Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Limitazioni DDL e altre informazioni per Aurora PostgreSQL Limitless Database
I seguenti argomenti descrivono le limitazioni o forniscono ulteriori informazioni per i comandi SQL DDL in Aurora PostgreSQL Limitless Database.
Argomenti
ALTER TABLE
Il comando ALTER TABLE è generalmente supportato in Aurora PostgreSQL Limitless Database. Per ulteriori informazioni, consulta ALTER TABLE
Limitazioni
ALTER TABLE presenta le seguenti limitazioni per le opzioni supportate.
- Rimozione di una colonna
-
-
Nelle tabelle sottoposte a sharding, non puoi rimuovere le colonne che fanno parte della chiave shard.
-
Nelle tabelle di riferimento, non puoi rimuovere le colonne che fanno parte della chiave primaria.
-
- Modifica del tipo di dati di una colonna
-
-
L’espressione
USINGnon è supportata. -
Nelle tabelle sottoposte a sharding, non puoi modificare il tipo delle colonne che fanno parte della chiave shard.
-
- Aggiunta o rimozione di un vincolo
-
Per i dettagli sulle opzioni non supportate, consulta Vincoli.
- Modifica del valore predefinito di una colonna
-
I valori predefiniti sono supportati. Per ulteriori informazioni, consulta Valori predefiniti.
Opzioni non supportate
Alcune opzioni non sono supportate perché dipendono da funzionalità non disponibili, come i trigger.
Le seguenti opzioni a livello di tabella per ALTER TABLE non sono supportate:
-
ALL IN TABLESPACE -
ATTACH PARTITION -
DETACH PARTITION -
Flag
ONLY -
RENAME CONSTRAINT
Le seguenti opzioni a livello di colonna per ALTER TABLE non sono supportate:
-
ADD GENERATED
-
DROP EXPRESSION [ IF EXISTS ]
-
DROP IDENTITY [ IF EXISTS ]
-
RESET
-
RESTART
-
SET
-
SET COMPRESSION
-
SET STATISTICS
CREATE DATABASE
In Aurora PostgreSQL Limitless Database sono supportati solo Limitless Database.
Durante l’esecuzione di CREATE DATABASE, i database creati correttamente in uno o più nodi potrebbero non riuscire a essere creati negli altri nodi, poiché la creazione del database è un’operazione non transazionale. In questo caso, gli oggetti del database creati correttamente vengono rimossi automaticamente da tutti i nodi entro un periodo di tempo predeterminato per mantenere la coerenza nel gruppo shard database. Durante questo intervallo di tempo, un nuovo tentativo di creazione di un database con lo stesso nome potrebbe generare un errore che indica che il database esiste già.
Sono supportate le seguenti opzioni:
-
Regola di confronto:
CREATE DATABASEnameWITH [LOCALE =locale] [LC_COLLATE =lc_collate] [LC_CTYPE =lc_ctype] [ICU_LOCALE =icu_locale] [ICU_RULES =icu_rules] [LOCALE_PROVIDER =locale_provider] [COLLATION_VERSION =collation_version]; -
CREATE DATABASE WITH OWNER:CREATE DATABASEnameWITH OWNER =user_name;
Le seguenti opzioni non sono supportate:
-
CREATE DATABASE WITH TABLESPACE:CREATE DATABASEnameWITH TABLESPACE =tablespace_name; -
CREATE DATABASE WITH TEMPLATE:CREATE DATABASEnameWITH TEMPLATE =template;
CREATE INDEX
CREATE INDEX CONCURRENTLY è supportata per le tabelle sottoposte a sharding:
CREATE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX è supportata per tutti i tipi di tabella:
CREATE UNIQUE INDEXindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX CONCURRENTLY non è supportata:
CREATE UNIQUE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
Per ulteriori informazioni, consulta UNIQUE. Per informazioni generali sulla creazione di indici, consulta CREATE INDEX
- Visualizzazione degli indici
-
Non tutti gli indici sono visibili sui router quando utilizzi
\do comandi simili. In alternativa, utilizza la vistatable_namepg_catalog.pg_indexesper ottenere gli indici, come mostrato nell’esempio seguente.SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"id"}'; CREATE TABLE items (id int PRIMARY KEY, val int); CREATE INDEX items_my_index on items (id, val); postgres_limitless=> SELECT * FROM pg_catalog.pg_indexes WHERE tablename='items'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+----------------+------------+------------------------------------------------------------------------ public | items | items_my_index | | CREATE INDEX items_my_index ON ONLY public.items USING btree (id, val) public | items | items_pkey | | CREATE UNIQUE INDEX items_pkey ON ONLY public.items USING btree (id) (2 rows)
CREATE SCHEMA
CREATE SCHEMA con un elemento dello schema non è supportato:
CREATE SCHEMAmy_schemaCREATE TABLE (column_nameINT);
Questa opzione genera un errore simile al seguente:
ERROR: CREATE SCHEMA with schema elements is not supported
CREATE TABLE
Le relazioni nelle istruzioni CREATE TABLE non sono supportate, ad esempio:
CREATE TABLE orders (orderid int, customerId int, orderDate date) WITH (autovacuum_enabled = false);
Le colonne IDENTITY non sono supportate, ad esempio:
CREATE TABLE orders (orderid INT GENERATED ALWAYS AS IDENTITY);
Aurora PostgreSQL Limitless Database supporta fino a 54 caratteri per i nomi di tabelle sottoposte a sharding.
CREATE TABLE AS
Per creare una tabella utilizzando CREATE TABLE AS, è necessario utilizzare la variabile rds_aurora.limitless_create_table_mode. Per le tabelle sottoposte a sharding, è necessario utilizzare anche la variabile rds_aurora.limitless_create_table_shard_key. Per ulteriori informazioni, consulta Creazione di tabelle Limitless utilizzando variabili.
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; CREATE TABLE ctas_table AS SELECT 1 a; -- "source" is the source table whose columns and data types are used to create the new "ctas_table2" table. CREATE TABLE ctas_table2 AS SELECT a,b FROM source;
Non puoi utilizzare CREATE TABLE AS per creare tabelle di riferimento, poiché richiedono vincoli di chiave primaria. CREATE TABLE
AS non propaga le chiavi primarie alle nuove tabelle.
