Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Integrazioni Zero-ETL di Aurora
È una soluzione completamente gestita per rendere disponibili i dati transazionali nella destinazione di analisi dopo la scrittura su un cluster di database Aurora. Estrazione, trasformazione e caricamento (ETL) è il processo di combinazione di dati provenienti da più origini in un grande data warehouse centrale.
Un’integrazione Zero-ETL rende disponibili i dati del cluster di database Aurora in Amazon Redshift o in un lakehouse Amazon SageMaker AI quasi in tempo reale. Una volta che i dati sono nel data warehouse o data lake di destinazione, puoi potenziare i tuoi carichi di lavoro di analisi, ML e intelligenza artificiale utilizzando le funzionalità integrate, come machine learning, viste materializzate, condivisione dei dati, accesso federato a più data store e data lake e integrazioni con SageMaker Amazon AI, Quick e altro. Servizi AWS
Per creare un’integrazione Zero-ETL, è necessario specificare un cluster di database Aurora come origine e un lakehouse o un data warehouse supportato come destinazione. L’integrazione replica i dati dal database di origine nel lakehouse o data warehouse di destinazione.
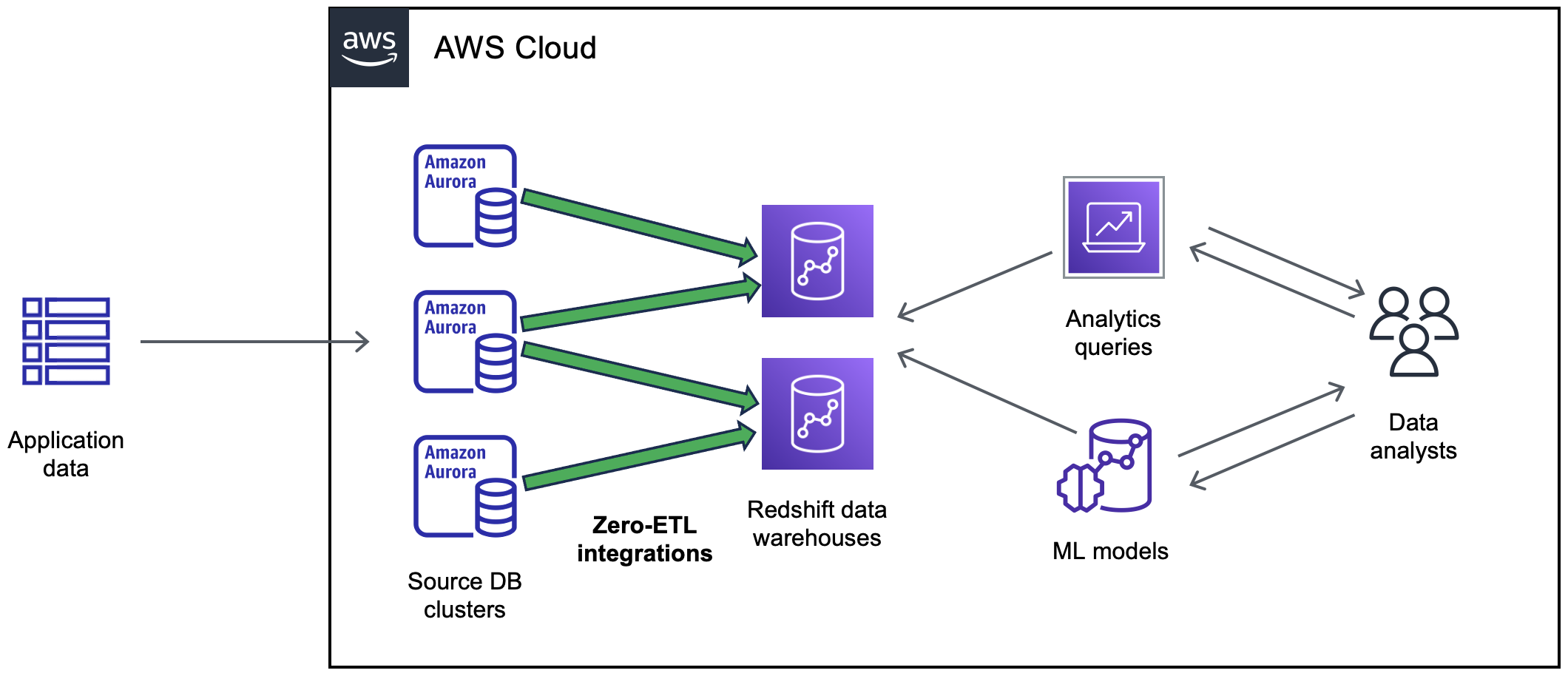
Il diagramma seguente illustra questa funzionalità per l’integrazione Zero-ETL con Amazon Redshift:
Il diagramma seguente illustra questa funzionalità per l’integrazione Zero-ETL con un Amazon SageMaker AI Lakehouse:
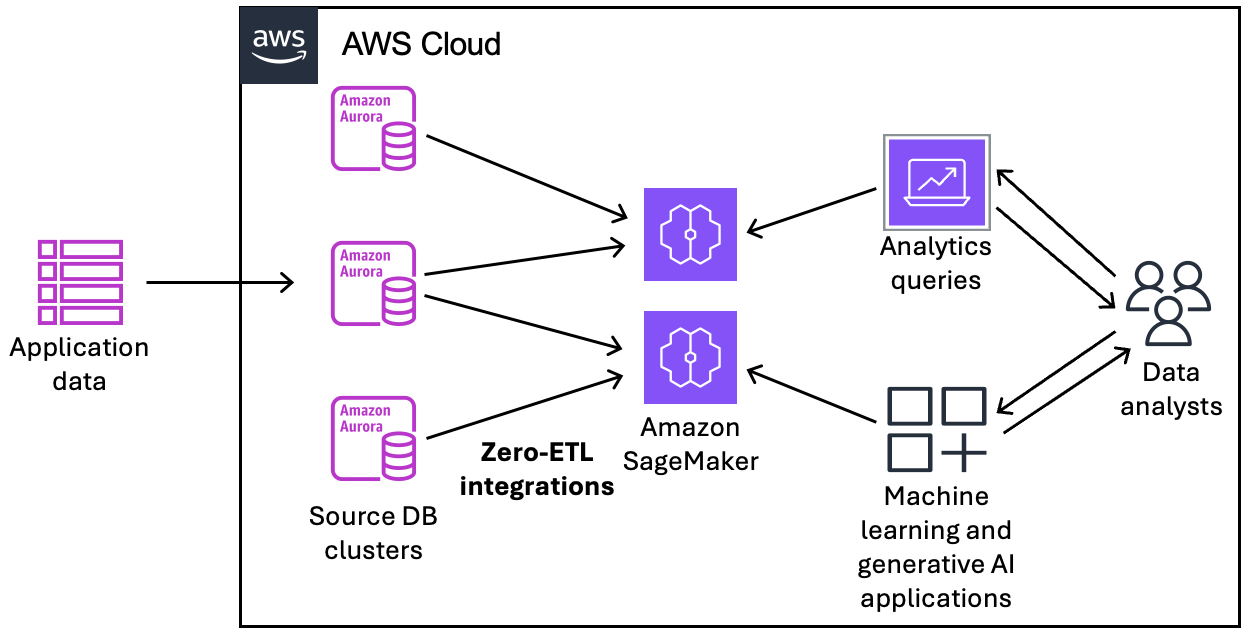
L’integrazione monitora lo stato della pipeline dei dati ed esegue il ripristino in caso di problemi quando possibile. Puoi creare integrazioni da più cluster di database Aurora in un unico lakehouse o data warehouse di destinazione così da ottenere informazioni dettagliate da diverse applicazioni.
Per ulteriori informazioni sul costo delle integrazioni Zero-ETL, consulta le pagine Prezzi di Amazon Aurora
Argomenti
Creazione di integrazioni Zero-ETL di Aurora con Amazon Redshift
Creazione di integrazioni Zero-ETL di Aurora con un lakehouse Amazon SageMaker
Aggiunta di dati a un cluster di database Aurora di origine ed esecuzione di query al suo interno
Visualizzazione e monitoraggio delle integrazioni Zero-ETL Aurora
Risoluzione dei problemi delle integrazioni Zero-ETL di Aurora
Vantaggi
Le integrazioni Zero-ETL di Aurora offrono i seguenti vantaggi:
-
Ti consentono di ottenere approfondimenti di tipo olistico da più origini dati.
-
Elimina la necessità di creare e mantenere pipeline di dati complesse che eseguano operazioni di estrazione, trasformazione e caricamento (ETL). Zero-ETL le integrazioni eliminano le sfide legate alla creazione e alla gestione delle pipeline fornendole e gestendole per te.
-
Ti consentono di ridurre il carico e i costi operativi e di concentrarti sul miglioramento delle applicazioni.
-
Puoi utilizzare le funzionalità di analisi e machine learning della destinazione per ricavare informazioni dettagliate da dati transazionali e di altro tipo e reagire in modo efficace in caso di eventi critici e urgenti.
Concetti chiave
Per iniziare a utilizzare le integrazioni Zero-ETL, tieni presente i seguenti concetti:
- Integrazione
-
Una pipeline dei dati completamente gestita che replica automaticamente i dati transazionali e gli schemi da un cluster di database Aurora a un data warehouse o un catalogo.
- Cluster di database di origine
-
Il cluster di database Aurora da cui viene eseguita la replica dei dati. È possibile specificare un cluster DB che utilizza istanze DB o Aurora serverless istanze DB assegnate come origine.
- Target
-
Si tratta del lakehouse o data warehouse in cui viene eseguita la replica dei dati. Esistono due tipi di data warehouse: un data warehouse con cluster con provisioning e un data warehouse serverless. Un data warehouse con cluster con provisioning è costituito da un insieme di risorse di calcolo denominate nodi, strutturate in un gruppo denominato cluster. Un data warehouse serverless è composto da un gruppo di lavoro che archivia le risorse di calcolo e da un spazio dei nomi che ospita gli oggetti e gli utenti del database. Entrambi i data warehouse utilizzano un motore di analisi e contengono uno o più database.
Un lakehouse di destinazione è costituito da cataloghi, database, tabelle e viste. Per ulteriori informazioni sull’architettura lakehouse, consulta SageMaker Lakehouse components nella Guida per l’utente di Amazon SageMaker AI Unified Studio.
Più cluster di database di destinazione possono scrivere nella stessa destinazione.
Per ulteriori informazioni sui nodi principali e sui nodi di calcolo, consulta Architettura del sistema di data warehouse nella Guida per sviluppatori di database di Amazon Redshift.
Limitazioni
Le seguenti limitazioni si applicano alle integrazioni Zero-ETL di Aurora.
Argomenti
Limitazioni generali
-
Il cluster di database di origine deve trovarsi nella stessa Regione della destinazione.
-
Non è possibile rinominare un cluster di database né alcuna delle sue istanze se include integrazioni esistenti.
-
Non è possibile creare più integrazioni tra gli stessi database di origine e destinazione.
-
Non è possibile eliminare un cluster di database con integrazioni esistenti. Devi prima eliminare tutte le integrazioni associate.
-
Se il cluster di database di origine viene arrestato, è possibile che le ultime transazioni non vengano replicate nella destinazione finché non si riprende il cluster.
-
Se il cluster di è l'origine di una blue/green distribuzione, gli ambienti blu e verde non possono avere integrazioni zero-ETL esistenti durante lo switchover. Occorre eliminare l’integrazione, eseguire lo switchover e poi ricrearla.
-
Un cluster di database deve contenere almeno un’istanza database per essere l’origine di un’integrazione.
-
Non è possibile creare un'integrazione per un cluster DB di origine che sia un clone tra più account, come quelli condivisi utilizzando (). AWS Resource Access Manager AWS RAM
-
Se il cluster di origine è il cluster database primario in un database globale Aurora e esegue il failover su uno dei relativi cluster secondari, l’integrazione diventa inattiva. È necessario eliminare e ricreare l’integrazione.
-
Non è possibile creare un’integrazione per un database di origine in cui un’altra integrazione è attivamente in fase di creazione.
-
Durante la fase iniziale della creazione di un’integrazione o quando una tabella viene risincronizzata, il seeding dei dati dall’origine alla destinazione può richiedere 20-25 minuti o più, a seconda delle dimensioni del database di origine. Ciò può causare un aumento del ritardo di replica.
-
Alcuni tipi di dati non sono supportati. Per ulteriori informazioni, consulta Differenze tra i tipi di dati tra i database Aurora e Amazon Redshift.
-
Le tabelle di sistema, le tabelle temporanee e le viste non vengono replicate nei warehouse di destinazione.
