, il numero di richieste che possono essere messe in coda in un determinato momento può essere aumentato se l'applicazione è in grado di gestire la latenza aggiuntiva causata dalle richieste messe in coda prima di essere inviate.
In alternativa, è possibile creare nuovi PriorityLevelConfigurations oggetti FlowSchema e oggetti specifici per il carico di lavoro del cliente. Tieni presente che l'assegnazione di più garanzie ConcurrencyShares a risorse esistenti PriorityLevelConfigurations o nuove PriorityLevelConfigurations comporterà una riduzione del numero di richieste che possono essere gestite da altri bucket, poiché il limite complessivo rimarrà di 600 in volo per server API.
Quando si apportano modifiche ai valori predefiniti di APF, queste metriche devono essere monitorate su un cluster non di produzione per garantire che la modifica delle impostazioni non provochi 429 indesiderati:
-
La metrica per
apiserver_flowcontrol_rejected_requests_totaldeve essere monitorata per tutti per garantire che nessun bucket cominci FlowSchemas a far cadere le richieste. -
I valori relativi
apiserver_flowcontrol_nominal_limit_seatseapiserver_flowcontrol_current_executing_seatsdevono essere confrontati per garantire che la concorrenza in uso non rischi di violare il limite per quel livello di priorità.
Un caso d'uso comune per definire un nuovo FlowSchema e PriorityLevelConfiguration riguarda l'isolamento. Supponiamo di voler isolare le chiamate a eventi di lunga durata a una lista dai pod in base alla rispettiva quota di richieste. Ciò eviterà che le richieste importanti provenienti dai pod che utilizzano gli account di servizio esistenti ricevano 429 richieste e non abbiano più FlowSchema capacità di richiesta. Ricordiamo che il numero totale di richieste in entrata è limitato, tuttavia, questo esempio mostra che le impostazioni APF possono essere modificate per suddividere meglio la capacità delle richieste per un determinato carico di lavoro:
FlowSchema Oggetto di esempio per isolare le richieste di eventi della lista:
apiVersion: flowcontrol.apiserver.k8s.io/v1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
Questo FlowSchema cattura tutte le chiamate agli eventi di elenco effettuate dagli account di servizio nello spazio dei nomi predefinito.
-
La precedenza di corrispondenza 8000 è inferiore al valore di 9000 utilizzato dagli account di servizio esistenti, FlowSchema quindi queste chiamate agli eventi di elenco corrisponderanno a list-events-default-service-accounts anziché a service-accounts.
-
Stiamo usando il catch-all PriorityLevelConfiguration per isolare queste richieste. Questo bucket consente di utilizzare solo 13 richieste in arrivo da queste chiamate di eventi di lunga durata. I pod inizieranno a ricevere 429 richieste non appena cercheranno di inviare più di 13 di queste richieste contemporaneamente.
Recupero di risorse nel server API
La raccolta di informazioni dal server API è un comportamento previsto per i cluster di qualsiasi dimensione. Man mano che si aumenta il numero di risorse nel cluster, la frequenza delle richieste e il volume dei dati possono rapidamente diventare un ostacolo per il piano di controllo e portare alla latenza e alla lentezza delle API. A seconda della gravità della latenza, se non si presta attenzione, si verificano tempi di inattività imprevisti.
Essere consapevoli di ciò che si richiede e con quale frequenza sono i primi passi per evitare questo tipo di problemi. Di seguito sono riportate alcune linee guida per limitare il volume delle query in base alle migliori pratiche di scalabilità. I suggerimenti contenuti in questa sezione vengono forniti a partire dalle opzioni note per garantire la scalabilità ottimale.
Usa Shared Informer
Quando si creano controller e sistemi di automazione che si integrano con l'API Kubernetes, spesso è necessario ottenere informazioni dalle risorse Kubernetes. Se effettui regolarmente sondaggi su queste risorse, ciò può causare un carico significativo sul server API.
L'utilizzo di un informatore
I controllori dovrebbero evitare di eseguire il polling di risorse a livello di cluster senza etichette e selettori di campo, specialmente in cluster di grandi dimensioni. Ogni sondaggio non filtrato richiede l'invio di molti dati non necessari da etcd tramite il server API per essere filtrati dal client. Filtrando in base a etichette e namespace è possibile ridurre la quantità di lavoro che il server API deve eseguire per soddisfare la richiesta e i dati inviati al client.
Ottimizza l'utilizzo dell'API Kubernetes
Quando si chiama l'API Kubernetes con controller personalizzati o automazione, è importante limitare le chiamate solo alle risorse necessarie. Senza limiti, puoi causare un carico non necessario sul server API e così via.
