Amazon Redshift tidak akan lagi mendukung pembuatan UDF Python baru mulai Patch 198. UDF Python yang ada akan terus berfungsi hingga 30 Juni 2026. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kapasitas komputasi untuk Amazon Redshift Serverless
Dengan Amazon Redshift Serverless, skala kapasitas komputasi secara otomatis naik dan turun agar sesuai dengan kebutuhan beban kerja Anda. Kapasitas komputasi mengacu pada daya pemrosesan dan memori yang dialokasikan ke beban kerja Amazon Redshift Tanpa Server Anda. Kasus penggunaan umum termasuk menangani periode lalu lintas puncak, menjalankan analisis kompleks, atau memproses volume data yang besar secara efisien. Persyaratan berikut memberikan detail tentang cara Amazon Redshift mengelola kapasitas komputasi.
RPU
Amazon Redshift Serverless mengukur kapasitas gudang data di Redshift Processing Units (RPU). RPU adalah sumber daya yang digunakan untuk menangani beban kerja. Satu RPU menyediakan memori 16 GB.
Kapasitas dasar
Setelan ini menentukan kapasitas gudang data dasar yang digunakan Amazon Redshift untuk menyajikan kueri. Kapasitas dasar ditentukan dalam RPU. Anda dapat mengatur kapasitas dasar di Redshift Processing Units (RPU). Menetapkan kapasitas dasar yang lebih tinggi memastikan peningkatan kinerja kueri, terutama untuk pekerjaan pemrosesan data yang membutuhkan banyak sumber daya. Kapasitas dasar default untuk Amazon Redshift Serverless adalah 128 RPU. Anda dapat menyesuaikan pengaturan kapasitas Basis dari 4 RPU ke 512 RPU. Anda dapat mengatur nilai ini ke 4 RPU, atau dalam satuan 8 pada atau di atas 8 RPU (8,16,24... 512). Anda dapat menyetel nilai ini menggunakan AWS konsol, operasi UpdateWorkgroup API, atau update-workgroup operasi di AWS CLI.
Dengan kapasitas dasar minimum 4 RPU, Anda memiliki fleksibilitas untuk menjalankan beban kerja yang lebih sederhana hingga lebih kompleks berdasarkan biaya gudang data dan persyaratan kapasitas Anda. Kapasitas RPU 4 basis ditargetkan ke gudang yang berisi data kurang dari 32TB, dan kapasitas RPU dasar RPU 8, 16, dan 24 ditargetkan untuk beban kerja yang membutuhkan kurang dari 128TB data. Jika kebutuhan data Anda lebih besar dari 128 TB, Anda harus menggunakan minimal 32 RPU dasar. Selain itu, untuk beban kerja yang memiliki tabel dengan kolom jumlah besar dan konkurensi yang lebih tinggi, sebaiknya gunakan 32 atau lebih RPU dasar.
RPU dasar maksimum yang tersedia, 1024, menambahkan tingkat sumber daya komputasi tertinggi ke beban kerja Anda. Ini memberikan lebih banyak fleksibilitas untuk mendukung beban kerja dengan kompleksitas besar dan mempercepat pemuatan dan kueri data.
catatan
Kapasitas RPU dasar maksimum yang diperluas sebesar 1024 tersedia di berikut ini. Wilayah AWS Di wilayah lain, kapasitas dasar maksimum adalah 512 RPU.
Timur AS (N. Virginia)
AS Timur (Ohio)
-
AS Barat (Oregon)
-
Europe (Ireland)
-
Eropa (Frankfurt)
Anda dapat menambah atau mengurangi RPU dalam satuan 32 saat mengatur kapasitas dasar antara 512-1024.
Jika Anda mengelola beban kerja yang lebih besar dan lebih kompleks, pertimbangkan untuk meningkatkan ukuran gudang data Redshift Tanpa Server Anda. Gudang yang lebih besar memiliki akses ke sumber daya komputasi yang lebih banyak, memungkinkan mereka memproses kueri dengan lebih efisien.
