Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Observabilitas multi-AZ
Untuk dapat mengevakuasi Availability Zone selama peristiwa yang diisolasi ke Availability Zone tunggal, pertama-tama Anda harus dapat mendeteksi bahwa kegagalan tersebut, pada kenyataannya, diisolasi ke satu Availability Zone. Ini membutuhkan visibilitas kesetiaan tinggi tentang bagaimana sistem berperilaku di setiap Availability Zone. Banyak AWS layanan menyediakan out-of-the-box metrik yang memberikan wawasan operasional tentang sumber daya Anda. Misalnya, Amazon EC2 menyediakan banyak metrik seperti CPU pemanfaatan, membaca dan menulis disk, dan lalu lintas jaringan masuk dan keluar.
Namun, saat Anda membangun beban kerja yang menggunakan layanan ini, Anda memerlukan lebih banyak visibilitas daripada hanya metrik standar tersebut. Anda ingin visibilitas ke dalam pengalaman pelanggan yang disediakan oleh beban kerja Anda. Selain itu, metrik Anda harus disejajarkan dengan Availability Zone tempat metrik tersebut diproduksi. Ini adalah wawasan yang Anda butuhkan untuk mendeteksi kegagalan abu-abu yang dapat diamati secara berbeda. Tingkat visibilitas itu membutuhkan instrumentasi.
Instrumentasi membutuhkan penulisan kode eksplisit. Kode ini harus melakukan hal-hal seperti mencatat berapa lama tugas berlangsung, menghitung berapa banyak item yang berhasil atau gagal, mengumpulkan metadata tentang permintaan, dan sebagainya. Anda juga perlu menentukan ambang batas sebelumnya untuk menentukan apa yang dianggap normal dan apa yang tidak. Anda harus menguraikan tujuan dan ambang batas keparahan yang berbeda untuk latensi, ketersediaan, dan jumlah kesalahan dalam beban kerja Anda. Artikel Perpustakaan Pembangun Amazon Instrumentasi sistem terdistribusi untuk visibilitas operasional
Metrik harus dihasilkan dari sisi server maupun sisi klien. Praktik terbaik untuk menghasilkan metrik sisi klien dan memahami pengalaman pelanggan adalah menggunakan kenari, perangkat lunak yang secara teratur memeriksa beban kerja Anda dan mencatat metrik.
Selain menghasilkan metrik ini, Anda juga perlu memahami konteksnya. Salah satu cara untuk melakukannya adalah dengan menggunakan dimensi. Dimensi memberi metrik identitas unik, dan membantu menjelaskan apa yang dikatakan metrik kepada Anda. Untuk metrik yang digunakan untuk mengidentifikasi kegagalan dalam beban kerja Anda (misalnya, latensi, ketersediaan, atau jumlah kesalahan), Anda perlu menggunakan dimensi yang sejajar dengan batas isolasi kesalahan Anda.
Misalnya, jika Anda menjalankan layanan web di satu Wilayah, di beberapa Availability Zone, menggunakan kerangka web M odel-view-controllerRegion Availability
Zone ID,Controller,Action,, dan InstanceId sebagai dimensi untuk kumpulan dimensi Anda (jika Anda menggunakan layanan mikro, Anda mungkin menggunakan nama dan HTTP metode layanan alih-alih nama pengontrol dan tindakan). Ini karena Anda mengharapkan berbagai jenis kegagalan diisolasi oleh batas-batas ini. Anda tidak akan mengharapkan bug dalam kode layanan web Anda yang memengaruhi kemampuannya untuk membuat daftar produk untuk juga memengaruhi halaman beranda. Demikian pula, Anda tidak akan mengharapkan EBS volume penuh pada satu EC2 instance untuk memengaruhi EC2 instance lain dari menyajikan konten web Anda. Dimensi ID Availability Zone adalah hal yang memungkinkan Anda mengidentifikasi dampak terkait Availability Zone secara konsisten. Akun AWS Anda dapat menemukan ID Availability Zone di beban kerja Anda dengan berbagai cara. Lihat Lampiran A — Mendapatkan ID Availability Zone untuk beberapa contoh.
