Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Aggiunta di dati a un database RDS di origine ed esecuzione di query al suo interno
Per completare la creazione di un’integrazione Zero-ETL che replichi i dati da Amazon RDS in Amazon Redshift, devi creare un database nella destinazione.
Per le connessioni con Amazon Redshift, connettiti al cluster o al gruppo di lavoro Amazon Redshift e crea un database con un riferimento al tuo identificatore di integrazione. Quindi, puoi aggiungere dati al database RDS e vederli replicati in Amazon Redshift o Amazon SageMaker.
Argomenti
Creazione di un database di destinazione
Prima di poter iniziare a replicare i dati in Amazon Redshift dopo aver creato un’integrazione, devi creare un database nel data warehouse di destinazione. Questo database deve includere un riferimento all’identificatore di integrazione. Puoi utilizzare la console Amazon Redshift o Editor di query v2 per creare il database.
Per istruzioni sulla creazione di un database di destinazione, consulta Creazione di un database di destinazione in Amazon Redshift.
Aggiunta di dati al database di origine
Dopo aver configurato l’integrazione, puoi popolare il database RDS di origine con i dati che desideri replicare nel data warehouse.
Nota
Esistono differenze tra i tipi di dati in Amazon RDS e il warehouse di analisi di destinazione. Per una tabella di mappature dei tipi di dati, consulta Differenze tra i tipi di dati tra i database RDS e Amazon Redshift.
Innanzitutto, connettiti al database di origine utilizzando il client MySQL di tua scelta. Per istruzioni, consulta Connessione all’istanza database MySQL.
Quindi, crea una tabella e inserisci una riga di dati di esempio.
Importante
Assicurati che la tabella abbia una chiave primaria. Altrimenti, non può essere replicata nel data warehouse di destinazione.
RDS per MySQL
L’esempio seguente utilizza l’utilità MySQL Workbench
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS per PostgreSQL
L’esempio seguente utilizza il terminale interattivo PostgreSQL psql. Quando ti connetti al database, includi il nome del database che desideri replicare.
psql -hmydatabase.123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS per Oracle
L’esempio seguente utilizza SQL*Plus per connettersi al database RDS per Oracle.
sqlplus 'user_name@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dns_name)(PORT=port))(CONNECT_DATA=(SID=database_name)))' SQL> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); SQL> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Interrogazione dei dati Amazon RDS in Amazon Redshift
Dopo aver aggiunto i dati al database RDS, questi vengono replicati nel database di destinazione e sono pronti per essere sottoposti a query.
Esecuzione di query sui dati replicati
-
Vai alla console Amazon Redshift e scegli Editor di query v2 nel riquadro di navigazione a sinistra.
-
Connettiti al cluster o al gruppo di lavoro e scegli il database di destinazione (creato dall’integrazione) dal menu a tendina (destination_database in questo esempio). Per istruzioni sulla creazione di un database di destinazione, consulta Creazione di un database di destinazione in Amazon Redshift.
-
Utilizzo di un’istruzione SELECT per eseguire query sui dati. In questo esempio, puoi eseguire il comando seguente per selezionare tutti i dati dalla tabella creata nel database RDS di origine:
SELECT * frommy_db."books_table";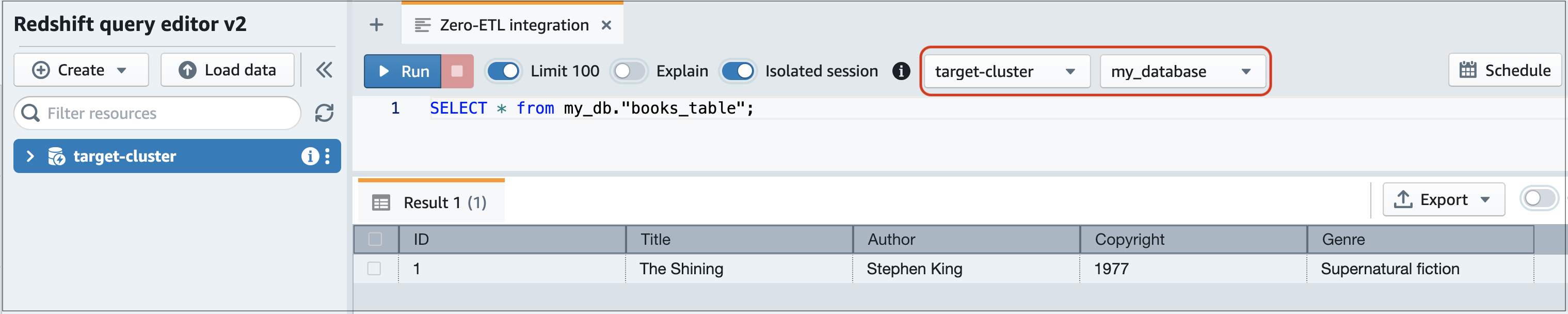
-
my_db -
books_table
-
Puoi anche eseguire query sui dati utilizzando il client della riga di comando. Esempio:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
Nota
Per distinguere tra maiuscole e minuscole, usa le virgolette doppie (" ") per i nomi di schemi, tabelle e colonne. Per ulteriori informazioni, consulta enable_case_sensitive_identifier.
