Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
# Paralelisasi tugas
Untuk mengoptimalkan kinerja, penting untuk memparalelkan tugas untuk pemuatan dan transformasi data. Seperti yang kita bahas di [Topik utama di Apache Spark](key-topics-apache-spark.md), jumlah partisi dataset terdistribusi tangguh (RDD) penting, karena menentukan tingkat paralelisme. Setiap tugas yang dibuat Spark sesuai dengan partisi RDD berdasarkan 1:1. Untuk mencapai kinerja terbaik, Anda perlu memahami bagaimana jumlah partisi RDD ditentukan dan bagaimana angka itu dioptimalkan.
Jika Anda tidak memiliki cukup paralelisme, gejala berikut akan dicatat dalam [CloudWatchmetrik](https://docs.aws.amazon.com/glue/latest/dg/monitoring-awsglue-with-cloudwatch-metrics.html) dan UI Spark.
## CloudWatch metrik
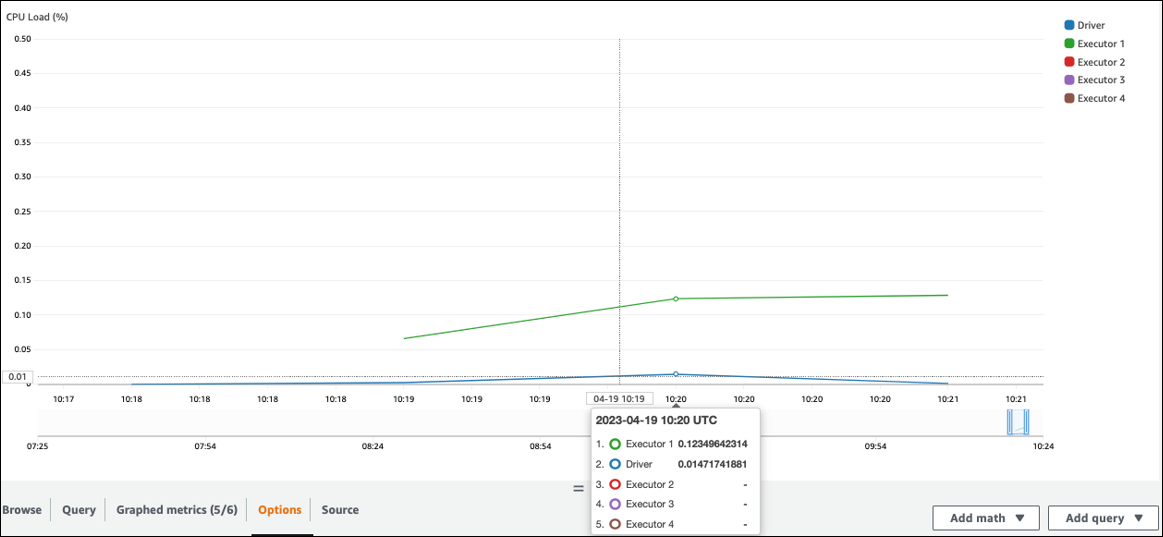
Periksa **Beban CPU** dan **Pemanfaatan Memori**. Jika beberapa pelaksana tidak memproses selama fase pekerjaan Anda, itu tepat untuk meningkatkan paralelisme. Dalam hal ini, selama jangka waktu yang divisualisasikan, **Pelaksana 1** melakukan tugas, tetapi pelaksana yang tersisa (2, 3, dan 4) tidak. Anda dapat menyimpulkan bahwa pelaksana tersebut tidak diberi tugas oleh driver Spark.
## Spark UI
Pada tab **Stage** di UI Spark, Anda dapat melihat**** *jumlah tugas* dalam satu tahap. Dalam hal ini, Spark hanya melakukan satu tugas.

Selain itu, timeline acara menunjukkan **Executor 1** memproses satu tugas. Ini berarti bahwa pekerjaan pada tahap ini dilakukan sepenuhnya pada satu eksekutor, sementara yang lain menganggur.

Jika Anda mengamati gejala-gejala ini, cobalah solusi berikut untuk setiap sumber data.
### Paralelisasi beban data dari Amazon S3
Untuk memparalelkan beban data dari Amazon S3, periksa dulu jumlah partisi default. Anda kemudian dapat secara manual menentukan jumlah target partisi, tetapi pastikan untuk menghindari terlalu banyak partisi.
