Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Basis pengetahuan untuk Amazon Bedrock
Amazon Bedrock adalah layanan yang dikelola sepenuhnya yang membuat model foundation berkinerja tinggi (FMs) dari startup AI terkemuka dan Amazon tersedia untuk Anda gunakan melalui API terpadu. Basis pengetahuan adalah kemampuan Amazon Bedrock yang membantu Anda menerapkan seluruh alur kerja RAG, mulai dari konsumsi hingga pengambilan dan augmentasi yang cepat. Tidak perlu membangun integrasi kustom ke sumber data atau untuk mengelola aliran data. Manajemen konteks sesi dibangun sehingga aplikasi AI generatif Anda dapat dengan mudah mendukung percakapan multi-putaran.
Setelah Anda menentukan lokasi data Anda, basis pengetahuan untuk Amazon Bedrock secara internal mengambil dokumen, memotongnya menjadi blok teks, mengubah teks menjadi embeddings, dan kemudian menyimpan embeddings dalam database vektor pilihan Anda. Amazon Bedrock mengelola dan memperbarui embeddings, menjaga database vektor tetap sinkron dengan data. Untuk informasi selengkapnya tentang cara kerja basis pengetahuan, lihat Cara kerja basis pengetahuan Amazon Bedrock.
Jika Anda menambahkan basis pengetahuan ke agen Amazon Bedrock, agen mengidentifikasi basis pengetahuan yang sesuai berdasarkan masukan pengguna. Agen mengambil informasi yang relevan dan menambahkan informasi ke prompt input. Prompt yang diperbarui menyediakan model dengan lebih banyak informasi konteks untuk menghasilkan respons. Untuk meningkatkan transparansi dan meminimalkan halusinasi, informasi yang diambil dari basis pengetahuan dapat dilacak ke sumbernya.
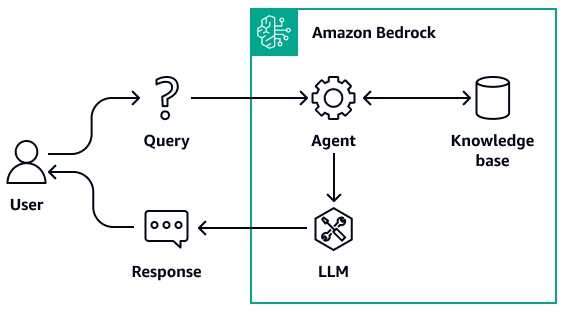
Amazon Bedrock mendukung dua berikut APIs untuk RAG:
-
RetrieveAndGenerate— Anda dapat menggunakan API ini untuk menanyakan basis pengetahuan Anda dan menghasilkan tanggapan dari informasi yang diambilnya. Secara internal, Amazon Bedrock mengubah kueri menjadi embeddings, menanyakan basis pengetahuan, menambah prompt dengan hasil pencarian sebagai informasi konteks, dan mengembalikan respons yang dihasilkan LLM. Amazon Bedrock juga mengelola memori jangka pendek percakapan untuk memberikan hasil yang lebih kontekstual.
-
Ambil - Anda dapat menggunakan API ini untuk menanyakan basis pengetahuan Anda dengan informasi yang diambil langsung dari basis pengetahuan. Anda dapat menggunakan informasi yang dikembalikan dari API ini untuk memproses teks yang diambil, mengevaluasi relevansinya, atau mengembangkan alur kerja terpisah untuk pembuatan respons. Secara internal, Amazon Bedrock mengubah kueri menjadi embeddings, mencari basis pengetahuan, dan mengembalikan hasil yang relevan. Anda dapat membuat alur kerja tambahan di atas hasil penelusuran. Misalnya, Anda dapat menggunakan LangChain
AmazonKnowledgeBasesRetrieverplugin untuk mengintegrasikan alur kerja RAG ke dalam aplikasi AI generatif.
Untuk contoh pola arsitektur dan step-by-step instruksi untuk menggunakan APIs, lihat Pangkalan Pengetahuan sekarang memberikan pengalaman RAG yang dikelola sepenuhnya di Amazon BedrockRetrieveAndGenerate API untuk membangun alur kerja RAG untuk aplikasi berbasis obrolan cerdas, lihat Membangun aplikasi chatbot kontekstual menggunakan Pangkalan Pengetahuan Amazon Bedrock
Sumber data untuk basis pengetahuan
Anda dapat menghubungkan data kepemilikan Anda ke basis pengetahuan. Setelah mengonfigurasi konektor sumber data, Anda dapat menyinkronkan atau memperbarui data dengan basis pengetahuan Anda dan membuat data Anda tersedia untuk kueri. Basis pengetahuan Amazon Bedrock mendukung koneksi ke sumber data berikut:
-
Amazon Simple Storage Service (Amazon S3) - Anda dapat menghubungkan bucket Amazon S3 ke basis pengetahuan Amazon Bedrock dengan menggunakan konsol atau API. Basis pengetahuan mencerna dan mengindeks file dalam ember. Jenis sumber data ini mendukung fitur-fitur berikut:
-
Bidang metadata dokumen — Anda dapat menyertakan file terpisah untuk menentukan metadata file di bucket Amazon S3. Anda kemudian dapat menggunakan bidang metadata ini untuk memfilter dan meningkatkan relevansi tanggapan.
