Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica dell'importazione di dati dai dati di Amazon S3
Per importare i dati S3 in Amazon RDS
Raccogli innanzitutto i dettagli che devi fornire alla funzione. Questi includono il nome della tabella sull'istanza del cluster percorso del file, il tipo di file e dove sono archiviati i dati di Amazon S3. Regione AWS Per ulteriori informazioni, consulta Visualizzazione di un oggetto nella Guida per l'utente di Servizio di archiviazione semplice Amazon.
Nota
L'importazione in più parti da Amazon S3 non è attualmente supportata.
Otteni il nome della tabella in cui la funzione
aws_s3.table_import_from_s3deve importare dati. Il seguente comando, ad esempio, crea una tabellat1che può essere utilizzata in fasi successive.postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));Ottieni i dettagli relativi al bucket Amazon S3 e i dati da importare. A tale scopo, apri la console Amazon S3 all'indirizzo e scegli https://console.aws.amazon.com/s3/
Bucket. Individua il bucket contenente i dati nell'elenco. Scegli il bucket, apri la pagina Object overview (Panoramica degli oggetti) e quindi scegli Properties (Proprietà). Prendi nota del nome, del percorso, del e del tipo di file del Regione AWS bucket. Il nome della risorsa Amazon (ARN) è richiesto in un secondo momento per configurare l'accesso ad Amazon S3 tramite un ruolo IAM. Per ulteriori informazioni, consulta Configurazione dell'accesso a un bucket Simple Storage Service (Amazon S3). Un esempio è illustrato nell'immagine seguente.
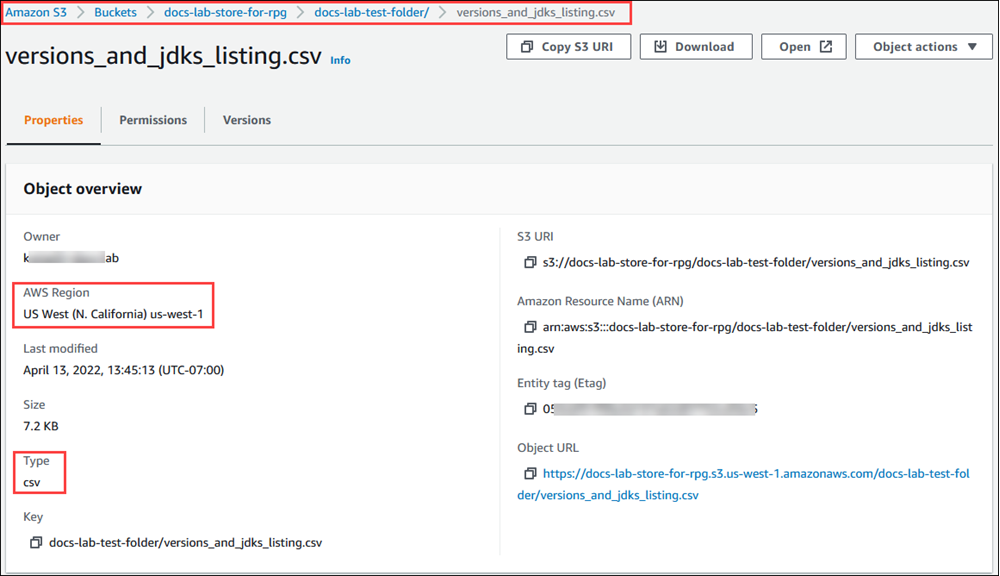
Puoi verificare il percorso dei dati nel bucket Amazon S3 utilizzando il comando. AWS CLI
aws s3 cpSe le informazioni sono corrette, questo comando scarica una copia del file Amazon S3.aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
Configura le autorizzazioni sull'istanza database RDS per PostgreSQL per consentire l'accesso al file sul bucket Amazon S3. A tale scopo, utilizzi un ruolo AWS Identity and Access Management (IAM) o credenziali di sicurezza. Per ulteriori informazioni, consulta Configurazione dell'accesso a un bucket Simple Storage Service (Amazon S3).
Fornisci alla funzione
create_s3_uriil percorso e gli altri dettagli dell'oggetto Amazon S3 raccolti (vedi passaggio 2) per costruire un oggetto URI Amazon S3. Per ulteriori informazioni su questa funzione, consulta aws_commons.create_s3_uri. Di seguito è riportato un esempio di costruzione dell'oggetto durante una sessione psql.postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gsetNella fase seguente, si passa questo oggetto (
aws_commons._s3_uri_1) alla funzioneaws_s3.table_import_from_s3per importare i dati nella tabella.-
Invoca la funzione
aws_s3.table_import_from_s3per importare dati da Amazon S3 nella tabella. Per informazioni di riferimento, consulta aws_s3.table_import_from_s3. Per alcuni esempi, consulta Importazione di dati da Amazon S3 alla tua istanza database .
