Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan pelatihan elastis di Amazon SageMaker HyperPod
Pelatihan elastis adalah SageMaker HyperPod kemampuan Amazon baru yang secara otomatis menskalakan pekerjaan pelatihan berdasarkan ketersediaan sumber daya komputasi dan prioritas beban kerja. Pekerjaan pelatihan elastis dapat dimulai dengan sumber daya komputasi minimum yang diperlukan untuk pelatihan model dan secara dinamis menskalakan naik atau turun melalui pos pemeriksaan otomatis dan dimulainya kembali di berbagai konfigurasi node (ukuran dunia). Penskalaan dicapai dengan secara otomatis menyesuaikan jumlah replika data-paralel. Selama periode pemanfaatan klaster yang tinggi, pekerjaan pelatihan elastis dapat dikonfigurasi untuk secara otomatis menurunkan skala sebagai respons terhadap permintaan sumber daya dari pekerjaan dengan prioritas lebih tinggi, membebaskan komputasi untuk beban kerja kritis. Ketika sumber daya habis selama periode di luar puncak, pekerjaan pelatihan elastis secara otomatis menskalakan kembali untuk mempercepat pelatihan, lalu turunkan kembali ketika beban kerja dengan prioritas lebih tinggi membutuhkan sumber daya lagi.
Pelatihan elastis dibangun di atas operator HyperPod pelatihan dan mengintegrasikan komponen-komponen berikut:
-
SageMaker HyperPod Tata Kelola Tugas Amazon untuk antrian pekerjaan, prioritas, dan penjadwalan
-
PyTorch Distributed Checkpoint (DCP)
untuk manajemen status dan pos pemeriksaan yang dapat diskalakan, seperti DCP
Kerangka kerja yang didukung
-
PyTorch dengan Distributed Data Parallel (DDP) dan Fully Sharded Data Parallel (FSDP)
-
PyTorch Pos Pemeriksaan Terdistribusi (DCP)
Prasyarat
SageMaker HyperPod Kluster EKS
Anda harus memiliki SageMaker HyperPod cluster yang berjalan dengan orkestrasi Amazon EKS. Untuk informasi tentang membuat kluster HyperPod EKS, lihat:
SageMaker HyperPod Operator Pelatihan
Pelatihan Elastis didukung dalam operator pelatihan v. 1.2 ke atas.
Untuk menginstal operator pelatihan sebagai add-on EKS, lihat: https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(Disarankan) Instal dan konfigurasikan Task Governance dan Kueue
Kami merekomendasikan menginstal dan mengonfigurasi Kueue melalui HyperPod Tata Kelola Tugas untuk menentukan prioritas beban kerja dengan pelatihan elastis. Kueue menyediakan manajemen beban kerja yang lebih kuat dengan antrian, prioritas, penjadwalan geng, pelacakan sumber daya, dan preemption yang anggun yang penting untuk beroperasi di lingkungan pelatihan multi-tenant.
-
Penjadwalan geng memastikan bahwa semua pod yang diperlukan dari pekerjaan pelatihan dimulai bersama. Ini mencegah situasi di mana beberapa pod dimulai sementara yang lain tetap tertunda, yang dapat menyebabkan sumber daya terbuang sia-sia.
-
Preemption yang lembut memungkinkan pekerjaan elastis dengan prioritas rendah untuk menghasilkan sumber daya ke beban kerja dengan prioritas lebih tinggi. Pekerjaan elastis dapat diturunkan dengan anggun tanpa diusir secara paksa, meningkatkan stabilitas klaster secara keseluruhan.
Sebaiknya konfigurasi komponen Kueue berikut:
-
PriorityClasses untuk mendefinisikan kepentingan pekerjaan relatif
-
ClusterQueues untuk mengelola berbagi sumber daya global dan kuota di seluruh tim atau beban kerja
-
LocalQueues untuk merutekan pekerjaan dari ruang nama individu ke ruang nama yang sesuai ClusterQueue
Untuk pengaturan yang lebih lanjut, Anda juga dapat memasukkan:
-
Fair-share kebijakan untuk menyeimbangkan penggunaan sumber daya di beberapa tim
-
Aturan preemption khusus untuk menegakkan SLA organisasi atau kontrol biaya
Silakan merujuk ke:
(Disarankan) Siapkan ruang nama pengguna dan kuota sumber daya
Saat menerapkan fitur ini di Amazon EKS, kami sarankan untuk menerapkan serangkaian konfigurasi tingkat klaster dasar untuk memastikan isolasi, keadilan sumber daya, dan konsistensi operasional di seluruh tim.
