Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Visualizzazione dell'attività dettagliata del servizio e dell'integrità operativa tramite la pagina dei dettagli del servizio
Quando strumentalizzi la tua CloudWatch applicazione, Amazon Application Signals mappa tutti i servizi rilevati dall'applicazione. Utilizza la pagina dei dettagli del servizio per visualizzare una panoramica dei servizi, delle operazioni, delle dipendenze, dei canary e delle richieste client per un singolo servizio. Per visualizzare la pagina dei dettagli del servizio, effettua le seguenti operazioni:
-
Apri la CloudWatch console
. -
Scegli Servizi nella sezione Application Signals nel pannello di navigazione a sinistra.
-
Scegli il nome di qualsiasi servizio dalle tabelle Servizi, Servizi principali o dipendenze.
In schedule-visits, vedrai l'etichetta e l'ID dell'account sotto il nome del servizio.
La pagina dei dettagli del servizio è organizzata nelle seguenti schede:
-
Panoramica: utilizza questa scheda per visualizzare una panoramica di un determinato servizio, incluso il numero di operazioni, dipendenze, synthetics e pagine client. La scheda mostra le metriche chiave per l'intero servizio, le operazioni principali e le dipendenze. Queste metriche includono dati di serie temporali su latenza, guasti ed errori in tutte le operazioni di servizio relative a quel servizio.
-
Operazioni di servizio: utilizza questa scheda per visualizzare un elenco delle operazioni chiamate dal servizio e grafici interattivi con le metriche chiave che misurano l'integrità di ciascuna operazione. Puoi selezionare un punto dati in un grafico per ottenere informazioni su tracce, log o metriche associate a quel punto dati.
-
Dipendenze: questa scheda mostra un elenco delle dipendenze chiamate dal servizio e un elenco delle metriche di tali dipendenze.
-
Canary synthetics: utilizza questa scheda per visualizzare un elenco di canary synthetics che simulano le chiamate degli utenti al servizio e le metriche chiave delle prestazioni relative a tali canary.
-
Pagine client: utilizza questa scheda per visualizzare un elenco delle pagine client che chiamano il servizio e le metriche che misurano la qualità delle interazioni client con la tua applicazione.
-
Metriche correlate: utilizza questa scheda per correlare le metriche correlate, ad esempio metriche standard, metriche di runtime e metriche personalizzate per un servizio, le sue operazioni o le sue dipendenze.
Visualizzazione della panoramica del servizio
Utilizza la pagina Panoramica del servizio per visualizzare un riepilogo di alto livello delle metriche per tutte le operazioni di servizio in un'unica posizione. Controlla le prestazioni di tutte le operazioni, le dipendenze, le pagine client e i canary synthetics che interagiscono con l'applicazione. Utilizza queste informazioni per determinare dove concentrare gli sforzi per identificare i problemi, risolvere gli errori e individuare le opportunità di ottimizzazione.
Scegli un collegamento in Dettagli del servizio per visualizzare le informazioni relative a un servizio specifico. Ad esempio, per i servizi ospitati in Amazon EKS, la pagina dei dettagli del servizio mostra informazioni su cluster, namespace e carico di lavoro. Per i servizi ospitati in Amazon ECS o Amazon EC2, la pagina dei dettagli del servizio mostra il valore Ambiente.
In Servizi, la scheda Panoramica mostra un riepilogo di quanto segue:
-
Operazioni: utilizza questa scheda per visualizzare lo stato delle operazioni di servizio. Lo stato di integrità è determinato dagli indicatori del livello di servizio (SLI) definiti come parte di un obiettivo del livello di servizio (SLO).
-
Dipendenze: utilizza questa scheda per visualizzare le principali dipendenze dei servizi richiamati dall'applicazione, elencate in base al tasso di guasto, e per visualizzare l'integrità delle dipendenze del servizio. Lo stato di integrità è determinato dagli indicatori del livello di servizio (SLI) definiti come parte di un obiettivo del livello di servizio (SLO).
-
Canary synthetics: utilizza questa scheda per visualizzare il risultato delle chiamate simulate agli endpoint o alle API associate al servizio e il numero di canary falliti.
-
Pagine client: utilizza questa scheda per visualizzare le pagine principali richiamate dai client con errori asincroni JavaScript e XML (AJAX).
La figura seguente mostra una panoramica dei tuoi servizi:

La scheda Panoramica mostra anche un grafico delle dipendenze con la latenza più elevata tra tutti i servizi. Utilizza le metriche di latenza p99, p90 e p50 per valutare rapidamente quali dipendenze contribuiscono alla latenza totale del servizio, come segue:

Ad esempio, il grafico precedente mostra che il 99% delle richieste fatte alla dipendenza customer-service sono state completate in circa 4.950 millisecondi. Le altre dipendenze hanno richiesto meno tempo.
I grafici che mostrano le quattro operazioni di servizio principali per latenza mostrano il volume di richieste, la disponibilità, il tasso di guasto e il tasso di errore per tali servizi, come illustrato nella figura seguente:
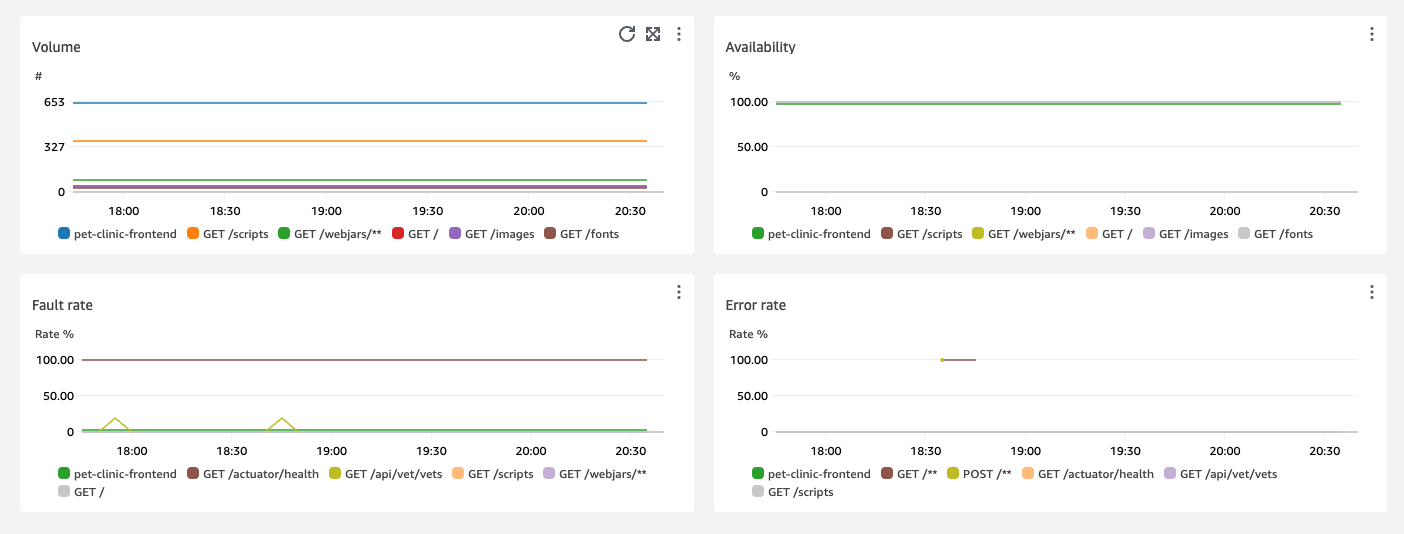
La sezione Dettagli del servizio mostra i dettagli del servizio, inclusi ID account ed Etichetta dell'account.