Meskipun dokumen ini terutama menggunakan Amazon EC2 sebagai sumber daya komputasi dalam contoh, InstanceId dapat diganti dengan ID penampung untuk Amazon Elastic Container Service (Amazon
Kenari Anda juga dapat menggunakanController,, ActionAZ-ID, dan Region sebagai dimensi dalam metriknya jika Anda memiliki titik akhir zona untuk beban kerja Anda. Dalam hal ini, sejajarkan kenari Anda untuk berjalan di Availability Zone yang sedang mereka uji. Ini memastikan bahwa jika peristiwa Availability Zone yang terisolasi memengaruhi Availability Zone tempat kenari Anda berjalan, itu tidak merekam metrik yang membuat Availability Zone berbeda yang sedang diuji tampak tidak sehat. Misalnya, kenari Anda dapat menguji setiap titik akhir zona untuk layanan di belakang Network Load Balancer () atau Application Load Balancer NLB () menggunakan nama zonalnyaALB. DNS
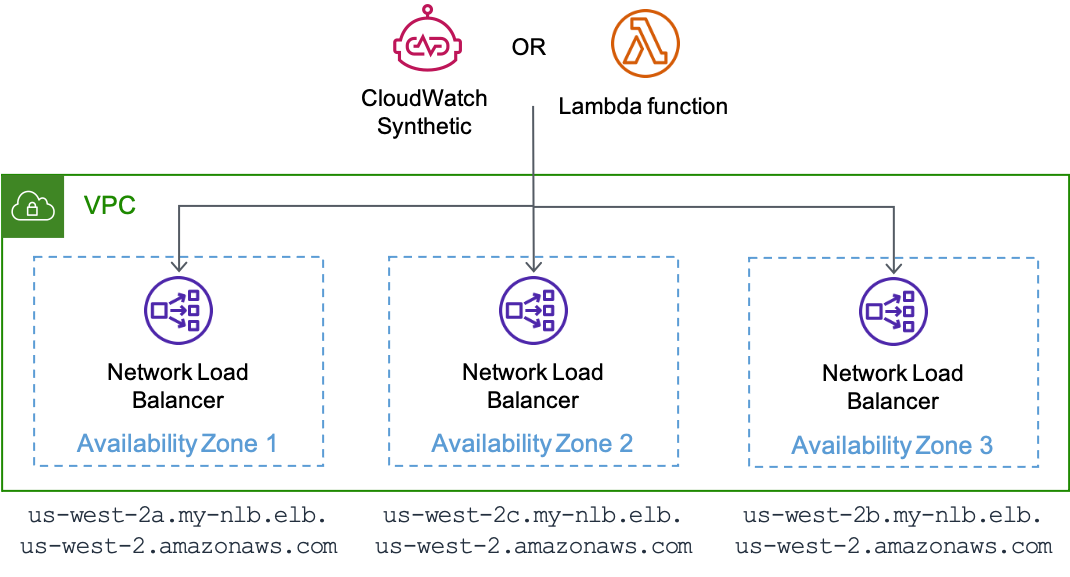
Sebuah kenari yang berjalan pada CloudWatch Synthetics atau fungsi AWS Lambda yang menguji setiap titik akhir zona NLB
Dengan menghasilkan metrik dengan dimensi ini, Anda dapat membuat CloudWatch alarm Amazon yang memberi tahu Anda saat perubahan ketersediaan atau latensi terjadi dalam batas-batas tersebut. Anda juga dapat dengan cepat menganalisis data tersebut menggunakan dasbor. Untuk menggunakan metrik dan log secara efisien, Amazon CloudWatch menawarkan format metrik tertanam (EMF) yang memungkinkan Anda menyematkan metrik kustom dengan data log. CloudWatchsecara otomatis mengekstrak metrik kustom sehingga Anda dapat memvisualisasikan dan alarm pada mereka. AWS menyediakan beberapa pustaka klien untuk berbagai bahasa pemrograman yang membuatnya mudah untuk memulaiEMF. Mereka dapat digunakan dengan AmazonEC2, AmazonECS, Amazon EKS AWS LambdaAZ-IDInstanceId,, atau Controller serta bidang lain di log seperti SuccessLatency atauHttpResponseCode.
