Amazon Redshift tidak akan lagi mendukung pembuatan UDF Python baru mulai Patch 198. UDF Python yang ada akan terus berfungsi hingga 30 Juni 2026. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Arsitektur sistem gudang data
Bagian ini menjelaskan komponen yang membentuk arsitektur gudang data Amazon Redshift, seperti yang ditunjukkan pada gambar berikut.
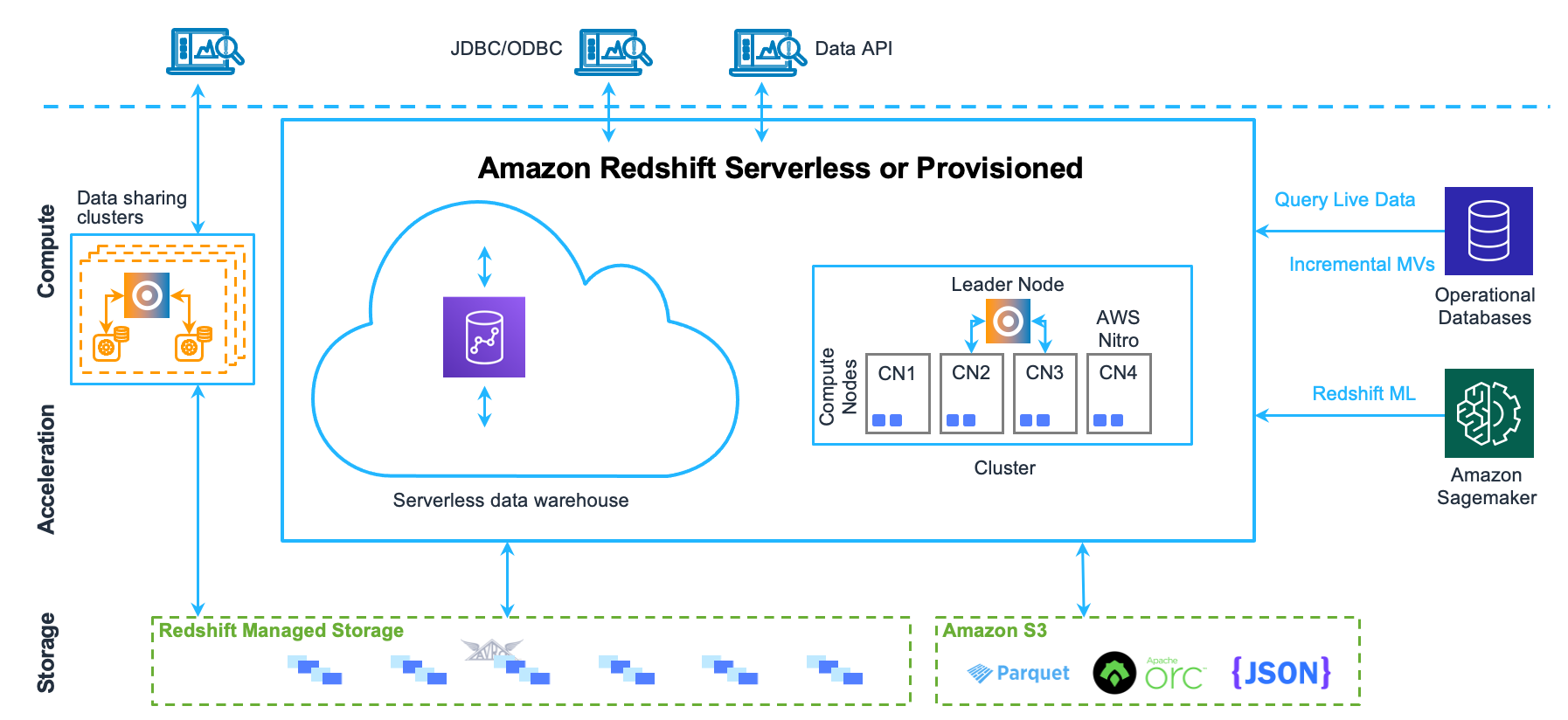
Aplikasi klien
Amazon Redshift terintegrasi dengan berbagai alat pemuatan data dan ETL (ekstrak, transformasi, dan muat) serta alat pelaporan, penambangan data, dan analitik intelijen bisnis (BI). Amazon Redshift didasarkan pada PostgreSQL standar terbuka, sehingga sebagian besar aplikasi klien SQL yang ada akan bekerja dengan hanya sedikit perubahan. Untuk informasi tentang perbedaan penting antara Amazon Redshift SQL dan PostgreSQL, lihat. Amazon Redshift dan PostgreSQL
Cluster
Komponen infrastruktur inti dari gudang data Amazon Redshift adalah cluster.
Sebuah cluster terdiri dari satu atau lebih node komputasi. Jika sebuah cluster disediakan dengan dua atau lebih node komputasi, node pemimpin tambahan mengoordinasikan node komputasi dan menangani komunikasi eksternal. Aplikasi klien Anda berinteraksi langsung hanya dengan node pemimpin. Node komputasi transparan untuk aplikasi eksternal.