Visualizzazione delle operazioni del servizio
Quando instrumenti la tua applicazione, Application Signals rileva tutte le operazioni di servizio chiamate dall'applicazione. Utilizza la scheda Operazioni di servizio per visualizzare una tabella che contiene le operazioni di servizio e un insieme di metriche che misurano le prestazioni di un'operazione selezionata. Queste metriche includono lo stato SLI, il numero di dipendenze, il volume, guasti, errori e disponibilità, come illustrato nella figura seguente:
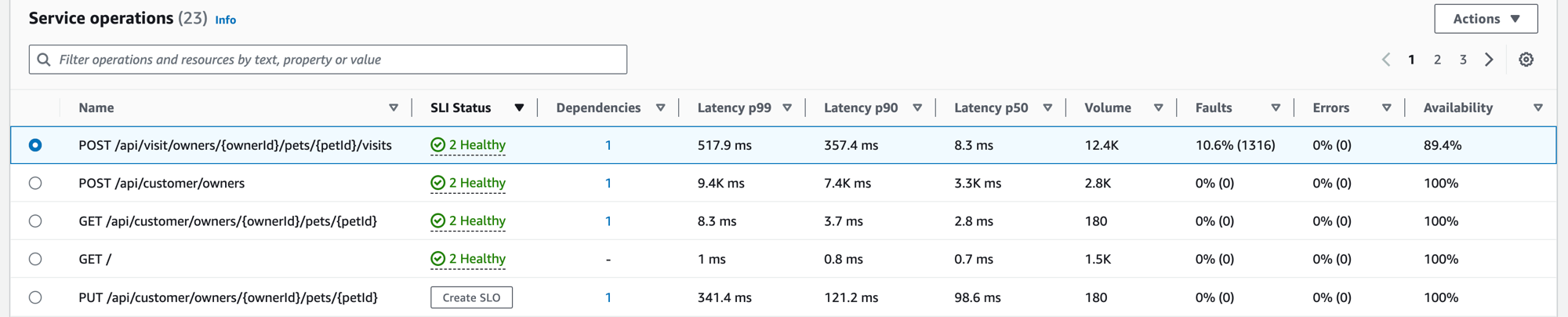
Filtra la tabella per trovare facilmente un'operazione di servizio scegliendo una o più proprietà dalla casella di testo del filtro. Quando scegli una proprietà, una procedura ti guida attraverso i criteri di filtro e vedrai il filtro completo sotto la casella di testo del filtro. Seleziona Cancella filtri in qualsiasi momento per rimuovere il filtro della tabella.
Scegli lo stato SLI di un'operazione per visualizzare un popup contenente un collegamento a eventuali SLI non integri e un collegamento per visualizzare tutti gli SLO relativi all'operazione, come mostrato nella tabella seguente:
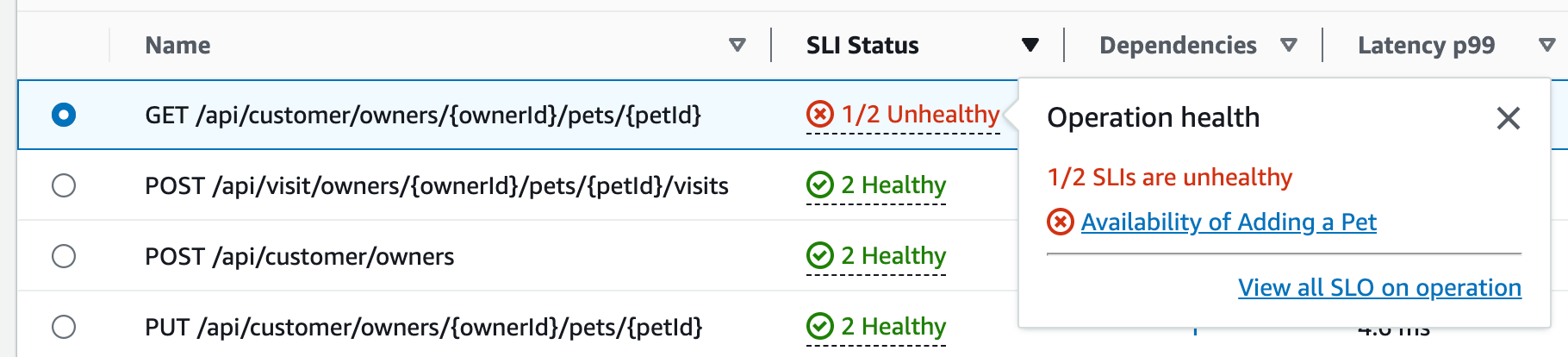
La tabella delle operazioni di servizio elenca lo stato SLI, il numero di SLI integri o non integri e il numero totale di SLO per ogni operazione.
Utilizza gli SLI per monitorare latenza, disponibilità e altre metriche operative che misurano l'integrità operativa di un servizio. Utilizza uno SLO per verificare le prestazioni e lo stato di integrità dei tuoi servizi e delle tue operazioni.
Per creare uno SLO, procedi come descritto di seguito:
-
Se un'operazione non dispone di uno SLO, seleziona il pulsante Crea SLO nella colonna Stato SLI.
-
Se un'operazione dispone già di uno SLO, procedi come indicato di seguito:
-
Seleziona il pulsante di opzione accanto al nome dell'operazione.
-
Scegli Crea SLO dalla freccia rivolta verso il basso Operazioni in alto a destra della tabella.
-
Per ulteriori informazioni, consulta gli obiettivi del livello di servizio (SLO).
La colonna Dipendenze mostra il numero di dipendenze chiamate da questa operazione. Seleziona questo numero per aprire la scheda Dipendenze filtrata in base all'operazione selezionata.
Visualizzazione delle metriche delle operazioni di servizio, delle tracce correlate e dei log dell'applicazione
Application Signals mette in correlazione le metriche relative al funzionamento del servizio con AWS X-Ray trace, CloudWatch Container Insights e registri delle applicazioni. Utilizza queste metriche per risolvere i problemi di integrità operativa. Per visualizzare le metriche come informazioni grafiche, procedi come indicato di seguito:
-
Seleziona un'operazione di servizio nella tabella Operazioni di servizio per visualizzare un insieme di grafici per l'operazione selezionata sopra la tabella con le metriche per Volume e disponibilità, Latenza e Guasti ed errori.
-
Passa il mouse su un punto in un grafico per visualizzare ulteriori informazioni.
-
Seleziona un punto per aprire un pannello di diagnostica che mostra le tracce correlate, le metriche e i log dell'applicazione per il punto selezionato nel grafico.
