Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crea un Job ibrido
Questa sezione mostra come creare un Hybrid Job usando uno script Python. In alternativa, per creare un lavoro ibrido da codice Python locale, come il tuo ambiente di sviluppo integrato (IDE) preferito o un notebook Braket, vedi. Esegui il codice locale come lavoro ibrido
In questa sezione:
Crea ed esegui
Una volta ottenuto un ruolo con le autorizzazioni per eseguire un lavoro ibrido, sei pronto per procedere. L'elemento chiave del tuo primo lavoro ibrido con Braket è lo script dell'algoritmo. Definisce l'algoritmo da eseguire e contiene le classiche attività logiche e quantistiche che fanno parte dell'algoritmo. Oltre allo script dell'algoritmo, puoi fornire altri file di dipendenza. Lo script dell'algoritmo, insieme alle sue dipendenze, viene chiamato modulo sorgente. Il punto di ingresso definisce il primo file o funzione da eseguire nel modulo di origine all'avvio del processo ibrido.
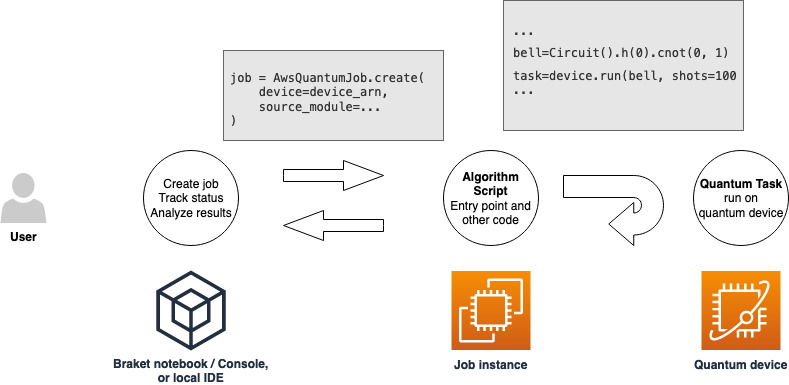
Innanzitutto, consideriamo il seguente esempio di base di uno script di algoritmo che crea cinque stati a campana e stampa i risultati di misurazione corrispondenti.
import os from braket.aws import AwsDevice from braket.circuits import Circuit def start_here(): print("Test job started!") # Use the device declared in the job script device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test job completed!")
Salvate questo file con il nome algorithm_script.py nella directory di lavoro corrente sul notebook Braket o nell'ambiente locale. Il file algorithm_script.py ha start_here() come punto di ingresso pianificato.
Quindi, crea un file Python o un taccuino Python nella stessa directory del file algorithm_script.py. Questo script avvia il processo ibrido e gestisce qualsiasi elaborazione asincrona, come la stampa dello stato o dei risultati chiave che ci interessano. Come minimo, questo script deve specificare lo script di lavoro ibrido e il dispositivo principale.
Nota
Per ulteriori informazioni su come creare un notebook Braket o caricare un file, ad esempio il file algorithm_script.py, nella stessa directory dei notebook, consulta Esegui il tuo primo circuito usando l'SDK Amazon Braket Python
Per questo primo caso di base, scegli come target un simulatore. Indipendentemente dal tipo di dispositivo quantistico scelto come target, un simulatore o un'unità di elaborazione quantistica (QPU) effettiva, il dispositivo specificato device nello script seguente viene utilizzato per pianificare il processo ibrido ed è disponibile per gli script dell'algoritmo come variabile di ambiente. AMZN_BRAKET_DEVICE_ARN
Nota
È possibile utilizzare solo i dispositivi disponibili nel processo ibrido. Regione AWS L'SDK Amazon Braket seleziona automaticamente questa opzione. Regione AWS Ad esempio, un lavoro ibrido in us-east-1 può IonQ utilizzareSV1,, TN1 e dispositiviDM1, ma non dispositivi. Rigetti
Se scegli un computer quantistico anziché un simulatore, Braket pianifica i tuoi lavori ibridi per eseguire tutte le loro attività quantistiche con accesso prioritario.
from braket.aws import AwsQuantumJob from braket.devices import Devices job = AwsQuantumJob.create( Devices.Amazon.SV1, source_module="algorithm_script.py", entry_point="algorithm_script:start_here", wait_until_complete=True )
Il parametro wait_until_complete=True imposta una modalità dettagliata in modo che il lavoro stampi l'output del lavoro effettivo mentre è in esecuzione. Dovreste vedere un output simile a quello dell'esempio seguente.
