Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Caricamento di file per la prima volta
È possibile utilizzare la funzione di AWS Supply Chain associazione automatica per caricare i dati grezzi e associare automaticamente i dati grezzi al modello di AWS Supply Chain dati. È inoltre possibile visualizzare le colonne e le tabelle richieste per ogni AWS Supply Chain modulo all'interno dell'applicazione AWS Supply Chain web.
Per una breve dimostrazione di come funziona l'associazione automatica, guarda il seguente video:
Nota
Puoi caricare file CSV su Amazon S3 solo quando utilizzi l'associazione automatica.
Dopo aver associato le colonne di origine del set di dati alle colonne di destinazione, AWS Supply Chain genererà automaticamente la ricetta SQL.
Nota
AWS Supply Chain utilizza Amazon Bedrock for Auto-association, che non è supportato in tutte le AWS regioni & in cui AWS Supply Chain è disponibile. Pertanto, AWS Supply Chain chiamerà l'endpoint Amazon Bedrock dalla regione disponibile più vicina, la regione Europa (Irlanda) — Europa (Francoforte) e la regione Asia Pacifico (Sydney) — Stati Uniti occidentali (Oregon).
Nota
L'associazione automatica tramite Large Language Models (LLM) è supportata solo quando i dati vengono importati tramite Amazon S3.
-
Nella AWS Supply Chain dashboard, nel riquadro di navigazione a sinistra, scegli Data Lake, quindi scegli la scheda Data Ingestion.
Viene visualizzata la pagina Data Ingestion.
Scegli Aggiungi nuova fonte.
Viene visualizzata la pagina Seleziona la tua fonte di dati.
Nella pagina Seleziona la tua fonte di dati, scegli Carica file.
Scegli Continua.
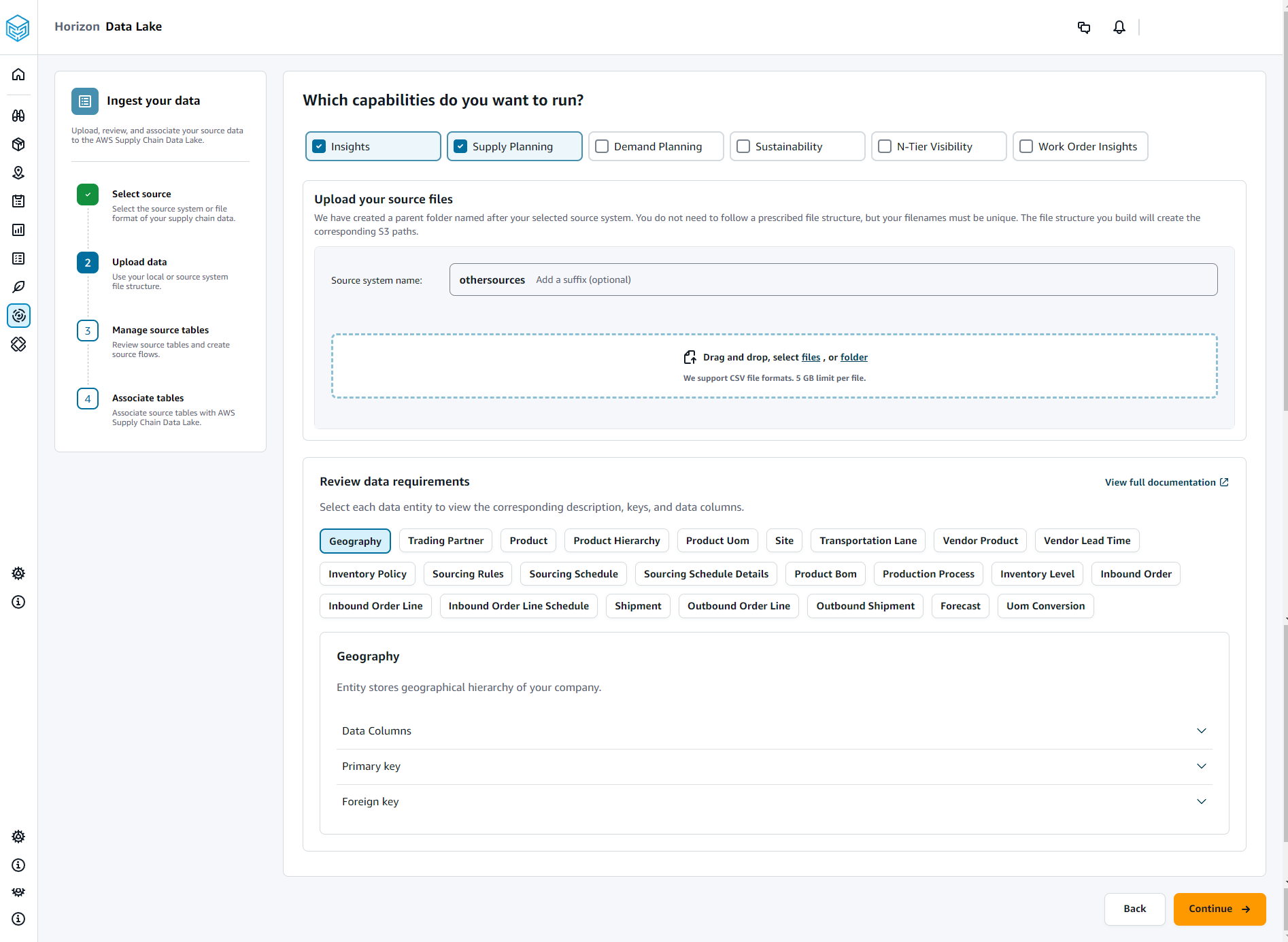
Nella pagina Quali funzionalità desideri eseguire, scegli i AWS Supply Chain moduli che desideri utilizzare. Puoi scegliere più di un modulo.