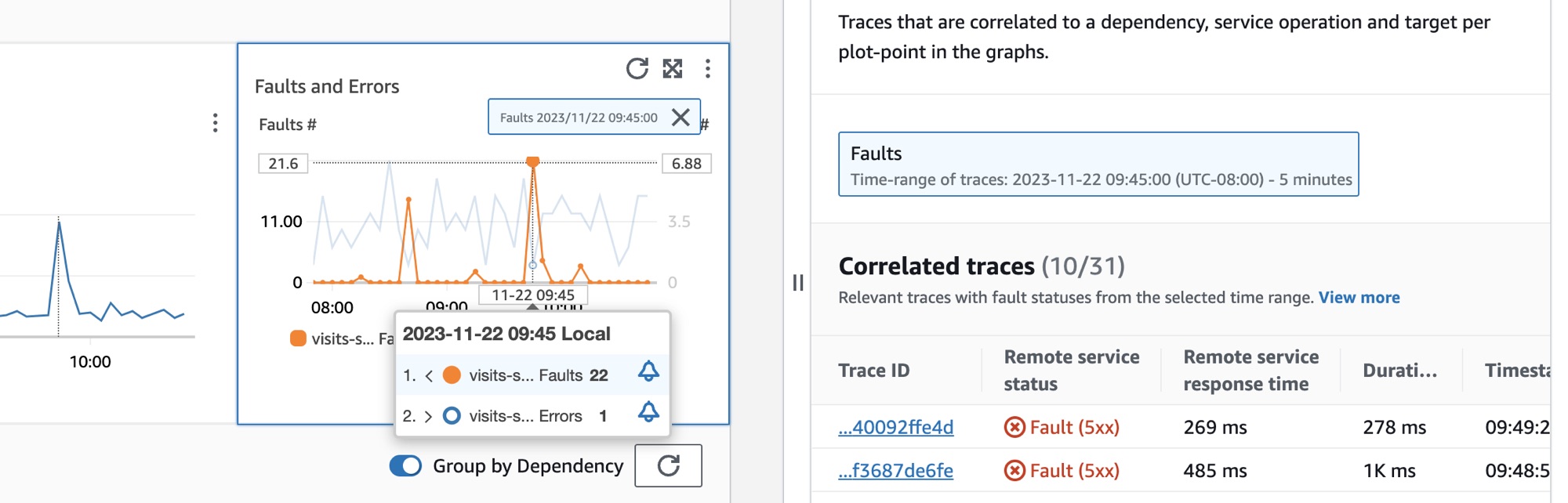
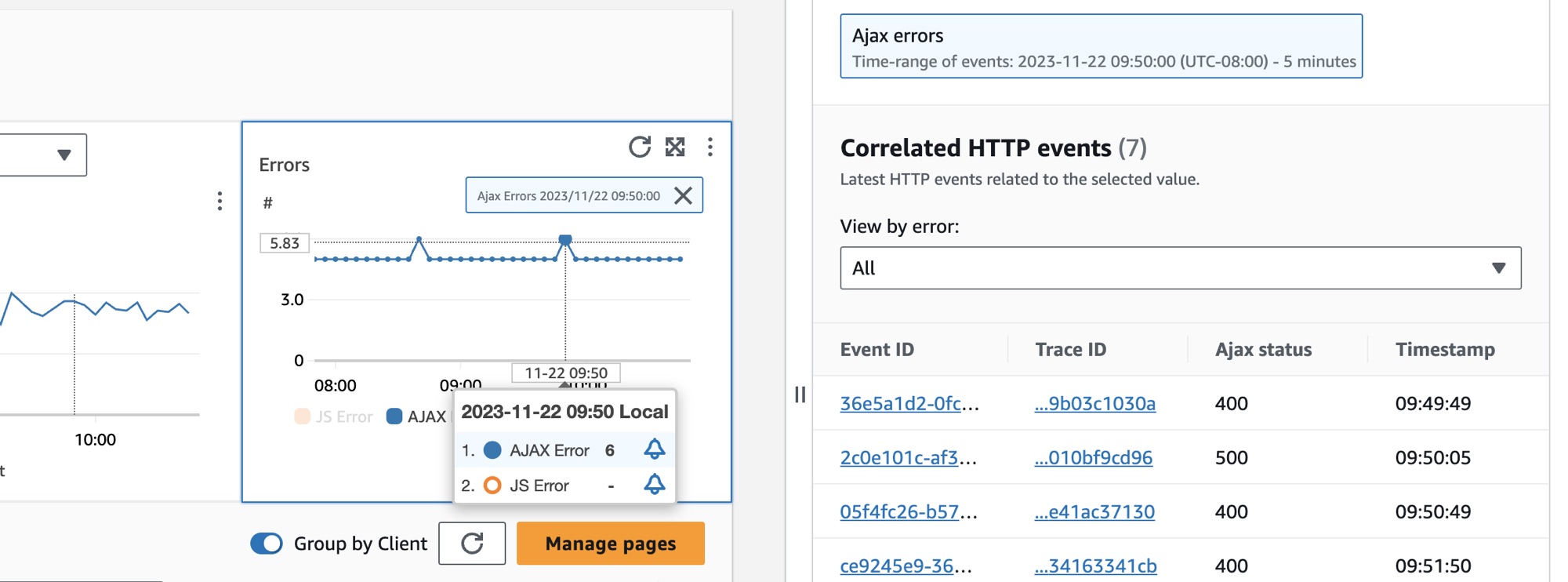
L'immagine seguente mostra il suggerimento che appare dopo aver passato il mouse su un punto del grafico e il pannello di diagnostica che appare dopo aver fatto clic su un punto. Il suggerimento contiene informazioni sul punto dati associato nel grafico Guasti ed errori. Il pannello contiene Tracce correlate, Collaboratori principali e Log dell'applicazione associati al punto selezionato.