Si consiglia di utilizzare l'argomento watch ogni volta che è possibile. Senza argomenti, il comportamento predefinito consiste nell'elencare gli oggetti. Per utilizzare watch anziché list puoi aggiungerlo ?watch=true alla fine della tua richiesta API. Ad esempio, per inserire tutti i pod nello spazio dei nomi predefinito con un orologio, usa:
/api/v1/namespaces/default/pods?watch=true
Se state elencando oggetti, dovreste limitare l'ambito di ciò che state elencando e la quantità di dati restituiti. È possibile limitare i dati restituiti aggiungendo limit=500 argomenti alle richieste. L'fieldSelectorargomento e il /namespace/ percorso possono essere utili per assicurarsi che gli elenchi abbiano un ambito ristretto quanto necessario. Ad esempio, per elencare solo i pod in esecuzione nello spazio dei nomi predefinito, utilizza il percorso e gli argomenti dell'API seguenti.
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
Oppure elenca tutti i pod che funzionano con:
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
Un'altra opzione per limitare le chiamate di controllo o gli oggetti elencati è quella di utilizzare resourceVersions, come puoi leggere nella documentazione di KubernetesresourceVersion argomenti, riceverai la versione più recente disponibile che richiede una lettura del quorum etcd, che è la lettura più costosa e più lenta per il database. La ResourceVersion dipende dalle risorse che state cercando di interrogare e può essere trovata sul campo. metadata.resourseVersion Ciò è consigliato anche nel caso in cui si utilizzino le chiamate watch e non solo le chiamate in elenco
È resourceVersion=0 disponibile uno speciale che restituirà i risultati dalla cache del server API. Questo può ridurre il carico di etcd ma non supporta l'impaginazione.
/api/v1/namespaces/default/pods?resourceVersion=0
Si consiglia di utilizzare watch con un valore ResourceVersion impostato come valore noto più recente ricevuto dall'elenco o dall'orologio precedente. Questo viene gestito automaticamente in client-go. Ma si consiglia di ricontrollarlo se si utilizza un client k8s in altre lingue.
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
Se chiami l'API senza argomenti, sarà la più dispendiosa in termini di risorse per il server API e così via. Questa chiamata otterrà tutti i pod in tutti i namespace senza impaginazione o limitazione dell'ambito e richiederà la lettura del quorum da etcd.
/api/v1/pods
Evita il fragore delle mandrie DaemonSet
A DaemonSet assicura che tutti (o alcuni) nodi eseguano una copia di un pod. Quando i nodi si uniscono al cluster, il daemonset-controller crea dei pod per quei nodi. Quando i nodi lasciano il cluster, quei pod vengono raccolti nella spazzatura. L'eliminazione di un file DaemonSet pulirà i pod che ha creato.
Alcuni usi tipici di a DaemonSet sono:
-
Esecuzione di un demone di archiviazione del cluster su ogni nodo
-
Esecuzione di un demone di raccolta dei log su ogni nodo
-
Esecuzione di un demone di monitoraggio dei nodi su ogni nodo
Nei cluster con migliaia di nodi, la creazione di un nuovo nodo DaemonSet, l'aggiornamento o l'aumento del numero di nodi può comportare un carico elevato sul piano di controllo. DaemonSet Se DaemonSet i pod emettono costose richieste ai server API all'avvio del pod, possono causare un elevato utilizzo di risorse sul piano di controllo a causa di un gran numero di richieste simultanee.
Durante il normale funzionamento, è possibile utilizzare RollingUpdate a per garantire l'implementazione graduale di nuovi pod. DaemonSet Con una strategia di RollingUpdate aggiornamento, dopo aver aggiornato un DaemonSet modello, il controller elimina i vecchi DaemonSet pod e ne crea automaticamente di nuovi in modo DaemonSet controllato. Al massimo un pod DaemonSet sarà in esecuzione su ciascun nodo durante l'intero processo di aggiornamento. È possibile eseguire un'implementazione graduale maxUnavailable impostando su 1, su 0 e maxSurge minReadySeconds su 60. Se non specifichi una strategia di aggiornamento, per impostazione predefinita Kubernetes creerà un RollingUpdate con maxUnavailable 1, maxSurge 0 e 0. minReadySeconds
minReadySeconds: 60 strategy: type: RollingUpdate rollingUpdate: maxSurge: 0 maxUnavailable: 1
A RollingUpdate assicura l'implementazione graduale di nuovi DaemonSet pod se DaemonSet è già stato creato e ha il numero previsto di pod su tutti i nodi. Ready In determinate condizioni, che non sono coperte dalle strategie, possono insorgere problemi legati al Thundering Herd. RollingUpdate
Evita che le greggi si agitino al momento della creazione DaemonSet
Per impostazione predefinita, indipendentemente dalla RollingUpdate configurazione, il daemonset-controller nel kube-controller-manager creerà i pod per tutti i nodi corrispondenti contemporaneamente quando ne crei uno nuovo. DaemonSet Per forzare l'implementazione graduale dei pod dopo aver creato un, puoi usare un o. DaemonSet NodeSelector NodeAffinity In questo DaemonSet modo verrà creato un oggetto corrispondente a zero nodi, quindi potrai aggiornare gradualmente i nodi per renderli idonei a far funzionare un pod DaemonSet a una velocità controllata. Puoi seguire questo approccio:
-
Aggiungi un'etichetta a tutti i nodi per
run-daemonset=false.