Namespace dan Konfigurasi Akses
Atur beban kerja Anda menggunakan ruang nama terpisah untuk setiap tim atau proyek. Ini memungkinkan Anda untuk menerapkan isolasi dan tata kelola yang halus. Kami juga merekomendasikan untuk mengonfigurasi pemetaan AWS IAM ke Kubernetes RBAC untuk mengaitkan pengguna atau peran IAM individu dengan ruang nama yang sesuai.
Praktik utama meliputi:
-
Petakan peran IAM ke akun layanan Kubernetes menggunakan Peran IAM untuk Akun Layanan (IRSA) saat beban kerja membutuhkan izin. AWS https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
Terapkan kebijakan RBAC untuk membatasi pengguna hanya pada ruang nama yang ditentukan (mis.,
Role/RoleBindingbukan izin di seluruh klaster).
Kendala Sumber Daya dan Komputasi
Untuk mencegah perselisihan sumber daya dan memastikan penjadwalan yang adil di seluruh tim, terapkan kuota dan batasan di tingkat namespace:
-
ResourceQuotas untuk membatasi jumlah CPU, memori, penyimpanan, dan objek agregat (pod, PVC, layanan, dll.).
-
LimitRanges untuk menerapkan batas CPU dan memori per-pod atau per-container default dan maksimum.
-
PodDisruptionBudgets (PDB) sesuai kebutuhan untuk menentukan ekspektasi ketahanan.
-
Opsional: kendala Namespace-level antrian (misalnya, melalui Tata Kelola Tugas atau Kueue) untuk mencegah pengguna mengirimkan pekerjaan secara berlebihan.
Kendala ini membantu menjaga stabilitas klaster dan mendukung penjadwalan yang dapat diprediksi untuk beban kerja pelatihan terdistribusi.
Auto-scaling
SageMaker HyperPod pada EKS mendukung penskalaan otomatis cluster melalui Karpenter. Ketika Karpenter atau penyedia sumber daya serupa digunakan bersama dengan pelatihan elastis, cluster serta pekerjaan pelatihan elastis dapat ditingkatkan secara otomatis setelah pekerjaan pelatihan elastis diserahkan. Ini karena operator pelatihan elastis mengambil pendekatan serakah, selalu meminta lebih dari sumber daya komputasi yang tersedia hingga mencapai batas maksimum yang ditetapkan oleh pekerjaan. Hal ini terjadi karena operator pelatihan elastis terus meminta sumber daya tambahan sebagai bagian dari eksekusi pekerjaan elastis, yang dapat memicu penyediaan node. Penyedia sumber daya berkelanjutan seperti Karpenter akan melayani permintaan dengan meningkatkan cluster komputasi.
Agar peningkatan skala ini dapat diprediksi dan terkendali, kami sarankan untuk mengonfigurasi tingkat ruang nama ResourceQuotas di ruang nama tempat pekerjaan pelatihan elastis dibuat. ResourceQuotas membantu membatasi sumber daya maksimum yang dapat diminta pekerjaan, mencegah pertumbuhan klaster yang tidak terbatas sambil tetap mengizinkan perilaku elastis dalam batas yang ditentukan.
Misalnya, ResourceQuota untuk 8 ml.p5.48xlarge instance akan memiliki bentuk berikut:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
Bangun Wadah Pelatihan
HyperPod operator pelatihan bekerja dengan PyTorch peluncur khusus yang disediakan melalui paket python HyperPod Elastic Agent () https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun perintah dengan hyperpodrun untuk meluncurkan pelatihan. Untuk lebih jelasnya, silakan lihat:
Contoh wadah pelatihan:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
Modifikasi kode pelatihan
SageMaker HyperPod menyediakan satu set resep yang sudah dikonfigurasi untuk dijalankan dengan Kebijakan Elastis.