Berikut adalah beberapa contoh di mana memiliki kapasitas dasar yang lebih tinggi bermanfaat:
Anda memiliki kueri kompleks yang membutuhkan waktu lama untuk dijalankan
Tabel Anda memiliki sejumlah besar kolom.
Kueri Anda memiliki jumlah JOIN yang tinggi.
Kueri Anda mengumpulkan atau memindai sejumlah besar data dari sumber eksternal, seperti data lake.
Untuk informasi lebih lanjut tentang kuota dan batas Amazon Redshift Tanpa Server, buka. Kuota untuk objek Amazon Redshift Tanpa Server
Pertimbangan dan batasan untuk kapasitas Amazon Redshift Tanpa Server
Berikut ini adalah pertimbangan dan batasan untuk kapasitas Amazon Redshift Serverless. Untuk pertimbangan Redshift Tanpa Server umum, lihat. Pertimbangan saat menggunakan Amazon Redshift Serverless
-
Konfigurasi 4 RPU dasar mendukung kapasitas penyimpanan terkelola hingga 32 TB. Jika Anda menggunakan lebih dari 32 TB penyimpanan terkelola, Anda tidak dapat mengatur RPU dasar menjadi kurang dari 8 RPU.
-
Konfigurasi 8 atau 16 RPU dasar mendukung kapasitas penyimpanan terkelola Redshift hingga 128 TB. Jika Anda menggunakan lebih dari 128 TB penyimpanan terkelola, Anda tidak dapat mengatur basis ke kurang dari 32 RPU.
-
Mengedit kapasitas dasar grup kerja Anda mungkin membatalkan beberapa kueri yang berjalan di workgroup Anda.
Redshift Serverless menskalakan RPU untuk gudang data Anda menggunakan peningkatan berikut:
4 hingga 8 RPU: Peningkatan langkah 4 RPU.
8 hingga 512 RPU: Peningkatan langkah 8 RPU.
512 hingga 1024 RPU: Peningkatan dalam langkah 32 RPU.
-
Vacuum boost hanya didukung untuk 8 RPU dan Above. Untuk 8 RPU dan kurang, gunakan perintah berikut sebagai gantinya:
VACUUM [FULL | SORT ONLY | DELETE ONLY | REINDEX | RECLUSTER] [table_name] [TO threshold PERCENT]
Redshift Tanpa Server dengan kapasitas 4 Unit Pemrosesan Redshift (RPU)
Redshift Tanpa Server dengan kapasitas 4 RPU dasar sangat ideal untuk beban kerja yang lebih kecil atau kurang menuntut. Titik masuk ini menawarkan solusi yang fleksibel dan hemat biaya. Konfigurasi entry-level ini mendukung gudang data hingga sumber daya berikut:
Penyimpanan terkelola Redshift hingga 32 TB.
Maksimal 100 kolom per tabel
Memori 64 GB
Jika Anda perlu melampaui batasan ini, Anda harus meningkatkan kapasitas dasar Anda secara manual, daripada mengandalkan auto-scaling. Setelah Anda menskalakan gudang data Anda melebihi 4 RPU, gudang data Anda akan terus menggunakan lebih banyak RPU, dan Amazon Redshift tidak akan menskalakan gudang data Anda kembali ke 4 RPU.
catatan
Anda dapat membuat tabel dengan lebih dari 100 kolom saat menggunakan 4 RPU dasar, namun, kami menyarankan Anda membatasi tabel hingga 100 kolom. Melebihi batas ini dapat menyebabkan gudang data Anda kehabisan memori selama eksekusi kueri, yang menurunkan kinerja.
Anda dapat membuat gudang data yang menggunakan 4 RPU sebagai berikut: Wilayah AWS
AS Timur (Ohio)
AS Timur (Virginia Utara)
AS Barat (California Utara)
AS Barat (Oregon)
Asia Pasifik (Mumbai)
Asia Pasifik (Singapura)
Asia Pasifik (Sydney)
Asia Pasifik (Tokyo)
Eropa (Irlandia)
Eropa (Stockholm)
AI-driven penskalaan dan optimasi
Fitur AI-driven penskalaan dan pengoptimalan tersedia di semua AWS Wilayah di mana Amazon Redshift Tanpa Server tersedia.