Initializing Braket Job: arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 Job queue position: 1 Job queue position: 1 Job queue position: 1 .............. . . . Beginning Setup Checking for Additional Requirements Additional Requirements Check Finished Running Code As Process Test job started! Counter({'00': 58, '11': 42}) Counter({'00': 55, '11': 45}) Counter({'11': 51, '00': 49}) Counter({'00': 56, '11': 44}) Counter({'11': 56, '00': 44}) Test job completed! Code Run Finished 2025-09-24 23:13:40,962 sagemaker-training-toolkit INFO Reporting training SUCCESS
Nota
Puoi anche usare il tuo modulo personalizzato con il AwsQuantumJob.create
Monitora i tuoi risultati
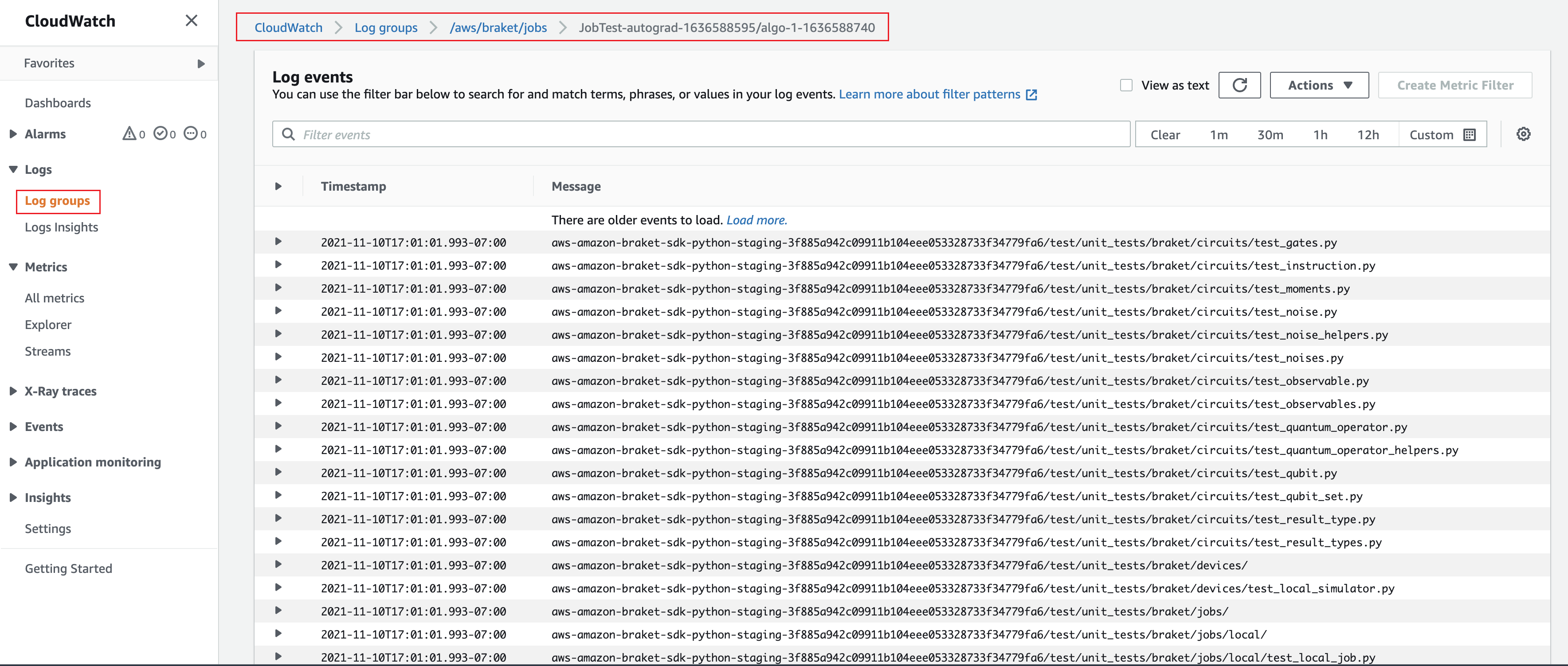
In alternativa, puoi accedere all'output del registro da Amazon CloudWatch. Per fare ciò, vai alla scheda Gruppi di log nel menu a sinistra della pagina dei dettagli del lavoro, seleziona il gruppo di logaws/braket/jobs, quindi scegli il flusso di log che contiene il nome del lavoro. Nell'esempio precedente è braket-job-default-1631915042705/algo-1-1631915190.