Untuk mengaktifkan pelatihan elastis untuk skrip PyTorch pelatihan khusus, Anda perlu melakukan modifikasi kecil pada loop pelatihan Anda. Panduan ini memandu Anda melalui modifikasi yang diperlukan untuk memastikan pekerjaan pelatihan Anda merespons peristiwa penskalaan elastis yang terjadi saat ketersediaan sumber daya komputasi berubah. Selama semua peristiwa elastis (misalnya, node tersedia, atau node didahului), pekerjaan pelatihan menerima sinyal peristiwa elastis yang digunakan untuk mengoordinasikan shutdown yang anggun dengan menyimpan pos pemeriksaan, dan melanjutkan pelatihan dengan memulai kembali dari pos pemeriksaan yang disimpan dengan konfigurasi dunia baru. Untuk mengaktifkan pelatihan elastis dengan skrip pelatihan khusus, Anda perlu:
Mendeteksi Peristiwa Penskalaan Elastis
Dalam loop pelatihan Anda, periksa peristiwa elastis selama setiap iterasi:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
Menerapkan Penghematan Pos Pemeriksaan dan Pemuatan Pos Pemeriksaan
Catatan: Sebaiknya gunakan PyTorch Distributed Checkpoint (DCP) untuk menyimpan status model dan pengoptimal, karena DCP mendukung melanjutkan dari pos pemeriksaan dengan ukuran dunia yang berbeda. Format pos pemeriksaan lainnya mungkin tidak mendukung pemuatan pos pemeriksaan pada ukuran dunia yang berbeda, dalam hal ini Anda harus menerapkan logika khusus untuk menangani perubahan ukuran dunia yang dinamis.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(Opsional) Gunakan dataloader stateful
Jika Anda hanya berlatih untuk satu zaman (yaitu, satu lintasan tunggal melalui seluruh kumpulan data), model harus melihat setiap sampel data tepat sekali. Jika pekerjaan pelatihan berhenti di pertengahan zaman dan dilanjutkan dengan ukuran dunia yang berbeda, sampel data yang diproses sebelumnya akan diulang jika status dataloader tidak dipertahankan. Dataloader stateful mencegah hal ini dengan menyimpan dan memulihkan posisi dataloader, memastikan bahwa proses yang dilanjutkan berlanjut dari peristiwa penskalaan elastis tanpa memproses ulang sampel apa pun. Sebaiknya gunakan StatefulDataLoaderstate_dict() dan load_state_dict() metode torch.utils.data.DataLoader tersebut, memungkinkan pemeriksaan tengah zaman dari proses pemuatan data.
Mengirimkan pekerjaan pelatihan elastis
HyperPod operator pelatihan mendefinisikan jenis sumber daya baru -hyperpodpytorchjob. Pelatihan elastis memperluas jenis sumber daya ini dan menambahkan bidang yang disorot di bawah ini:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
Menggunakan kubectl
Anda selanjutnya dapat meluncurkan pelatihan elastis dengan perintah berikut.
kubectl apply -f elastic-training-job.yaml
Menggunakan SageMaker Resep
Pekerjaan pelatihan elastis dapat diluncurkan melalui SageMaker HyperPod resep
catatan
Kami telah menyertakan 46 resep elastis untuk pekerjaan SFO dan DPO di Resep Hyperpod. Pengguna dapat meluncurkan pekerjaan tersebut dengan perubahan satu baris di atas skrip peluncur statis yang ada:
++recipes.elastic_policy.is_elastic=true
Selain resep statis, resep elastis menambahkan bidang berikut untuk menentukan perilaku elastis:
Kebijakan Elastis
elastic_policyBidang mendefinisikan konfigurasi tingkat pekerjaan untuk pekerjaan pelatihan elastis, ia memiliki konfigurasi berikut:
-
is_elastic:bool- jika pekerjaan ini adalah pekerjaan elastis -
min_nodes:int- jumlah minimum node yang digunakan untuk pelatihan elastis -
max_nodes:int- jumlah maksimum node yang digunakan untuk pelatihan elastis -
replica_increment_step:int- penambahan jumlah pod dalam grup ukuran tetap, bidang ini saling eksklusif untuk yang kita definisikan nanti.scale_config -
use_graceful_shutdown:bool- jika menggunakan shutdown anggun selama acara penskalaan, default ke.true -
scaling_timeout:int- waktu tunggu di detik selama acara penskalaan sebelum batas waktu -
graceful_shutdown_timeout:int- waktu tunggu untuk shutdown yang anggun
Berikut ini adalah contoh definisi bidang ini, Anda juga dapat menemukannya di repo Resep Hyperpod dalam resep: recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
Konfigurasi Skala
scale_configBidang mendefinisikan konfigurasi utama pada setiap skala tertentu. Ini adalah kamus nilai kunci, di mana kunci adalah bilangan bulat yang mewakili skala target dan nilai adalah bagian dari resep dasar. Pada <key> skala besar, kami menggunakan <value> untuk memperbarui konfigurasi spesifik dalam base/static resep. Berikut ini menunjukkan contoh bidang ini:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
Konfigurasi di atas mendefinisikan konfigurasi pelatihan pada skala 2 dan 3. Dalam kedua kasus, kami menggunakan tingkat pembelajaran4e-4, ukuran batch128. Tetapi pada skala 2, kami menggunakan 8, sedangkan skala 3, kami menggunakan ukuran batch yang tidak rata karena ukuran batch kereta tidak dapat dibagi secara merata menjadi 3 node. micro_train_batch_size
Ukuran Batch Tidak Rata
Ini adalah bidang untuk menentukan perilaku distribusi batch ketika ukuran batch global tidak dapat dibagi secara merata dengan jumlah peringkat. Ini tidak khusus untuk pelatihan elastis, tetapi ini adalah enabler untuk granularitas penskalaan yang lebih halus.