Differenze tra i tipi di dati tra i database RDS e Amazon Redshift
Di seguito, le tabelle mostrano le mappature dei tipi di dati RDS per MySQL, RDS per PostgreSQL e RDS per Oracle ai tipi di dati di destinazione corrispondenti. Amazon RDS attualmente supporta solo questi tipi di dati per le integrazioni Zero-ETL.
Se una tabella nel database di origine include un tipo di dato non supportato, la tabella non viene sincronizzata e non è utilizzabile dalla destinazione. Lo streaming dall’origine alla destinazione va avanti, ma la tabella con il tipo di dato non supportato non è disponibile. Per correggere la tabella e renderla disponibile nella destinazione, devi annullare manualmente la modifica iniziale e aggiornare l’integrazione eseguendo ALTER DATABASE...INTEGRATION
REFRESH.
Nota
Non puoi aggiornare le integrazioni Zero-ETL con un Amazon SageMaker Lakehouse. Piuttosto, elimina e prova a creare nuovamente l’integrazione.
RDS per MySQL
| Tipi di dati RDS per MySQL | Tipi di dati di destinazione | Description | Limitazioni |
|---|---|---|---|
| INT | INTEGER | Intero a quattro byte firmato | Nessuno |
| SMALLINT | SMALLINT | Intero a due byte firmato | Nessuno |
| TINYINT | SMALLINT | Intero a due byte firmato | Nessuno |
| MEDIUMINT | INTEGER | Intero a quattro byte firmato | Nessuno |
| BIGINT | BIGINT | Intero a otto byte firmato | Nessuno |
| INT UNSIGNED | BIGINT | Intero a otto byte firmato | Nessuno |
| TINYINT UNSIGNED | SMALLINT | Intero a due byte firmato | Nessuno |
| MEDIUMINT UNSIGNED | INTEGER | Intero a quattro byte firmato | Nessuno |
| BIGINT UNSIGNED | DECIMAL(20,0) | Numerico esatto di precisione selezionabile | Nessuno |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | Numerico esatto di precisione selezionabile |
Precisione superiore a 38 e scala superiore a 37 non supportate |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | Numerico esatto di precisione selezionabile |
Precisione superiore a 38 e scala superiore a 37 non supportate |
| FLOAT4/REAL | REAL | Numero in virgola mobile a precisione singola | Nessuno |
| FLOAT4/REAL NON FIRMATO | REAL | Numero in virgola mobile a precisione singola | Nessuno |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Numero in virgola mobile a precisione doppia | Nessuno |
| DOUBLE/REAL/FLOAT8 NON FIRMATO | DOUBLE PRECISION | Numero in virgola mobile a precisione doppia | Nessuno |
| BIT(n) | VARBYTE(8) | Variable-length valore binario | Nessuno |
| BINARY(n) | VARBYTE(n) | Variable-length valore binario | Nessuno |
| VARBINARY(n) | VARBYTE(n) | Variable-length valore binario | Nessuno |
| CHAR(n) | VARCHAR(n) | Variable-length valore stringa | Nessuno |
| VARCHAR(n) | VARCHAR(n) | Variable-length valore stringa | Nessuno |
| TEXT | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| TINYTEXT | VARCHAR(255) | Variable-length valore di stringa fino a 255 caratteri | Nessuno |
| MEDIUMTEXT | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| LONGTEXT | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| ENUM | VARCHAR(1020) | Variable-length valore di stringa fino a 1.020 caratteri | Nessuno |
| SET | VARCHAR(1020) | Variable-length valore di stringa fino a 1.020 caratteri | Nessuno |
| DATE | DATE | Data di calendario (anno, mese, giorno) | Nessuno |
| DATETIME | TIMESTAMP | Data e ora (senza fuso orario) | Nessuno |
| TIMESTAMP(p) | TIMESTAMP | Data e ora (senza fuso orario) | Nessuno |
| TIME | VARCHAR(18) | Variable-length valore di stringa fino a 18 caratteri | Nessuno |
| ANNO | VARCHAR(4) | Variable-length valore stringa fino a 4 caratteri | Nessuno |
| JSON | SUPER | Dati o documenti semistrutturati come valori | Nessuno |
RDS per PostgreSQL
Zero-ETL integrazioni per RDS per PostgreSQL Aurora PostgreSQL .