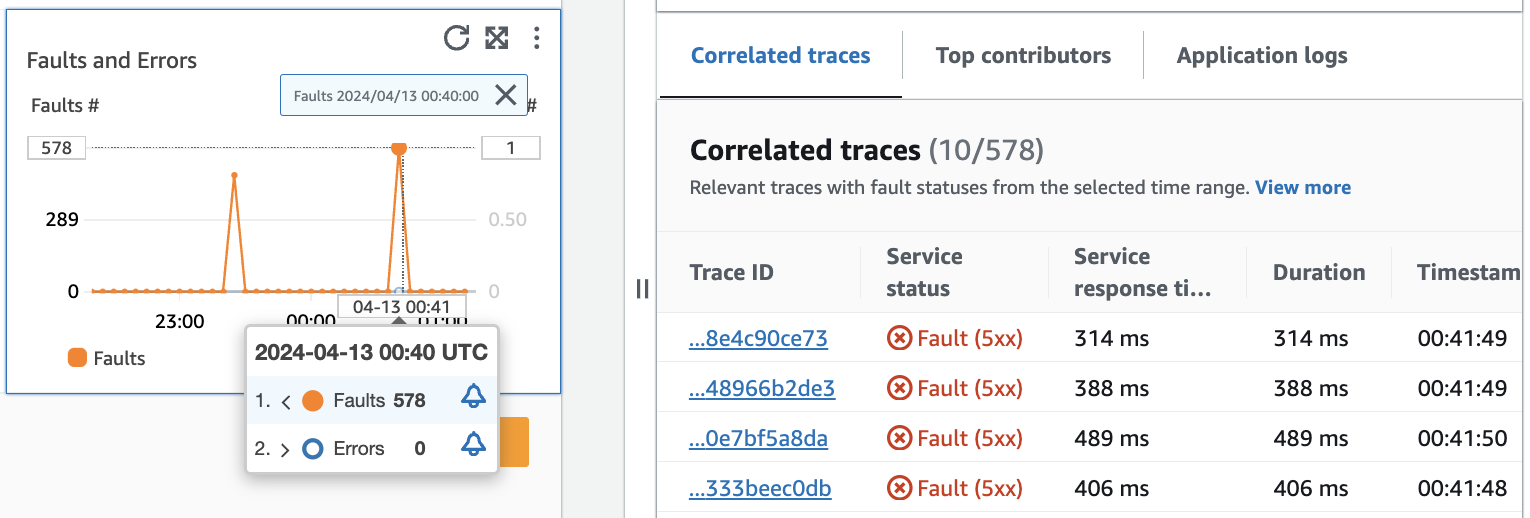
Tracce correlate
Osserva le tracce correlate per comprendere un problema di fondo relativo a una traccia. Puoi verificare se le tracce correlate o gli eventuali nodi di servizio a esse associati si comportano in modo simile. Per esaminare le tracce correlate, scegliete un ID di traccia dalla tabella Tracce correlate per aprire la pagina dei dettagli di X-Ray traccia relativa alla traccia scelta. La pagina dei dettagli della traccia contiene una mappa dei nodi del servizio associati alla traccia selezionata e una sequenza temporale dei segmenti di traccia.
Collaboratori principali
Visualizza i collaboratori principali per trovare le principali origini di input per una metrica. Raggruppa i collaboratori in base ai diversi componenti per cercare le somiglianze all'interno del gruppo e capire in che modo il comportamento delle tracce differisce tra uno e l'altro.
La scheda Collaboratori principali fornisce le metriche relative al volume delle chiamate, alla disponibilità, alla latenza media, agli errori e ai guasti per ciascun gruppo. L'immagine di esempio seguente mostra i collaboratori principali di un insieme di metriche per un'applicazione implementata su una piattaforma Amazon EKS:
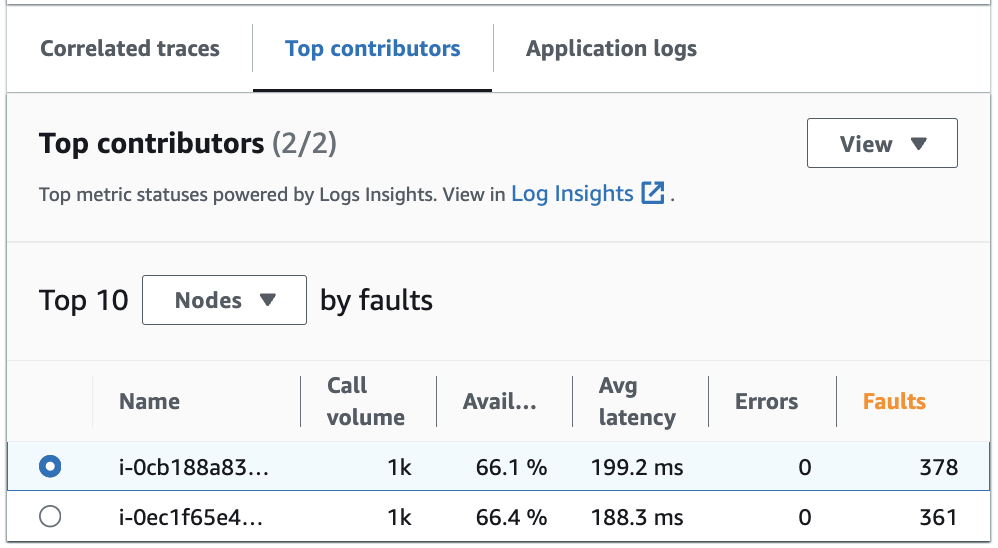
I collaboratori principali contengono le seguenti metriche:
-
Volume delle chiamate: utilizza il volume delle chiamate per comprendere il numero di richieste per intervallo di tempo per un gruppo.
-
Disponibilità: utilizza la disponibilità per vedere in quale percentuale di tempo non sono stati rilevati guasti per un gruppo.
-
Latenza media: utilizza la latenza per verificare il tempo medio di esecuzione delle richieste per un gruppo in un intervallo di tempo, il cui valore dipende da quanto tempo prima sono state effettuate le richieste oggetto di indagine. Le richieste effettuate meno di 15 giorni prima vengono valutate a intervalli di 1 minuto. Le richieste effettuate tra i 15 e i 30 giorni precedenti, inclusi, vengono valutate a intervalli di 5 minuti. Ad esempio, se stai esaminando le richieste che hanno causato un errore 15 giorni fa, la metrica del volume delle chiamate è uguale al numero di richieste per intervallo di 5 minuti.
-
Errori: il numero di errori per gruppo misurato in un intervallo di tempo.
-
Guasti: il numero di guasti per gruppo in un intervallo di tempo.
Collaboratori principali che utilizzano Amazon EKS o Kubernetes
Utilizza le informazioni sui principali contributori per le applicazioni distribuite su Amazon EKS o Kubernetes per visualizzare i parametri di salute operativa raggruppati per Node, Pod e. PodTemplateHash Si applicano le seguenti definizioni:
-
Un pod è un gruppo di uno o più container Docker che condividono spazio di archiviazione e risorse. Un pod è l'unità più piccola che può essere implementata su una piattaforma Kubernetes. Raggruppa per pod per verificare se gli errori sono correlati a limitazioni specifiche dei pod.
-
Un nodo è un server che esegue i pod. Raggruppa per nodi per verificare se gli errori sono correlati a limitazioni specifiche del nodo.
-
Un hash del modello pod viene utilizzato per trovare una versione particolare di un'implementazione. Raggruppa per hash del modello pod per verificare se gli errori sono correlati a una particolare implementazione.
Collaboratori principali che utilizzano Amazon EC2
Utilizza le informazioni sui collaboratori principali per le applicazioni implementate su Amazon EKS per visualizzare le metriche dell'integrità operativa raggruppate per ID istanza e gruppo Auto Scaling. Si applicano le seguenti definizioni:
-
Un ID dell'istanza è un identificatore univoco per l'istanza Amazon EC2 eseguita dal servizio. Raggruppa per ID dell'istanza per verificare se gli errori sono correlati a un'istanza Amazon EC2 specifica.
-
Un gruppo Auto Scaling è una raccolta di istanze Amazon EC2 che consentono di aumentare o ridurre verticalmente le risorse necessarie per soddisfare le richieste delle applicazioni. Raggruppa per gruppo Auto Scaling se desideri verificare se gli errori sono limitati alle istanze all'interno del gruppo.