Nella sezione Carica i tuoi file sorgente, aggiungi un suffisso al nome del sistema di origine. Ad esempio, oracle_test.
Per caricare il set di dati di origine, scegli i file o trascina i file.
Vengono visualizzate le tabelle di origine con il nome e lo stato.
Scegli Carica su S3. Lo stato di caricamento cambierà per visualizzare lo stato.
In Rivedi i requisiti dei dati, esamina tutte le entità di dati e le colonne richieste per la AWS Supply Chain funzionalità selezionata. Vengono visualizzate tutte le chiavi primarie ed esterne richieste.
Scegli Continua.
In Gestisci le tue tabelle di origine, le seguenti tabelle di origine e le colonne elencate verranno associate automaticamente e importate nel data lake.
Scegli Elimina tabella per eliminare una qualsiasi delle tabelle di origine prima dell'importazione nel data lake.
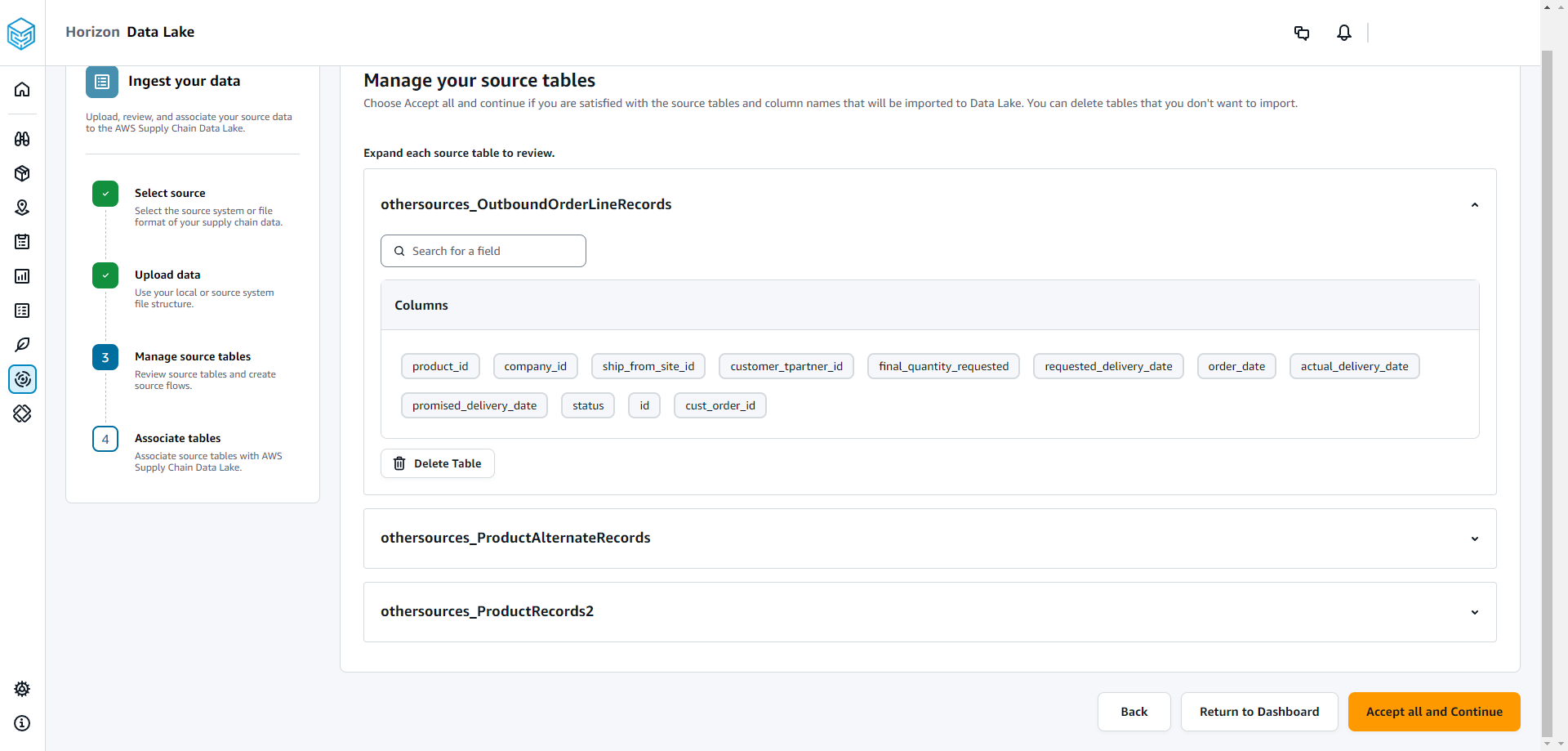
Scegli Accetta tutto e continua.