| Tipi di dati RDS per PostgreSQL | Tipi di dati di Amazon Redshift | Description | Limitazioni |
|---|---|---|---|
| array | SUPER | Dati o documenti semistrutturati come valori | Nessuno |
| bigint | BIGINT | Intero a otto byte firmato | Nessuno |
| bigserial | BIGINT | Intero a otto byte firmato | Nessuno |
| bit varying(n) | VARBYTE(n) | Variable-length valore binario fino a 16.777.216 byte | Nessuno |
| bit(n) | VARBYTE(n) | Variable-length valore binario fino a 16.777.216 byte | Nessuno |
| bit, bit varying | VARBYTE(16777216) | Variable-length valore binario fino a 16.777.216 byte | Nessuno |
| booleano | BOOLEAN | true/falseBooleano logico () | Nessuno |
| bytea | VARBYTE(16777216) | Variable-length valore binario fino a 16.777.216 byte | Nessuno |
| char(n) | CHAR(n) | Fixed-length valore della stringa di caratteri fino a 65.535 byte | Nessuno |
| char varying(n) | VARCHAR(65535) | Variable-length valore della stringa di caratteri fino a 65.535 caratteri | Nessuno |
| cid | BIGINT |
Intero a otto byte firmato |
Nessuno |
| cidr |
VARCHAR(19) |
Variable-length valore di stringa fino a 19 caratteri |
Nessuno |
| data | DATE | Data di calendario (anno, mese, giorno) |
Valori superiori a 294.276 A.D. Non supportati |
| double precision | DOUBLE PRECISION | Numeri in virgola mobile a precisione doppia | Valori subnormali non completamente supportati |
|
gtsvector |
VARCHAR(65535) |
Variable-length valore di stringa fino a 65.535 caratteri |
Nessuno |
| inet |
VARCHAR(19) |
Variable-length valore di stringa fino a 19 caratteri |
Nessuno |
| intero | INTEGER | Intero a quattro byte firmato | Nessuno |
|
int2vector |
SUPER | Dati o documenti semistrutturati come valori. | Nessuno |
| intervallo | INTERVAL | Intervallo di tempo | Sono supportati solo i tipi INTERVAL che specificano un qualificatore da anno a mese o da giorno a secondo. |
| json | SUPER | Dati o documenti semistrutturati come valori | Nessuno |
| jsonb | SUPER | Dati o documenti semistrutturati come valori | Nessuno |
| jsonpath | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
|
macaddr |
VARCHAR(17) | Variable-length valore di stringa fino a 17 caratteri | Nessuno |
|
macaddr8 |
VARCHAR(23) | Variable-length valore stringa fino a 23 caratteri | Nessuno |
| money | DECIMAL(20,3) | Importo in valuta | Nessuno |
| nome | VARCHAR(64) | Variable-length valore di stringa fino a 64 caratteri | Nessuno |
| numeric(p,s) | DECIMAL(p,s) | User-defined valore di precisione fisso |
|
| oid | BIGINT | Intero a otto byte firmato | Nessuno |
| oidvector | SUPER | Dati o documenti semistrutturati come valori. | Nessuno |
| pg_brin_bloom_summary | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| pg_dependencies | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| pg_lsn | VARCHAR(17) | Variable-length valore di stringa fino a 17 caratteri | Nessuno |
| pg_mcv_list | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| pg_ndistinct | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| pg_node_tree | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| pg_snapshot | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| real | REAL | Numero in virgola mobile a precisione singola | Valori subnormali non completamente supportati |
| refcursor | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| smallint | SMALLINT | Intero a due byte firmato | Nessuno |
| smallserial | SMALLINT | Intero a due byte firmato | Nessuno |
| seriale | INTEGER | Intero a quattro byte firmato | Nessuno |
| testo | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| tid | VARCHAR(23) | Variable-length valore di stringa fino a 23 caratteri | Nessuno |
| ora [(p)] senza fuso orario | VARCHAR(19) | Variable-length valore di stringa fino a 19 caratteri | Valori Infinity e -Infinity non supportati |
