Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio della replica di lettura
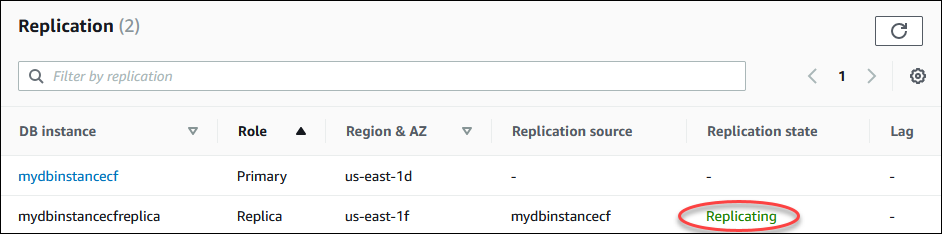
Puoi monitorare lo stato di una replica di lettura in diversi modi. La console Amazon RDS mostra lo stato di una replica di lettura nella sezione Replication (Replica) della scheda Connectivity & security (Connettività e sicurezza) nelle informazioni di dettaglio della replica di lettura. Per visualizzare i dettagli per una replica di lettura, scegli il nome della replica di lettura nell'elenco di istanze database nella console di Amazon RDS.
Puoi anche vedere lo stato di una replica di lettura utilizzando il AWS CLI
describe-db-instances comando o l'operazione dell'API DescribeDBInstances Amazon RDS.
Lo stato di una replica di lettura può essere uno dei seguenti:
-
replicating (replica in corso) – La replica di lettura sta eseguendo correttamente la replica.
-
replica danneggiata (solo SQL Server e PostgreSQL) – Le repliche ricevono dati dall'istanza primaria, ma uno o più database potrebbe non ricevere aggiornamenti. Ciò può verificarsi, ad esempio, quando una replica sta completando l'impostazione dei database appena creati. Può verificarsi anche quando vengono apportate modifiche DDL non supportate o a oggetti di grandi dimensioni nell'ambiente blu di una distribuzione. blue/green
Lo stato non passa da
replication degradedaerror, a meno che non si verifichi un errore durante lo stato danneggiato. -
error (errore) – Si è verificato un errore di replica. Controlla il campo Replication Error (Errore di replica) nella console Amazon RDS o il log degli eventi per determinare esattamente l'errore. Per ulteriori informazioni sulla risoluzione dei problemi causati da un errore di replica, consulta Risoluzione dei problemi relativi a una replica di lettura MySQL.
-
terminated (terminata) (solo MariaDB, MySQL o PostgreSQL) – La replica è terminata. Questa situazione si verifica se la replica viene arrestata per più di 30 giorni consecutivi, manualmente o a causa di un errore di replica. In questo caso, Amazon RDS termina la replica tra l'istanza database primaria e tutte le repliche di lettura. Amazon RDS si comporta così per evitare requisiti di archiviazione maggiori sull'istanza database di origine e tempi di failover prolungati.
L'interruzione della replica può influire sullo storage, perché può causare l'aumento delle dimensioni e del numero dei log a causa del volume elevato di messaggi di errore scritti nel log. L'interruzione della replica può anche influire sul ripristino dagli errori a causa del tempo necessario ad Amazon RDS per mantenere ed elaborare il numero elevato di log durante il ripristino.
-
terminated (terminata) (solo Oracle) – La replica è terminata. Questa situazione si verifica se la replica viene arrestata per più di 8 ore a causa della mancanza di spazio di archiviazione nella replica di lettura. In questo caso, Amazon RDS termina la replica tra l'istanza database primaria e tutte le repliche di lettura. Questo è uno stato terminale e la replica di lettura deve essere ricreata.
-
stopped (arrestata) (solo MySQL o MariaDB) – La replica è stata interrotta a causa di una richiesta avviata dal cliente.
-
replication stop point set (punto di arresto replica impostato) (solo MySQL) – È stato impostato un punto di arresto avviato dal cliente tramite la stored procedure e la replica è in corso.
-
replication stop point reached (punto di arresto replica raggiunto) (solo MySQL) – È stato impostato un punto di arresto avviato dal cliente tramite la stored procedure e la replica è stata arrestata perché è stato raggiunto il punto di arresto.