kubectl label nodes --all run-daemonset=false
-
Crea il tuo DaemonSet con un'
NodeAffinityimpostazione che corrisponda a qualsiasi nodo senzarun-daemonset=falseetichetta. Inizialmente, ciò comporterà l' DaemonSet assenza di pod corrispondenti.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
Rimuovi l'
run-daemonset=falseetichetta dai tuoi nodi a una velocità controllata. Puoi usare questo script bash come esempio:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
Facoltativamente, rimuovi l'
NodeAffinityimpostazione dal tuo DaemonSet oggetto. Nota che questo attiverà anche un contenitoreRollingUpdatee sostituirà gradualmente tutti i DaemonSet pod esistenti a causa della modifica del DaemonSet modello.
Evita che le masse si agitino grazie alla scalabilità orizzontale dei nodi
Analogamente alla DaemonSet creazione, la creazione di nuovi nodi a una velocità elevata può comportare l'avvio simultaneo di un gran numero di pod. DaemonSet È necessario creare nuovi nodi a una velocità controllata in modo che il controller crei DaemonSet i pod alla stessa velocità. Se ciò non è possibile, puoi rendere inizialmente i nuovi nodi non idonei per quelli esistenti DaemonSet utilizzando. NodeAffinity Successivamente, potete aggiungere gradualmente un'etichetta ai nuovi nodi in modo che il daemonset-controller crei i pod a una velocità controllata. Puoi seguire questo approccio:
-
Aggiungi un'etichetta a tutti i nodi esistenti per
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
Aggiorna il tuo DaemonSet con un'
NodeAffinityimpostazione che corrisponda a qualsiasi nodo con un'run-daemonset=trueetichetta. Nota che questo attiverà anche un podRollingUpdatee sostituirà gradualmente tutti i DaemonSet pod esistenti perché il DaemonSet modello è cambiato. È necessario attendere ilRollingUpdatecompletamento dell'operazione prima di passare alla fase successiva.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
Crea nuovi nodi nel tuo cluster. Nota che questi nodi non avranno l'
run-daemonset=trueetichetta, quindi non DaemonSet corrisponderanno a quei nodi. -
Aggiungi l'
run-daemonset=trueetichetta ai nuovi nodi (che attualmente non hanno l'run-daemonsetetichetta) a una velocità controllata. Puoi usare questo script bash come esempio:
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
Facoltativamente, rimuovi l'
NodeAffinityimpostazione dal tuo DaemonSet oggetto e rimuovi l'run-daemonsetetichetta da tutti i nodi.
Evita che le mandrie si agitino durante gli aggiornamenti DaemonSet
Una RollingUpdate politica rispetterà solo l'maxUnavailableimpostazione dei DaemonSet pod che lo sono. Ready Se a DaemonSet ha solo NotReady pod o una grande percentuale di NotReady pod e ne aggiorni il modello, il daemonset-controller creerà nuovi pod contemporaneamente per tutti i pod. NotReady Ciò può causare problemi di Thundering Herd in presenza di un numero significativo di pod, ad esempio se i NotReady pod si bloccano continuamente o non riescono a estrarre immagini.
Per forzare l'implementazione graduale dei pod quando si aggiorna un contenitore DaemonSet e se ne sono presenti, è possibile modificare temporaneamente la strategia di aggiornamento in modalità NotReady from to. DaemonSet RollingUpdate OnDelete ConOnDelete, dopo aver aggiornato un DaemonSet modello, il controller crea nuovi pod dopo aver eliminato manualmente quelli vecchi, in modo da poter controllare l'implementazione di nuovi pod. Puoi seguire questo approccio:
-
Controlla se ci sono dei
NotReadypod nel tuo DaemonSet. -
In caso contrario, puoi aggiornare il DaemonSet modello in tutta sicurezza e la
RollingUpdatestrategia garantirà un'implementazione graduale. -
In caso affermativo, dovresti prima aggiornare il tuo DaemonSet per utilizzare la
OnDeletestrategia.
updateStrategy: type: OnDelete
-
Successivamente, aggiorna il DaemonSet modello con le modifiche necessarie.
-
Dopo questo aggiornamento, puoi eliminare i vecchi DaemonSet pod inviando richieste di eliminazione dei pod a una frequenza controllata. Puoi usare questo script bash come esempio in cui il DaemonSet nome è fluentd-elasticsearch nello spazio dei nomi kube-system:
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
Infine, puoi tornare alla strategia precedente. DaemonSet
RollingUpdate
