Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Integrazione di DynamoDB con Streaming gestito da Amazon per Apache Kafka
Streaming gestito da Amazon per Apache Kafka (Amazon MSK) semplifica l’acquisizione e l’elaborazione dei dati in streaming in tempo reale con un servizio completamente gestito per Apache Kafka e ad alta disponibilità.
Apache Kafka
Grazie a queste funzionalità, Apache Kafka viene spesso utilizzato per creare pipeline di dati in streaming in tempo reale. Una pipeline di dati elabora e sposta i dati in modo affidabile da un sistema all’altro e può essere una parte importante dell’adozione di una strategia di database dedicati, facilitando l’uso di più database, ciascuno dei quali supporta casi d’uso diversi.
Amazon DynamoDB è l’obiettivo comune di queste pipeline di dati per supportare applicazioni che utilizzano modelli di dati chiave-valore o documentali e desiderano una scalabilità illimitata con prestazioni costanti con risposte in pochi millisecondi.
Come funziona
Un’integrazione tra Amazon MSK e DynamoDB utilizza una funzione Lambda per utilizzare i record da Amazon MSK e scriverli su DynamoDB.
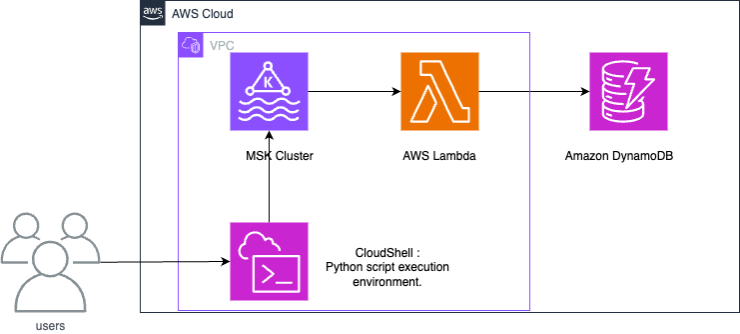
Lambda esegue internamente il polling di nuovi messaggi da Amazon MSK, quindi invoca in modo sincrono la funzione Lambda di destinazione. Il payload degli eventi della funzione Lambda contiene batch di messaggi da Amazon MSK. Per l’integrazione tra Amazon MSK e DynamoDB, la funzione Lambda scrive questi messaggi su DynamoDB.
Configurazione di un’integrazione tra Amazon MSK e DynamoDB
Nota
È possibile scaricare le risorse utilizzate in questo esempio nel seguente GitHub repository
La procedura seguente mostra come configurare un esempio di integrazione tra Amazon MSK e Amazon DynamoDB. L’esempio rappresenta i dati generati da dispositivi Internet delle cose (IoT) e inseriti in Amazon MSK. Man mano che i dati vengono inseriti in Amazon MSK, possono essere integrati con servizi di analisi o strumenti di terze parti compatibili con Apache Kafka, rendendo possibili vari casi d’uso di analisi. L’integrazione di DynamoDB fornisce anche la ricerca dei valori delle chiavi dei record dei singoli dispositivi.
Questo esempio dimostrerà come uno script Python scrive i dati di sensori IoT su Amazon MSK. Quindi, una funzione Lambda scrive elementi con la chiave di partizione “deviceid” in DynamoDB.
Il CloudFormation modello fornito creerà le seguenti risorse: un bucket Amazon S3, un Amazon VPC, un cluster Amazon MSK e AWS CloudShell uno per testare le operazioni sui dati.
Per generare dati di test, crea un argomento Amazon MSK e quindi crea una tabella DynamoDB. È possibile utilizzare Session Manager dalla console di gestione per accedere al CloudShell sistema operativo ed eseguire script Python.
Dopo aver eseguito il CloudFormation modello, puoi completare la creazione di questa architettura eseguendo le seguenti operazioni.
-
Esegui il CloudFormation modello
S3bucket.yamlper creare un bucket S3. Esegui eventuali script o operazioni successive nella stessa Regione. InserisciForMSKTestS3come nome dello CloudFormation stack.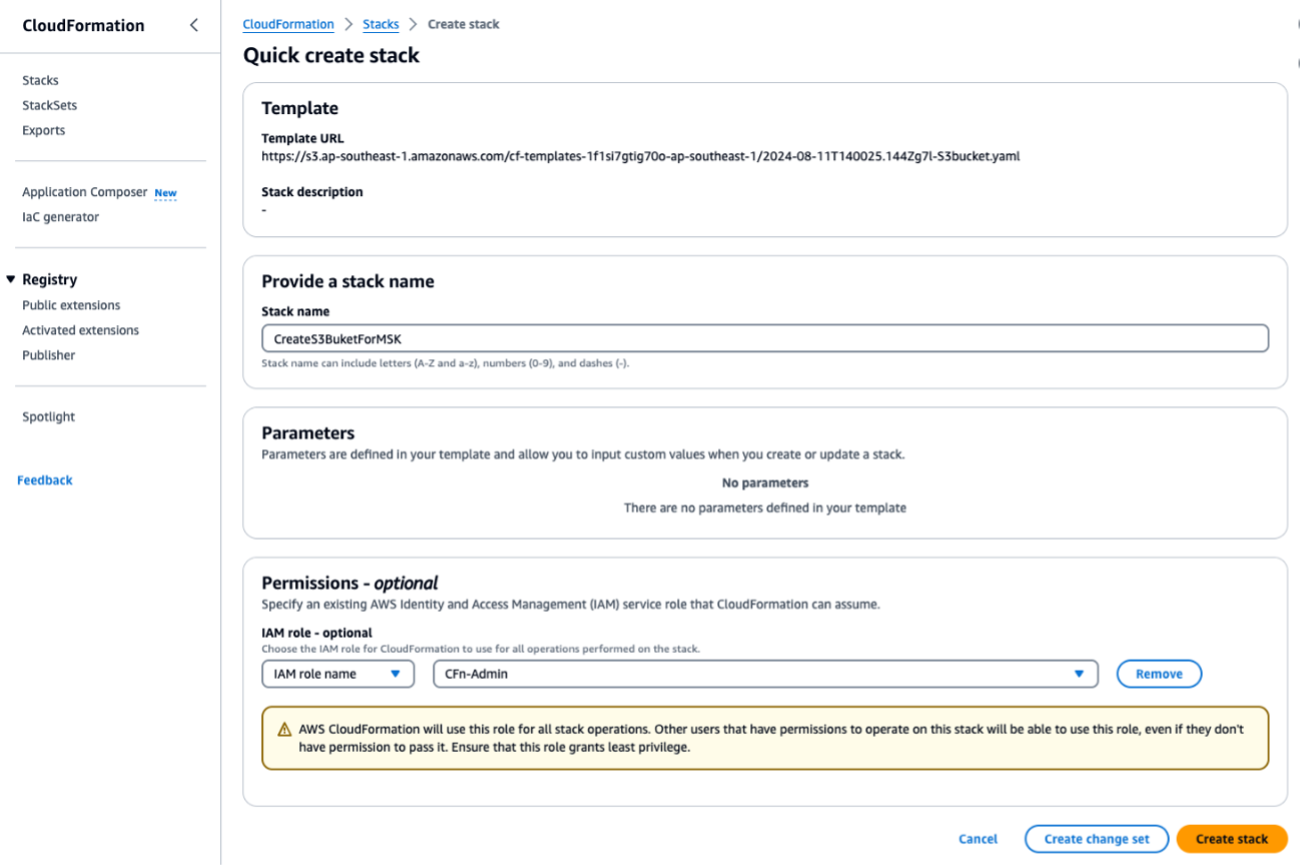
Al termine, annota il nome del bucket S3 in uscita nella sezione Output. Ne avrai bisogno nella Fase 3.
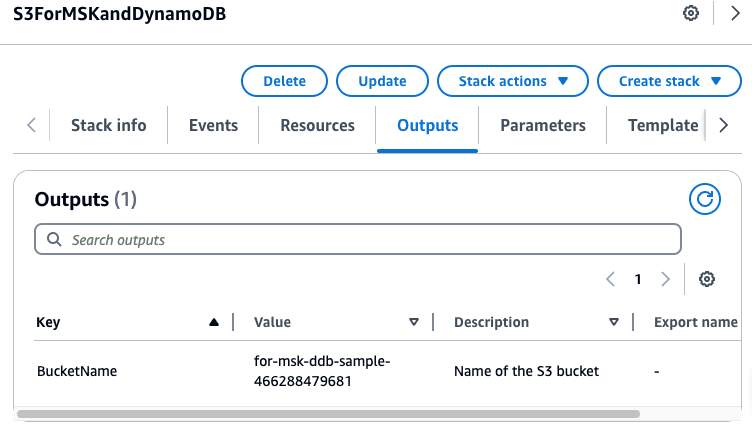
-
Carica il file ZIP
fromMSK.zipscaricato nel bucket S3 appena creato.
-
Esegui il CloudFormation modello
VPC.yamlper creare un VPC, un cluster Amazon MSK e una funzione Lambda. Nella schermata di immissione dei parametri, inserisci il nome del bucket S3 creato nella Fase 1, in cui viene richiesto il bucket S3. Imposta il nome dello CloudFormation stack su.ForMSKTestVPC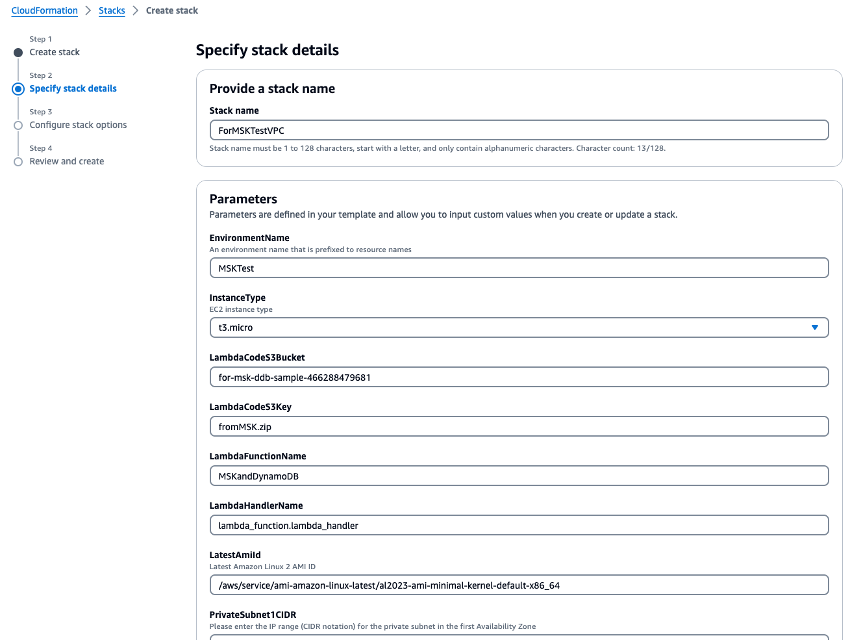
-
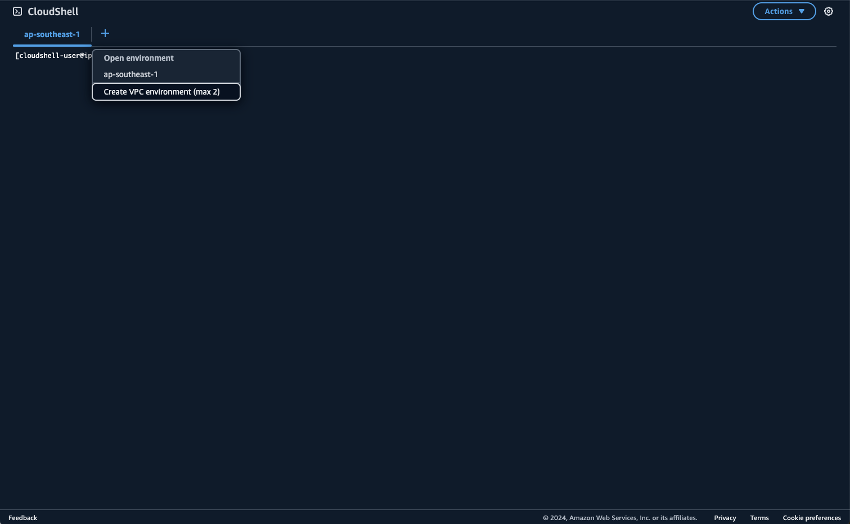
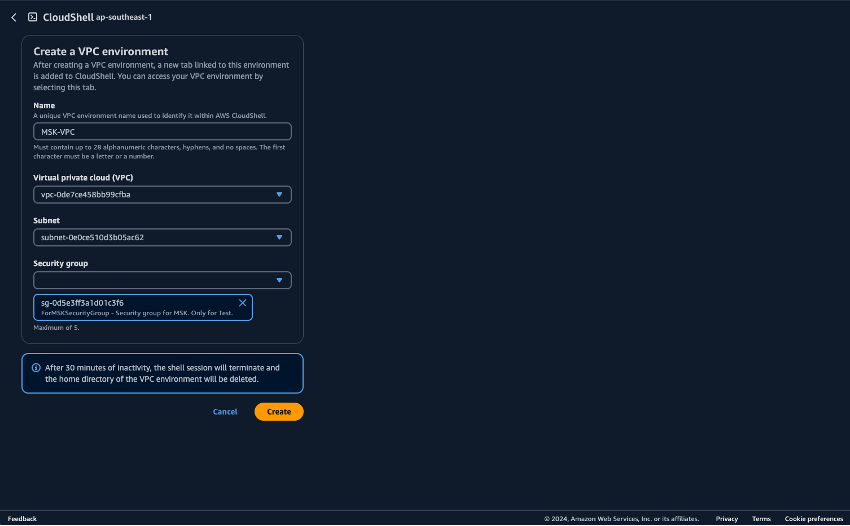
Prepara l'ambiente per l'esecuzione degli script Python. CloudShell È possibile utilizzare CloudShell su. Console di gestione AWS Per ulteriori informazioni sull'utilizzo CloudShell, vedere Guida introduttiva a AWS CloudShell. Dopo l'avvio CloudShell, crea un file CloudShell che appartenga al VPC appena creato per connetterti al cluster Amazon MSK. Crealo CloudShell in una sottorete privata. Riempi i seguenti campi:
-
Nome: può essere impostato su qualsiasi nome. Un esempio è MSK-VPC
-
VPC: seleziona MSKTest
-
Sottorete: seleziona Sottorete privata MSKTest (AZ1)
-
SecurityGroup- seleziona ForMSKSecurityGroup
Una volta avviata l' CloudShell appartenenza alla sottorete privata, esegui il seguente comando:
pip install boto3 kafka-python aws-msk-iam-sasl-signer-python -
-
Scarica gli script Python dal bucket S3.
aws s3 cp s3://[YOUR-BUCKET-NAME]/pythonScripts.zip ./ unzip pythonScripts.zip -
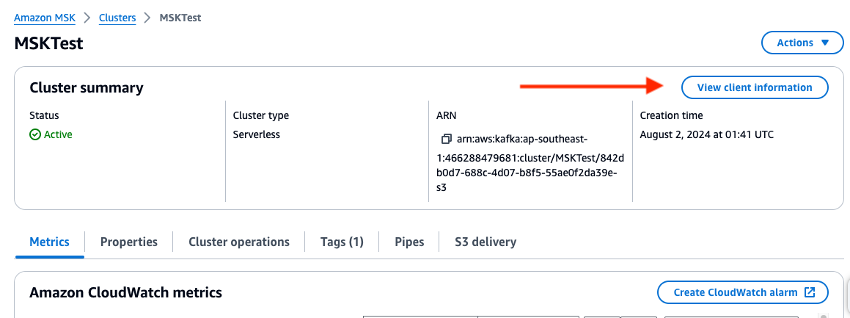
Controlla la console di gestione e imposta le variabili di ambiente per l’URL del broker e il valore della Regione negli script Python. Controlla l’endpoint del broker del cluster Amazon MSK nella console di gestione.
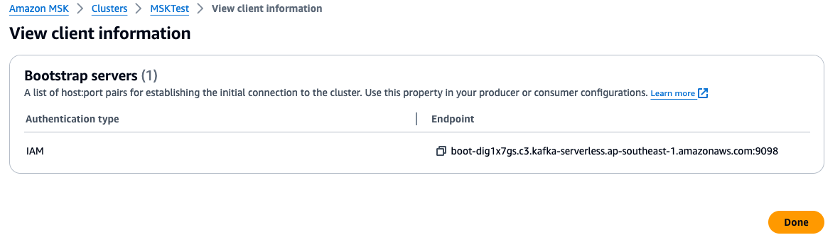
-
Imposta le variabili di ambiente su. CloudShell Se utilizzi la Regione Stati Uniti occidentali (Oregon):
export AWS_REGION="us-west-2" export MSK_BROKER="boot-YOURMSKCLUSTER.c3.kafka-serverless.ap-southeast-1.amazonaws.com:9098" -
Esegui i seguenti script Python.
Crea un argomento Amazon MSK:
python ./createTopic.pyCrea una tabella DynamoDB:
python ./createTable.pyScrivi i dati di test nell’argomento Amazon MSK:
python ./kafkaDataGen.py -
Controlla i CloudWatch parametri per le risorse Amazon MSK, Lambda e DynamoDB create e verifica i dati archiviati nella tabella
device_statusutilizzando DynamoDB Data Explorer per garantire che tutti i processi funzionino correttamente. Se ogni processo viene eseguito senza errori, puoi verificare che i dati di test scritti da Amazon MSK CloudShell vengano scritti anche su DynamoDB.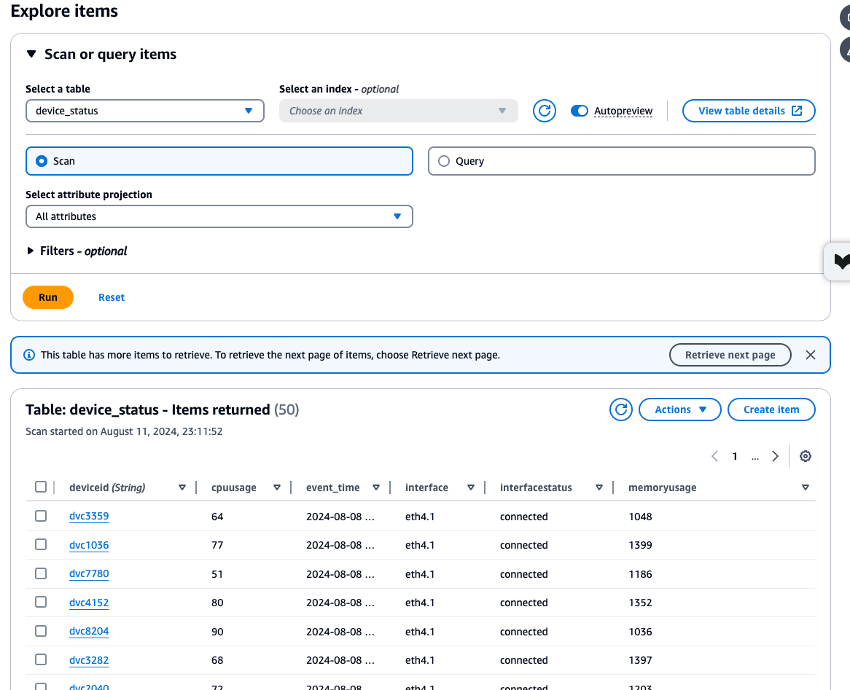
-
Al termine, elimina le risorse create in questo tutorial. Elimina i due CloudFormation stack: e.
ForMSKTestS3ForMSKTestVPCSe l’eliminazione dello stack viene completata correttamente, tutte le risorse verranno eliminate.
Fasi successive
Nota
Se hai creato risorse seguendo questo esempio, ricordati di eliminarle per evitare addebiti imprevisti.
L’integrazione ha identificato un’architettura che collega Amazon MSK e DynamoDB per consentire il supporto dei carichi di lavoro OLTP da parte dei dati di flusso. Da qui, è possibile realizzare ricerche più complesse collegando DynamoDB a Service. OpenSearch Prendi in considerazione l'integrazione con, EventBridge per esigenze più complesse basate sugli eventi, ed estensioni come Amazon Managed Service per Apache Flink per un throughput più elevato e requisiti di latenza inferiori.