Node pemimpin
Node pemimpin mengelola komunikasi dengan program klien dan semua komunikasi dengan node komputasi. Ini mem-parsing dan mengembangkan rencana eksekusi untuk melaksanakan operasi database, khususnya, serangkaian langkah yang diperlukan untuk mendapatkan hasil untuk kueri yang kompleks. Berdasarkan rencana eksekusi, node pemimpin mengkompilasi kode, mendistribusikan kode yang dikompilasi ke node komputasi, dan menetapkan sebagian data ke setiap node komputasi.
Node pemimpin mendistribusikan pernyataan SQL ke node komputasi hanya ketika kueri referensi tabel yang disimpan pada node komputasi. Semua kueri lainnya berjalan secara eksklusif pada node pemimpin. Amazon Redshift dirancang untuk mengimplementasikan fungsi SQL tertentu hanya pada node pemimpin. Kueri yang menggunakan salah satu fungsi ini akan mengembalikan kesalahan jika referensi tabel yang berada di node komputasi. Untuk informasi selengkapnya, lihat Fungsi SQL didukung pada node pemimpin.
Hitung node
Node pemimpin mengkompilasi kode untuk elemen individu dari rencana eksekusi dan menetapkan kode ke node komputasi individu. Node komputasi menjalankan kode yang dikompilasi dan mengirim hasil perantara kembali ke node pemimpin untuk agregasi akhir.
Setiap node komputasi memiliki CPU dan memori khusus sendiri, yang ditentukan oleh jenis node. Seiring bertambahnya beban kerja, Anda dapat meningkatkan kapasitas komputasi klaster dengan meningkatkan jumlah node, memutakhirkan tipe node, atau keduanya.
Amazon Redshift menyediakan beberapa tipe node untuk kebutuhan komputasi Anda. Untuk detail setiap jenis node, lihat klaster Amazon Redshift di Panduan Manajemen Pergeseran Merah Amazon.
Penyimpanan Terkelola Redshift
Data gudang data disimpan dalam tingkat penyimpanan terpisah Redshift Managed Storage (RMS). RMS menyediakan kemampuan untuk menskalakan penyimpanan Anda ke petabyte menggunakan penyimpanan Amazon S3. RMS memungkinkan Anda menskalakan dan membayar komputasi dan penyimpanan secara independen, sehingga Anda dapat mengukur cluster Anda hanya berdasarkan kebutuhan komputasi Anda. Secara otomatis menggunakan penyimpanan SSD-based lokal berkinerja tinggi sebagai cache tier-1. Ini juga memanfaatkan pengoptimalan, seperti suhu blok data, usia blok data, dan pola beban kerja untuk memberikan kinerja tinggi sambil menskalakan penyimpanan secara otomatis ke Amazon S3 bila diperlukan tanpa memerlukan tindakan apa pun.
Irisan simpul
Sebuah node komputasi dipartisi menjadi irisan. Setiap irisan dialokasikan sebagian dari memori node dan ruang disk, di mana ia memproses sebagian dari beban kerja yang ditugaskan ke node. Node pemimpin mengelola distribusi data ke irisan dan membagi beban kerja untuk kueri atau operasi database lainnya ke irisan. Irisan kemudian bekerja secara paralel untuk menyelesaikan operasi.
Jumlah irisan per node ditentukan oleh ukuran node cluster. Untuk informasi selengkapnya tentang jumlah irisan untuk setiap ukuran node, buka Tentang cluster dan node di Amazon Redshift Management Guide.
Saat Anda membuat tabel, Anda dapat secara opsional menentukan satu kolom sebagai kunci distribusi. Ketika tabel dimuat dengan data, baris didistribusikan ke irisan simpul sesuai dengan kunci distribusi yang didefinisikan untuk tabel. Memilih kunci distribusi yang baik memungkinkan Amazon Redshift menggunakan pemrosesan paralel untuk memuat data dan menjalankan kueri secara efisien. Untuk informasi tentang memilih kunci distribusi, lihatPilih gaya distribusi terbaik.
Jaringan internal
Amazon Redshift memanfaatkan koneksi bandwidth tinggi, kedekatan, dan protokol komunikasi khusus untuk menyediakan komunikasi jaringan pribadi berkecepatan sangat tinggi antara node pemimpin dan node komputasi. Node komputasi berjalan pada jaringan terpisah dan terisolasi yang tidak pernah diakses oleh aplikasi klien secara langsung.
Basis Data
Sebuah cluster berisi satu atau lebih database. Data pengguna disimpan pada node komputasi. Klien SQL Anda berkomunikasi dengan node pemimpin, yang pada gilirannya mengkoordinasikan kueri yang dijalankan dengan node komputasi.
Amazon Redshift adalah sistem manajemen basis data relasional (RDBMS), sehingga kompatibel dengan aplikasi RDBMS lainnya. Meskipun menyediakan fungsionalitas yang sama dengan RDBMS biasa, termasuk fungsi pemrosesan transaksi online (OLTP) seperti memasukkan dan menghapus data, Amazon Redshift dioptimalkan untuk analisis kinerja tinggi dan pelaporan kumpulan data yang sangat besar.
Amazon Redshift didasarkan pada PostgreSQL. Amazon Redshift dan PostgreSQL memiliki sejumlah perbedaan yang sangat penting yang perlu Anda perhitungkan saat Anda merancang dan mengembangkan aplikasi gudang data Anda. Untuk informasi tentang bagaimana Amazon Redshift SQL berbeda dari PostgreSQL, lihat. Amazon Redshift dan PostgreSQL