Per ulteriori informazioni, consulta CREATE DATABASE
DROP DATABASE
Puoi eliminare i database creati.
Il comando DROP DATABASE viene eseguito in background in modo asincrono. Durante l’esecuzione, riceverai un errore se provi a creare un nuovo database con lo stesso nome.
SELECT INTO
SELECT INTO è funzionalmente simile a CREATE TABLE AS. Devi utilizzare la variabile rds_aurora.limitless_create_table_mode. Per le tabelle sottoposte a sharding, è necessario utilizzare anche la variabile rds_aurora.limitless_create_table_shard_key. Per ulteriori informazioni, consulta Creazione di tabelle Limitless utilizzando variabili.
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; -- "source" is the source table whose columns and data types are used to create the new "destination" table. SELECT * INTO destination FROM source;
Attualmente, l’operazione SELECT INTO viene eseguita tramite il router, non direttamente tramite gli shard. Di conseguenza, le prestazioni possono essere lente.
Per ulteriori informazioni, consulta SELECT INTO
Vincoli
Le seguenti limitazioni si applicano ai vincoli in Aurora PostgreSQL Limitless Database.
- CHECK
-
Sono supportati vincoli semplici che coinvolgono operatori di confronto con valori letterali. Le espressioni e i vincoli più complessi che richiedono convalide delle funzioni non sono supportati, come illustrato negli esempi seguenti.
CREATE TABLE my_table ( id INT CHECK (id > 0) -- supported , val INT CHECK (val > 0 AND val < 1000) -- supported , tag TEXT CHECK (length(tag) > 0) -- not supported: throws "Expression inside CHECK constraint is not supported" , op_date TIMESTAMP WITH TIME ZONE CHECK (op_date <= now()) -- not supported: throws "Expression inside CHECK constraint is not supported" );Puoi assegnare nomi espliciti ai vincoli, come illustrato nell’esempio seguente.
CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , val INT CONSTRAINT val_in_range CHECK (val > 0 AND val < 1000) );Puoi utilizzare la sintassi dei vincoli a livello di tabella con il vincolo
CHECK, come illustrato nell’esempio seguente.CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , min_val INT CONSTRAINT min_val_in_range CHECK (min_val > 0 AND min_val < 1000) , max_val INT , CONSTRAINT max_val_in_range CHECK (max_val > 0 AND max_val < 1000 AND max_val > min_val) ); - EXCLUDE
-
I vincoli di esclusione non sono supportati in Aurora PostgreSQL Limitless Database.
- FOREIGN KEY
-
Per ulteriori informazioni, consulta Chiavi esterne.
- NOT NULL
-
I vincoli
NOT NULLnon sono supportati senza restrizioni. - PRIMARY KEY
-
La chiave primaria implica vincoli univoci e pertanto si applicano le stesse restrizioni sui vincoli unici alla chiave primaria. Ciò significa che:
-
Se una tabella viene convertita in una tabella sottoposta a sharding, la chiave shard deve essere un sottoinsieme della chiave primaria. Vale a dire, la chiave primaria contiene tutte le colonne della chiave shard.
-
Se una tabella viene convertita in una tabella di riferimento, deve avere una chiave primaria.
Negli esempi seguenti viene illustrato l’uso delle chiavi primarie.
-- Create a standard table. CREATE TABLE public.my_table ( item_id INT , location_code INT , val INT , comment text ); -- Change the table to a sharded table using the 'item_id' and 'location_code' columns as shard keys. CALL rds_aurora.limitless_alter_table_type_sharded('public.my_table', ARRAY['item_id', 'location_code']);Tentativo di aggiungere una chiave primaria che non contiene una chiave shard:
-- Add column 'item_id' as the primary key. -- Invalid because the primary key doesnt include all columns from the shard key: -- 'location_code' is part of the shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERROR -- add column "val" as primary key -- Invalid because primary key does not include all columns from shard key: -- item_id and location_code iare part of shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERRORTentativo di aggiungere una chiave primaria che contiene una chiave shard:
-- Add the 'item_id' and 'location_code' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code); -- OK -- Add the 'item_id', 'location_code', and 'val' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code, val); -- OKConversione di una tabella standard in tabella di riferimento.
-- Create a standard table. CREATE TABLE zipcodes (zipcode INT PRIMARY KEY, details VARCHAR); -- Convert the table to a reference table. CALL rds_aurora.limitless_alter_table_type_reference('public.zipcode');Per ulteriori informazioni sulla creazione di tabelle sottoposte a sharding e di riferimento, consulta Creazione di tabelle di Aurora PostgreSQL Limitless Database.
-
- UNIQUE
-
Nelle tabelle sottoposte a sharding, la chiave univoca deve contenere la chiave shard, ovvero la chiave shard deve essere un sottoinsieme della chiave univoca. Questa condizione viene verificata durante la conversione del tipo di tabella in sottoposta a sharding. Nelle tabelle di riferimento non sono presenti restrizioni.
CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT UNIQUE );Table-level
UNIQUEi vincoli sono supportati, come illustrato nell'esempio seguente.CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT , CONSTRAINT zipcode_and_email UNIQUE (zipcode, email) );L’esempio seguente mostra l’uso combinato di una chiave primaria e una chiave univoca. Entrambe le chiavi devono includere la chiave shard.
SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"p_id"}'; CREATE TABLE t1 ( p_id BIGINT NOT NULL, c_id BIGINT NOT NULL, PRIMARY KEY (p_id), UNIQUE (p_id, c_id) );
Per ulteriori informazioni, consulta Vincoli
Valori predefiniti
Aurora PostgreSQL Limitless Database supporta espressioni nei valori predefiniti.
L’esempio seguente mostra l’uso dei valori predefiniti.
CREATE TABLE t ( a INT DEFAULT 5, b TEXT DEFAULT 'NAN', c NUMERIC ); CALL rds_aurora.limitless_alter_table_type_sharded('t', ARRAY['a']); INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c ---+-----+--- 5 | NAN | (1 row)
Le espressioni sono supportate, come illustrato nell’esempio seguente.