Collaboratori principali che utilizzano una piattaforma personalizzata
Utilizza le informazioni sui collaboratori principali per le applicazioni implementate utilizzando instrumentazione personalizzata per visualizzare le metriche sull'integrità operativa raggruppate per nome host. Si applicano le seguenti definizioni:
-
Un nome host identifica un dispositivo come un endpoint o un'istanza Amazon EC2 connesso a una rete. Raggruppa per nome host per verificare se gli errori sono correlati a uno specifico dispositivo fisico o virtuale.
Visualizzazione dei collaboratori principali in Log Insights e Container Insights
Visualizza e modifica la query automatica che ha generato le metriche per i tuoi collaboratori principali in Approfondimenti di Logs. Visualizza le metriche delle prestazioni dell'infrastruttura per gruppi specifici come pod o nodi in Approfondimenti sui container. Puoi ordinare cluster, nodi o carichi di lavoro in base al consumo di risorse e identificare rapidamente le anomalie o mitigare i rischi in modo proattivo prima che l'esperienza dell'utente finale ne risenta. Segue un'immagine che mostra come selezionare queste opzioni:
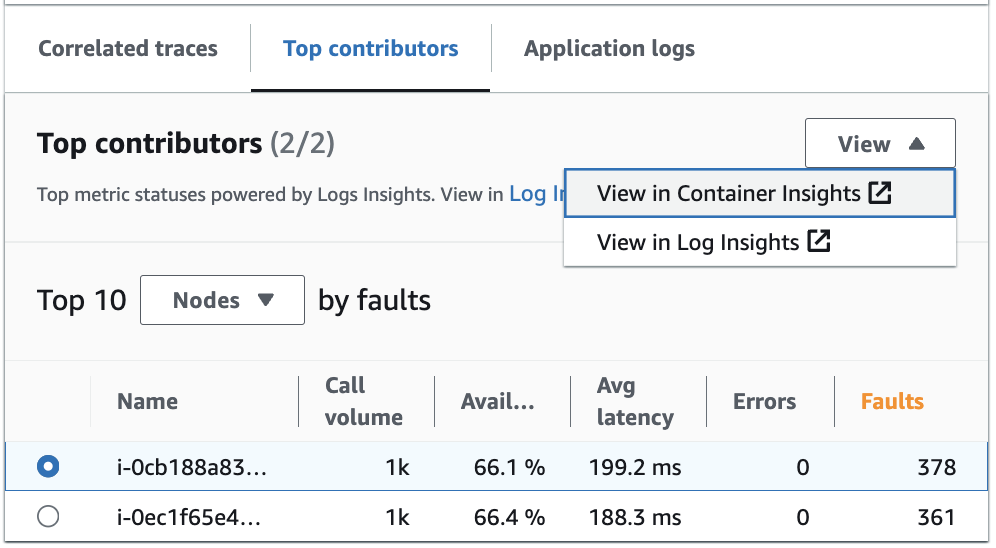
In Approfondimenti sui container, puoi visualizzare le metriche per il container Amazon EKS o Amazon ECS specifiche per il raggruppamento dei tuoi collaboratori principali. Ad esempio, se raggruppi per pod per generare i collaboratori principali di un container EKS, Approfondimenti sui container mostrerà le metriche e le statistiche filtrate per tale pod.
In Approfondimenti di Logs, puoi modificare la query che ha generato le metriche in Collaboratori principali utilizzando i seguenti passaggi:
-
Seleziona Visualizza in Approfondimenti di Logs. La pagina Approfondimenti di Logs che si apre contiene una query generata automaticamente e le seguenti informazioni:
-
Il nome del gruppo di cluster di log.
-
L'operazione su cui stavi indagando. CloudWatch
-
L'aggregato della metrica di integrità operativa con cui ha interagito nel grafico.
I risultati del registro vengono filtrati automaticamente per mostrare i dati degli ultimi cinque minuti precedenti alla selezione del punto dati sul grafico del servizio.
-
-
Per modificare la query, sostituisci il testo generato con le tue modifiche. È inoltre possibile utilizzare il generatore di query per generare una nuova query o aggiornare la query esistente.
Log di applicazioni
Utilizza la query nella scheda Log dell'applicazione per generare informazioni registrate per il gruppo di log corrente e il servizio e per inserire un timestamp. Un gruppo di log è un gruppo di flussi di log che è possibile definire quando si configura l'applicazione.
Utilizza un gruppo di log per organizzare log con caratteristiche simili, tra cui:
-
Acquisire i log da un'organizzazione, un'origine o una funzione specifica.
-
Acquisire i log a cui accede un determinato utente.
-
Acquisire i log per un determinato periodo di tempo.
Utilizza questi flussi di log per tenere traccia di gruppi o intervalli di tempo specifici. Per questi gruppi di log puoi anche impostare regole di monitoraggio, allarmi e notifiche. Per informazioni generali sui gruppi di log, consulta Working with log groups and log streams.
La query dei log dell'applicazione restituisce i log, i modelli di testo ricorrenti e le visualizzazioni grafiche per i gruppi di log.
Per eseguire la query, seleziona Esegui query in Approfondimenti di Logs per eseguire la query generata automaticamente o modificare la query. Per modificare la query, sostituisci il testo generato automaticamente con le tue modifiche. È inoltre possibile utilizzare il generatore di query per generare una nuova query o aggiornare la query esistente.
L'immagine seguente mostra l'interrogazione di esempio che viene generata automaticamente in base al punto selezionato nel grafico delle operazioni di servizio:
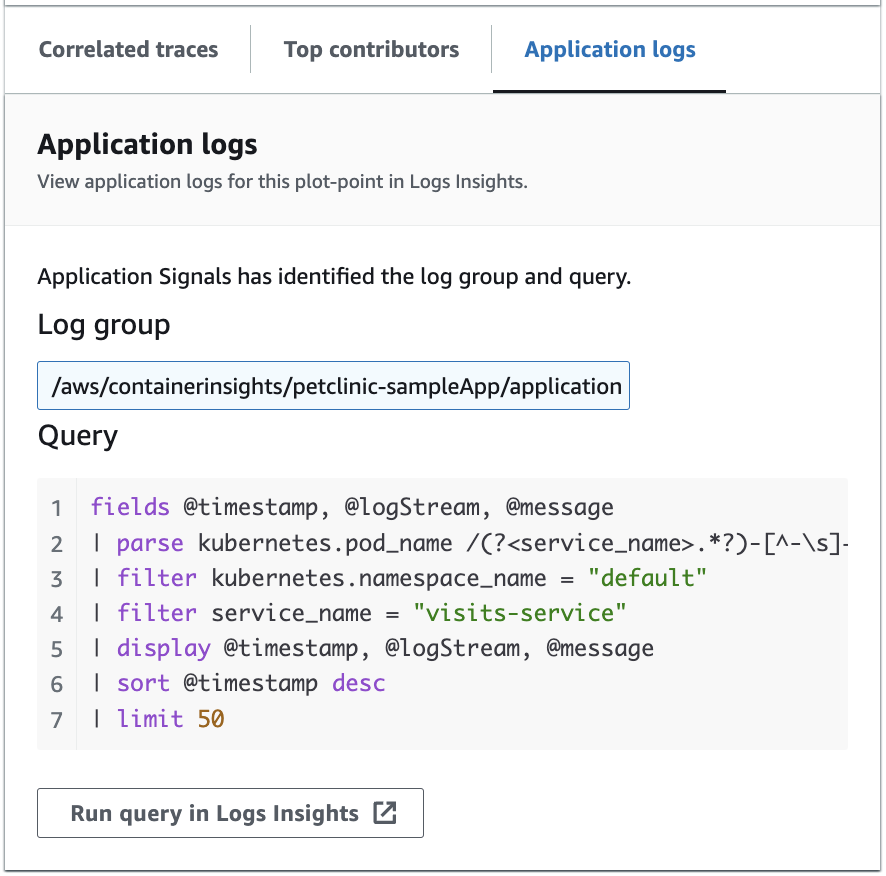
Nell'immagine precedente, CloudWatch ha rilevato automaticamente il gruppo di log associato al punto selezionato e lo ha incluso in una query generata.