Puoi anche visualizzare lo stato del lavoro ibrido nella console selezionando la pagina Hybrid Jobs e quindi scegliendo Impostazioni.
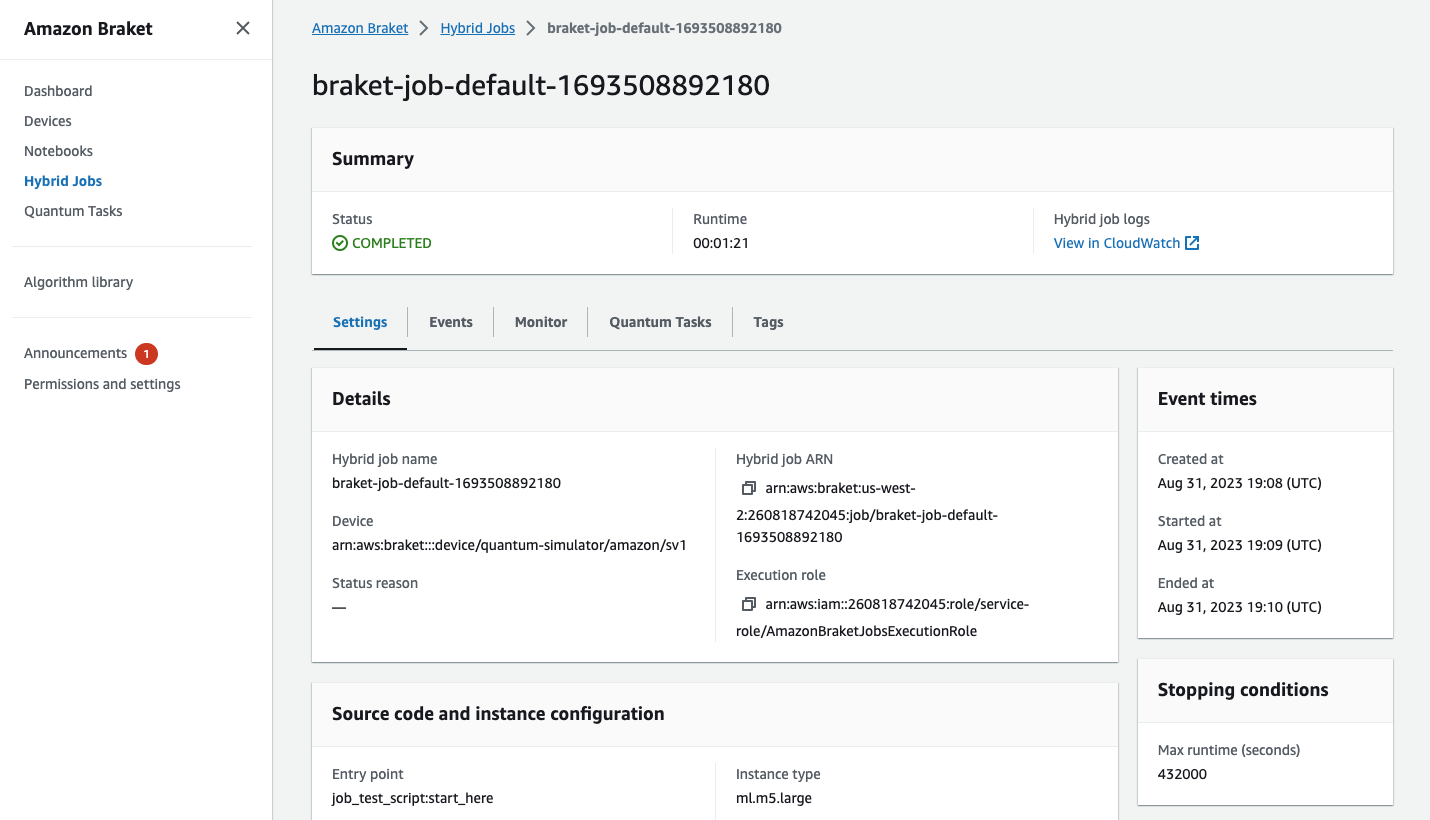
Il tuo lavoro ibrido produce alcuni artefatti in Amazon S3 mentre è in esecuzione. Il nome predefinito del bucket S3 è amazon-braket-<region>-<accountid> e il contenuto si trova nella directory. jobs/<jobname>/<timestamp> Puoi configurare le posizioni S3 in cui vengono archiviati questi artefatti specificandone una diversa code_location quando il lavoro ibrido viene creato con Braket Python SDK.
Nota
Questo bucket S3 deve trovarsi nella stessa posizione del job script. Regione AWS
La jobs/<jobname>/<timestamp> directory contiene una sottocartella con l'output dello script del punto di ingresso in un file. model.tar.gz Esiste anche una directory denominata script che contiene gli elementi dello script dell'algoritmo in un file. source.tar.gz I risultati delle vostre attività quantistiche effettive si trovano nella directory denominata. jobs/<jobname>/tasks
Salva i risultati
È possibile salvare i risultati generati dallo script dell'algoritmo in modo che siano disponibili dall'oggetto di lavoro ibrido nello script del processo ibrido e dalla cartella di output in Amazon S3 (in un file tar-zip denominato model.tar.gz).
L'output deve essere salvato in un file utilizzando un formato JavaScript Object Notation (JSON). Se i dati non possono essere serializzati prontamente in testo, come nel caso di un array numpy, puoi passare un'opzione per serializzare utilizzando un formato di dati selezionato. Vedi il modulo braket.jobs.data_persistence
Per salvare i risultati dei lavori ibridi, aggiungi le seguenti righe commentate con #ADD al file algorithm_script.py.
import os from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_result # ADD def start_here(): print("Test job started!") device = AwsDevice(os.environ['AMZN_BRAKET_DEVICE_ARN']) results = [] # ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) results.append(task.result().measurement_counts) # ADD save_job_result({"measurement_counts": results}) # ADD print("Test job completed!")
È quindi possibile visualizzare i risultati del lavoro dal proprio script di lavoro aggiungendo la riga print(job.result())commentata con #ADD.
import time from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="algorithm_script.py", entry_point="algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", ) print(job.arn) while job.state() not in AwsQuantumJob.TERMINAL_STATES: print(job.state()) time.sleep(10) print(job.state()) print(job.result()) # ADD
In questo esempio, abbiamo rimosso wait_until_complete=True per sopprimere l'output verboso. Puoi aggiungerlo nuovamente per il debug. Quando si esegue questo processo ibrido, vengono emessi l'identificatore e iljob-arn, seguiti dallo stato del lavoro ibrido ogni 10 secondi fino all'arrivo del lavoro ibridoCOMPLETED, dopodiché vengono visualizzati i risultati del circuito a campana. Guarda l'esempio seguente.
arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 INITIALIZED RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING ... RUNNING RUNNING COMPLETED {'measurement_counts': [{'11': 53, '00': 47},..., {'00': 51, '11': 49}]}
Utilizzo dei checkpoint
Puoi salvare iterazioni intermedie dei tuoi lavori ibridi utilizzando i checkpoint. Nell'esempio di script di algoritmo della sezione precedente, dovresti aggiungere le seguenti righe commentate con #ADD per creare file di checkpoint.
from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_checkpoint # ADD import os def start_here(): print("Test job starts!") device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) # ADD the following code job_name = os.environ["AMZN_BRAKET_JOB_NAME"] save_job_checkpoint(checkpoint_data={"data": f"data for checkpoint from {job_name}"}, checkpoint_file_suffix="checkpoint-1") # End of ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test hybrid job completed!")
Quando si esegue il job ibrido, viene creato il file -checkpoint-1.json <jobname>negli artefatti del job ibrido nella directory checkpoints con un percorso predefinito. /opt/jobs/checkpoints Lo script di lavoro ibrido rimane invariato a meno che non si desideri modificare questo percorso predefinito.
Se si desidera caricare un lavoro ibrido da un checkpoint generato da un precedente lavoro ibrido, lo script dell'algoritmo utilizza. from braket.jobs import load_job_checkpoint La logica da caricare nello script dell'algoritmo è la seguente.
from braket.jobs import load_job_checkpoint checkpoint_1 = load_job_checkpoint( "previous_job_name", checkpoint_file_suffix="checkpoint-1", )
Dopo aver caricato questo checkpoint, puoi continuare la logica in base al contenuto caricato su. checkpoint-1
Nota
Il checkpoint_file_suffix deve corrispondere al suffisso precedentemente specificato durante la creazione del checkpoint.
Lo script di orchestrazione deve specificare il precedente lavoro ibrido con la riga commentata con job-arn #ADD.
from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="source_dir", entry_point="source_dir.algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", copy_checkpoints_from_job="<previous-job-ARN>", #ADD )
