Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione da un database relazionale a DynamoDB
La migrazione di un database relazionale in DynamoDB richiede un’attenta pianificazione per garantire un esito positivo. Questa guida è utile per comprendere come funziona questo processo, quali sono gli strumenti a disposizione e come valutare quindi le potenziali strategie di migrazione e selezionarne una più adatta alle proprie esigenze.
Argomenti
Considerazioni sulle tempistiche di migrazione di un database relazionale a DynamoDB
Scelta della strategia appropriata per la migrazione a DynamoDB
Esecuzione di una migrazione online a DynamoDB migrando ogni tabella 1:1
Esecuzione di una migrazione online a DynamoDB con una tabella di staging personalizzata
Motivi per migrare a DynamoDB
La migrazione ad Amazon DynamoDB offre una serie di vantaggi interessanti per aziende e organizzazioni. Ecco alcuni vantaggi chiave che rendono DynamoDB una scelta interessante per la migrazione dei database:
-
Scalabilità: DynamoDB è progettato per gestire carichi di lavoro enormi e scalare in modo fluido per adattarsi a volumi e traffico di dati in crescita. Con DynamoDB, è possibile aumentare o ridurre verticalmente un database in base alla richiesta in modo semplice, assicurando che le applicazioni siano in grado di gestire picchi improvvisi di traffico senza compromettere le prestazioni.
-
Prestazioni: DynamoDB offre un accesso ai dati a bassa latenza, permettendo alle applicazioni di recuperare ed elaborare i dati con una velocità eccezionale. La sua architettura distribuita garantisce che le operazioni di lettura e scrittura siano distribuite su più nodi, offrendo tempi di risposta coerenti con risposte in pochi millisecondi anche a frequenze di richieste elevate.
-
Completamente gestito: DynamoDB è un servizio completamente gestito fornito da AWS. Ciò significa che AWS gestisce gli aspetti operativi della gestione del database, tra cui il provisioning, la configurazione, l'applicazione di patch, i backup e la scalabilità. Ciò consente di concentrarsi maggiormente sullo sviluppo delle applicazioni e meno sulle attività di amministrazione del database.
-
Architettura serverless: DynamoDB supporta un modello serverless, noto come DynamoDB on demand, in cui il pagamento avviene solo per le effettive richieste di lettura e scrittura effettuate dall’applicazione senza richiedere il provisioning anticipato della capacità. Questo pay-per-request modello offre efficienza in termini di costi e spese operative minime, in quanto si pagano solo le risorse utilizzate senza la necessità di fornire e monitorare la capacità.
-
Flessibilità NoSQL: a differenza dei database relazionali tradizionali, DynamoDB segue un modello di dati NoSQL, che offre flessibilità nella progettazione dello schema. Con DynamoDB, è possibile archiviare dati strutturati, semistrutturati e non strutturati, rendendoli ideali per la gestione di tipi di dati diversi e in evoluzione. Questa flessibilità consente cicli di sviluppo più rapidi e un adattamento più semplice alle mutevoli esigenze aziendali.
-
Disponibilità e durabilità elevate: DynamoDB replica i dati su più zone di disponibilità all’interno di una Regione, garantendo elevata disponibilità e durabilità dei dati. Gestisce automaticamente la replica, il failover e il recupero, riducendo al minimo il rischio di perdita dei dati o interruzioni del servizio. DynamoDB offre un accordo sul livello di servizio (SLA) di disponibilità fino al 99,999%.
-
Sicurezza e conformità: DynamoDB si integra con AWS Identity and Access Management per il controllo granulare degli accessi. Fornisce la crittografia dei dati a riposo e in transito, garantendo la sicurezza dei dati. DynamoDB aderisce inoltre a vari standard di conformità, tra cui HIPAA, PCI DSS e GDPR, che consentono di soddisfare i requisiti normativi.