| ora [(p)] con fuso orario | VARCHAR(22) | Variable-length valore di stringa fino a 22 caratteri | Valori Infinity e -Infinity non supportati |
| timestamp [(p)] senza fuso orario | TIMESTAMP | Data e ora (senza fuso orario) |
|
| timestamp [(p)] con fuso orario | TIMESTAMPTZ | Data e ora (con fuso orario) |
|
| tsquery | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| tsvector | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| txid_snapshot | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
| uuid | VARCHAR(36) | Variable-length stringa di 36 caratteri | Nessuno |
| xid | BIGINT | Intero a otto byte firmato | Nessuno |
| xid8 | DECIMAL(20, 0) | Decimale a precisione fissa | Nessuno |
| xml | VARCHAR(65535) | Variable-length valore di stringa fino a 65.535 caratteri | Nessuno |
RDS per Oracle
Tipi di dati non supportati
I seguenti tipi di dati RDS per Oracle non sono supportati da Amazon Redshift:
-
ANYDATA -
BFILE -
REF -
ROWID -
UROWID -
VARRAY -
SDO_GEOMETRY -
User-defined tipi di dati
Differenze dei tipi di dati
La tabella seguente mostra le differenze tra i tipi di dati che influiscono su un’integrazione Zero-ETL quando RDS per Oracle è l’origine e Amazon Redshift è la destinazione.
| Tipi di dati RDS per Oracle | Tipi di dati di Amazon Redshift |
|---|---|
|
BINARY_FLOAT |
FLOAT4 |
|
BINARY_DOUBLE |
FLOAT8 |
|
BINARY |
VARCHAR (lunghezza) |
|
FLOAT (P) |
Se la precisione è =< 24 allora FLOAT4. Se la precisione è > 24 allora FLOAT8. |
|
NUMBER (P,S) |
Se la scala è => 0 e =< 37, NUMERIC(p,s). Se la scala è => 38 e =< 127 VARCHAR(lunghezza). Se la scala è 0:
Se la scala è minore di 0, INT8. |
|
DATE |
Se la scala è => 0 e =< 6, a seconda del tipo di colonna di destinazione Redshift, il valore è uno dei seguenti:
Se la scala è => 7 e =< 9, VARCHAR (37). |
|
INTERVAL_YEAR TO MONTH |
Se la lunghezza è compresa tra 1 e 65.535, VARCHAR (lunghezza in byte). Se la lunghezza è compresa tra 65.536 e 2.147.483.647, VARCHAR (65535). |
|
INTERVAL_DAY TO SECOND |
Se la lunghezza è compresa tra 1 e 65.535, VARCHAR (lunghezza in byte). Se la lunghezza è compresa tra 65.536 e 2.147.483.647, VARCHAR (65535). |
|
TIMESTAMP |
Se la scala è => 0 e =< 6, a seconda del tipo di colonna di destinazione Redshift, il valore è uno dei seguenti:
Se la scala è => 7 e =< 9, VARCHAR (37). |
|
TIMESTAMP WITH TIME ZONE |
Se la lunghezza è compresa tra 1 e 65.535, VARCHAR (lunghezza in byte). Se la lunghezza è compresa tra 65.536 e 2.147.483.647, VARCHAR (65535). |
|
TIMESTAMP WITH LOCAL TIME ZONE |
Se la lunghezza è compresa tra 1 e 65.535, VARCHAR (lunghezza in byte). Se la lunghezza è compresa tra 65.536 e 2.147.483.647, VARCHAR (65535). |
|
CHAR |
Se la lunghezza è compresa tra 1 e 65.535, VARCHAR (lunghezza in byte). Se la lunghezza è compresa tra 65.536 e 2.147.483.647, VARCHAR (65535). |
|
VARCHAR2 |
Se la lunghezza è superiore a 4.000 byte, VARCHAR (dimensione massima LOB). Le dimensioni massime di LOB non possono superare 63 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. Se la lunghezza è pari o inferiore a 4.000 byte, VARCHAR (lunghezza in byte). |
|
NCHAR |
Se la lunghezza è compresa tra 1 e 65.535, NVARCHAR (lunghezza in byte). Se la lunghezza è compresa tra 65.536 e 2.147.483.647, NVARCHAR (65535). |
|
NVARCHAR2 |
Se la lunghezza è superiore a 4.000 byte, NVARCHAR (dimensione massima LOB). Le dimensioni massime di LOB non possono superare 63 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. Se la lunghezza è pari o inferiore a 4.000 byte, NVARCHAR (lunghezza in byte). |
|
RAW |
VARCHAR (lunghezza) |
|
REAL |
FLOAT8 |
|
BLOB |
VARCHAR (dimensioni massime di LOB *2) Le dimensioni massime di LOB non possono superare 31 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. |
|
CLOB |
VARCHAR (dimensioni massime di LOB) Le dimensioni massime di LOB non possono superare 63 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. |