Amazon Redshift Serverless menawarkan fitur AI-driven penskalaan dan pengoptimalan tingkat lanjut untuk memenuhi beragam persyaratan beban kerja. Gudang data mungkin memiliki masalah penyediaan berikut:
Gudang data dapat disediakan secara berlebihan untuk meningkatkan kinerja kueri intensif sumber daya
Gudang data mungkin kurang disediakan untuk menghemat biaya.
Mencapai keseimbangan yang tepat antara kinerja dan biaya untuk beban kerja gudang data sangat menantang, terutama dengan kueri ad-hoc dan volume data yang terus bertambah. Saat menjalankan beban kerja campuran, yang terdiri dari kueri intensif sumber daya rendah dan tinggi, ada kebutuhan untuk penskalaan cerdas. Fitur AI-driven penskalaan dan pengoptimalan secara otomatis menskalakan komputasi atau RPU Tanpa Server sebagai respons terhadap pertumbuhan data. Fitur ini juga membantu mempertahankan kinerja kueri dalam sasaran harga-kinerja yang ditargetkan. AI-driven Penskalaan dan pengoptimalan secara dinamis mengalokasikan sumber daya komputasi saat volume data meningkat, memastikan kueri terus memenuhi target kinerja. AI-driven penskalaan dan pengoptimalan memungkinkan layanan beradaptasi dengan mulus terhadap perubahan persyaratan beban kerja, tanpa perlu intervensi manual atau perencanaan kapasitas yang kompleks.
Amazon Redshift Serverless menyediakan solusi penskalaan yang lebih komprehensif dan responsif berdasarkan faktor-faktor seperti kompleksitas kueri dan volume data. Fitur ini memungkinkan untuk mengoptimalkan kinerja harga beban kerja sambil mempertahankan fleksibilitas untuk menangani berbagai beban kerja dan mengembangkan kumpulan data secara efisien. Amazon Redshift Serverless dapat secara otomatis melakukan AI-driven pengoptimalan ke titik akhir Amazon Redshift Tanpa Server untuk memenuhi target performa harga yang ditentukan untuk grup kerja Tanpa Server Anda. Optimalisasi harga-kinerja otomatis ini sangat membantu jika Anda tidak tahu kapasitas dasar apa yang harus ditetapkan untuk beban kerja Anda, atau jika beberapa bagian dari beban kerja Anda mungkin mendapat manfaat dari lebih banyak sumber daya yang dialokasikan.
Contoh
Jika organisasi Anda biasanya menjalankan beban kerja yang hanya memerlukan 32 RPU tetapi tiba-tiba memperkenalkan kueri yang lebih kompleks, Anda mungkin tidak mengetahui kapasitas dasar yang sesuai. Menetapkan kapasitas dasar yang lebih tinggi menghasilkan kinerja yang lebih baik tetapi juga menimbulkan biaya yang lebih tinggi, sehingga biayanya mungkin tidak sesuai dengan harapan Anda. Menggunakan AI-driven penskalaan dan pengoptimalan sumber daya, Amazon Redshift Serverless secara otomatis menyesuaikan RPU untuk memenuhi target performa harga sekaligus menjaga agar biaya tetap dioptimalkan untuk organisasi Anda. Optimalisasi otomatis ini berguna terlepas dari ukuran beban kerja. Pengoptimalan otomatis dapat membantu Anda memenuhi target kinerja harga organisasi Anda jika Anda memiliki sejumlah kueri kompleks.
catatan
Price-performance target adalah pengaturan khusus kelompok kerja. Kelompok kerja yang berbeda dapat memiliki target harga-kinerja yang berbeda.
Agar biaya tetap dapat diprediksi, tetapkan batas kapasitas maksimum yang diizinkan untuk dialokasikan oleh Amazon Redshift Serverless ke beban kerja Anda.