-
Integrazione con l' AWS ecosistema: come parte dell' AWS ecosistema, DynamoDB si integra perfettamente con AWS altri servizi, come, e. AWS Lambda CloudFormation AWS AppSync Questa integrazione consente di creare architetture serverless, sfruttare l’infrastruttura come codice e creare applicazioni basate sui dati in tempo reale.
Considerazioni sulle tempistiche di migrazione di un database relazionale a DynamoDB
I sistemi di gestione dei database relazionali e i database NoSQL hanno diversi vantaggi e svantaggi. Queste differenze rendono la progettazione del database diversa tra i due sistemi.
| Tipo di attività | Database relazionale | Database NoSQL |
|---|---|---|
| Esecuzione di query sul database | Nei database relazionali è possibile eseguire query sui dati in modo flessibile, ma le query sono relativamente costose e non scalano bene in situazioni di traffico elevato (consulta Fase iniziale per la modellazione dei dati relazionali in DynamoDB). Un’applicazione di database relazionale può implementare la logica aziendale nelle stored procedure, nelle sottoquery SQL, nelle query di aggiornamento in blocco e nelle query di aggregazione. | In un database NoSQL come DynamoDB, le query possono essere eseguite in modo efficiente in un numero limitato di modi, al di fuori dei quali possono essere costose e lente. Le scritture su DynamoDB sono singleton. La logica di business dell'applicazione che in precedenza veniva eseguita nelle stored procedure deve essere rifattorizzata per essere eseguita all'esterno di DynamoDB in codice personalizzato eseguito su un host come Amazon Amazon EC2 o. AWS Lambda |
| Progettazione del database | La progettazione viene effettuata tenendo a mente la flessibilità senza doversi preoccupare dei dettagli dell’implementazione o delle prestazioni. L'ottimizzazione delle query in genere non ha ripercussioni sulla progettazione dello schema, ma la normalizzazione è importante. | Lo schema viene progettato in maniera specifica per fare in modo che le query più comuni e importanti siano il più possibile veloci e non costose. Le tue strutture di dati sono programmate per i requisiti specifici dei casi d'uso del tuo business. |
La progettazione per un database NoSQL richiede una mentalità diversa rispetto alla progettazione per un sistema di gestione di database relazionali (RDBMS, Relational Database Management System). Per un sistema RDBMS puoi creare un modello di dati normalizzati senza pensare ai modelli di accesso. Puoi estenderlo in seguito quando si presentano nuovi quesiti e requisiti di query. Puoi organizzare ogni tipo di dati nella sua tabella.
Con la progettazione NoSQL è possibile progettare lo schema per DynamoDB quando si è a conoscenza delle domande alle quali si deve rispondere. È essenziale capire da subito i problemi di business e i modelli di lettura e scrittura dell’applicazione. In un’applicazione DynamoDB è inoltre necessario cercare di mantenere il minor numero possibile di tabelle. Un numero inferiore di tabelle rende le cose più scalabili, richiede una minore gestione delle autorizzazioni e riduce il sovraccarico dell'applicazione DynamoDB. Può anche aiutare a mantenere i costi di backup complessivi più bassi.
L’attività di modellare i dati relazionali per DynamoDB e creare una nuova versione dell’applicazione front-end costituisce un argomento a parte. Questa guida presuppone la disponibilità della nuova versione dell’applicazione creata per utilizzare DynamoDB, ma è comunque necessario determinare il modo migliore per migrare e sincronizzare i dati storici durante la conversione.
Considerazioni sul dimensionamento
La dimensione massima di ogni elemento (riga) che viene archiviato in una tabella DynamoDB è 400 KB. Per ulteriori informazioni, consulta Quote in Amazon DynamoDB. La dimensione dell’elemento è determinata dalla dimensione totale di tutti i nomi e i valori degli attributi in un elemento. Per ulteriori informazioni, consulta Dimensioni e formati degli elementi di DynamoDB.