-
L’esecuzione di comandi DDL (ad esempio
ALTER TABLE) su una tabella di origine può attivare una risincronizzazione della tabella. Durante tale operazione non sarà possibile utilizzare la tabella per le query. Per ulteriori informazioni, consulta Una o più tabelle Amazon Redshift richiedono una risincronizzazione.
Aurora MySQL
-
Il cluster di database di origine deve eseguire una versione supportata di Aurora MySQL. Per un elenco delle versioni supportate, consulta Regioni e motori di database Aurora supportati per le integrazioni Zero-ETL.
-
Zero-ETL le integrazioni si basano sulla registrazione binaria di MySQL (binlog) per acquisire le continue modifiche ai dati. Il filtraggio dei dati basato su binlog è sconsigliato, poiché può causare incoerenze nei dati tra il database di origine e quello di destinazione.
-
Zero-ETL le integrazioni sono supportate solo per i database configurati per utilizzare il motore di archiviazione InnoDB.
-
I riferimenti a chiavi esterne con aggiornamenti di tabella predefiniti non sono supportati. In particolare, le regole
ON DELETEeON UPDATEnon sono supportate nelle operazioniCASCADE,SET NULLeSET DEFAULT. Se si tenta di creare o aggiornare una tabella con tali riferimenti a un’altra tabella, la tabella entrerà in uno stato di errore. -
Le transazioni XA
eseguite sul cluster di database di origine fanno sì che l’integrazione entri in uno stato di Syncing.
Limitazioni di Aurora PostgreSQL
-
Il cluster di database di origine deve eseguire una versione supportata di Aurora PostgreSQL. Per un elenco delle versioni supportate, consulta Regioni e motori di database Aurora supportati per le integrazioni Zero-ETL.
-
Se selezioni un cluster di database di origine Aurora PostgreSQL, è necessario specificare almeno un modello di filtro dei dati. Come minimo, il modello deve includere un singolo database (
database-name.*.* -
Tutti i database creati all'interno del cluster Aurora PostgreSQL DB di origine devono utilizzare la codifica. UTF-8
-
Quando utilizzi il partizionamento dichiarativo, le partizioni delle tabelle verranno replicate su Amazon Redshift. Tuttavia, la tabella partizionata stessa non viene replicata su Amazon Redshift.
-
Se elimini tutte le istanze database da un cluster di database che è l’origine di un’integrazione e successivamente aggiungi di nuovo un’istanza database, la replica tra il cluster di origine e quello di destinazione si interrompe.
-
Il cluster di database di origine non può utilizzare Aurora Limitless Database.
-
Le chiavi primarie sono obbligatorie su tutte le tabelle presenti nel filtro dati. Tutte le tabelle senza una chiave primaria verranno messe nello stato di errore.
Limitazioni di Amazon Redshift
Per un elenco delle limitazioni di Amazon Redshift relative alle integrazioni Zero-ETL, consulta la pagina delle Considerazioni sull’utilizzo delle integrazioni Zero-ETL con Amazon Redshift nella Guida alla gestione di Amazon Redshift.
Amazon SageMaker AI limitazioni di Lakehouse
Di seguito è riportata una limitazione per le integrazioni Amazon SageMaker AI Lakehouse Zero-ETL.
-
I nomi dei cataloghi hanno un limite di lunghezza di 19 caratteri.
Quote
Sul tuo account sono disponibili le seguenti quote relative alle integrazioni Zero-ETL di Aurora. Salvo dove diversamente specificato, ogni quota fa riferimento a una Regione specifica.
| Nome | Predefinito | Description |
|---|---|---|
| Integrazioni | 100 | Numero totale di integrazioni all’interno di un Account AWS. |
| Integrazioni per destinazione | 50 | Numero di integrazioni che inviano dati a un unico lakehouse o data warehouse di destinazione. |
| Integrazioni per cluster di origine | 5 | Numero di integrazioni che inviano dati da un unico cluster di database di origine. |
Inoltre, il warehouse di destinazione pone determinati limiti al numero di tabelle consentite in ogni istanza database o nodo del cluster. Per informazioni su quote e limiti di Amazon Redshift, consulta Quote e limiti in Amazon Redshift nella Guida alla gestione di Amazon Redshift.
Regioni supportate
Le integrazioni Aurora Zero-ETL sono disponibili in un sottoinsieme di. Regioni AWS Per un elenco delle regioni supportate, consulta Regioni e motori di database Aurora supportati per le integrazioni Zero-ETL.