Viene visualizzato un messaggio sull'associazione automatica delle tabelle al AWS Supply Chain data lake.
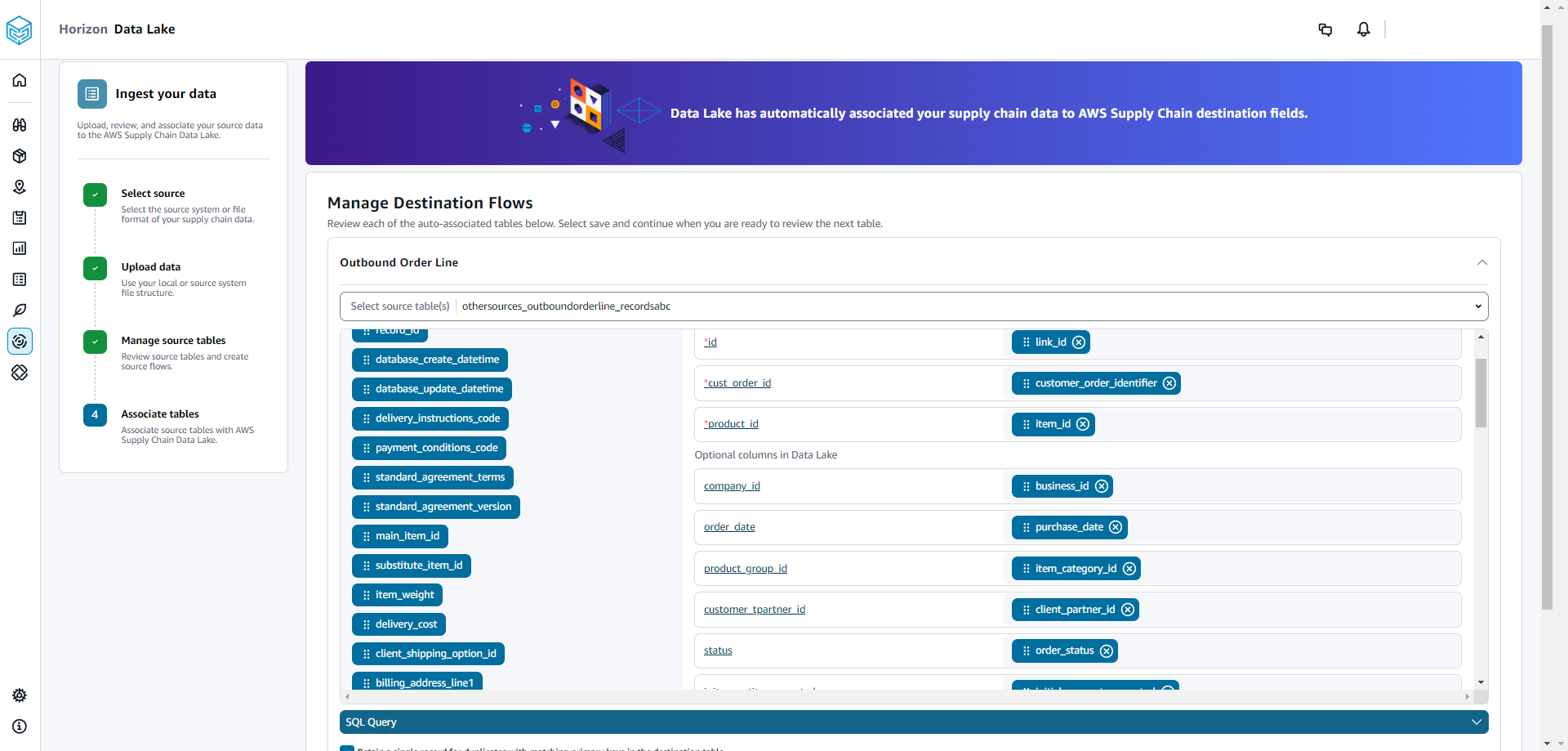
In Gestisci flussi di destinazione, puoi esaminare ogni tabella associata automaticamente.
Per impostazione predefinita, l'associazione automatica è abilitata e le colonne di origine vengono associate automaticamente alle colonne di destinazione. Per aggiornare le colonne associate automaticamente, puoi aggiornare la ricetta SQL per creare la tua ricetta personalizzata.
In Colonne di origine, sono elencate tutte le colonne di origine non associate. Trascina e rilascia le colonne non associate nelle colonne di destinazione a destra.
Segui il passaggio precedente per ogni tabella associata automaticamente.
Scegli Invia.
Scegli Esci e rivedi i flussi di destinazione.