Se l’applicazione ha bisogno di archiviare più dati in un elemento rispetto al limite di dimensione consentito da DynamoDB, suddividi l’elemento in una raccolta di elementi, comprimi i dati dell’elemento o archivia l’elemento come un oggetto in Amazon Simple Storage Service (Amazon S3) archiviando l’identificatore dell’oggetto Amazon S3 nell’elemento DynamoDB. Per informazioni, consulta Best practice per l’archiviazione di elementi e attributi di grandi dimensioni in DynamoDB. Il costo dell’aggiornamento di un elemento si basa sulla dimensione completa dell’elemento. Per i carichi di lavoro che richiedono aggiornamenti frequenti degli elementi esistenti, l’aggiornamento di elementi di piccole dimensioni di uno o due KB avrà un costo inferiore rispetto agli elementi più grandi. Per ulteriori informazioni sulle raccolte di elementi, consulta Raccolte di articoli: come modellare one-to-many le relazioni in DynamoDB.
Per la scelta degli attributi delle chiavi di partizione e ordinamento, le altre impostazioni della tabella, la dimensione e la struttura degli elementi e se creare indici secondari, assicurati di consultare la documentazione DynamoDB Modeling documentation e la guida per Ottimizzazione dei costi sulle tabelle DynamoDB. Testa il piano di migrazione in modo che la tua soluzione DynamoDB sia efficiente in termini di costi e si adatti alle funzionalità e ai limiti di DynamoDB.
Come funziona una migrazione a DynamoDB
Prima di esaminare gli strumenti di migrazione a disposizione, considera come le scritture vengono elaborate da DynamoDB.
L’operazione di scrittura predefinita e più comune è una singola operazione API PutItem. È possibile eseguire un’operazione PutItem in un ciclo per elaborare set di dati. DynamoDB supporta connessioni simultanee praticamente illimitate, quindi supponendo che sia possibile configurare ed eseguire una routine di caricamento multithread di massa MapReduce come o Spark, la velocità di scrittura è limitata solo dalla capacità della tabella di destinazione (anch'essa generalmente illimitata).
Quando si caricano dati in DynamoDB, è importante comprendere la velocità di scrittura dello strumento di caricamento. Se gli elementi (righe) in caricamento hanno una dimensione pari o inferiore a 1 KB, questa velocità è semplicemente il numero di elementi al secondo. È quindi possibile dotare la tabella di destinazione di una quantità sufficiente di WCU (Write Capacity Units, unità di capacità di scrittura) per gestire questa frequenza. Se lo strumento di caricamento supera la capacità allocata in un dato secondo, le richieste aggiuntive potrebbero essere sottoposte a limitazione (della larghezza di banda della rete) o rifiutate del tutto. Puoi verificare la presenza di accelerazioni nei CloudWatch grafici che si trovano nella scheda di monitoraggio della console DynamoDB.
La seconda operazione che può essere eseguita è con un’API correlata denominata BatchWriteItem. BatchWriteItem consente di combinare fino a 25 richieste di scrittura in un’unica chiamata API. Queste vengono ricevute dal servizio ed elaborate come richieste PutItem separate nella tabella. Attualmente, scegliendoBatchWriteItem, non avrai il vantaggio dei nuovi tentativi automatici inclusi nell' AWS SDK quando effettui chiamate singleton con. PutItem Pertanto, in caso di errori come le eccezioni di limitazione (della larghezza di banda della rete), sarà necessario cercare l’elenco di tutte le scritture non andate a buon fine nella chiamata di risposta a BatchWriteItem. Per ulteriori informazioni sulla gestione degli avvisi di limitazione nel caso in cui questi vengano rilevati nelle tabelle di limitazione, consulta. CloudWatch Risoluzione dei problemi di limitazione (della larghezza di banda della rete) in Amazon DynamoDB
Il terzo tipo di importazione dei dati è possibile con la funzionalità DynamoDB Import from S3PutItem, richiede un processo a monte e scrive i dati nel formato scelto in un bucket Amazon S3.