Visualizzazione delle dipendenze del servizio
Scegli la scheda Dipendenze per visualizzare la tabella Dipendenze e un insieme di parametri per le dipendenze di tutte le operazioni del servizio o di una singola operazione. La tabella contiene un elenco di dipendenze individuate da Application Signals, tra cui metriche relative a stato SLI, latenza, volume delle chiamate, tasso di guasto, tasso di errore e disponibilità.
Nella parte superiore della pagina, scegli un'operazione dall'elenco della freccia rivolta verso il basso per visualizzarne le dipendenze oppure seleziona Tutto per visualizzare le dipendenze per tutte le operazioni.
Filtra la tabella per trovare facilmente ciò che cerchi, scegliendo una o più proprietà dalla casella di testo del filtro. Quando scegli una proprietà, una procedura ti guida attraverso i criteri di filtro e vedrai il filtro completo sotto la casella di testo del filtro. Seleziona Cancella filtri in qualsiasi momento per rimuovere il filtro della tabella. Seleziona Raggruppa per dipendenza in alto a destra della tabella per raggruppare le dipendenze in base al nome del servizio e dell'operazione. Quando il raggruppamento è attivo, puoi espandere o comprimere un gruppo di dipendenze con l'icona + accanto al nome della dipendenza.
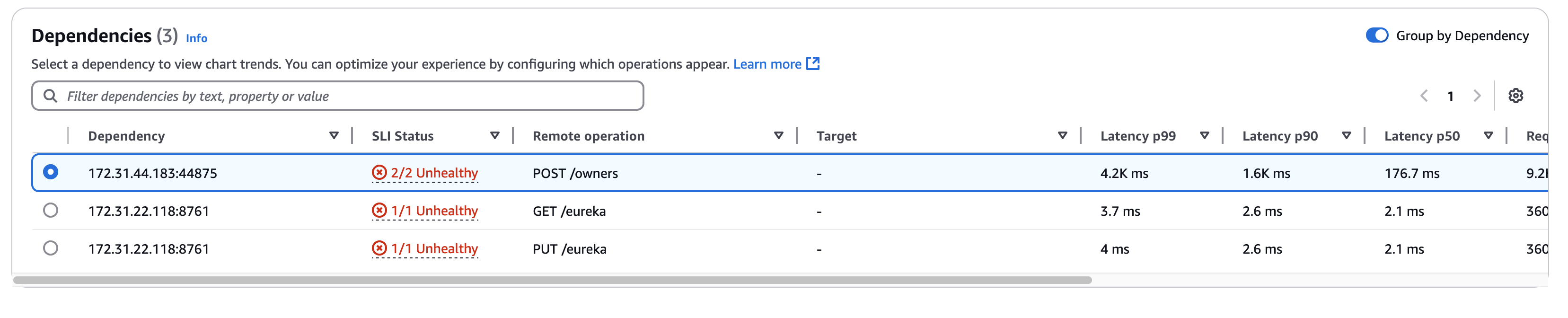
La colonna Dipendenza mostra il nome del servizio di dipendenza, mentre la colonna Operazione remota mostra il nome dell'operazione del servizio. La colonna Stato SLI mostra il numero di SLI integri o non integri insieme al numero totale di SLI per ogni dipendenza. Quando si chiamano AWS i servizi, la colonna Target mostra la AWS risorsa, ad esempio la tabella DynamoDB o la coda Amazon SNS.
Per selezionare una dipendenza, seleziona l'opzione accanto a una dipendenza nella tabella Dipendenze. Viene visualizzato un insieme di grafici che mostrano metriche dettagliate per il volume delle chiamate, la disponibilità, i guasti e gli errori. Passa il mouse su un punto in un grafico per visualizzare un popup con ulteriori informazioni. Seleziona un punto in un grafico per aprire un pannello di diagnostica che mostra le tracce correlate per tale punto. Scegli un ID di traccia dalla tabella delle tracce correlate per aprire la pagina dei dettagli di traccia per la X-Ray traccia selezionata.
Visualizzazione dei canary Synthetics
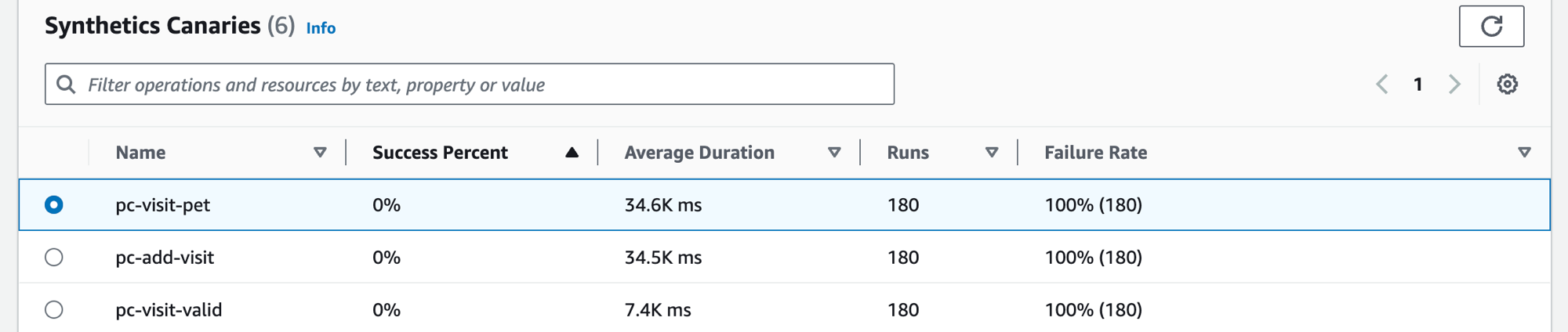
Scegli la scheda Canary Synthetics per visualizzare la tabella Canary Synthetics e un set di tabelle per ogni canary presente nella tabella. La tabella include i parametri relativi alla percentuale di successo, alla durata media, alle esecuzioni e alla frequenza di errore. Vengono visualizzati solo i canarini abilitati al tracciamento AWS X-Ray.
Usa la casella di testo del filtro nella tabella dei canary synthetics per trovare il canary che ti interessa. Ogni filtro creato viene visualizzato sotto la casella di testo del filtro. Seleziona Cancella filtri in qualsiasi momento per rimuovere il filtro della tabella.
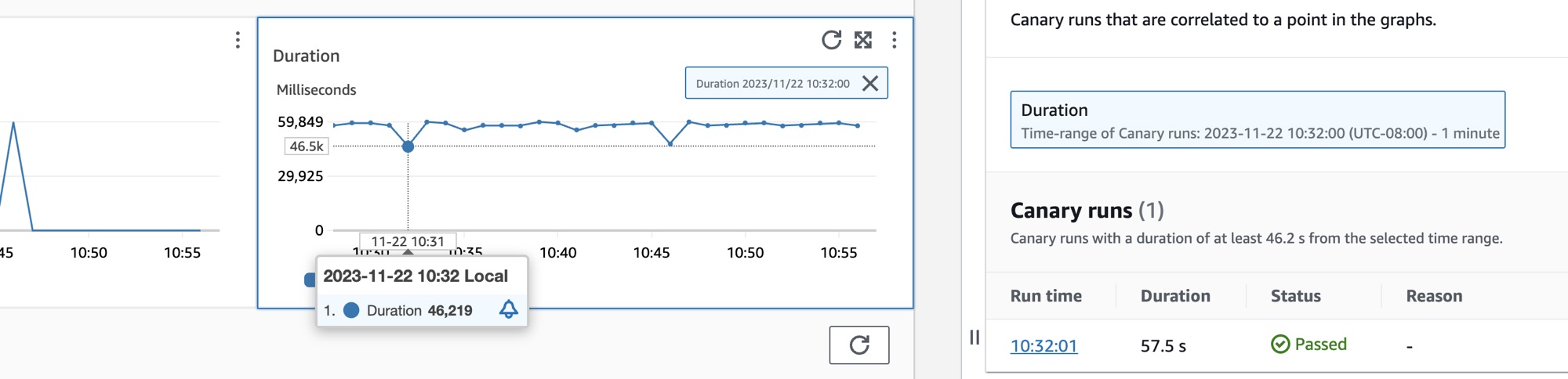
Seleziona il pulsante di opzione accanto al nome del canary per visualizzare una serie di schede contenenti grafici delle metriche dettagliati, tra cui percentuale di successo, errori e durata. Passa il mouse su un punto in un grafico per visualizzare un popup con ulteriori informazioni. Seleziona un punto in un grafico per aprire un pannello di diagnostica che mostra le esecuzioni di canary correlate per tale punto. Seleziona un'esecuzione di canary e scegli Tempo di esecuzione per visualizzare gli artefatti relativi all'esecuzione di canary selezionata, tra cui log, file HTTP Archive (HAR), schermate e passaggi suggeriti per aiutarti a risolvere i problemi. Scegli Ulteriori informazioni per aprire la pagina CloudWatch Synthetics Canaries accanto a Canary run.
Visualizzazione delle pagine client
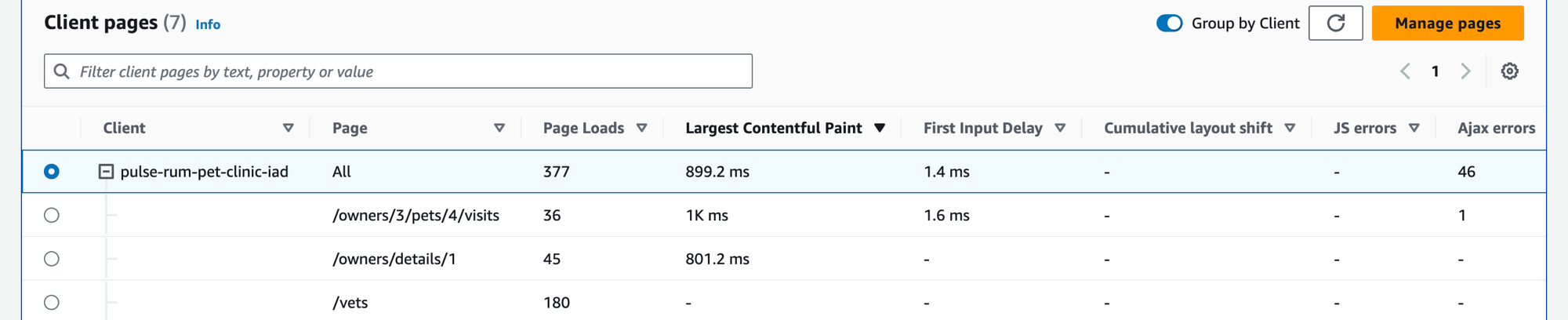
Scegli la scheda Pagine client per visualizzare un elenco di pagine web client che chiamano il servizio. Utilizza l'insieme di metriche per la pagina client selezionata per misurare la qualità dell'esperienza del cliente quando interagisce con un servizio o un'applicazione. Queste metriche includono caricamenti di pagine, dati web vitali ed errori.
Per visualizzare le pagine client nella tabella, è necessario configurare il client web CloudWatch RUM per la X-Ray tracciabilità e attivare le metriche di Application Signals per le pagine client. Scegli Gestisci pagine per selezionare le pagine che sono abilitate per le metriche di Application Signals.
Utilizza la casella di testo del filtro per trovare la pagina client o il monitoraggio dell'applicazione che ti interessa sotto la casella di testo del filtro. Seleziona Cancella filtri per rimuovere il filtro della tabella. Seleziona Raggruppa per client per raggruppare le pagine client per client. Una volta raggruppate, seleziona l'icona + accanto al nome di un client per espandere la riga e visualizzare tutte le pagine relative a quel client.
Per selezionare una pagina client, selezionare l'opzione accanto a una pagina client nella tabella Pagine client. Verrà visualizzata una serie di grafici che mostrano parametri dettagliati. Passa il mouse su un punto in un grafico per visualizzare un popup con ulteriori informazioni. Seleziona un punto in un grafico per aprire un pannello di diagnostica che mostra gli eventi di prestazione della navigazione correlati per tale punto. Scegliete un ID evento dall'elenco degli eventi di navigazione per aprire la visualizzazione della pagina CloudWatch RUM per l'evento scelto.
Nota
Per visualizzare gli errori AJAX nelle pagine client, utilizzate la versione 1.15 o successiva del client web CloudWatch RUM.
È possibile visualizzare fino a 100 operazioni, canary e pagine client e fino a 250 dipendenze per servizio.
