Amazon Redshift tidak akan lagi mendukung pembuatan UDF Python baru mulai Patch 198. UDF Python yang ada akan terus berfungsi hingga 30 Juni 2026. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan tampilan SVL_QUERY_SUMMARY
Untuk menganalisis informasi ringkasan kueri dengan streaming menggunakanSVL_QUERY_SUMMARY, lakukan hal berikut:
-
Jalankan kueri berikut untuk menentukan ID kueri Anda:
select query, elapsed, substring from svl_qlog order by query desc limit 5;Periksa teks kueri terpotong di
substringbidang untuk menentukanquerynilai mana yang mewakili kueri Anda. Jika Anda telah menjalankan kueri lebih dari sekali, gunakanquerynilai dari baris denganelapsednilai yang lebih rendah. Itu adalah baris untuk versi yang dikompilasi. Jika Anda telah menjalankan banyak kueri, Anda dapat meningkatkan nilai yang digunakan oleh klausa LIMIT yang digunakan untuk memastikan bahwa kueri Anda disertakan. -
Pilih baris dari SVL_QUERY_SUMMARY untuk kueri Anda. Urutkan hasil berdasarkan aliran, segmen, dan langkah:
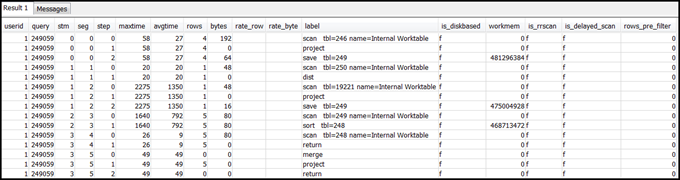
select * from svl_query_summary where query = MyQueryID order by stm, seg, step;Berikut ini adalah contoh hasil.
-
Petakan langkah-langkah untuk operasi dalam rencana kueri menggunakan informasi diMemetakan rencana kueri ke ringkasan kueri. Mereka harus memiliki nilai yang kira-kira sama untuk baris dan byte (baris * lebar dari rencana kueri). Jika tidak, lihat solusi Statistik tabel hilang atau kedaluwarsa yang direkomendasikan.
-
Lihat apakah
is_diskbasedbidang memiliki nilait(true) untuk setiap langkah. Hash, agregat, dan sortir adalah operator yang cenderung menulis data ke disk jika sistem tidak memiliki cukup memori yang dialokasikan untuk pemrosesan kueri.Jika
is_diskbasedbenar, lihat Memori tidak cukup dialokasikan untuk query solusi yang direkomendasikan. -
Tinjau nilai
labelbidang dan lihat apakah ada AGG-DIST-AGG urutan di mana saja dalam langkah-langkahnya. Kehadirannya menunjukkan agregasi dua langkah, yang mahal. Untuk memperbaikinya, ubah klausa GROUP BY untuk menggunakan kunci distribusi (kunci pertama, jika ada beberapa kunci). -
Tinjau
maxtimenilai untuk setiap segmen (sama di semua langkah di segmen). Identifikasi segmen denganmaxtimenilai tertinggi dan tinjau langkah-langkah di segmen ini untuk operator berikut.catatan
maxtimeNilai tinggi tidak selalu menunjukkan masalah dengan segmen. Meskipun nilainya tinggi, segmen ini mungkin tidak membutuhkan waktu lama untuk diproses. Semua segmen dalam aliran mulai diatur waktunya secara serempak. Namun, beberapa segmen hilir mungkin tidak dapat berjalan sampai mereka mendapatkan data dari segmen hulu. Efek ini mungkin membuat mereka tampak memakan waktu lama karenamaxtimenilainya mencakup waktu tunggu dan waktu pemrosesan mereka.-
BCAST atau DIST: Dalam kasus ini,
maxtimenilai tinggi mungkin merupakan hasil dari mendistribusikan kembali sejumlah besar baris. Untuk solusi yang direkomendasikan, lihatDistribusi data suboptimal. -
HJOIN (hash join): Jika langkah yang dimaksud memiliki nilai yang sangat tinggi di
rowsbidang dibandingkan denganrowsnilai pada langkah RETURN terakhir dalam kueri, lihat solusi yang Hash bergabung direkomendasikan. -
SCAN/SORT: Cari urutan langkah SCAN, SORT, SCAN, MERGE tepat sebelum langkah bergabung. Pola ini menunjukkan bahwa data yang tidak disortir sedang dipindai, diurutkan, dan kemudian digabungkan dengan area tabel yang diurutkan.
Lihat apakah nilai baris untuk langkah SCAN memiliki nilai yang sangat tinggi dibandingkan dengan nilai baris pada langkah RETURN terakhir dalam kueri. Pola ini menunjukkan bahwa mesin eksekusi memindai baris yang kemudian dibuang, yang tidak efisien. Untuk solusi yang direkomendasikan, lihatPredikat yang tidak cukup membatasi.
Jika
maxtimenilai untuk langkah SCAN tinggi, lihat solusi yang Klausa WHERE suboptimal direkomendasikan.Jika
rowsnilai untuk langkah SORT bukan nol, lihat solusi yang Baris yang tidak disortir atau disortir direkomendasikan.
-
-
Tinjau
rowsdanbytesnilai untuk 5-10 langkah yang mendahului langkah RETURN akhir untuk mendapatkan gambaran tentang jumlah data yang dikembalikan ke klien. Proses ini bisa menjadi sedikit seni.Misalnya, dalam ringkasan kueri contoh berikut, langkah PROJECT ketiga memberikan
rowsnilai, tetapi bukanbytesnilai. Dengan melihat melalui langkah-langkah sebelumnya untuk satu denganrowsnilai yang sama, Anda menemukan langkah SCAN yang menyediakan informasi baris dan byte.Berikut ini adalah hasil sampel.

Jika Anda mengembalikan volume data yang luar biasa besar, lihat solusi yang Set hasil yang sangat besar direkomendasikan.
-
Lihat apakah
bytesnilainya relatif tinggi terhadaprowsnilai untuk langkah apa pun, dibandingkan dengan langkah lain. Pola ini dapat menunjukkan bahwa Anda memilih banyak kolom. Untuk solusi yang direkomendasikan, lihatDaftar SELECT besar.