|
NCLOB |
NVARCHAR (dimensioni massime di LOB) Le dimensioni massime di LOB non possono superare 63 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. |
|
LONG |
VARCHAR (dimensioni massime di LOB) Le dimensioni massime di LOB non possono superare 63 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. |
|
LONG RAW |
VARCHAR (dimensioni massime di LOB *2) Le dimensioni massime di LOB non possono superare 31 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. |
|
XMLTYPE |
VARCHAR (dimensioni massime di LOB) Le dimensioni massime di LOB non possono superare 63 KB. Amazon Redshift non supporta valori VARCHAR di dimensioni superiori a 64 KB. |
Operazioni DDL per RDS per PostgreSQL
Zero-ETL le integrazioni sfruttano queste somiglianze per semplificare la replica dei dati da RDS per PostgreSQL Aurora PostgreSQL , schemi e tabelle.
Considera i seguenti punti quando gestisci le integrazioni Zero-ETL di RDS per PostgreSQL:
-
L’isolamento è gestito a livello di database.
-
La replica avviene a livello di database.
-
I database RDS per PostgreSQL sono mappati ai database Amazon Redshift per nome, con i dati che fluiscono verso il corrispondente database Redshift rinominato se l’originale viene rinominato.
Nonostante le loro somiglianze, Amazon Redshift e RDS per PostgreSQL presentano differenze importanti. Le seguenti sezioni descrivono le risposte del sistema Amazon Redshift per le operazioni DDL comuni.
operazioni database
La tabella seguente mostra le risposte del sistema per le operazioni DDL del database.
| Operazioni DDL | Risposta del sistema Redshift |
|---|---|
CREATE DATABASE |
Nessuna operazione |
DROP DATABASE |
Amazon Redshift elimina tutti i dati nel database Redshift di destinazione. |
RENAME DATABASE |
Amazon Redshift elimina tutti i dati nel database di destinazione originale e risincronizza i dati nel nuovo database di destinazione. Se il nuovo database non esiste, devi crearlo manualmente. Per istruzioni, consulta Creazione di database di destinazione in Amazon Redshift. |
Operazioni dello schema
La tabella seguente mostra le risposte del sistema per le operazioni DDL dello schema.
| Operazioni DDL | Risposta del sistema Redshift |
|---|---|
CREATE SCHEMA |
Nessuna operazione |
DROP SCHEMA |
Amazon Redshift elimina lo schema originale. |
RENAME SCHEMA |
Amazon Redshift elimina lo schema originale, quindi risincronizza i dati nel nuovo schema. |
Operazioni sulle tabelle
La tabella seguente mostra le risposte del sistema per le operazioni DDL della tabella.
| Operazioni DDL | Risposta del sistema Redshift |
|---|---|
CREATE TABLE |
Amazon Redshift crea la tabella. Alcune operazioni impediscono la creazione della tabella, ad esempio la creazione di una tabella senza una chiave primaria o l’esecuzione del partizionamento dichiarativo. Per ulteriori informazioni, consultare Limitazioni e Risoluzione dei problemi delle integrazioni Zero-ETL di Amazon RDS. |
DROP TABLE |
Amazon Redshift elimina la tabella. |
TRUNCATE TABLE |
Amazon Redshift tronca la tabella. |
ALTER TABLE
(RENAME...) |
Amazon Redshift rinomina la tabella o la colonna. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift elimina la tabella nello schema originale e risincronizza la tabella nel nuovo schema. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift aggiunge una chiave primaria e risincronizza la tabella. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift aggiunge una colonna alla tabella. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift elimina la colonna se non è una colonna di chiave primaria. Altrimenti, risincronizza la tabella. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
Se modifichi la tabella in registrata, Amazon Redshift risincronizza la tabella. Se modifichi la tabella in non registrata, Amazon Redshift elimina la tabella. |