Strumenti per la migrazione a DynamoDB
Esistono diversi strumenti di migrazione ed ETL comuni che è possibile utilizzare per migrare i dati in DynamoDB.
Amazon offre una serie di strumenti di dati che possono essere utilizzati durante la migrazione, tra cui AWS Database Migration Service (DMS), AWS Glue, Amazon EMR e Streaming gestito da Amazon per Apache Kafka. Tutti questi strumenti possono essere utilizzati per eseguire una migrazione con tempi di inattività e possono sfruttare le funzionalità di Change Data Capture (CDC) del database relazionale per supportare le migrazioni online. Nella scelta di uno strumento, è utile considerare il set di competenze e l’esperienza dell’organizzazione con ogni strumento, oltre alle funzionalità, alle prestazioni e al costo di ciascuno di essi.
Molti clienti scelgono di scrivere i propri script e processi di migrazione per creare trasformazioni dei dati personalizzate per il processo di migrazione. Se si prevede di gestire una tabella DynamoDB ad alto volume con traffico di scrittura intenso o processi regolari di caricamento in blocco di grandi dimensioni, si potrebbe voler scrivere in prima persona il codice di migrazione per acquisire maggiore familiarità con il comportamento di DynamoDB in presenza di un traffico di scrittura intenso. Scenari come la gestione della limitazione (della larghezza di banda della rete) e il provisioning efficiente delle tabelle possono essere sperimentati nelle prime fasi del progetto, quando si esegue una migrazione pratica.
Scelta della strategia appropriata per la migrazione a DynamoDB
Un’applicazione di database relazionale di grandi dimensioni può estendersi su un centinaio o più tabelle e supportare diverse funzioni applicative. Quando si predispone una migrazione su larga scala, occorre prendere in considerazione la possibilità di suddividere l’applicazione in componenti o microservizi più piccoli e di migrare un piccolo set di tabelle alla volta. È quindi possibile migrare componenti aggiuntivi su DynamoDB a ondate.
Nella selezione di una strategia di migrazione, diversi fattori possono indirizzare l’utente verso una soluzione o un’altra. Si presentano queste opzioni in un albero decisionale per semplificare le opzioni a disposizione in base ai requisiti e alle risorse disponibili. I concetti sono qui brevemente menzionati (ma verranno trattati più approfonditamente più avanti nella guida):
-
Migrazione offline: se l’applicazione è in grado di tollerare tempi di inattività durante la migrazione, questo semplificherà il processo di migrazione.
-
Migrazione ibrida: questo approccio consente un tempo di attività parziale durante la migrazione, ad esempio consentendo le letture ma non le scritture, oppure consente letture e inserimenti ma non aggiornamenti ed eliminazioni.
-
Migrazione online: la migrazione delle applicazioni che richiedono l’assenza di tempi di inattività durante la migrazione è meno semplice e può richiedere una pianificazione significativa e uno sviluppo personalizzato. Una decisione chiave riguarda la stima e la ponderazione dei costi legati alla creazione di un processo di migrazione personalizzato rispetto al costo per l’azienda derivante dai tempi di inattività durante la fase di conversione.