{ "_aws": { "Timestamp": 1634319245221, "CloudWatchMetrics": [ { "Namespace": "workloadname/frontend", "Metrics": [ { "Name": "2xx", "Unit": "Count" }, { "Name": "3xx", "Unit": "Count" }, { "Name": "4xx", "Unit": "Count" }, { "Name": "5xx", "Unit": "Count" }, { "Name": "SuccessLatency", "Unit": "Milliseconds" } ], "Dimensions": [ [ "Controller", "Action", "Region", "AZ-ID", "InstanceId"], [ "Controller", "Action", "Region", "AZ-ID"], [ "Controller", "Action", "Region"] ] } ], "LogGroupName": "/loggroupname" }, "CacheRefresh": false, "Host": "use1-az2-name.example.com", "SourceIp": "34.230.82.196", "TraceId": "|e3628548-42e164ee4d1379bf.", "Path": "/home", "OneBox": false, "Controller": "Home", "Action": "Index", "Region": "us-east-1", "AZ-ID": "use1-az2", "InstanceId": "i-01ab0b7241214d494", "LogGroupName": "/loggroupname", "HttpResponseCode": 200, "2xx": 1, "3xx": 0, "4xx": 0, "5xx": 0, "SuccessLatency": 20 }
Log ini memiliki tiga set dimensi. Mereka berkembang dalam urutan perincian, dari instance ke Availability Zone ke Region (Controllerdan selalu Action disertakan dalam contoh ini). Mereka mendukung pembuatan alarm di seluruh beban kerja Anda yang menunjukkan kapan ada dampak pada tindakan pengontrol tertentu dalam satu instance, dalam satu Availability Zone, atau dalam keseluruhan. Wilayah AWS Dimensi ini digunakan untuk menghitung metrik HTTP respons 2xx, 3xx, 4xx, dan 5xx, serta latensi untuk metrik permintaan yang berhasil (jika permintaan gagal, itu juga akan merekam metrik untuk latensi permintaan yang gagal). Log juga mencatat informasi lain seperti HTTP jalur, IP sumber pemohon, dan apakah permintaan ini memerlukan cache lokal untuk di-refresh. Titik data ini kemudian dapat digunakan untuk menghitung ketersediaan dan latensi dari setiap beban kerja API yang disediakan.
Catatan tentang penggunaan kode HTTP respons untuk metrik ketersediaan
Biasanya, Anda dapat menganggap respons 2xx dan 3xx berhasil, dan 5xx sebagai kegagalan. Kode respons 4xx jatuh di suatu tempat di tengah. Biasanya, mereka diproduksi karena kesalahan klien. Mungkin parameter berada di luar jangkauan yang mengarah ke respons 400
Misalnya, jika Anda telah memperkenalkan validasi masukan yang lebih ketat yang menolak permintaan yang akan berhasil sebelumnya, respons 400 mungkin dihitung sebagai penurunan ketersediaan. Atau mungkin Anda membatasi pelanggan dan mengembalikan respons 429. Sementara membatasi pelanggan melindungi layanan Anda untuk mempertahankan ketersediaannya, dari perspektif pelanggan, layanan tidak tersedia untuk memproses permintaan mereka. Anda harus memutuskan apakah kode respons 4xx adalah bagian dari perhitungan ketersediaan Anda atau tidak.
Meskipun bagian ini telah menguraikan penggunaan CloudWatch sebagai cara untuk mengumpulkan dan menganalisis metrik, itu bukan satu-satunya solusi yang dapat Anda gunakan. Anda dapat memilih untuk juga mengirim metrik ke Amazon Managed Service untuk Prometheus dan Amazon Managed Grafana, tabel Amazon DynamoDB, atau menggunakan solusi pemantauan pihak ketiga. Kuncinya adalah metrik yang dihasilkan oleh beban kerja Anda harus berisi konteks tentang batas isolasi kesalahan beban kerja Anda.
Dengan beban kerja yang menghasilkan metrik dengan dimensi yang disejajarkan dengan batas isolasi kesalahan, Anda dapat membuat observabilitas yang mendeteksi kegagalan terisolasi Availability Zone. Bagian berikut menjelaskan tiga pendekatan gratis untuk mendeteksi kegagalan yang timbul dari penurunan satu Availability Zone.
Topik