-
use_uneven_batch:bool- jika menggunakan distribusi batch yang tidak merata -
num_dp_groups_with_small_batch_size:int- dalam distribusi batch yang tidak merata, beberapa peringkat menggunakan ukuran batch lokal yang lebih kecil, di mana yang lain menggunakan ukuran batch yang lebih besar. Ukuran batch global harus sama dengansmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- nilai ini adalah ukuran batch lokal yang lebih kecil -
large_local_batch_size:int- nilai ini adalah ukuran batch lokal yang lebih besar
Pantau pelatihan tentang MLFlow
Pekerjaan resep Hyperpod mendukung observabilitas melalui MLFlow. Pengguna dapat menentukan konfigurasi MLFlow dalam resep:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
Konfigurasi ini dipetakan ke pengaturan MLFlow
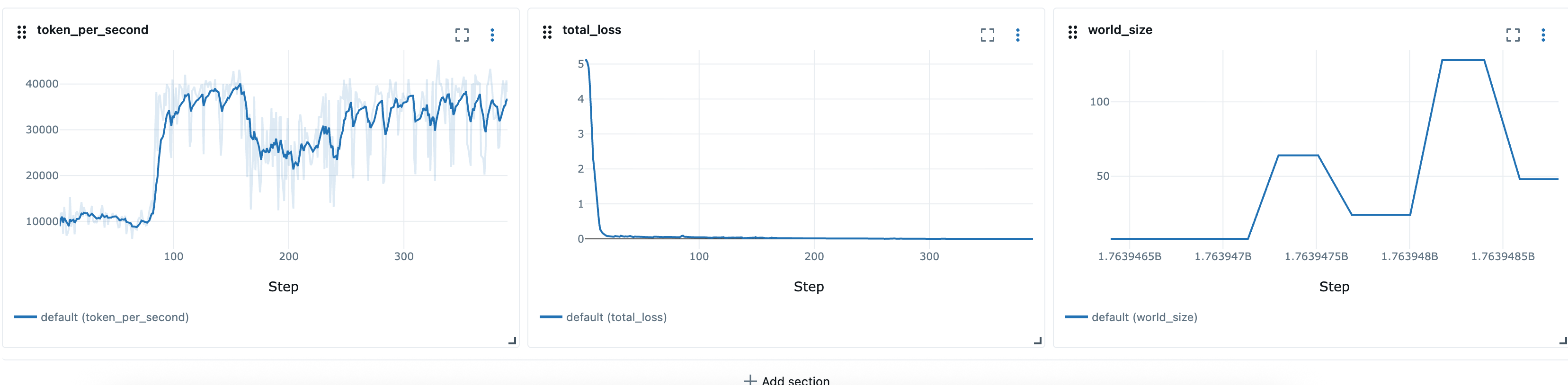
Setelah mendefinisikan resep elastis, kita dapat menggunakan skrip peluncur, seperti launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh untuk meluncurkan pekerjaan pelatihan elastis. Ini mirip dengan meluncurkan pekerjaan statis menggunakan resep Hyperpod.
catatan
Pekerjaan pelatihan elastis dari dukungan resep secara otomatis dilanjutkan dari pos pemeriksaan terbaru, namun, secara default, setiap restart membuat direktori pelatihan baru. Untuk mengaktifkan melanjutkan dari pos pemeriksaan terakhir dengan benar, kita perlu memastikan direktori pelatihan yang sama digunakan kembali. Hal ini dapat dilakukan dengan mengatur
recipes.training_config.training_args.override_training_dir=true
Use-case contoh dan batasan
Scale-up ketika lebih banyak sumber daya tersedia
Ketika lebih banyak sumber daya tersedia di cluster (misalnya, beban kerja lainnya selesai). Selama acara ini, pengontrol pelatihan akan secara otomatis meningkatkan pekerjaan pelatihan. Perilaku ini dijelaskan di bawah ini.