*Tentukan jumlah partisi default*
Untuk Amazon S3, jumlah awal partisi Spark RDD (masing-masing sesuai dengan tugas Spark) ditentukan oleh fitur kumpulan data Amazon S3 Anda (misalnya, format, kompresi, dan ukuran). Saat Anda membuat AWS Glue DynamicFrame atau Spark DataFrame dari objek CSV yang disimpan di Amazon S3, jumlah awal partisi RDD `NumPartitions` () dapat dihitung kira-kira sebagai berikut:
+ Ukuran objek <= 64 MB: `NumPartitions = Number of Objects`
+ Ukuran objek > 64 MB: `NumPartitions = Total Object Size / 64 MB`
+ Tidak dapat dipisahkan (gzip): `NumPartitions = Number of Objects`
Seperti yang dibahas di bagian [Kurangi jumlah pemindaian data](reduce-data-scan.md), Spark membagi objek S3 besar menjadi split yang dapat diproses secara paralel. Ketika objek lebih besar dari ukuran split, Spark membagi objek dan membuat partisi RDD (dan tugas) untuk setiap split. Ukuran split Spark didasarkan pada format data dan lingkungan runtime Anda, tetapi ini adalah perkiraan awal yang masuk akal. Beberapa objek dikompresi menggunakan format kompresi yang tidak dapat dipisahkan seperti gzip, sehingga Spark tidak dapat membaginya.
`NumPartitions`Nilai dapat bervariasi tergantung pada format data Anda, kompresi, AWS Glue versi, jumlah AWS Glue pekerja, dan konfigurasi Spark.
Misalnya, ketika Anda memuat satu `csv.gz` objek 10 GB menggunakan Spark DataFrame, driver Spark hanya akan membuat satu RDD Partition (`NumPartitions=1`) karena gzip tidak dapat dipisahkan. Ini menghasilkan beban berat pada satu pelaksana Spark tertentu dan tidak ada tugas yang ditugaskan ke pelaksana yang tersisa, seperti yang dijelaskan pada gambar berikut.
Periksa jumlah tugas (`NumPartitions`) aktual untuk tahap pada tab [Spark Web UI](https://docs.aws.amazon.com/glue/latest/dg/monitor-spark-ui.html) **Stage**, atau jalankan `df.rdd.getNumPartitions()` kode Anda untuk memeriksa paralelisme.
Saat menemukan file gzip 10 GB, periksa apakah sistem yang menghasilkan file itu dapat menghasilkannya dalam format yang dapat dibagi. Jika ini bukan pilihan, Anda mungkin perlu [menskalakan kapasitas cluster](scale-cluster-capacity.md) untuk memproses file. Untuk menjalankan transformasi secara efisien pada data yang Anda muat, Anda perlu menyeimbangkan kembali RDD Anda di seluruh pekerja di cluster Anda dengan menggunakan partisi ulang.
*Secara manual menentukan jumlah target partisi*
Bergantung pada properti data Anda dan implementasi Spark dari fungsionalitas tertentu, Anda mungkin berakhir dengan `NumPartitions` nilai rendah meskipun pekerjaan yang mendasarinya masih dapat diparalelkan. Jika `NumPartitions` terlalu kecil, jalankan `df.repartition(N)` untuk menambah jumlah partisi sehingga pemrosesan dapat didistribusikan di beberapa pelaksana Spark.
Dalam hal ini, berjalan `df.repartition(100)` akan meningkat `NumPartitions` dari 1 menjadi 100, membuat 100 partisi data Anda, masing-masing dengan tugas yang dapat ditugaskan ke pelaksana lainnya.
Operasi `repartition(N)` membagi seluruh data secara merata (10 GB/100 partisi = 100 MB/partisi), menghindari kemiringan data ke partisi tertentu.
**catatan**
Ketika operasi shuffle seperti `join` dijalankan, jumlah partisi secara dinamis meningkat atau menurun tergantung pada nilai atau. `spark.sql.shuffle.partitions` `spark.default.parallelism` Ini memfasilitasi pertukaran data yang lebih efisien antara pelaksana Spark. Untuk informasi selengkapnya, lihat [dokumentasi Spark](https://spark.apache.org/docs/latest/configuration.html#runtime-sql-configuration).