CREATE TABLE t1 (a NUMERIC DEFAULT random());
Nell’esempio seguente viene aggiunta una nuova colonna che è NOT NULL e ha un valore predefinito.
ALTER TABLE t ADD COLUMN d BOOLEAN NOT NULL DEFAULT FALSE; SELECT * FROM t; a | b | c | d ---+-----+---+--- 5 | NAN | | f (1 row)
L’esempio seguente modifica una colonna esistente con un valore predefinito.
ALTER TABLE t ALTER COLUMN c SET DEFAULT 0.0; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f (2 rows)
L’esempio seguente rimuove un valore predefinito.
ALTER TABLE t ALTER COLUMN a DROP DEFAULT; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f | NAN | 0.0 | f (3 rows)
Per ulteriori informazioni, consulta Valori predefiniti
Estensioni
Le seguenti estensioni PostgreSQL sono supportate in Aurora PostgreSQL Limitless Database:
-
aurora_limitless_fdw: questa estensione è preinstallata. e non può essere rimossa. -
aws_s3: questa estensione funziona in Aurora PostgreSQL Limitless Database in modo simile ad Aurora PostgreSQL.Puoi importare dati da un bucket Amazon S3 in un cluster di database Aurora PostgreSQL Limitless Database oppure esportare dati da un cluster di database Aurora PostgreSQL Limitless Database in un bucket Amazon S3. Per ulteriori informazioni, consultare Importazione di dati da Amazon S3 in un cluster database Aurora PostgreSQL e Esportazione di dati da del cluster di database Aurora PostgreSQLRDS per PostgreSQL a Amazon S3.
-
btree_gin -
citext -
ip4r -
pg_buffercache: questa estensione si comporta in modo diverso in Aurora PostgreSQL Limitless Database rispetto alla versione Community PostgreSQL. Per ulteriori informazioni, consulta Differenze di pg_buffercache in Aurora PostgreSQL Limitless Database. -
pg_stat_statements -
pg_trgm -
pgcrypto -
pgstattuple: questa estensione si comporta in modo diverso in Aurora PostgreSQL Limitless Database rispetto alla versione Community PostgreSQL. Per ulteriori informazioni, consulta Differenze di pgstattuple in Aurora PostgreSQL Limitless Database. -
pgvector -
plpgsql: questa estensione è preinstallata, ma puoi rimuoverla. -
PostGIS: le transazioni lunghe e le funzioni di gestione delle tabelle non sono supportate. La modifica della tabella di riferimento spaziale non è supportata. -
unaccent -
uuid
La maggior parte delle estensioni PostgreSQL non è attualmente supportata in Aurora PostgreSQL Limitless Database. Tuttavia, puoi comunque utilizzare l’impostazione della configurazione shared_preload_libraries
Ad esempio, puoi caricare l’estensione pg_hint_plan, ma il suo caricamento non garantisce che vengano utilizzati i suggerimenti passati nei commenti delle query.
Nota
Non puoi modificare gli oggetti associati all’estensione pg_stat_statementspg_stat_statements, consulta limitless_stat_statements.
Puoi utilizzare le funzioni pg_available_extensions e pg_available_extension_versions per trovare le estensioni supportate in Aurora PostgreSQL Limitless Database.
Le seguenti istruzioni DDL sono supportate per le estensioni:
- CREATE EXTENSION
-
Puoi creare estensioni, come in PostgreSQL.
CREATE EXTENSION [ IF NOT EXISTS ]extension_name[ WITH ] [ SCHEMAschema_name] [ VERSIONversion] [ CASCADE ]Per ulteriori informazioni, consulta CREATE EXTENSION
nella documentazione di PostgreSQL. - ALTER EXTENSION
-
Le seguenti istruzioni DDL sono supportate:
ALTER EXTENSIONnameUPDATE [ TOnew_version] ALTER EXTENSIONnameSET SCHEMAnew_schemaPer ulteriori informazioni, consulta ALTER EXTENSION
nella documentazione di PostgreSQL. - DROP EXTENSION
-
Puoi rimuovere le estensioni, come in PostgreSQL.
DROP EXTENSION [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]Per ulteriori informazioni, consulta DROP EXTENSION
nella documentazione di PostgreSQL.
Le seguenti istruzioni DDL non sono supportate per le estensioni:
- ALTER EXTENSION
-
Non puoi aggiungere o rimuovere oggetti membri delle estensioni.
ALTER EXTENSIONnameADDmember_objectALTER EXTENSIONnameDROPmember_object
Differenze di pg_buffercache in Aurora PostgreSQL Limitless Database
In Aurora PostgreSQL Limitless Database, quando installi l’estensione pg_buffercachepg_buffercache, ricevi informazioni relative al buffer solo dal nodo a cui sei hai attualmente effettuato la connessione: il router. Allo stesso modo, l’uso della funzione pg_buffercache_summary o pg_buffercache_usage_counts fornisce informazioni solo dal nodo connesso.
Puoi disporre di numerosi nodi e potresti aver bisogno di accedere alle informazioni del buffer da qualsiasi nodo per diagnosticare i problemi in modo efficace. Pertanto, Aurora PostgreSQL Limitless Database fornisce le seguenti funzioni:
-
rds_aurora.limitless_pg_buffercache(subcluster_id) -
rds_aurora.limitless_pg_buffercache_summary(subcluster_id) -
rds_aurora.limitless_pg_buffercache_usage_counts(subcluster_id)
Inserendo l’ID cluster secondario di qualsiasi nodo, che si tratti di un router o di uno shard, puoi accedere facilmente alle informazioni del buffer specifiche di quel nodo. Queste funzioni sono disponibili subito dopo l’installazione dell’estensione pg_buffercache nel Limitless Database.
Nota
Aurora PostgreSQL Limitless Database supporta queste funzioni per la versione 1.4 e successive dell’estensione pg_buffercache.
Le colonne mostrate nella vista limitless_pg_buffercache differiscono leggermente da quelle nella vista pg_buffercache:
-
bufferid: rimane invariata rispetto apg_buffercache. -
relname: invece di mostrare il numero di nodo del file come inpg_buffercache,limitless_pg_buffercachepresenta il valorerelnameassociato, se disponibile, nel database attuale o nei cataloghi del sistema condiviso, altrimentiNULL. -
parent_relname: questa nuova colonna, non presente inpg_buffercache, mostra il valorerelnameprincipale se il valore nella colonnarelnamerappresenta una tabella partizionata (nel caso di tabelle sottoposte a sharding). Altrimenti, mostraNULL. -
spcname: invece di mostrare l’identificatore dell’oggetto tablespace (OID) come inpg_buffercache,limitless_pg_buffercachemostra il nome del tablespace. -
datname: invece di mostrare l’OID del database come inpg_buffercache,limitless_pg_buffercachemostrare il nome del database. -
relforknumber: rimane invariata rispetto apg_buffercache. -
relblocknumber: rimane invariata rispetto apg_buffercache. -
isdirty: rimane invariata rispetto apg_buffercache. -
usagecount: rimane invariata rispetto apg_buffercache. -
pinning_backends: rimane invariata rispetto apg_buffercache.
Le colonne nelle viste limitless_pg_buffercache_summary e limitless_pg_buffercache_usage_counts sono le stesse di quelle presenti nelle normali viste pg_buffercache_summary e pg_buffercache_usage_counts, rispettivamente.
Tramite queste funzioni, puoi accedere a informazioni dettagliate sulla cache del buffer in tutti i nodi dell’ambiente Aurora PostgreSQL Limitless Database, facilitando una diagnosi e una gestione più efficaci dei sistemi di database.
Differenze di pgstattuple in Aurora PostgreSQL Limitless Database
In Aurora PostgreSQL, l’estensione pgstattuple
Riconosciamo l’importanza di questa estensione per ottenere statistiche a livello di tuple, fondamentali per attività come la rimozione del bloat e la raccolta di informazioni diagnostiche. Pertanto, Aurora PostgreSQL Limitless Database fornisce supporto per l’estensione pgstattuple nei Limitless Database.
Aurora PostgreSQL Limitless Database include le seguenti funzioni nello schema rds_aurora:
- Tuple-level funzioni statistiche
-
rds_aurora.limitless_pgstattuple(relation_name)-
Scopo: estrarre statistiche a livello di tuple per le tabelle standard e i relativi indici
-
Input:
relation_name(testo): il nome della relazione -
Output: colonne coerenti con quelle restituite dalla funzione
pgstattuplein Aurora PostgreSQL
rds_aurora.limitless_pgstattuple(relation_name,subcluster_id)-
Scopo: estrarre statistiche a livello di tuple per le tabelle di riferimento, le tabelle sottoposte a sharding, le tabelle di catalogo e i relativi indici
-
Input:
-
relation_name(testo): il nome della relazione -
subcluster_id(testo): l’ID cluster secondario del nodo da cui estrarre le statistiche
-
-
Output:
-
Per le tabelle di riferimento e di catalogo (inclusi i relativi indici), le colonne sono coerenti con Aurora PostgreSQL.
-
Per le tabelle sottoposte a sharding, le statistiche rappresentano solo la partizione della tabella sottoposta a sharding che risiede nel cluster secondario specificato.
-
-
- Funzioni di statistiche sugli indici
-
rds_aurora.limitless_pgstatindex(relation_name)-
Scopo: Estrarre le statistiche per B-tree gli indici su tabelle standard
-
Input:
relation_name(text) — Il nome dell'indice B-tree -
Output: vengono restituite tutte le colonne tranne
root_block_no. Le colonne restituite sono coerenti con la funzionepgstatindexin Aurora PostgreSQL.
rds_aurora.limitless_pgstatindex(relation_name,subcluster_id)-
Scopo: Estrarre le statistiche per B-tree gli indici nelle tabelle di riferimento, nelle tabelle ripartite e nelle tabelle del catalogo.
-
Input:
-
relation_name(testo) — Il nome dell'indice B-tree -
subcluster_id(testo): l’ID cluster secondario del nodo da cui estrarre le statistiche
-
-
Output:
-
Per gli indici delle tabelle di riferimento e di catalogo, vengono restituite tutte le colonne (tranne
root_block_no). Le colonne restituite sono coerenti con Aurora PostgreSQL. -
Per le tabelle sottoposte a sharding, le statistiche rappresentano solo la partizione dell’indice della tabella sottoposta a sharding che risiede nel cluster secondario specificato. La colonna
tree_levelmostra la media di tutte le sezioni di tabella del cluster secondario richiesto.
-
rds_aurora.limitless_pgstatginindex(relation_name)-
Scopo: estrarre le statistiche per gli indici invertiti generalizzati (GIN) su tabelle standard
-
Input:
relation_name(testo): il nome del GIN -
Output: colonne coerenti con quelle restituite dalla funzione
pgstatginindexin Aurora PostgreSQL
rds_aurora.limitless_pgstatginindex(relation_name,subcluster_id)-
Scopo: estrarre le statistiche per gli indici GIN su tabelle di riferimento, tabelle sottoposte a sharding e tabelle di catalogo.
-
Input:
-
relation_name(testo): il nome dell’indice -
subcluster_id(testo): l’ID cluster secondario del nodo da cui estrarre le statistiche
-
-
Output:
-
Per gli indici GIN di tabelle di riferimento e catalogo, le colonne sono coerenti con Aurora PostgreSQL.
-
Per le tabelle sottoposte a sharding, le statistiche rappresentano solo la partizione dell’indice della tabella sottoposta a sharding che risiede nel cluster secondario specificato.
-
rds_aurora.limitless_pgstathashindex(relation_name)-
Scopo: estrarre le statistiche per gli indici hash su tabelle standard
-
Input:
relation_name(testo): il nome del indice hash -
Output: colonne coerenti con quelle restituite dalla funzione
pgstathashindexin Aurora PostgreSQL
rds_aurora.limitless_pgstathashindex(relation_name,subcluster_id)-
Scopo: estrarre le statistiche per gli indici hash su tabelle di riferimento, tabelle sottoposte a sharding e tabelle di catalogo.