Untuk mensimulasikan situasi ketika lebih banyak sumber daya tersedia, kami dapat mengirimkan pekerjaan prioritas tinggi, dan kemudian melepaskan sumber daya kembali dengan menghapus pekerjaan prioritas tinggi.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
Perilaku yang diharapkan:
-
Operator pelatihan membuat Beban Kerja Kueue Ketika pekerjaan pelatihan elastis meminta perubahan ukuran dunia, operator pelatihan menghasilkan objek Beban Kerja Kueue tambahan yang mewakili persyaratan sumber daya baru.
-
Kueue mengakui Workload Kueue mengevaluasi permintaan berdasarkan sumber daya, prioritas, dan kebijakan antrian yang tersedia. Setelah disetujui, Beban Kerja diterima.
-
Operator pelatihan membuat Pod tambahan Setelah masuk, operator meluncurkan pod tambahan yang diperlukan untuk mencapai ukuran dunia baru.
-
Ketika pod baru sudah siap, operator pelatihan mengirimkan sinyal peristiwa elastis khusus ke skrip pelatihan.
-
Pekerjaan pelatihan melakukan pemeriksaan, untuk mempersiapkan shutdown yang anggun Proses pelatihan secara berkala memeriksa sinyal peristiwa elastis dengan memanggil fungsi elastic_event_detected (). Setelah terdeteksi, ia memulai pos pemeriksaan. Setelah pos pemeriksaan berhasil diselesaikan, proses pelatihan keluar dengan bersih.
-
Operator pelatihan memulai kembali pekerjaan dengan ukuran dunia baru Operator menunggu semua proses keluar, kemudian memulai kembali pekerjaan pelatihan menggunakan ukuran dunia yang diperbarui dan pos pemeriksaan terbaru.
Catatan: Ketika Kueue tidak digunakan, operator pelatihan melewatkan dua langkah pertama. Ini segera mencoba untuk membuat pod tambahan yang diperlukan untuk ukuran dunia baru. Jika sumber daya yang cukup tidak tersedia di klaster, pod ini akan tetap dalam status Pending hingga kapasitas tersedia.

Preemption oleh pekerjaan prioritas tinggi
Pekerjaan elastis dapat diperkecil secara otomatis ketika pekerjaan prioritas tinggi membutuhkan sumber daya. Untuk mensimulasikan perilaku ini, Anda dapat mengirimkan pekerjaan pelatihan elastis, yang menggunakan jumlah maksimum sumber daya yang tersedia sejak awal pelatihan, daripada menyerahkan pekerjaan prioritas tinggi, dan mengamati perilaku preemption.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
Ketika pekerjaan dengan prioritas tinggi membutuhkan sumber daya, Kueue dapat mendahului beban kerja Pelatihan Elastis dengan prioritas rendah (mungkin ada lebih dari 1 objek Beban Kerja yang terkait dengan pekerjaan Pelatihan Elastis). Proses preemption mengikuti urutan ini:
-
Pekerjaan prioritas tinggi diserahkan Pekerjaan menciptakan Beban Kerja Kueue baru, tetapi Beban Kerja tidak dapat diterima karena sumber daya klaster yang tidak mencukupi.
-
Kueue mendahului salah satu Beban Kerja Pekerjaan Pelatihan Elastis Pekerjaan elastis mungkin memiliki beberapa Beban Kerja aktif (satu per konfigurasi ukuran dunia). Kueue memilih satu untuk didahului berdasarkan kebijakan prioritas dan antrian.
-
Operator pelatihan mengirimkan sinyal peristiwa elastis. Setelah pencegahan dipicu, operator pelatihan memberi tahu proses pelatihan yang sedang berjalan untuk berhenti dengan anggun.
-
Proses pelatihan melakukan pemeriksaan. Pekerjaan pelatihan secara berkala memeriksa sinyal peristiwa elastis. Ketika terdeteksi, ia memulai pos pemeriksaan terkoordinasi untuk mempertahankan kemajuan sebelum dimatikan.
-
operator pelatihan membersihkan pod dan beban kerja. Operator menunggu penyelesaian pos pemeriksaan, lalu menghapus pod pelatihan yang merupakan bagian dari Beban Kerja yang telah dipreempted. Ini juga menghapus objek Workload yang sesuai dari Kueue.
-
Beban kerja prioritas tinggi diterima. Dengan sumber daya yang dibebaskan, Kueue mengakui pekerjaan prioritas tinggi, memungkinkannya untuk memulai eksekusi.

