Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione da Couchbase Server
Introduzione
Questa guida presenta i punti chiave da considerare durante la migrazione da Couchbase Server ad Amazon DocumentDB. Spiega le considerazioni relative alle fasi di scoperta, pianificazione, esecuzione e convalida della migrazione. Spiega inoltre come eseguire migrazioni offline e online.
Confronto con Amazon DocumentDB
| Server Couchbase | Amazon DocumentDB | |
|---|---|---|
| Organizzazione dei dati | Nelle versioni 7.0 e successive, i dati sono organizzati in bucket, ambiti e raccolte. Nelle versioni precedenti, i dati sono organizzati in bucket. | I dati sono organizzati in database e raccolte. |
| Compatibilità | Esistono diversi APIs servizi (ad esempio dati, indice, ricerca, ecc.). Le ricerche secondarie utilizzano SQL++ (precedentemente noto come N1QL), un linguaggio di query basato su SQL standard ANSI, familiare a molti sviluppatori. | Amazon DocumentDB è compatibile con l'API MongoDB. |
| Architettura | Lo storage è collegato a ciascuna istanza del cluster. Non è possibile scalare l'elaborazione indipendentemente dallo storage. | Amazon DocumentDB è progettato per il cloud e per evitare i limiti delle architetture di database tradizionali. I livelli di elaborazione e storage sono separati in Amazon DocumentDB e il livello di elaborazione può essere scalato indipendentemente dallo storage. |
| Aggiungi capacità di lettura su richiesta | I cluster possono essere scalati orizzontalmente aggiungendo istanze. Poiché lo storage è collegato all'istanza in cui è in esecuzione il servizio, il tempo necessario per la scalabilità orizzontale dipende dalla quantità di dati che devono essere spostati nella nuova istanza o ribilanciati. | Puoi ottenere la scalabilità di lettura per il tuo cluster Amazon DocumentDB creando fino a 15 repliche Amazon DocumentDB nel cluster. Non vi è alcun impatto sul livello di storage. |
| Ripristino rapido in caso di guasto del nodo | I cluster dispongono di funzionalità di failover automatico, ma il tempo necessario per ripristinare la piena potenza del cluster dipende dalla quantità di dati che devono essere spostati sulla nuova istanza. | Amazon DocumentDB può eseguire il failover del sistema primario in genere entro 30 secondi e ripristinare il cluster alla massima potenza in 8-10 minuti, indipendentemente dalla quantità di dati nel cluster. |
| Scala lo storage man mano che i dati crescono | Per lo storage in cluster autogestito e IOs non scalabile automaticamente. | Archiviazione e IOs scalabilità automatiche di Amazon DocumentDB. |
| Backup dei dati senza influire sulle prestazioni | I backup vengono eseguiti dal servizio di backup e non sono abilitati per impostazione predefinita. Poiché lo storage e l'elaborazione non sono separati, può esserci un impatto sulle prestazioni. | I backup di Amazon DocumentDB sono abilitati per impostazione predefinita e non possono essere disattivati. I backup sono gestiti dal livello di storage, quindi hanno un impatto zero sul livello di elaborazione. Amazon DocumentDB supporta il ripristino da uno snapshot del cluster e il ripristino da un point-in-time. |
| Durabilità dei dati | Un cluster può contenere un massimo di 3 copie di replica dei dati per un totale di 4 copie. Ogni istanza in cui è in esecuzione il servizio dati avrà 1, 2 o 3 copie di replica attive dei dati. | Amazon DocumentDB conserva 6 copie di dati indipendentemente dal numero di istanze di calcolo presenti, con un quorum di scrittura di 4 e persistent true. I client ricevono una conferma dopo che il livello di storage ha salvato 4 copie dei dati in modo permanente. |
| Coerenza | È supportata la coerenza immediata K/V delle operazioni. L'SDK di Couchbase indirizza K/V le richieste all'istanza specifica che contiene la copia attiva dei dati, quindi una volta confermato l'aggiornamento, il client ha la garanzia di leggerlo. La replica degli aggiornamenti su altri servizi (indice, ricerca, analisi, eventi) alla fine è coerente. | Le repliche di Amazon DocumentDB alla fine sono coerenti. Se sono necessarie letture di coerenza immediate, il client può leggere dall'istanza principale. |
| Replica | Cross-Data Center Replication (XDCR) fornisce una replica filtrata, attiva-passiva/attiva-attiva dei dati in molti:molte topologie. | I cluster globali di Amazon DocumentDB forniscono replica attiva-passiva in topologie 1:many (fino a 10). |
Individuazione
La migrazione ad Amazon DocumentDB richiede una conoscenza approfondita del carico di lavoro del database esistente. Il rilevamento del carico di lavoro è il processo di analisi della configurazione e delle caratteristiche operative del cluster Couchbase (set di dati, indici e carico di lavoro) per garantire una transizione senza interruzioni con interruzioni minime.