Untuk mengonfigurasi target harga-kinerja, gunakan konsol. AWS Target harga-kinerja diaktifkan secara default untuk semua grup kerja Tanpa Server baru dan disetel ke Balanced. Anda dapat memodifikasi target harga-kinerja setelah Anda membuat grup kerja Tanpa Server.
Untuk mengedit target harga-kinerja untuk grup kerja Anda
Di konsol Amazon Redshift Tanpa Server, pilih konfigurasi Workgroup.
Pilih workgroup yang ingin Anda edit target harga-kinerja. Pilih tab Performance, lalu pilih Edit.
Pilih Price-performancetarget, dan sesuaikan slider ke pengaturan yang Anda inginkan.
Pilih Simpan perubahan.
Untuk memperbarui jumlah maksimum RPU yang dapat dialokasikan Amazon Redshift Serverless ke beban kerja Anda, pilih tab Batas pada bagian Konfigurasi Workgroup.
Anda dapat menggunakan slider Price-performance target untuk mengatur keseimbangan yang Anda inginkan antara biaya dan kinerja. Dengan menggerakkan slider, Anda dapat memilih salah satu opsi berikut:
Mengoptimalkan biaya — Pengaturan ini memprioritaskan penghematan biaya. Amazon Redshift Serverless mencoba untuk secara otomatis meningkatkan kapasitas komputasi saat melakukannya tidak menimbulkan biaya tambahan. Amazon Redshift Serverless juga mencoba mengurangi sumber daya komputasi dengan biaya lebih rendah, mungkin meningkatkan runtime kueri.
Seimbang — Pengaturan ini menciptakan keseimbangan antara kinerja dan biaya. Amazon Redshift Tanpa Server menskalakan kinerja, dan dapat menghasilkan kenaikan atau penurunan biaya yang moderat. Ini adalah pengaturan yang disarankan untuk sebagian besar gudang data Amazon Redshift Tanpa Server.
Mengoptimalkan kinerja - Pengaturan ini memprioritaskan kinerja. Amazon Redshift menskalakan secara agresif untuk kinerja tinggi, berpotensi menimbulkan biaya lebih tinggi.
Posisi menengah: Anda juga dapat mengatur slider ke salah satu dari dua posisi perantara antara Seimbang dan Mengoptimalkan biaya atau Mengoptimalkan untuk kinerja. Gunakan pengaturan ini jika optimasi penuh untuk biaya atau kinerja terlalu ekstrim.
Pertimbangan saat memilih target harga-kinerja Anda
Anda dapat menggunakan penggeser harga-kinerja untuk memilih target harga-kinerja yang Anda inginkan untuk beban kerja Anda. Algoritma AI-driven penskalaan dan pengoptimalan belajar dari waktu ke waktu dari riwayat beban kerja Anda, dan meningkatkan prediksi dan akurasi keputusan.
Contoh
Untuk contoh ini, asumsikan kueri yang membutuhkan waktu tujuh menit dan biaya $7. Gambar berikut menunjukkan runtime kueri dan biaya tanpa penskalaan.