Tujuan Anda saat menentukan jumlah target partisi adalah memaksimalkan penggunaan pekerja yang disediakan AWS Glue . Jumlah AWS Glue pekerja dan jumlah tugas Spark terkait melalui jumlah vCPUs. Spark mendukung satu tugas untuk setiap inti vCPU. Dalam AWS Glue versi 3.0 atau yang lebih baru, Anda dapat menghitung jumlah target partisi dengan menggunakan rumus berikut.
```
# Calculate NumPartitions by WorkerType
numExecutors = (NumberOfWorkers - 1)
numSlotsPerExecutor =
4 if WorkerType is G.1X
8 if WorkerType is G.2X
16 if WorkerType is G.4X
32 if WorkerType is G.8X
NumPartitions = numSlotsPerExecutor * numExecutors
# Example: Glue 4.0 / G.1X / 10 Workers
numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver
numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later )
NumPartitions = 9 * 4 = 36
```
Dalam contoh ini, setiap pekerja G.1X menyediakan empat inti vCPU ke eksekutor Spark (). `spark.executor.cores = 4` Spark mendukung satu tugas untuk setiap inti vCPU, sehingga pelaksana G.1X Spark dapat menjalankan empat tugas secara bersamaan (). `numSlotPerExecutor` Jumlah partisi ini memanfaatkan sepenuhnya cluster jika tugas membutuhkan waktu yang sama. Namun, beberapa tugas akan memakan waktu lebih lama dari yang lain, membuat inti idle. Jika ini terjadi, pertimbangkan untuk mengalikan `numPartitions` dengan 2 atau 3 untuk memecah dan menjadwalkan tugas bottleneck secara efisien.
*Terlalu banyak partisi*
Jumlah partisi yang berlebihan menciptakan jumlah tugas yang berlebihan. Hal ini menyebabkan beban berat pada driver Spark karena overhead yang terkait dengan pemrosesan terdistribusi, seperti tugas manajemen dan pertukaran data antara pelaksana Spark.
Jika jumlah partisi dalam pekerjaan Anda jauh lebih besar dari jumlah partisi target Anda, pertimbangkan untuk mengurangi jumlah partisi. Anda dapat mengurangi partisi dengan menggunakan opsi berikut:
+ Jika ukuran file Anda sangat kecil, gunakan AWS Glue [GroupFiles](https://docs.aws.amazon.com/glue/latest/dg/grouping-input-files.html). Anda dapat mengurangi paralelisme berlebihan yang dihasilkan dari peluncuran tugas Apache Spark untuk memproses setiap file.
+ Gunakan `coalesce(N)` untuk menggabungkan partisi bersama-sama. Ini adalah proses berbiaya rendah. Ketika mengurangi jumlah partisi, lebih disukai daripada`repartition(N)`, `coalesce(N)` karena `repartition(N)` melakukan shuffle untuk mendistribusikan jumlah catatan di setiap partisi secara merata. Itu meningkatkan biaya dan overhead manajemen.
+ Gunakan Eksekusi Kueri Adaptif Spark 3.x. Seperti yang dibahas dalam [Topik utama di bagian Apache Spark](key-topics-apache-spark.md), Adaptive Query Execution menyediakan fungsi untuk secara otomatis menggabungkan jumlah partisi. Anda dapat menggunakan pendekatan ini ketika Anda tidak dapat mengetahui jumlah partisi sampai Anda melakukan eksekusi.
### Paralelisasi beban data dari JDBC
Jumlah partisi Spark RDD ditentukan oleh konfigurasi. Perhatikan bahwa secara default hanya satu tugas yang dijalankan untuk memindai seluruh kumpulan data sumber melalui `SELECT` kueri.
Keduanya AWS Glue DynamicFrames dan Spark DataFrames mendukung pemuatan data JDBC paralel di beberapa tugas. Hal ini dilakukan dengan menggunakan `where` predikat untuk membagi satu `SELECT` query menjadi beberapa query. Untuk memparalelkan pembacaan dari JDBC, konfigurasikan opsi berikut:
+ Untuk AWS Glue DynamicFrame, atur `hashfield` (atau `hashexpression)` dan`hashpartition`. Untuk mempelajari lebih lanjut, lihat [Membaca dari tabel JDBC secara paralel](https://docs.aws.amazon.com/glue/latest/dg/run-jdbc-parallel-read-job.html).