Configurazione del cluster
Couchbase utilizza un'architettura incentrata sui servizi in cui ogni funzionalità corrisponde a un servizio. Esegui il seguente comando sul tuo cluster Couchbase per determinare quali servizi vengono utilizzati (vedi Ottenere informazioni sui nodi):
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
Output di esempio:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
I servizi Couchbase includono quanto segue:
Servizio dati (kv)
Il servizio dati fornisce read/write l'accesso ai dati in memoria e su disco.
Amazon DocumentDB supporta K/V le operazioni sui dati JSON tramite l'API MongoDB.
Servizio di interrogazione (n1ql)
Il servizio di interrogazione supporta l'interrogazione di dati JSON tramite SQL++.
Amazon DocumentDB supporta l'interrogazione di dati JSON tramite l'API MongoDB.
Servizio di indicizzazione (indice)
Il servizio di indicizzazione crea e mantiene indici sui dati, velocizzando le interrogazioni.
Amazon DocumentDB supporta un indice primario predefinito e la creazione di indici secondari su dati JSON tramite l'API MongoDB.
Servizio di ricerca (fts)
Il servizio di ricerca supporta la creazione di indici per la ricerca di testo completo.
La funzionalità di ricerca full-text nativa di Amazon DocumentDB consente di eseguire ricerche di testo su set di dati testuali di grandi dimensioni utilizzando indici di testo per scopi speciali tramite l'API MongoDB. Per casi d'uso di ricerca avanzata, l'integrazione Zero-ETL di Amazon DocumentDB con OpenSearch Amazon
Servizio di analisi (cbas)
Il servizio di analisi supporta l'analisi dei dati JSON quasi in tempo reale.
Amazon DocumentDB supporta query ad hoc su dati JSON tramite l'API MongoDB. Puoi anche eseguire query complesse sui tuoi dati JSON in Amazon DocumentDB utilizzando Apache Spark in esecuzione su Amazon
Servizio di organizzazione di eventi (eventing)
Il servizio di gestione degli eventi esegue la logica di business definita dall'utente in risposta alle modifiche dei dati.
Amazon DocumentDB automatizza i carichi di lavoro basati sugli eventi richiamando AWS Lambda funzioni ogni volta che i dati cambiano con il cluster Amazon DocumentDB.
Servizio di backup (backup)
Il servizio di backup pianifica backup completi e incrementali dei dati e unioni di backup precedenti.
Amazon DocumentDB esegue continuamente il backup dei dati su Amazon S3 con un periodo di conservazione da 1 a 35 giorni in modo da poter ripristinare rapidamente in qualsiasi momento entro il periodo di conservazione del backup. Amazon DocumentDB acquisisce anche istantanee automatiche dei dati come parte di questo processo di backup continuo. Puoi anche gestire il backup e il ripristino di Amazon DocumentDB
Caratteristiche operative
Utilizza Discovery Tool for Couchbase
Set di dati
Lo strumento recupera le seguenti informazioni sul bucket, sull'ambito e sulla raccolta:
nome bucket
Tipo di bucket
nome dell'ambito
nome della raccolta
dimensione totale (byte)
articoli totali
dimensione dell'articolo (byte)
Indici
Lo strumento recupera le seguenti statistiche sull'indice e tutte le definizioni degli indici per tutti i bucket. Tieni presente che gli indici primari sono esclusi poiché Amazon DocumentDB crea automaticamente un indice primario per ogni raccolta.
nome bucket
nome dell'ambito
nome della raccolta
nome dell'indice
dimensione dell'indice (byte)
Carico di lavoro
Lo strumento recupera le metriche delle K/V query N1QL. K/V i valori delle metriche vengono raccolti a livello di bucket e le metriche SQL++ vengono raccolte a livello di cluster.
Le opzioni della riga di comando dello strumento sono le seguenti:
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
Di seguito è illustrato un esempio di comando:
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
I valori delle metriche K/V si baseranno su campioni effettuati ogni 10 minuti nell'ultima settimana (vedi metodo HTTP e
collection-stats.csv: informazioni sul bucket, sull'ambito e sulla raccolta
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv: nomi e dimensioni degli indici
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv: recupera, imposta ed elimina le metriche per tutti i bucket
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv — SQL++ seleziona, elimina e inserisce le metriche per il cluster
selects,deletes,inserts 0,132,87
indexes- .txt <bucket-name>— definizioni degli indici di tutti gli indici nel bucket. Tieni presente che gli indici primari sono esclusi poiché Amazon DocumentDB crea automaticamente un indice primario per ogni raccolta.
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
Pianificazione
Nella fase di pianificazione, determinerai i requisiti del cluster Amazon DocumentDB e la mappatura dei bucket, degli ambiti e delle raccolte Couchbase ai database e alle raccolte Amazon DocumentDB.
Requisiti del cluster Amazon DocumentDB
Usa i dati raccolti nella fase di scoperta per dimensionare il tuo cluster Amazon DocumentDB. Consulta la sezione Dimensionamento delle istanze per ulteriori informazioni sul dimensionamento del cluster Amazon DocumentDB.
Mappatura di bucket, ambiti e raccolte su database e raccolte
Determina i database e le raccolte che esisteranno nei tuoi cluster Amazon DocumentDB. Considera le seguenti opzioni a seconda di come sono organizzati i dati nel tuo cluster Couchbase. Queste non sono le uniche opzioni, ma forniscono punti di partenza da considerare.
Couchbase Server 6.x o versioni precedenti
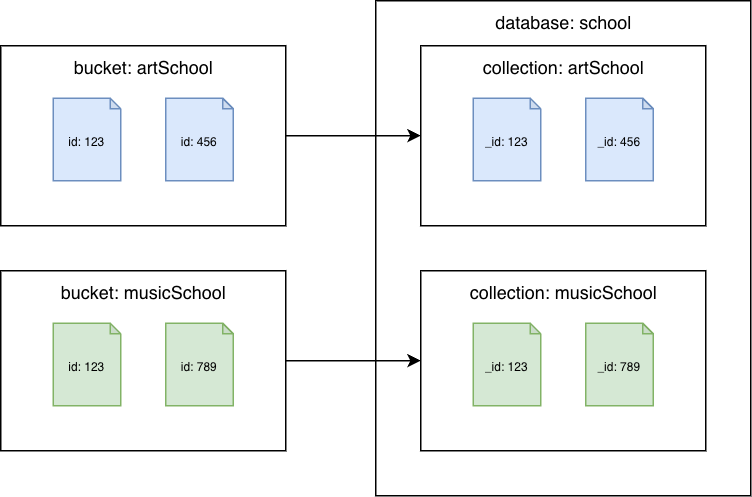
Bucket Couchbase per le raccolte Amazon DocumentDB
Esegui la migrazione di ogni bucket in una raccolta Amazon DocumentDB diversa. In questo scenario, il valore del documento Couchbase verrà utilizzato come id valore Amazon _id DocumentDB.
Couchbase Server 7.0 o versione successiva
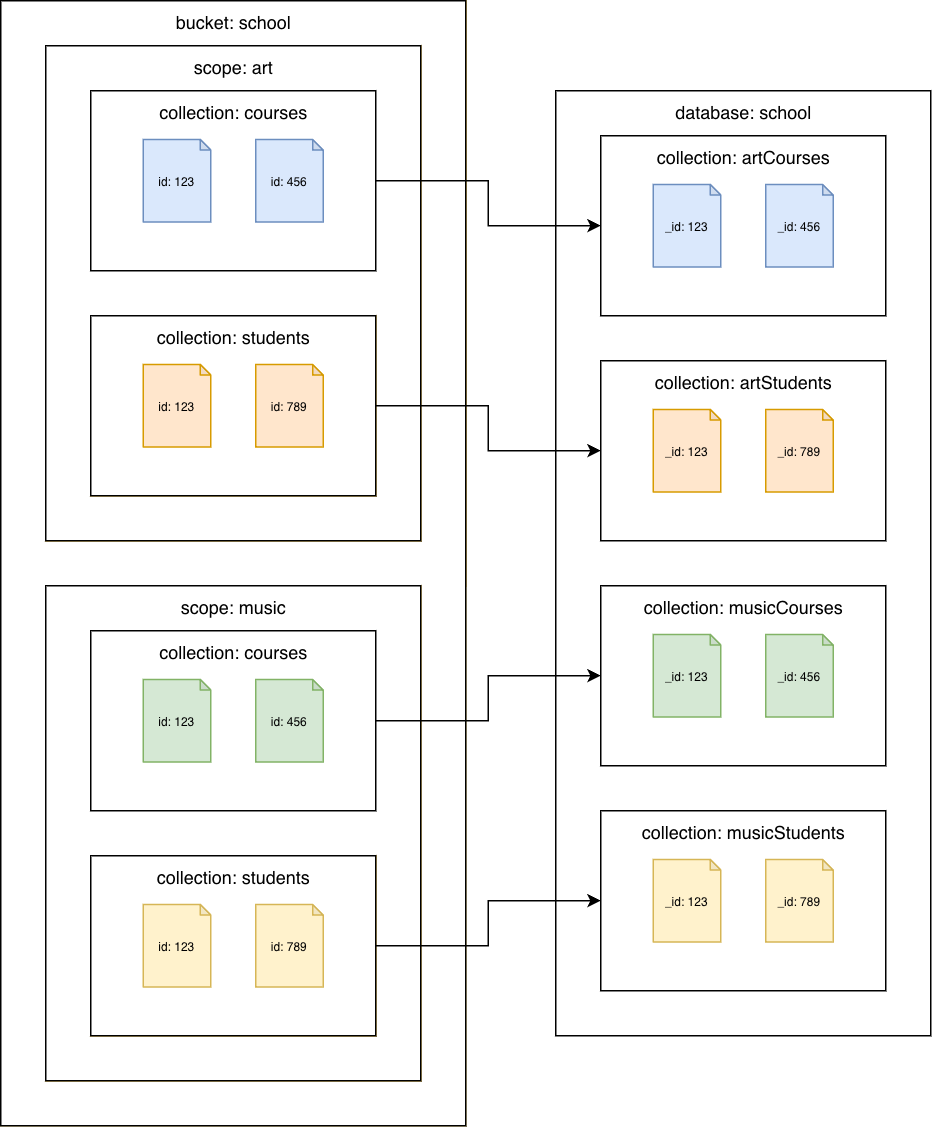
Da raccolte Couchbase a raccolte Amazon DocumentDB
Esegui la migrazione di ogni raccolta in una raccolta Amazon DocumentDB diversa. In questo scenario, il valore del documento Couchbase verrà utilizzato come id valore Amazon _id DocumentDB.
Migrazione
Migrazione degli indici
La migrazione ad Amazon DocumentDB implica il trasferimento non solo di dati ma anche di indici per mantenere le prestazioni delle query e ottimizzare le operazioni del database. Questa sezione descrive il step-by-step processo dettagliato per la migrazione degli indici su Amazon DocumentDB garantendo al contempo compatibilità ed efficienza.
Usa Amazon Q per convertire le CREATE INDEX istruzioni SQL++ in comandi Amazon createIndex() DocumentDB.
Carica i <bucket name>file indexes- .txt creati da Discovery Tool for Couchbase.
Inserisci il seguente prompt:
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q genererà comandi Amazon DocumentDB createIndex() equivalenti. Tieni presente che potrebbe essere necessario aggiornare i nomi delle raccolte in base al modo in cui hai mappato i bucket, gli ambiti e le raccolte di Couchbase alle raccolte Amazon DocumentDB.
Esempio:
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Esempio di output Amazon Q (estratto):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Per gli indici che Amazon Q non è in grado di convertire, consulta la sezione Gestione degli indici e degli indici e delle proprietà degli indici di Amazon DocumentDB per ulteriori informazioni.
Codice di rifattorizzazione per utilizzare MongoDB APIs
I client utilizzano Couchbase per connettersi al Couchbase SDKs Server. I client Amazon DocumentDB utilizzano i driver MongoDB per connettersi ad Amazon DocumentDB. Tutte le lingue supportate da Couchbase SDKs sono supportate anche dai driver MongoDB. Vedi MongoDB Drivers
Poiché APIs sono diversi tra Couchbase Server e Amazon DocumentDB, dovrai rifattorizzare il codice per utilizzare il MongoDB appropriato. APIs Puoi usare Amazon Q per convertire le chiamate K/V API e le query SQL++ nell'equivalente MongoDB: APIs
Carica i file del codice sorgente.
Immettete il seguente prompt:
Convert the Couchbase API code to Amazon DocumentDB API code
Utilizzando l'esempio di codice Python di Hello Couchbase
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Consulta Connessione programmatica ad Amazon DocumentDB per esempi di connessione ad Amazon DocumentDB in Python, Node.js, PHP, Go, Java, C#/.NET, R e Ruby.
Seleziona l'approccio di migrazione
Per la migrazione dei dati su Amazon DocumentDB, sono disponibili due opzioni:
Migrazione offline
Prendi in considerazione una migrazione offline quando:
I tempi di inattività sono accettabili: la migrazione offline comporta l'interruzione delle operazioni di scrittura sul database di origine, l'esportazione dei dati e quindi l'importazione in Amazon DocumentDB. Questo processo comporta tempi di inattività per l'applicazione. Se l'applicazione o il carico di lavoro sono in grado di tollerare questo periodo di indisponibilità, la migrazione offline è un'opzione valida.
Migrazione di set di dati più piccoli o esecuzione di prove concettuali: per set di dati più piccoli, il tempo necessario per il processo di esportazione e importazione è relativamente breve, il che rende la migrazione offline un metodo rapido e semplice. È inoltre ideale per lo sviluppo, i test e gli proof-of-concept ambienti in cui i tempi di inattività sono meno critici.
La semplicità è una priorità: il metodo offline, che utilizza cbexport e mongoimport, è generalmente l'approccio più semplice per la migrazione dei dati. Evita le complessità dell'acquisizione dei dati di modifica (CDC) implicata nei metodi di migrazione online.
Non è necessario replicare alcuna modifica in corso: se il database di origine non riceve attivamente le modifiche durante la migrazione o se tali modifiche non sono fondamentali per essere acquisite e applicate alla destinazione durante il processo di migrazione, è appropriato un approccio offline.