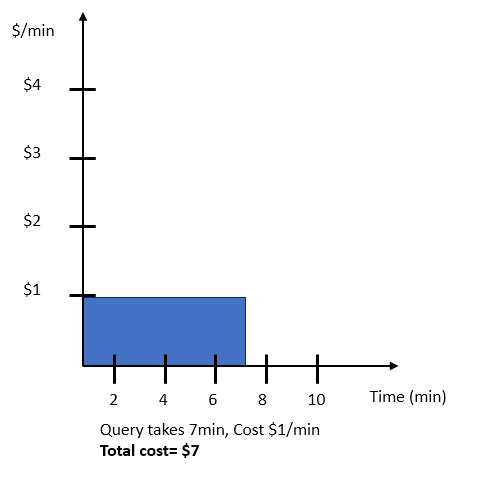
Kueri yang diberikan mungkin diskalakan dalam beberapa cara berbeda, seperti yang ditunjukkan di bawah ini. Berdasarkan target harga-kinerja yang Anda pilih, AI-driven penskalaan memprediksi bagaimana kueri memperdagangkan kinerja dan biaya, dan menskalakannya sesuai dengan itu. Memilih opsi slider yang berbeda menghasilkan hasil sebagai berikut:
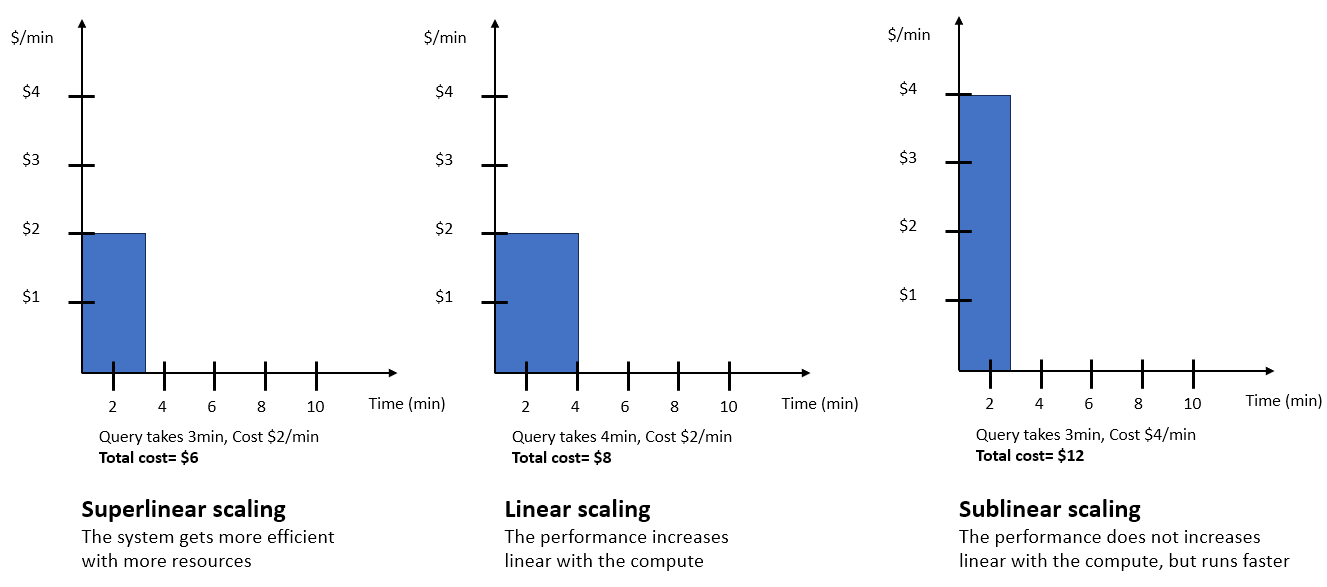
Mengoptimalkan Biaya — Dengan opsi Optimize for Cost, gudang data Anda menskalakan pilihan yang menurunkan biaya Anda. Dalam contoh sebelumnya, pendekatan penskalaan super linier menunjukkan perilaku ini. Penskalaan hanya akan terjadi jika dapat dilakukan dengan cara yang hemat biaya sesuai dengan prediksi model penskalaan. Jika model penskalaan memprediksi bahwa penskalaan yang dioptimalkan biaya tidak dimungkinkan untuk beban kerja yang diberikan, maka gudang data tidak akan diskalakan.
Seimbang — Dengan opsi Balanced, sistem menskalakan sambil menyeimbangkan pertimbangan biaya dan kinerja, dengan potensi peningkatan biaya yang terbatas. Opsi Balanced melakukan penskalaan beban kerja superlinear, linier, dan mungkin sublinear.
Optimize for Performance — Dengan opsi Optimizes for Performance, selain metode sebelumnya untuk meningkatkan kinerja, sistem juga menskalakan meskipun biayanya lebih tinggi, dan mungkin tidak sebanding dengan peningkatan runtime. Dengan Optimizes for Performance, sistem melakukan penskalaan superlinear, penskalaan linier, dan penskalaan sublinear jika memungkinkan. Semakin dekat posisi slider ke posisi Optimizes for Performance, semakin Amazon Redshift Serverless mengizinkan penskalaan sublinear.