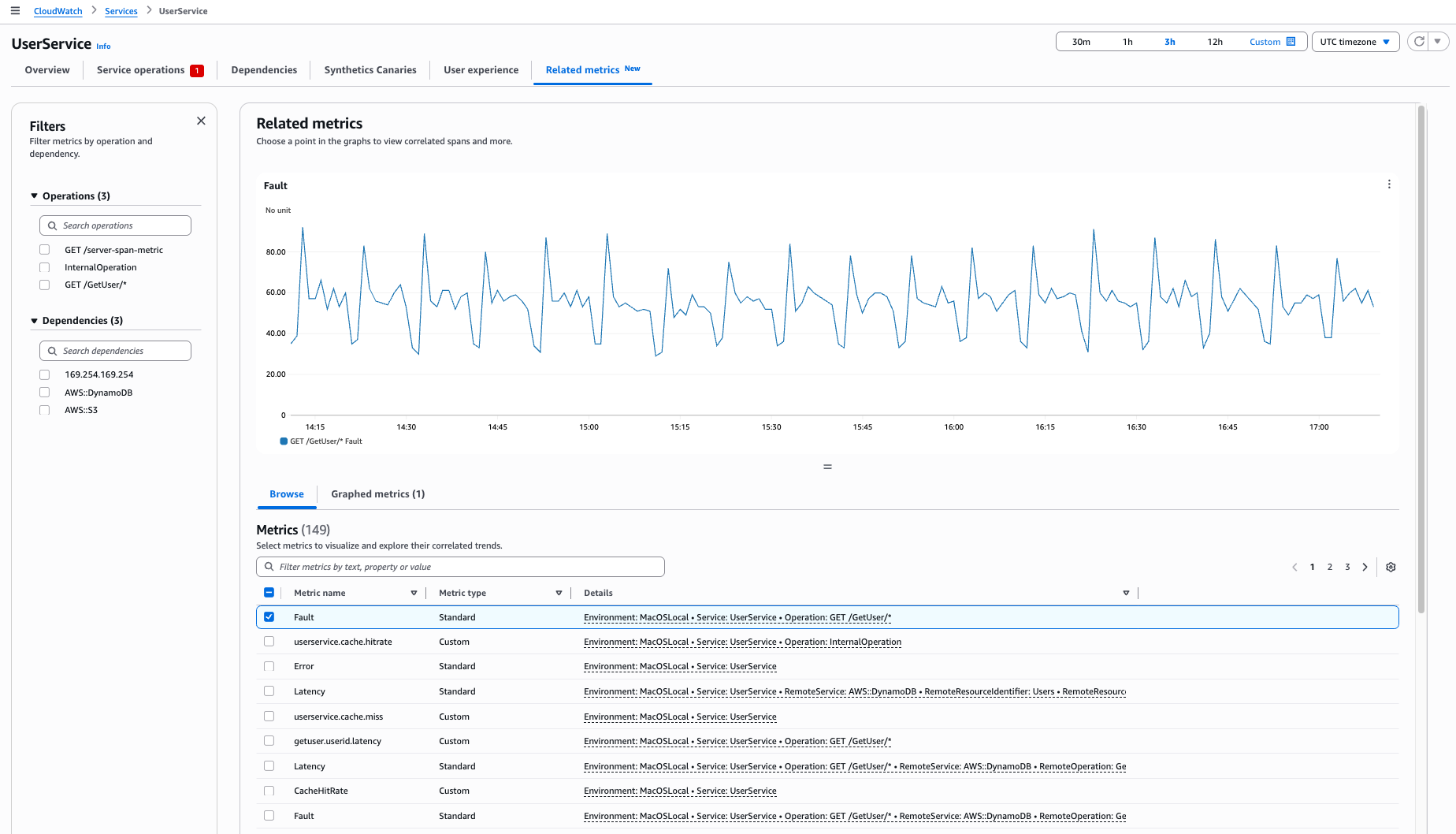
Visualizzazione di Metriche correlate
Utilizza la scheda Metriche correlate per visualizzare più metriche, identificare i modelli di correlazione e determinare le cause principali dei problemi.
La tabella delle metriche mostra tre tipi di metriche:
Metriche standard: Application Signals raccoglie le metriche dell'applicazione standard dai servizi che rileva. Per ulteriori informazioni, consulta Standard application metrics collected
Metriche di runtime: Application Signals utilizza AWS Distro for OpenTelemetry SDK per raccogliere automaticamente le OpenTelemetry-compatible metriche dalle applicazioni Java e Python. Per ulteriori informazioni, consulta Rumtime metrics
Metriche personalizzate: Application Signals consente di generare metriche personalizzate dalla propria applicazione. Per ulteriori informazioni, consulta Metriche personalizzate con Application Signals
È possibile accedere alla scheda Metriche correlate dalle schede Panoramica del servizio, Operazioni di servizio, Dipendenze, Canary synthetics o RUM.
-
Inizialmente, nel pannello di navigazione a sinistra tutte le operazioni e le dipendenze sono deselezionate
-
Inizialmente, il grafico mostra la metrica dei guasti relativa all'operazione con il tasso di guasto più elevato
Prima di iniziare l'analisi di correlazione, assicurati che i punti dati siano visibili in Operazioni di servizio o Dipendenze. Per analizzare le correlazioni:
Apri la pagina Operazioni di servizio o Dipendenze.
Seleziona un punto dati nel grafico.
Nel pannello di destra, scegli Correla con altre metriche.
Nella scheda Metriche correlate che si apre, vedrai:
L'operazione o la dipendenza selezionata nella barra di navigazione a sinistra
La metrica selezionata rappresentata graficamente nella tabella Sfoglia metriche
Gli intervalli correlati, quando si seleziona un punto dati
Per rappresentare graficamente più metriche, seleziona una o più metriche dalla visualizzazione Sfoglia nella scheda Metriche correlate. Scegli Metriche rappresentate graficamente per visualizzare tutte le metriche rappresentate graficamente.
Per filtrare le metriche, usa i filtri del pannello di sinistra per concentrarti su operazioni o dipendenze specifiche e usa la barra dei filtri dell'intestazione della tabella per cercare per nome, tipo o altri attributi. Queste opzioni di filtro ti aiutano a rilevare i modelli ricorrenti e a risolvere i problemi in modo più efficiente.
Per analizzare nel dettaglio le metriche correlate, seleziona un punto dati nella scheda Metriche correlate. Potrai quindi visualizzare:
Collaboratori principali: analizza le metriche CloudWatch eseguendo le query di Logs Insights. Queste query elaborano i record Enhanced Metrics Format (EMF) che contengono attributi chiave per un'analisi dettagliata di quanto segue:
Misurazioni della latenza
Occorrenze di guasti
Metriche della disponibilità del servizio
Le seguenti metriche non supportano i collaboratori principali:
Metriche OTEL
Server-side Metriche Span
Puoi visualizzare i principali contributori di RED Metrics e Span Metrics. Client-side
Intervalli correlati: la sezione Intervalli correlati funziona in modo coerente con la scheda Operazioni di servizio. Per aiutarti a identificare le tracce e le metriche correlate, il meccanismo di correlazione funziona in base a:
Confronto dei nomi delle metriche con gli attributi di intervallo
Identificazione dei modelli corrispondenti durante il periodo di tempo selezionato
Visualizzazione delle informazioni di traccia pertinenti
Per analizzare in modo efficace le metriche e gli intervalli, devi capire in che modo i diversi tipi di metriche sono correlati. Queste sono le limitazioni chiave:
Le metriche OTEL non sono correlate agli intervalli perché utilizzano sistemi di denominazione indipendenti
Per correlare Server o Client-side Span Metrics con gli spans:
Includi il campo Dimensione del servizio nella configurazione
Senza Dimensione del servizio, non è possibile correlare queste metriche con gli intervalli
Applicazioni di log: per informazioni sull'applicazione di log, consulta Application logs