Preemption dapat menyebabkan seluruh pekerjaan pelatihan berhenti, yang mungkin tidak diinginkan untuk semua alur kerja. Untuk menghindari suspensi pekerjaan penuh sambil tetap memungkinkan penskalaan elastis, pelanggan dapat mengonfigurasi dua tingkat prioritas yang berbeda dalam pekerjaan pelatihan yang sama dengan mendefinisikan dua bagian: replicaSpec
-
ReplicaSpec primer (tetap) dengan prioritas normal atau tinggi
-
Berisi jumlah replika minimum yang diperlukan untuk menjaga pekerjaan pelatihan tetap berjalan.
-
Menggunakan yang lebih tinggi PriorityClass, memastikan replika ini tidak pernah didahului.
-
Mempertahankan kemajuan dasar bahkan ketika cluster berada di bawah tekanan sumber daya.
-
-
ReplicaSpec elastis (dapat diskalakan) dengan prioritas lebih rendah
-
Berisi replika opsional tambahan yang memberikan komputasi ekstra selama penskalaan elastis.
-
Menggunakan yang lebih rendah PriorityClass, memungkinkan Kueue untuk mendahului replika ini ketika pekerjaan dengan prioritas lebih tinggi membutuhkan sumber daya.
-
Memastikan hanya bagian elastis yang direklamasi, sementara pelatihan inti berlanjut tanpa gangguan.
-
Konfigurasi ini memungkinkan pencegahan sebagian, di mana hanya kapasitas elastis yang direklamasi—mempertahankan kontinuitas pelatihan sambil tetap mendukung pembagian sumber daya yang adil di lingkungan multi-penyewa. Contoh:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
Menyerahkan penggusuran pod, pod crash, dan degradasi perangkat keras:
Operator HyperPod pelatihan menyertakan mekanisme bawaan untuk memulihkan proses pelatihan ketika tiba-tiba terputus. Interupsi dapat terjadi karena berbagai alasan, seperti kegagalan kode pelatihan, penggusuran pod, kegagalan node, degradasi perangkat keras, dan masalah runtime lainnya.
Ketika ini terjadi, operator secara otomatis mencoba membuat ulang pod yang terpengaruh dan melanjutkan pelatihan dari pos pemeriksaan terbaru. Jika pemulihan tidak segera memungkinkan, misalnya, karena kapasitas cadangan yang tidak mencukupi, operator dapat melanjutkan kemajuan dengan mengurangi sementara ukuran dunia dan mengurangi pekerjaan pelatihan elastis.
Ketika pekerjaan pelatihan elastis mogok atau kehilangan replika, sistem berperilaku sebagai berikut:
-
Fase Pemulihan (menggunakan node cadangan) Pengontrol Pelatihan
faultyScaleDownTimeoutInSecondsmenunggu sumber daya tersedia dan mencoba memulihkan replika yang gagal dengan memindahkan pod pada kapasitas cadangan. -
Penurunan skala elastis Jika pemulihan tidak dimungkinkan dalam jendela batas waktu, operator pelatihan menurunkan skala pekerjaan ke ukuran dunia yang lebih kecil (jika kebijakan elastis pekerjaan mengizinkannya). Pelatihan kemudian dilanjutkan dengan replika yang lebih sedikit.
-
Peningkatan skala elastis Ketika sumber daya tambahan tersedia kembali, operator secara otomatis menskalakan pekerjaan pelatihan kembali ke ukuran dunia yang diinginkan.
Mekanisme ini memastikan bahwa pelatihan dapat dilanjutkan dengan waktu henti minimal, bahkan di bawah tekanan sumber daya atau kegagalan infrastruktur sebagian, sambil tetap memanfaatkan penskalaan elastis.
Gunakan pelatihan elastis dengan HyperPod fitur lain
Pelatihan elastis saat ini tidak mendukung kemampuan pelatihan tanpa pemeriksaan, pos pemeriksaan berjenjang HyperPod terkelola, atau instans Spot.
catatan
Kami mengumpulkan metrik operasional gabungan dan anonim rutin tertentu untuk menyediakan ketersediaan layanan yang penting. Pembuatan metrik ini sepenuhnya otomatis dan tidak melibatkan tinjauan manusia terhadap beban kerja pelatihan model yang mendasarinya. Metrik ini berhubungan dengan pekerjaan dan operasi penskalaan, manajemen sumber daya, dan fungsionalitas layanan penting.