Perhatikan hal berikut saat mengatur Price-Performanceslider:
Anda dapat mengubah pengaturan harga-kinerja kapan saja, tetapi penskalaan beban kerja tidak akan segera berubah. Penskalaan berubah seiring waktu saat sistem belajar tentang beban kerja saat ini. Kami menyarankan untuk memantau Grup Kerja Tanpa Server selama 1-3 hari untuk memverifikasi dampak pengaturan baru.
Opsi slider harga-kinerja Kapasitas Max dan Max RPU-hours bekerja sama. Kapasitas maksimum dan Max RPU-hours adalah kontrol untuk membatasi RPU maksimum yang Amazon Redshift Serverless memungkinkan gudang data untuk diskalakan, dan jam RPU maksimum yang Amazon Redshift Serverless memungkinkan gudang data untuk dikonsumsi. Amazon Redshift Serverless selalu menghormati dan menerapkan pengaturan ini, terlepas dari pengaturan target harga-kinerja.
Memantau penskalaan otomatis sumber daya
Anda dapat memantau penskalaan AI-driven RPU dengan cara berikut:
Tinjau grafik kapasitas RPU yang digunakan di konsol Amazon Redshift.
Pantau
ComputeCapacitymetrik di bawahAWS/Redshift-ServerlessdanWorkgroupdi dalam CloudWatch.Kueri tampilan SYS_QUERY_HISTORY. Berikan ID kueri atau teks kueri tertentu untuk mengidentifikasi periode waktu. Gunakan periode waktu ini untuk menanyakan tampilan sistem SYS_SERVERLESS_USAGE untuk menemukan nilainya.
compute_capacitycompute_capacityBidang menunjukkan RPU yang diskalakan selama runtime kueri.
Gunakan contoh berikut untuk menanyakan SYS_QUERY_HISTORY tampilan. Ganti nilai sampel dengan teks kueri Anda.
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds from sys_query_history where query_text like '<query_text>' and query_text not like '%sys_query_history%' order by start_time desc
Jalankan kueri berikut untuk melihat bagaimana compute_capacity diskalakan selama periode dari start_time keend_time. Ganti start_time dan end_time dalam query berikut dengan output dari query sebelumnya:
select * from sys_serverless_usage where end_time >= 'start_time' and end_time <= DATEADD(minute,1,'end_time') order by end_time asc
Untuk petunjuk langkah demi langkah untuk menggunakan fitur ini, lihat Mengonfigurasi pemantauan, batasan, dan alarm di Amazon Redshift Tanpa Server
Pertimbangan saat menggunakan AI-driven penskalaan dan optimasi
Pertimbangkan hal berikut saat menggunakan AI-driven penskalaan dan pengoptimalan:
Untuk beban kerja yang ada di Amazon Redshift Serverless yang membutuhkan 8 hingga 512 Base RPU, sebaiknya gunakan penskalaan dan pengoptimalan Amazon Redshift Serverless untuk hasil yang optimal. AI-driven Kami tidak menyarankan menggunakan fitur ini untuk 4 Base RPU atau lebih dari 512 Base RPU beban kerja.
Price-performance target secara otomatis mengoptimalkan beban kerja, meskipun hasilnya dapat bervariasi. Sebaiknya gunakan fitur ini dari waktu ke waktu sehingga sistem dapat mempelajari pola spesifik Anda dengan menjalankan beban kerja yang representatif.
AI-driven penskalaan dan pengoptimalan menggunakan waktu optimal untuk menerapkan pengoptimalan ke grup kerja Tanpa Server, bergantung pada beban kerja yang berjalan di instans Amazon Redshift Tanpa Server.
Untuk mempelajari lebih lanjut tentang AI-driven pengoptimalan dan penskalaan sumber daya, tonton video berikut.