-
Input:
-
relation_name(testo): il nome dell’indice -
subcluster_id(testo): l’ID cluster secondario del nodo da cui estrarre le statistiche
-
-
Output:
-
Per gli indici hash di tabelle di riferimento e catalogo, le colonne sono coerenti con Aurora PostgreSQL.
-
Per le tabelle sottoposte a sharding, le statistiche rappresentano solo la partizione dell’indice della tabella sottoposta a sharding che risiede nel cluster secondario specificato.
-
-
- Funzioni di conteggio delle pagine
-
rds_aurora.limitless_pg_relpages(relation_name)-
Scopo: estrarre il conteggio delle pagine per le tabelle standard e i relativi indici
-
Input:
relation_name(testo): il nome della relazione -
Output: conteggio di pagine della relazione specificata
rds_aurora.limitless_pg_relpages(relation_name,subcluster_id)-
Scopo: estrarre il conteggio delle pagine per le tabelle di riferimento, le tabelle sottoposte a sharding e le tabelle di catalogo (inclusi i relativi indici)
-
Input:
-
relation_name(testo): il nome della relazione -
subcluster_id(testo): l’ID cluster secondario del nodo da cui estrarre il conteggio delle pagine
-
-
Output: per le tabelle sottoposte a sharding, il conteggio delle pagine è la somma delle pagine di tutte le sezioni della tabella sul cluster secondario specificato.
-
- Funzioni di statistiche approssimate a livello di tuple
-
rds_aurora.limitless_pgstattuple_approx(relation_name)-
Scopo: estrarre statistiche approssimative a livello di tuple per le tabelle standard e i relativi indici
-
Input:
relation_name(testo): il nome della relazione -
Output: colonne coerenti con quelle restituite dalla funzione pgstattuple_approx in Aurora PostgreSQL
rds_aurora.limitless_pgstattuple_approx(relation_name,subcluster_id)-
Scopo: estrarre statistiche approssimate a livello di tuple per le tabelle di riferimento, le tabelle sottoposte a sharding e le tabelle di catalogo (inclusi i relativi indici)
-
Input:
-
relation_name(testo): il nome della relazione -
subcluster_id(testo): l’ID cluster secondario del nodo da cui estrarre le statistiche
-
-
Output:
-
Per le tabelle di riferimento e di catalogo (inclusi i relativi indici), le colonne sono coerenti con Aurora PostgreSQL.
-
Per le tabelle sottoposte a sharding, le statistiche rappresentano solo la partizione della tabella sottoposta a sharding che risiede nel cluster secondario specificato.
-
-
Nota
Attualmente, Aurora PostgreSQL Limitless Database non supporta l’estensione pgstattuple su viste materializzate, tabelle TOAST o tabelle temporanee.
In Aurora PostgreSQL Limitless Database, è necessario fornire l’input come testo, sebbene Aurora PostgreSQL supporti altri formati.
Chiavi esterne
I vincoli di chiave esterna (FOREIGN KEY) sono supportati con alcune limitazioni:
-
CREATE TABLEconFOREIGN KEYè supportato solo per le tabelle standard. Per creare una tabella sottoposta a sharding o una tabella di riferimento conFOREIGN KEY, create innanzitutto la tabella senza un vincolo di chiave esterna. Successivamente, modificala utilizzando la seguente istruzione:ALTER TABLE ADD CONSTRAINT; -
La conversione di una tabella standard in una tabella sottoposta a sharding o di riferimento non è supportata se la tabella possiede un vincolo di chiave esterna. Rimuovi il vincolo, quindi aggiungilo dopo la conversione.
-
Le seguenti limitazioni si applicano ai tipi di tabella per i vincoli di chiave esterna:
-
Una tabella standard può avere un vincolo di chiave esterna rispetto a un’altra tabella standard.
-
Una tabella sottoposta a sharding può avere un vincolo di chiave esterna se le tabelle principale e secondaria sono co-localizzate e la chiave esterna è un superset della chiave shard.
-
Una tabella sottoposta a sharding può avere un vincolo di chiave esterna rispetto a una tabella di riferimento.
-
Una tabella di riferimento può avere un vincolo di chiave esterna rispetto a un’altra tabella di riferimento.
-
Argomenti
Opzioni di chiave esterna
Le chiavi esterne sono supportate in Aurora PostgreSQL Limitless Database per alcune opzioni DDL. La tabella seguente elenca le opzioni supportate e non supportate tra le tabelle di Aurora PostgreSQL Limitless Database:
| Opzione DDL | Da riferimento a riferimento | Da sottoposta a sharding a sottoposta a sharding (co-localizzate) | Da sottoposta a sharding a riferimento | Da standard a standard |
|---|---|---|---|---|
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
No | No | No | No |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | No | No | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
No | No | No | No |
|
|
Sì | No | No | Sì |
|
|
No | No | No | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
Sì | Sì | Sì | Sì |
|
|
No | No | No | No |
|
|
Sì | No | No | Sì |
Esempi
-
Da standard a standard:
set rds_aurora.limitless_create_table_mode='standard'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer REFERENCES products (product_no), quantity integer ); SELECT constraint_name, table_name, constraint_type FROM information_schema.table_constraints WHERE constraint_type='FOREIGN KEY'; constraint_name | table_name | constraint_type -------------------------+-------------+----------------- orders_product_no_fkey | orders | FOREIGN KEY (1 row) -
Da sottoposta a sharding a sottoposta a sharding (co-localizzate):
set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"product_no"}'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; set rds_aurora.limitless_create_table_collocate_with='products'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
Da sottoposta a sharding a riferimento:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
Da riferimento a riferimento:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no);
Funzioni
Le funzioni sono supportate in Aurora PostgreSQL Limitless Database.
I seguenti DDL sono supportati per le funzioni:
- CREATE FUNCTION
-
Puoi creare funzioni, come in Aurora PostgreSQL, con l’eccezione di modificarne la volatilità durante la sostituzione.