È possibile visualizzare dove viene replicata un'istanza database e, in caso affermativo, verificarne lo stato di replica. Nella pagina Databases (Database) della console RDS viene visualizzato Primary (Primario) nella colonna Role (Ruolo). Scegliere il nome dell'istanza database. Nella relativa pagina dei dettagli, nella scheda Connectivity & security (Connettività e sicurezza), lo stato di replica si trova in Replica.
Monitoraggio del ritardo di replica
Puoi monitorare il ritardo di replica in Amazon CloudWatch visualizzando la metrica Amazon ReplicaLag RDS.
Per Db2, la metrica ReplicaLag è il ritardo massimo dei database che sono rimasti indietro, in secondi. Ad esempio, se sono disponibili due database con, rispettivamente, un ritardo di 5 secondi e 10 secondi, ReplicaLag è di 10 secondi. I database senza stati di High Availability Disaster Recovery (HADR) disponibili non sono inclusi nel calcolo.
Per MariaDB e MySQL, il parametro ReplicaLag indica il valore del campo Seconds_Behind_Master del comando SHOW REPLICA STATUS. Le cause comuni del ritardo di replica per MySQL e MariaDB sono le seguenti:
-
Interruzione della connessione di rete.
-
Scrittura in tabelle con indici in una replica di lettura. Se il parametro
read_onlynon è impostato su 0 nella replica di lettura, la replica può essere interrotta. -
Uso di un motore di storage non transazionale come MyISAM. La replica è supportata solo per il motore di storage InnoDB in MySQL e per il motore di storage XtraDB in MariaDB.
Nota
Le versioni precedenti di MariaDB utilizzavano SHOW SLAVE STATUS anziché SHOW REPLICA STATUS. Se si utilizza una versione di MariaDB precedente alla 10.5, utilizzare SHOW SLAVE STATUS.
Quando il parametro ReplicaLag è 0, la replica ha raggiunto l'istanza del database primaria. Se il parametro ReplicaLag restituisce -1, la replica non è attualmente attiva. ReplicaLag = -1 equivale a Seconds_Behind_Master = NULL.
Per Oracle, il parametro ReplicaLag è la somma del valore Apply
Lag e della differenza tra il tempo corrente e il valore DATUM_TIME di Apply Lag. Il valore DATUM_TIME indica il tempo in cui la replica di lettura ha ricevuto per l'ultima volta i dati dall'istanza database di origine. Per ulteriori informazioni, consultare V$DATAGUARD_STATS
Per SQL Server, il parametro ReplicaLag è il ritardo massimo dei database che sono rimasti indietro, in secondi. Ad esempio, se sono disponibili due database con, rispettivamente, un ritardo di 5 secondi e 10 secondi, ReplicaLag è di 10 secondi. Il parametro ReplicaLag restituisce il valore della query seguente.
SELECT MAX(secondary_lag_seconds) max_lag FROM sys.dm_hadr_database_replica_states;
Per ulteriori informazioni, consulta secondary_lag_seconds
ReplicaLag restituisce -1 se RDS non è in grado di determinare il ritardo, ad esempio durante la configurazione della replica o quando lo stato della replica di lettura è error.
Nota
I nuovi database non vengono inclusi nel calcolo del ritardo finché non sono accessibili nella replica di lettura.
Per PostgreSQL, il parametro ReplicaLag restituisce il valore della query seguente.
SELECT extract(epoch from now() - pg_last_xact_replay_timestamp()) AS reader_lag
PostgreSQL versioni 9.5.2 e successive usano slot di replica fisici per gestire la conservazione dei dati Write Ahead Log (WAL) nell'istanza di origine. Per ogni istanza di replica di lettura tra regioni, Amazon RDS crea uno slot di replica fisica e lo associa all'istanza. Due CloudWatch metriche di Amazon mostrano quanto sia indietro rispetto alla replica con maggior ritardo in termini di dati WAL ricevuti e di quanto spazio di archiviazione viene utilizzato per i dati WAL. Oldest Replication Slot Lag Transaction
Logs Disk Usage Il valore Transaction
Logs Disk Usage può aumentare in modo considerevole quando una replica di lettura tra regioni è in notevole ritardo.
Per ulteriori informazioni sul monitoraggio di un'istanza DB con, consulta. CloudWatch Monitoraggio Amazon RDS metriche con Amazon CloudWatch