Couchbase Server 6.x o versione precedente
Bucket Couchbase per la raccolta Amazon DocumentDB
Esporta i dati utilizzando cbexport json--formatopzione puoi usare o. lines list
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importa i dati in una raccolta Amazon DocumentDB utilizzando mongoimport con l'opzione appropriata per importare le righe o l'elenco:
linee:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
elenco:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 o versione successiva
Per eseguire una migrazione offline, usa gli strumenti cbexport e mongoimport:
Bucket Couchbase con ambito e raccolta predefiniti
Esporta i dati utilizzando cbexport json--formatopzione puoi usare o. lines list
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
Importa i dati in una raccolta Amazon DocumentDB utilizzando mongoimport con l'opzione appropriata per importare le righe o l'elenco:
linee:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
elenco:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Da raccolte Couchbase a raccolte Amazon DocumentDB
Esporta i dati utilizzando cbexport json--include-dataopzione per esportare ogni raccolta. Per l'--formatopzione puoi usare lines olist. Utilizza le --collection-field opzioni --scope-field e per memorizzare il nome dell'ambito e della raccolta nei campi specificati in ogni documento JSON.
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
Poiché cbexport ha aggiunto i _collection campi _scope and a ogni documento esportato, puoi rimuoverli da ogni documento nel file di esportazione tramite cerca e sostituisci o qualsiasi metodo tu preferisca. sed
Importa i dati per ogni raccolta in una raccolta Amazon DocumentDB utilizzando mongoimport con l'opzione appropriata per importare le righe o l'elenco:
righe:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
elenco:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Migrazione online
Prendi in considerazione una migrazione online quando è necessario ridurre al minimo i tempi di inattività e le modifiche in corso devono essere replicate su Amazon DocumentDB quasi in tempo reale.
Vedi Come eseguire una migrazione live da Couchbase ad Amazon DocumentDB per
Couchbase Server 6.x o versioni precedenti
Bucket Couchbase per la raccolta Amazon DocumentDB
L'utilità di migrazione per Couchbasedocument.id.strategy parametro è configurato per utilizzare il valore della chiave del messaggio come valore del _id campo (vedi Sink Connector Id Strategy Properties):
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 o versione successiva
Bucket Couchbase con ambito e raccolta predefiniti
L'utilità di migrazione per Couchbasedocument.id.strategy parametro è configurato per utilizzare il valore della chiave del messaggio come valore del _id campo (vedi Sink Connector Id Strategy Properties):
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Da raccolte Couchbase a raccolte Amazon DocumentDB
Configura il connettore di origine
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
Configura il connettore sink
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
Convalida
Questa sezione fornisce un processo di convalida dettagliato per verificare la coerenza e l'integrità dei dati dopo la migrazione ad Amazon DocumentDB. Le fasi di convalida si applicano indipendentemente dal metodo di migrazione.
Argomenti
Verifica che tutte le raccolte esistano nella destinazione
Fonte Couchbase
opzione 1: Query Workbench
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
opzione 2: strumento cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Obiettivo Amazon DocumentDB
mongosh (vedi Connect to your Amazon DocumentDB cluster):
db.getSiblingDB('<database>') db.getCollectionNames()
Verifica il numero di documenti tra i cluster di origine e di destinazione
Fonte Couchbase
Couchbase Server 6.x o versione precedente
opzione 1: query workbench
SELECT COUNT(*) FROM `<bucket>`
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 o versione successiva
opzione 1: query workbench
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Obiettivo Amazon DocumentDB
mongosh (vedi Connect to your Amazon DocumentDB cluster):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
Confronta i documenti tra i cluster di origine e di destinazione
Fonte Couchbase
Couchbase Server 6.x o versione precedente
opzione 1: query workbench
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 o versione successiva
opzione 1: query workbench
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Obiettivo Amazon DocumentDB
mongosh (vedi Connect to your Amazon DocumentDB cluster):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