| Se | And | Allora |
|---|---|---|
| È possibile disattivare l’applicazione per qualche tempo durante una finestra di manutenzione per eseguire la migrazione dei dati. È una migrazione offline. |
Utilizzare AWS DMS ed eseguire una migrazione offline utilizzando un'attività a pieno carico. Se lo desideri, preforma i dati di origine con un codice SQL |
|
| È possibile eseguire l’applicazione in modalità di sola lettura durante la migrazione. È una migrazione ibrida. | Disabilita le scritture all’interno dell’applicazione o del database di origine. Utilizza AWS DMS ed esegui una migrazione offline utilizzando un'attività a pieno carico. | |
| Durante la migrazione è possibile eseguire l’applicazione con letture e inserimenti di nuovi record, ma senza aggiornamenti o eliminazioni. È una migrazione ibrida. | Si hanno competenze nello sviluppo di applicazioni e l’app relazionale esistente può essere aggiornata per eseguire doppie scritture, anche su DynamoDB, per tutti i nuovi record | Utilizza AWS DMS ed esegui una migrazione offline utilizzando un'attività a pieno carico. Contemporaneamente implementa una versione dell’app esistente che consenta la lettura e l’esecuzione di doppie scritture. |
| È necessaria una migrazione con tempi di inattività minimi. È una migrazione online. |
|
Utilizzare AWS DMS per eseguire una migrazione dei dati online. Esegui un’attività di caricamento in blocco seguita da un’attività di sincronizzazione CDC. |
| È necessaria una migrazione con tempi di inattività minimi. È una migrazione online. |
|
Crea la tabella NoSQL-ready all’interno del database SQL. Compilalo e sincronizzalo utilizzando JOINs,, UNIONs, trigger VIEWs, stored procedure. |
| È necessaria una migrazione con tempi di inattività minimi. È una migrazione online. |
|
Prendi in considerazione gli approcci di migrazione ibridi o offline. |
| È necessaria una migrazione con tempi di inattività minimi. È una migrazione online. | È possibile saltare la migrazione dei dati storici delle transazioni oppure archiviarli in Amazon S3 anziché migrarli. È necessario migrare solo alcune piccole tabelle statiche. | Scrivi uno script o usa qualsiasi strumento ETL per migrare le tabelle. Se lo desideri, preforma i dati di origine con un codice SQL VIEW. |
Esecuzione di una migrazione offline a DynamoDB
Le migrazioni offline sono adatte quando è possibile un tempo di inattività per eseguire la migrazione. I database relazionali in genere richiedono almeno qualche tempo di inattività ogni mese per la manutenzione e l’applicazione delle patch, oppure possono richiedere tempi di inattività più lunghi per gli aggiornamenti hardware o gli aggiornamenti delle versioni principali.
Amazon S3 può essere utilizzato come area di staging durante una migrazione. I dati archiviati in formato CSV (valori separati da virgola) o DynamoDB JSON possono essere importati automaticamente in una nuova tabella DynamoDB utilizzando la funzionalità di importazione in DynamoDB da S3.
Si potrebbe voler combinare le tabelle per sfruttare modelli di accesso NoSQL unici (ad esempio, trasformando quattro tabelle legacy in un’unica tabella DynamoDB). Una singola richiesta di documento chiave-valore o una query per una raccolta di elementi preraggruppati di solito restituisce una latenza migliore rispetto a un database SQL che esegue una query join multi-tabella. Tuttavia, ciò rende l’attività di migrazione più difficile. Una query view SQL potrebbe essere adatta all’interno del database di origine per preparare un singolo set di dati che rappresenti tutte e quattro le tabelle in un unico set.
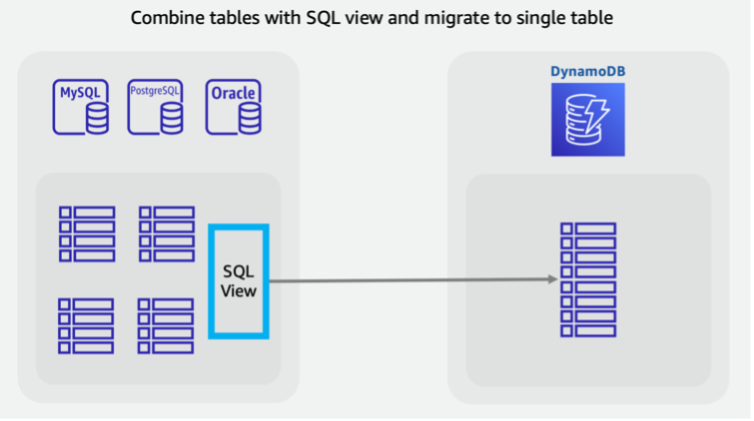
Questa visualizzazione consente di creare tabelle JOIN in una forma denormalizzata oppure può mantenere le entità normalizzate e impilare le tabelle utilizzando un query UNION SQL. Le decisioni chiave relative alla ridefinizione dei dati relazionali sono trattate in questo video
Pianifica
Esecuzione di una migrazione offline con Amazon S3
Strumenti
-
Un processo ETL per estrarre e trasformare i dati SQL e archiviarli in un bucket S3, ad esempio:
-
AWS Database Migration Service, un servizio in grado di caricare in blocco i dati storici e di elaborare anche i record del CDC per sincronizzare le tabelle di origine e di destinazione.