```
connection_mysql8_options = {
"url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test",
"dbtable": "medicare_tb",
"user": "test",
"password": "XXXXXXXXX",
"hashexpression":"id",
"hashpartitions":"10"
}
datasource0 = glueContext.create_dynamic_frame.from_options(
'mysql',
connection_options=connection_mysql8_options,
transformation_ctx= "datasource0"
)
```
+ Untuk Spark DataFrame, set`numPartitions`,, `partitionColumn``lowerBound`, dan`upperBound`. Untuk mempelajari lebih lanjut, lihat [JDBC Ke Database Lain](https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html).
```
df = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \
.option("dbtable", "medicare_tb") \
.option("user", "test") \
.option("password", "XXXXXXXXXX") \
.option("partitionColumn", "id") \
.option("numPartitions", "10") \
.option("lowerBound", "0") \
.option("upperBound", "1141455") \
.load()
df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
```
### Paralelisasi beban data dari DynamoDB saat menggunakan konektor ETL
Jumlah partisi Spark RDD ditentukan oleh parameter. `dynamodb.splits` Untuk memparalelkan pembacaan dari Amazon DynamoDB, konfigurasikan opsi berikut:
+ Meningkatkan nilai`dynamodb.splits`.
+ Optimalkan parameter dengan mengikuti rumus yang dijelaskan dalam [Jenis koneksi dan opsi untuk ETL AWS Glue untuk Spark](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-connect.html#aws-glue-programming-etl-connect-dynamodb).
### Paralelisasi beban data dari Kinesis Data Streams
Jumlah partisi Spark RDD ditentukan oleh jumlah pecahan di sumber aliran data Amazon Kinesis Data Streams. Jika Anda hanya memiliki beberapa pecahan dalam aliran data Anda, hanya akan ada beberapa tugas Spark. Hal ini dapat mengakibatkan paralelisme rendah dalam proses hilir. Untuk memparalelkan pembacaan dari Kinesis Data Streams, konfigurasikan opsi berikut:
+ Tingkatkan jumlah pecahan untuk mendapatkan lebih banyak paralelisme saat memuat data dari Kinesis Data Streams.
+ Jika logika Anda dalam batch mikro cukup kompleks, pertimbangkan untuk mempartisi ulang data di awal batch, setelah menjatuhkan kolom yang tidak dibutuhkan.
Untuk informasi selengkapnya, lihat [Praktik terbaik untuk mengoptimalkan biaya dan kinerja untuk AWS Glue streaming pekerjaan ETL](https://aws.amazon.com/blogs/big-data/best-practices-to-optimize-cost-and-performance-for-aws-glue-streaming-etl-jobs/).
### Paralelisasi tugas setelah pemuatan data
Untuk memparalelkan tugas setelah pemuatan data, tingkatkan jumlah partisi RDD dengan menggunakan opsi berikut:
+ Partisi ulang data untuk menghasilkan jumlah partisi yang lebih besar, terutama tepat setelah pemuatan awal jika beban itu sendiri tidak dapat diparalelkan.
Panggil aktif `repartition()` DynamicFrame atau DataFrame, tentukan jumlah partisi. Aturan praktis yang baik adalah dua atau tiga kali jumlah core yang tersedia.
Namun, saat menulis tabel yang dipartisi, ini dapat menyebabkan ledakan file (setiap partisi berpotensi menghasilkan file ke setiap partisi tabel). Untuk menghindari hal ini, Anda dapat mempartisi ulang DataFrame dengan kolom Anda. Ini menggunakan kolom partisi tabel sehingga data diatur sebelum menulis. Anda dapat menentukan jumlah partisi yang lebih tinggi tanpa mendapatkan file kecil di partisi tabel. Namun, berhati-hatilah untuk menghindari kemiringan data, di mana beberapa nilai partisi berakhir dengan sebagian besar data dan menunda penyelesaian tugas.
+ Ketika ada shuffle, tingkatkan nilainya. `spark.sql.shuffle.partitions` Ini juga dapat membantu mengatasi masalah memori apa pun saat mengocoknya.
Bila Anda memiliki lebih dari 2.001 partisi shuffle, Spark menggunakan format memori terkompresi. Jika Anda memiliki nomor yang mendekati itu, Anda mungkin ingin menetapkan `spark.sql.shuffle.partitions` nilai di atas batas itu untuk mendapatkan representasi yang lebih efisien.