-
Filter penyertaan atau pengecualian — Anda dapat menyertakan atau mengecualikan konten tertentu saat merayapi.
-
Sinkronisasi tambahan — Perubahan konten dilacak, dan hanya konten yang telah berubah sejak sinkronisasi terakhir dirayapi.
-
-
Confluence— Anda dapat menghubungkan Atlassian Confluence instance ke basis pengetahuan Amazon Bedrock dengan menggunakan konsol atau API. Jenis sumber data ini mendukung fitur-fitur berikut:
-
Deteksi otomatis bidang dokumen utama - Bidang metadata secara otomatis terdeteksi dan dirayapi. Anda dapat menggunakan bidang ini untuk pemfilteran.
-
Filter konten penyertaan atau pengecualian — Anda dapat menyertakan atau mengecualikan konten tertentu dengan menggunakan awalan atau pola ekspresi reguler pada spasi, judul halaman, judul blog, komentar, nama lampiran, atau ekstensi.
-
Sinkronisasi tambahan - Perubahan konten dilacak, dan hanya konten yang telah berubah sejak sinkronisasi terakhir dirayapi.
-
OAuth Otentikasi 2.0, otentikasi dengan token Confluence API — Kredensyal otentikasi disimpan di. AWS Secrets Manager
-
-
Microsoft SharePoint— Anda dapat menghubungkan SharePoint instance ke basis pengetahuan dengan menggunakan konsol atau API. Jenis sumber data ini mendukung fitur-fitur berikut:
-
Deteksi otomatis bidang dokumen utama - Bidang metadata secara otomatis terdeteksi dan dirayapi. Anda dapat menggunakan bidang ini untuk pemfilteran.
-
Filter konten penyertaan atau pengecualian — Anda dapat menyertakan atau mengecualikan konten tertentu dengan menggunakan awalan atau pola ekspresi reguler pada judul halaman utama, nama acara, dan nama file (termasuk ekstensinya).
-
Sinkronisasi tambahan - Perubahan konten dilacak, dan hanya konten yang telah berubah sejak sinkronisasi terakhir dirayapi.
-
OAuth Otentikasi 2.0 — Kredensyal otentikasi disimpan di. AWS Secrets Manager
-
-
Salesforce— Anda dapat menghubungkan Salesforce instance ke basis pengetahuan dengan menggunakan konsol atau API. Jenis sumber data ini mendukung fitur-fitur berikut:
-
Deteksi otomatis bidang dokumen utama - Bidang metadata secara otomatis terdeteksi dan dirayapi. Anda dapat menggunakan bidang ini untuk pemfilteran.
-
Filter konten penyertaan atau pengecualian — Anda dapat menyertakan atau mengecualikan konten tertentu dengan menggunakan awalan atau pola ekspresi reguler. Untuk daftar jenis konten yang dapat Anda terapkan filter, lihat Filter inklusi/pengecualian di dokumentasi Amazon Bedrock.
-
Sinkronisasi tambahan — Perubahan konten dilacak, dan hanya konten yang telah berubah sejak sinkronisasi terakhir dirayapi.
-
OAuth Otentikasi 2.0 — Kredensyal otentikasi disimpan di. AWS Secrets Manager
-
-
Web Crawler — Perayap Web Amazon Bedrock menghubungkan dan merayapi yang Anda berikan. URLs Fitur-fitur berikut didukung:
-
Pilih beberapa URLs untuk dirayapi
-
Hormati arahan robots.txt standar, seperti dan
AllowDisallow -
Kecualikan URLs yang cocok dengan pola
-
Batasi tingkat perayapan
-
Di Amazon CloudWatch, lihat status setiap URL yang dirayapi
-
Untuk informasi selengkapnya tentang sumber data yang dapat Anda sambungkan ke basis pengetahuan Amazon Bedrock, lihat Membuat konektor sumber data untuk basis pengetahuan Anda.
Database vektor untuk basis pengetahuan
Ketika Anda mengatur koneksi antara basis pengetahuan dan sumber data, Anda harus mengkonfigurasi database vektor, juga dikenal sebagai penyimpanan vektor. Basis data vektor adalah tempat Amazon Bedrock menyimpan, memperbarui, dan mengelola embeddings yang mewakili data Anda. Setiap sumber data mendukung berbagai jenis database vektor. Untuk menentukan database vektor mana yang tersedia untuk sumber data Anda, lihat tipe sumber data.
Jika Anda lebih suka Amazon Bedrock untuk secara otomatis membuat database vektor di Amazon OpenSearch Tanpa Server untuk Anda, Anda dapat memilih opsi ini saat membuat basis pengetahuan. Namun, Anda juga dapat memilih untuk mengatur database vektor Anda sendiri. Jika Anda menyiapkan database vektor Anda sendiri, lihat Prasyarat untuk penyimpanan vektor Anda sendiri untuk basis pengetahuan. Setiap jenis database vektor memiliki prasyaratnya sendiri.
Bergantung pada tipe sumber data Anda, basis pengetahuan Amazon Bedrock mendukung database vektor berikut:
-
Pinecone
(Pineconedokumentasi) -
Redis Enterprise Cloud
(Redisdokumentasi) -
MongoDB Atlas
(MongoDBdokumentasi)