-
AWS Glue
-
Amazon EMR
-
Il proprio codice personalizzato
-
-
La funzionalità di importazione in DynamoDB da S3
Fasi di migrazione offline:
-
Crea un job ETL in grado di eseguire query sul database SQL, trasformare i dati della tabella in formato DynamoDB JSON o CSV e salvarli in un bucket S3.

-
La funzionalità di importazione in DynamoDB da S3 viene invocata per creare una nuova tabella e caricare automaticamente i dati dal bucket S3.
La migrazione completamente offline è semplice e diretta, ma potrebbe non essere apprezzata dai proprietari e dagli utenti delle applicazioni. Gli utenti trarrebbero vantaggio se l’applicazione potesse fornire livelli di servizio ridotti durante la migrazione, anziché non fornire alcun servizio.
È possibile aggiungere funzionalità per disabilitare le scritture durante la migrazione offline, consentendo al contempo alle letture di continuare normalmente. Gli utenti delle applicazioni possono comunque sfogliare i dati esistenti ed eseguire quey in modo sicuro durante la migrazione dei dati relazionali. Se questo è l’obiettivo, prosegui la lettura per ulteriori informazioni sulle migrazioni ibride.
Esecuzione di una migrazione ibrida a DynamoDB
Sebbene tutte le applicazioni di database eseguano operazioni di lettura e scrittura, è necessario considerare i tipi di operazioni di scrittura eseguite quando si pianifica una migrazione ibrida o online. Le scritture sul database possono essere classificate in tre bucket: inserimenti, aggiornamenti ed eliminazioni. Alcune applicazioni potrebbero non richiedere l’elaborazione immediata delle eliminazioni. Ad esempio, queste applicazioni possono rimandare le eliminazioni a un processo di pulizia in blocco alla fine del mese. La migrazione di questi tipi di applicazioni può essere più semplice e al contempo consentire tempi di attività parziali.
Piano
Esegui una online/offline migrazione ibrida con doppia scrittura delle applicazioni
Strumenti
-
Un processo ETL per estrarre e trasformare i dati SQL e archiviarli in un bucket S3, ad esempio:
-
AWS DMS
-
AWS Glue
-
Amazon EMR
-
Il proprio codice personalizzato
-
Fasi della migrazione ibrida:
-
Crea la tabella DynamoDB. Questa tabella riceverà sia dati storici in blocco che i nuovi dati in tempo reale.
-
Crea una versione dell’applicazione legacy con le eliminazioni e gli aggiornamenti disabilitati mentre esegui tutti gli inserimenti come doppia scrittura sia nel database SQL che in DynamoDB.
-
Iniziate il lavoro o l' AWS DMS attività ETL per completare i dati esistenti e distribuite contemporaneamente la nuova versione dell'applicazione
-
Una volta completato il processo di riempimento, DynamoDB disporrà di tutti i record esistenti e nuovi e sarà pronto per la conversione dell’applicazione.
