Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Aggiungere nuove entità di vocabolario
Puoi aggiungere un vocabolario alla tua libreria utilizzando l'API. InvokeDataAutomationLibraryIngestionJob Puoi fornire il vocabolario tramite un file manifest S3 o un payload in linea.
Importante
Le operazioni UPSERT utilizzano un metodo sostitutivo in stile clobber a livello di entità, il che significa che l'intera entità viene sostituita anziché unita al contenuto esistente.
Opzione 1: utilizzo del file manifesto S3
Passaggio 1: creare un file manifest JSONL
Ad esempio: vocabulary-manifest.json
{"entityId":"medical-en","description":"Medication terms in English language","phrases":[{"text":"paracetamol"},{"text":"ibuprofen"},{"text":"acetaminophen","displayAsText":"acetaminophen"}],"language":"EN"} {"entityId":"medical-es","description":"Medication terms in Spanish language","phrases":[{"text":"paracetamol"},{"text":"ibuprofen"},{"text":"acetaminophen","displayAsText":"acetaminophen"}],"language":"ES"}
Requisiti del file manifesto:
Formato di file: JSONL (linee JSON)
-
Entità JSON:
EntityID (richiesto): identificatore univoco (max 128 caratteri)
descrizione (opzionale): descrizione dell'EntityID
lingua (richiesta): codice della lingua ISO (lingue supportate)
-
frasi (richiesto): matrice di oggetti di testo. Ogni oggetto contiene:
testo (richiesto): singola parola o frase
displayAsText(opzionale): Utilizzatelo per sostituire la parola effettiva nella trascrizione (NOTA: distinzione tra maiuscole e minuscole)
Passaggio 2: carica il manifesto su S3
aws s3 cp vocabulary-manifest.json s3://my-bucket/manifests/
Fase 3: Avviare il processo di ingestione
Usa il InvokeDataAutomationLibraryIngestionJobper iniziare un lavoro di ingestione del vocabolario.
Esempio di CLI AWS:
Richiesta
aws bedrock-data-automation-data-automation invoke-data-automation-library-ingestion-job \ --library-arn "arn:aws:bedrock:us-east-1:123456789012:data-automation-library/healthcare-vocabulary" \ --entity-type "VOCABULARY" \ --operation-type "UPSERT" \ --input-configuration '{"s3Object":{"s3Uri":"s3://my-bucket/manifests/vocabulary-manifest.json"}}' \ --output-configuration '{"s3Uri":"s3://my-bucket/outputs/"}'
Risposta:
{ "jobArn": "arn:aws:bedrock:us-east-1:123456789012:data-automation-library-ingestion-job/job-12345" }
Esempio di console AWS:
Vai alla pagina «Dettagli della libreria»
Scegli «Aggiungi un elenco di vocaboli personalizzato»
Scegli «Carica/seleziona manifesto»
Scegli se caricare il file manifest direttamente o da una posizione S3

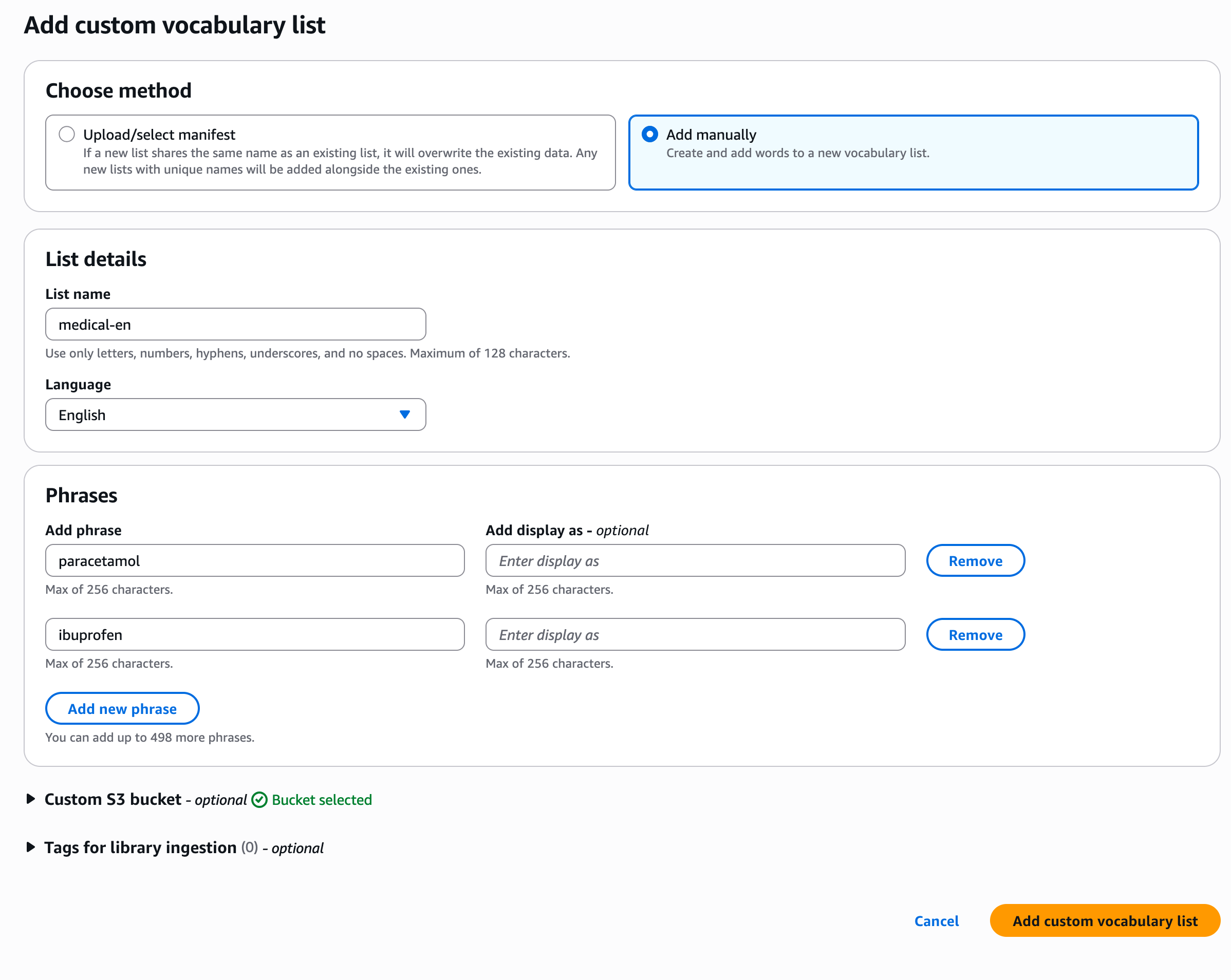
Opzione 2: utilizzo del payload in linea
Questa opzione può essere utilizzata per aggiornamenti rapidi con un massimo di 100 frasi.
Usa il InvokeDataAutomationLibraryIngestionJobper iniziare un lavoro di inserimento del vocabolario.
Esempio di CLI AWS:
Richiesta
aws bedrock-data-automation-data-automation invoke-data-automation-library-ingestion-job \ --library-arn "arn:aws:bedrock:us-east-1:123456789012:data-automation-library/healthcare-vocabulary" \ --entity-type "VOCABULARY" \ --operation-type "UPSERT" \ --input-configuration '{"inlinePayload":{"upsertEntitiesInfo":[{"vocabulary":{"entityId":"medical-en","language":"EN","phrases":[{"text":"paracetamol"},{"text":"ibuprofen"}]}}]}}' \ --output-configuration '{"s3Uri":"s3://bda-data-bucket/output/"}'
Risposta:
{ "jobArn": "arn:aws:bedrock:us-east-1:123456789012:data-automation-library-ingestion-job/job-12345" }
Esempio di console AWS:
Vai alla pagina «Dettagli della libreria»
Scegli «Aggiungi un elenco di vocaboli personalizzato»
Scegli «Aggiungi manualmente»