Per ulteriori informazioni, consulta CREATE FUNCTION
nella documentazione di PostgreSQL. - ALTER FUNCTION
-
Puoi creare funzioni, come in Aurora PostgreSQL, con l’eccezione di modificarne la volatilità.
Per ulteriori informazioni, consulta ALTER FUNCTION
nella documentazione di PostgreSQL. - DROP FUNCTION
-
Puoi rimuovere le funzioni, come in Aurora PostgreSQL.
DROP FUNCTION [ IF EXISTS ]name[ ( [ [argmode] [argname]argtype[, ...] ] ) ] [, ...] [ CASCADE | RESTRICT ]Per ulteriori informazioni, consulta DROP FUNCTION
nella documentazione di PostgreSQL.
Distribuzione delle funzioni
Quando tutte le istruzioni di una funzione sono indirizzate a un singolo shard, è conveniente eseguire l’intera funzione direttamente sullo shard di destinazione. In questo modo il risultato viene propagato al router, invece di eseguire la funzione direttamente sul router stesso. La capacità di pushdown di funzioni e stored procedure è utile per i clienti che desiderano eseguire la funzione o la stored procedure più vicino all’origine dati, ovvero allo shard.
Per distribuire una funzione, è necessario innanzitutto creare la funzione, quindi chiamare la procedura rds_aurora.limitless_distribute_function per distribuirla. Questa funzione usa la seguente sintassi:
SELECT rds_aurora.limitless_distribute_function('function_prototype', ARRAY['shard_key'], 'collocating_table');
La funzione accetta i seguenti parametri:
-
function_prototypeSe uno qualsiasi degli argomenti è definito come parametro
OUT, non includerne il tipo negli argomenti difunction_prototype. -
ARRAY[': l’elenco degli argomenti della funzione identificati come chiave shard per la funzione.shard_key'] -
collocating_table
Per identificare lo shard su cui eseguire questa funzione, il sistema prende l’argomento ARRAY[', ne esegue l’hash e individua lo shard da shard_key']collocating_table
- Restrizioni
-
Quando distribuisci una funzione o una procedura, questa opera solo sui dati delimitati dall’intervallo di chiavi shard in tale shard. Se la funzione o la procedura tenta di accedere ai dati da un altro shard, i risultati restituiti dalla funzione o dalla procedura distribuita saranno diversi rispetto a una funzione non distribuita.
Ad esempio, crea una funzione contenente query che interessano più shard, ma poi chiama la procedura
rds_aurora.limitless_distribute_functionper distribuirla. Quando invochi questa funzione fornendo argomenti per una chiave shard, è probabile che i risultati della sua esecuzione siano limitati dai valori presenti in tale shard. Questi risultati sono diversi da quelli prodotti senza distribuire la funzione. - Esempi
-
Considera la seguente funzione
funccon la tabella sottoposta a shardingcustomerscon la chiave shardcustomer_id.postgres_limitless=> CREATE OR REPLACE FUNCTION func(c_id integer, sc integer) RETURNS int language SQL volatile AS $$ UPDATE customers SET score = sc WHERE customer_id = c_id RETURNING score; $$;Ora distribuiamo questa funzione:
SELECT rds_aurora.limitless_distribute_function('func(integer, integer)', ARRAY['c_id'], 'customers');Di seguito è riportato un esempio di piani di query.
EXPLAIN(costs false, verbose true) SELECT func(27+1,10); QUERY PLAN -------------------------------------------------- Foreign Scan Output: (func((27 + 1), 10)) Remote SQL: SELECT func((27 + 1), 10) AS func Single Shard Optimized (4 rows)EXPLAIN(costs false, verbose true) SELECT * FROM customers,func(customer_id, score) WHERE customer_id=10 AND score=27; QUERY PLAN --------------------------------------------------------------------- Foreign Scan Output: customer_id, name, score, func Remote SQL: SELECT customers.customer_id, customers.name, customers.score, func.func FROM public.customers, LATERAL func(customers.customer_id, customers.score) func(func) WHERE ((customers.customer_id = 10) AND (customers.score = 27)) Single Shard Optimized (10 rows)L’esempio seguente mostra una procedura con parametri
INeOUTcome argomenti.CREATE OR REPLACE FUNCTION get_data(OUT id INTEGER, IN arg_id INT) AS $$ BEGIN SELECT customer_id, INTO id FROM customer WHERE customer_id = arg_id; END; $$ LANGUAGE plpgsql;L’esempio seguente distribuisce la procedura utilizzando solo i parametri
IN.EXPLAIN(costs false, verbose true) SELECT * FROM get_data(1); QUERY PLAN ----------------------------------- Foreign Scan Output: id Remote SQL: SELECT customer_id FROM get_data(1) get_data(id) Single Shard Optimized (6 rows)
Volatilità della funzione
Puoi determinare se una funzione è immutabile, stabile o volatile controllando il valore provolatile nella vista pg_procprovolatile indica se il risultato della funzione dipende solo dai suoi argomenti di input o è influenzato da fattori esterni.
Il valore è uno dei seguenti:
-
i: funzioni immutabili, che restituiscono sempre lo stesso risultato per gli stessi input. -
s: funzioni stabili, i cui risultati (per input fissi) non cambiano durante una scansione. -
v: funzioni volatili, i cui risultati potrebbero cambiare in qualsiasi momento. Usavanche per funzioni con effetti collaterali, in modo che le chiamate non possano essere ottimizzate ed eliminate.
Gli esempi seguenti mostrano le funzioni volatili.
SELECT proname, provolatile FROM pg_proc WHERE proname='pg_sleep'; proname | provolatile ----------+------------- pg_sleep | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='uuid_generate_v4'; proname | provolatile ------------------+------------- uuid_generate_v4 | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='nextval'; proname | provolatile ---------+------------- nextval | v (1 row)
La modifica della volatilità di una funzione esistente non è supportata in Aurora PostgreSQL Limitless Database. Questo vale sia per i comandi ALTER FUNCTION che per i comandi CREATE OR REPLACE FUNCTION, come illustrato negli esempi seguenti.
-- Create an immutable function CREATE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$IMMUTABLE; -- Altering the volatility throws an error ALTER FUNCTION immutable_func1 STABLE; -- Replacing the function with altered volatility throws an error CREATE OR REPLACE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$VOLATILE;
Consigliamo vivamente di assegnare le volatilità corrette alle funzioni. Ad esempio, se la funzione utilizza SELECT da più tabelle o fa riferimento a oggetti del database, non impostarla come IMMUTABLE. Se il contenuto della tabella cambia, l’immutabilità viene compromessa.
Aurora PostgreSQL consente SELECT all’interno di funzioni immutabili, ma i risultati potrebbero essere errati. Aurora PostgreSQL Limitless Database può restituire sia errori sia risultati errati. Per ulteriori informazioni, consulta Function volatility categories
Sequenze
Le sequenze nominate sono oggetti di database che generano numeri univoci in ordine crescente o decrescente. CREATE SEQUENCE crea un nuovo generatore di numeri di sequenza. I valori di sequenza sono garantiti come univoci.
Quando crei una sequenza denominata in Aurora PostgreSQL Limitless Database, viene creato un oggetto di sequenza distribuita. Successivamente, Aurora PostgreSQL Limitless Database distribuisce blocchi di valori di sequenza non sovrapposti su tutti i Distributed Transaction Router (router). I blocchi sono rappresentati come oggetti di sequenza locale sui router; pertanto, le operazioni di sequenza come nextval e currval vengono eseguite localmente. I router operano in modo indipendente e richiedono nuovi blocchi dalla sequenza distribuita, quando necessario.
Per ulteriori informazioni sulle sequenze, consulta CREATE SEQUENCE
Argomenti
Richiesta di un nuovo blocco
Puoi configurare le dimensioni dei blocchi allocati sui router utilizzando il parametro rds_aurora.limitless_sequence_chunk_size. Il valore predefinito è 250000. Ogni router possiede inizialmente due blocchi: attivi e riservati. I blocchi attivi vengono utilizzati per configurare gli oggetti di sequenza locale (impostando minvalue emaxvalue) e i blocchi riservati vengono archiviati in una tabella interna del catalogo. Quando un blocco attivo raggiunge il valore minimo o massimo, viene sostituito dal blocco riservato. A tal fine, ALTER SEQUENCE viene utilizzato internamente, dunque AccessExclusiveLock viene acquisito.
I worker in background vengono eseguiti ogni 10 secondi sui nodi del router per scansionare le sequenze alla ricerca di blocchi riservati utilizzati. Se viene trovato un blocco utilizzato, il worker richiede un nuovo blocco dalla sequenza distribuita. Assicurati di impostare una dimensione dei blocchi sufficientemente grande affinché i worker in background abbiano tempo sufficiente per richiederne di nuovi. Le richieste remote non avvengono mai nel contesto delle sessioni utente, quindi non puoi richiedere direttamente una nuova sequenza.
Limitazioni
Le limitazioni seguenti si applicano alle sequenze in Aurora PostgreSQL Limitless Database:
-
Il catalogo
pg_sequence, la funzionepg_sequencese l’istruzioneSELECT * FROMmostrano solo lo stato della sequenza locale, non quello distribuito.sequence_name -
I valori della sequenza sono garantiti come univoci e monotoni all’interno di una sessione. Tuttavia, possono risultare errati rispetto alle istruzioni
nextvaleseguite in altre sessioni, se tali sessioni sono connesse ad altri router. -
Assicurati che la dimensione della sequenza (numero di valori disponibili) sia sufficientemente grande da poter essere distribuita su tutti i router. Usa il parametro
rds_aurora.limitless_sequence_chunk_sizeper configurarechunk_size. Ogni router ha due blocchi. -
L’opzione
CACHEè supportata, ma la cache deve essere inferiore achunk_size.
Opzioni non supportate
Le seguenti opzioni non sono supportate per le sequenze in Aurora PostgreSQL Limitless Database.
- Funzioni di manipolazione di sequenze
-
La funzione
setvalnon è supportata. Per ulteriori informazioni, consulta Sequence Manipulation Functionsnella documentazione di PostgreSQL. - CREATE SEQUENCE
-
Le seguenti opzioni non sono supportate.
CREATE [{ TEMPORARY | TEMP} | UNLOGGED] SEQUENCE [[ NO ] CYCLE]Per ulteriori informazioni, consulta CREATE SEQUENCE
nella documentazione di PostgreSQL. - ALTER SEQUENCE
-
Le seguenti opzioni non sono supportate.
ALTER SEQUENCE [[ NO ] CYCLE]Per ulteriori informazioni, consulta ALTER SEQUENCE
nella documentazione di PostgreSQL. - ALTER TABLE
-
Il comando
ALTER TABLEnon è supportato per le sequenze.
Esempi
- CREATE/DROP SEQUENZA
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 1 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16960 | 20 | 1 | 1 | 10000 | 1 | 1 | f (1 row) % connect to another router postgres_limitless=> SELECT nextval('s'); nextval --------- 10001 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16959 | 20 | 10001 | 1 | 20000 | 10001 | 1 | f (1 row) postgres_limitless=> DROP SEQUENCE s; DROP SEQUENCE - ALTER SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> ALTER SEQUENCE s RESTART 500; ALTER SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 500 (1 row) postgres_limitless=> SELECT currval('s'); currval --------- 500 (1 row) - Funzioni di manipolazione di sequenze
-
postgres=# CREATE TABLE t(a bigint primary key, b bigint); CREATE TABLE postgres=# CREATE SEQUENCE s minvalue 0 START 0; CREATE SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b ---+--- 0 | 0 1 | 1 (2 rows) postgres=# ALTER SEQUENCE s RESTART 10000; ALTER SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b -------+------- 0 | 0 1 | 1 10000 | 10000 (3 rows)
Viste delle sequenze
Aurora PostgreSQL Limitless Database offre le seguenti viste per le sequenze.
- rds_aurora.limitless_distributed_sequence
-
Questa vista mostra lo stato e la configurazione della sequenza distribuita. Le colonne
minvalue,maxvalue,start,incecachehanno lo stesso significato della vista pg_sequencese mostrano le opzioni con cui è stata creata la sequenza. La colonna lastvalmostra l’ultimo valore allocato o riservato in un oggetto di sequenza distribuita. Ciò non significa che il valore sia già stato utilizzato, poiché i router mantengono localmente i blocchi di sequenza.postgres_limitless=> SELECT * FROM rds_aurora.limitless_distributed_sequence WHERE sequence_name='test_serial_b_seq'; schema_name | sequence_name | lastval | minvalue | maxvalue | start | inc | cache -------------+-------------------+---------+----------+------------+-------+-----+------- public | test_serial_b_seq | 1250000 | 1 | 2147483647 | 1 | 1 | 1 (1 row) - rds_aurora.limitless_sequence_metadata
-
Questa vista mostra i metadati della sequenza distribuita e aggrega i metadati della sequenza dai nodi del cluster. Usa le seguenti colonne:
-
subcluster_id: l’ID del nodo del cluster che possiede un blocco. -
Blocco attivo: un blocco di una sequenza attualmente in uso (
active_minvalue,active_maxvalue). -
Blocco riservato: il blocco locale che verrà utilizzato successivamente (
reserved_minvalue,reserved_maxvalue). -
local_last_value: l’ultimo valore osservato da una sequenza locale. -
chunk_size: la dimensione di un blocco, come configurato alla creazione.
postgres_limitless=> SELECT * FROM rds_aurora.limitless_sequence_metadata WHERE sequence_name='test_serial_b_seq' order by subcluster_id; subcluster_id | sequence_name | schema_name | active_minvalue | active_maxvalue | reserved_minvalue | reserved_maxvalue | chunk_size | chunk_state | local_last_value ---------------+-------------------+-------------+-----------------+-----------------+-------------------+-------------------+------------+-------------+------------------ 1 | test_serial_b_seq | public | 500001 | 750000 | 1000001 | 1250000 | 250000 | 1 | 550010 2 | test_serial_b_seq | public | 250001 | 500000 | 750001 | 1000000 | 250000 | 1 | (2 rows) -
Risoluzione dei problemi delle sequenze
Possono verificarsi i seguenti problemi con le sequenze:
- Dimensione del blocco non sufficientemente grande
-
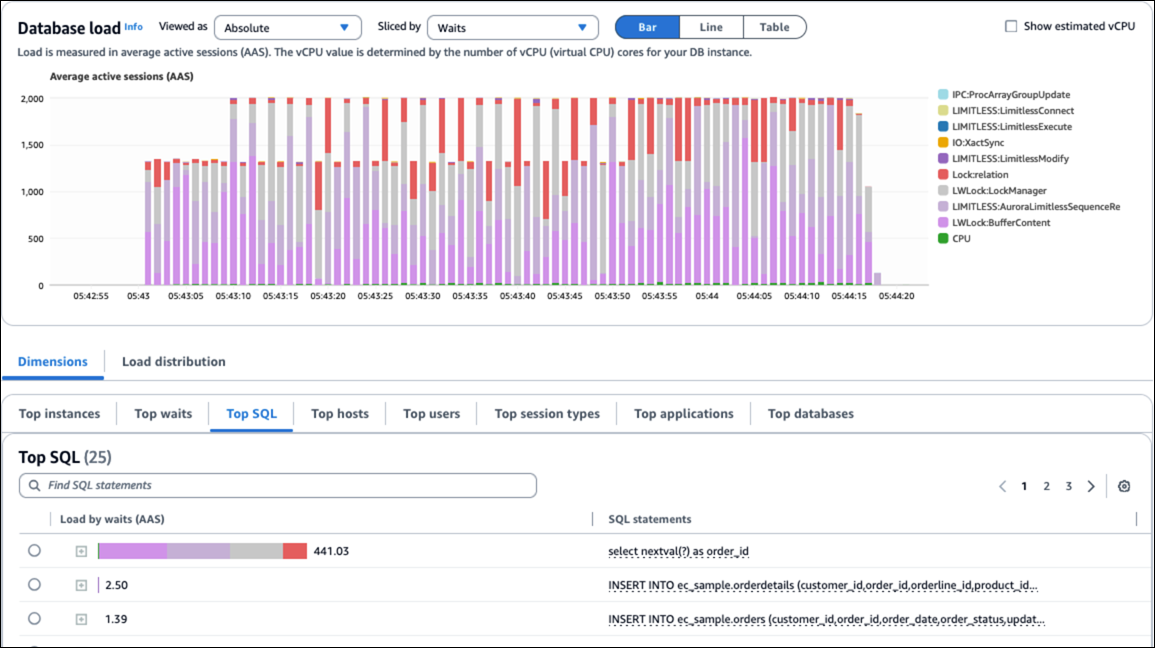
Se la dimensione del blocco non è sufficientemente grande e il tasso di transazione è elevato, i worker in background potrebbero non avere tempo sufficiente per richiedere nuovi blocchi prima che i blocchi attivi siano esauriti. Questo può causare eventi di contesa e attesa come
LIMITLESS:AuroraLimitlessSequenceReplace,LWLock:LockManager,LockrelationeLWlock:bufferscontent.Aumenta il valore del parametro
rds_aurora.limitless_sequence_chunk_size. - Cache della sequenza impostata troppo alta
-
In PostgreSQL, la memorizzazione nella cache delle sequenze avviene a livello di sessione. Ogni sessione alloca valori di sequenza successivi durante un accesso all’oggetto di sequenza e aumenta di conseguenza quelli dell’oggetto di sequenza di
last_value. Quindi, gli usi successivi dinextvalnella stessa sessione restituiscono semplicemente i valori preallocati senza interessare l’oggetto di sequenza.Tutti i numeri allocati ma non utilizzati all’interno di una sessione vengono persi al termine di tale sessione, con conseguenti “buchi” nella sequenza. Ciò può consumare rapidamente sequence_chunk e causare eventi di contesa e attesa come
LIMITLESS:AuroraLimitlessSequenceReplace,LWLock:LockManager,LockrelationeLWlock:bufferscontent.Riduci l’impostazione della cache della sequenza.
La figura seguente mostra gli eventi di attesa causati da problemi di sequenza.