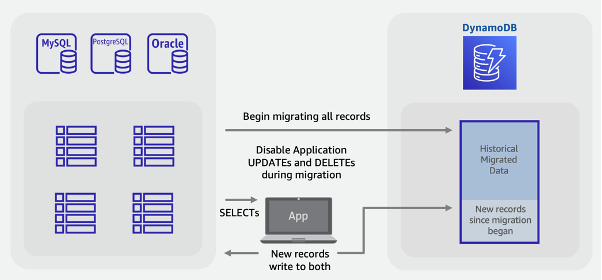
Nota
Il processo di riempimento scrive direttamente da SQL a DynamoDB. Non è possibile utilizzare la funzionalità di importazione da S3 come nell’esempio di migrazione offline, poiché tale funzionalità crea una nuova tabella che sarà attiva solo dopo il caricamento dei dati da parte di DynamoDB.
Esecuzione di una migrazione online a DynamoDB migrando ogni tabella 1:1
Molti database relazionali dispongono di una funzionalità denominata Change Data Capture (CDC), in cui il database consente agli utenti di richiedere un elenco delle modifiche a una tabella avvenute prima o dopo un determinato momento. Il CDC utilizza i log interni per abilitare questa funzionalità e non richiede che la tabella presenti colonne di timestamp per funzionare.
Nell’esecuzione della migrazione di uno schema di tabelle SQL a un database NoSQL, si potrebbe voler combinare e rimodellare i dati in un numero inferiore di tabelle. In questo modo sarà possibile raccogliere i dati in un’unica ubicazione ed evitare di dover unire manualmente i dati correlati in operazioni di lettura in più fasi. Tuttavia, il modellamento dei dati in un’unica tabella non è sempre necessario e a volte le tabelle vengono migrate 1:1 in DynamoDB. Queste migrazioni 1:1 sono meno complicate in quanto è possibile sfruttare la funzionalità CDC del database di origine, utilizzando strumenti ETL comuni che supportano questo tipo di migrazione. I dati per ogni riga possono comunque essere trasformati in nuovi formati, ma l’ambito di ogni tabella rimane lo stesso.
Prendi in considerazione la migrazione delle tabelle SQL 1:1 in DynamoDB, con l’avvertenza che DynamoDB non supporta query join lato server. Sarà necessario aggiungere logica all’applicazione per combinare i dati di più tabelle.
Pianifica
Esegui una migrazione online di ogni tabella in DynamoDB utilizzando AWS DMS
Strumenti
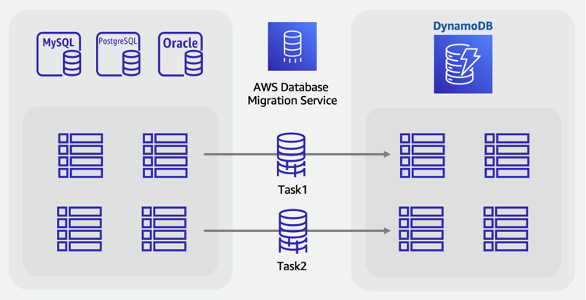
Fasi di migrazione online:
-
Identifica nello schema di origine le tabelle che verranno migrate
-
Crea lo stesso numero di tabelle in DynamoDB con la stessa struttura di chiave dell’origine
-
Crea un server di replica AWS DMS e configura gli endpoint di origine e di destinazione
-
Definisci le trasformazioni necessarie per riga (ad esempio colonne concatenate o conversione delle date nel formato di stringa ISO-8601)
-
Crea un’attività di migrazione per ogni tabella per Pieno carico e Change Data Capture
-
Monitora queste attività fino all’inizio della fase di replica in corso
-
A questo punto, è possibile eseguire qualsiasi verifica di convalida e quindi far passare gli utenti all’applicazione che legge e scrive su DynamoDB.
Esecuzione di una migrazione online a DynamoDB con una tabella di staging personalizzata
Come nello scenario di migrazione offline riportato sopra, è possibile scegliere di combinare le tabelle per sfruttare modelli di accesso NoSQL unici (ad esempio, trasformando quattro tabelle legacy in un’unica tabella DynamoDB). Una query VIEW SQL potrebbe essere adatta all’interno del database di origine per preparare un singolo set di dati che rappresenti tutte e quattro le tabelle in un unico set.
Tuttavia, per le migrazioni online con dati in tempo reale e mutevoli, non è possibile sfruttare le funzionalità CDC in quanto non sono supportate per le query VIEW. Se le tabelle includono una colonna di timestamp dell’ultimo aggiornamento e questa è incorporata nella query VIEW, è possibile creare un processo ETL personalizzato che la utilizzi per eseguire un caricamento in blocco con sincronizzazione.
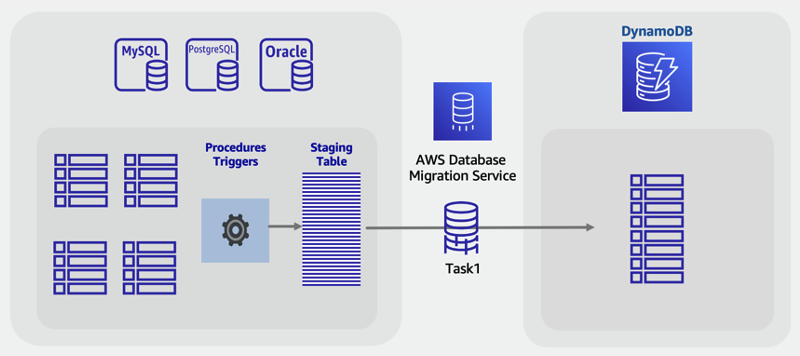
Un nuovo approccio a questa sfida consiste nell’utilizzare funzionalità SQL standard come query view, stored procedure e trigger per creare una nuova tabella SQL nel formato DynamoDB NoSQL finale desiderato.
Se il server di database dispone di capacità di riserva, è possibile creare questa singola tabella di staging prima dell’inizio della migrazione. A tale scopo, è necessario scrivere una stored procedure che legga le tabelle esistenti, trasformi i dati in base alle esigenze e scriva nella nuova tabella di staging. È possibile aggiungere un set di trigger per replicare le modifiche nelle tabelle nella tabella di staging in tempo reale. Se i trigger non sono consentiti in base alla policy aziendale, le modifiche alle stored procedure possono ottenere lo stesso risultato. È necessario aggiungere alcune righe di codice alle procedure che scrivono dati per scrivere le stesse modifiche anche nella tabella di staging.
La disponibilità di questa tabella di staging completamente sincronizzata con le tabelle delle applicazioni precedenti offrirà un ottimo punto di partenza per una migrazione in tempo reale. Gli strumenti che utilizzano il database CDC per eseguire migrazioni in tempo reale, ad esempio AWS DMS, possono ora essere utilizzati su questa tabella. Un vantaggio di questo approccio è che utilizza le competenze e le funzionalità SQL ben note disponibili nel motore di database relazionale.
Pianifica
Esegui una migrazione online con una tabella intermedia SQL utilizzando AWS DMS
Strumenti
-
Stored procedure o trigger SQL personalizzati
Fasi di migrazione online:
-
All’interno del motore di database relazionale di origine, assicurati che siano disponibili spazio su disco e capacità di elaborazione aggiuntivi.
-
Crea una nuova tabella di staging nel database SQL, con timestamp o funzionalità CDC abilitate.
-
Scrivi ed esegui una stored procedure per copiare i dati della tabella relazionale esistente nella tabella di staging.
-
Implementa i trigger o modifica le procedure esistenti per eseguire la doppia scrittura nella nuova tabella di staging mentre esegui le normali scritture sulle tabelle esistenti.
-
Esegui AWS DMS per migrare e sincronizzare questa tabella di origine con una tabella DynamoDB di destinazione
Questa guida ha presentato diverse considerazioni e approcci per la migrazione dei dati di database relazionali a DynamoDB, con particolare attenzione alla riduzione al minimo dei tempi di inattività e all’utilizzo di strumenti e tecniche di database comuni. Per ulteriori informazioni, consulta gli argomenti seguenti:
