Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Komponen arsitektur gudang data Amazon Redshift
Kami menyarankan Anda memiliki pemahaman dasar tentang komponen arsitektur inti di gudang data Amazon Redshift. Pengetahuan ini dapat membantu Anda lebih memahami cara mendesain kueri dan tabel Anda untuk kinerja yang optimal.
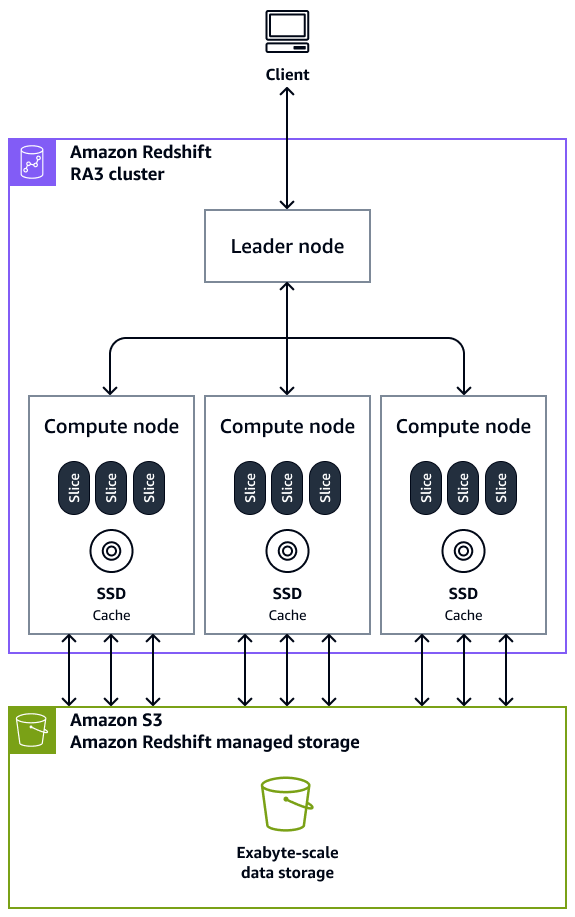
Gudang data di Amazon Redshift terdiri dari komponen arsitektur inti berikut:
-
Cluster — Cluster, yang terdiri dari satu atau lebih node komputasi, adalah komponen infrastruktur inti dari gudang data Amazon Redshift. Node komputasi transparan untuk aplikasi eksternal, tetapi aplikasi klien Anda berinteraksi langsung dengan node pemimpin saja. Sebuah cluster tipikal memiliki dua atau lebih node komputasi. Node komputasi dikoordinasikan melalui node pemimpin.
-
Leader node — Sebuah node pemimpin mengelola komunikasi untuk program klien dan semua node komputasi. Node pemimpin juga menyiapkan rencana untuk menjalankan kueri setiap kali kueri dikirimkan ke cluster. Ketika rencana sudah siap, node pemimpin mengkompilasi kode, mendistribusikan kode yang dikompilasi ke node komputasi, dan kemudian menetapkan irisan data ke setiap node komputasi untuk memproses hasil kueri.
-
Compute node — Sebuah node komputasi menjalankan query. Node pemimpin mengkompilasi kode untuk elemen individual dari rencana untuk menjalankan kueri dan menetapkan kode ke node komputasi individu. Node komputasi menjalankan kode yang dikompilasi dan mengirim hasil perantara kembali ke node pemimpin untuk agregasi akhir. Setiap node komputasi memiliki CPU khusus, memori, dan penyimpanan disk yang terpasang. Seiring bertambahnya beban kerja, Anda dapat meningkatkan kapasitas komputasi dan kapasitas penyimpanan klaster dengan meningkatkan jumlah node, memutakhirkan tipe node, atau keduanya.
-
Node slice — Sebuah node komputasi dipartisi menjadi unit yang disebut irisan. Setiap irisan dalam node komputasi dialokasikan sebagian dari memori node dan ruang disk di mana ia memproses sebagian dari beban kerja yang ditugaskan ke node. Irisan kemudian bekerja secara paralel untuk menyelesaikan operasi. Data didistribusikan di antara irisan berdasarkan gaya distribusi dan kunci distribusi dari tabel tertentu. Distribusi data yang merata memungkinkan Amazon Redshift menetapkan beban kerja secara merata ke irisan dan memaksimalkan manfaat pemrosesan paralel. Jumlah irisan per node komputasi ditentukan berdasarkan jenis node. Untuk informasi selengkapnya, lihat Cluster dan node di Amazon Redshift di dokumentasi Amazon Redshift.
-
Massively parallel processing (MPP) — Amazon Redshift menggunakan arsitektur MPP untuk memproses data dengan cepat, bahkan kueri yang kompleks dan data dalam jumlah besar. Beberapa node komputasi menjalankan kode kueri yang sama pada bagian data untuk memaksimalkan pemrosesan paralel.
-
Aplikasi klien — Amazon Redshift terintegrasi dengan berbagai pemuatan data, ekstrak, transformasi, dan pemuatan (ETL), pelaporan intelijen bisnis (BI), penambangan data, dan alat analitik. Semua aplikasi klien berkomunikasi dengan cluster melalui node pemimpin saja.
Diagram berikut menunjukkan bagaimana komponen arsitektur gudang data Amazon Redshift bekerja sama untuk mempercepat kueri.
Ada tujuh tahap siklus hidup kueri:
-
Penerimaan dan penguraian kueri:
-
Node pemimpin menerima kueri dan mem-parsing SQL.
-
Parser menghasilkan pohon query awal, yang mewakili struktur logis dari query asli.
-
Amazon Redshift memasukkan pohon kueri ini ke pengoptimal kueri.
-
-
Optimasi kueri:
-
Pengoptimal mengevaluasi kueri dan, jika perlu, menulis ulang untuk memaksimalkan efisiensi.
-
Proses optimasi ini mungkin melibatkan pembuatan beberapa kueri terkait untuk menggantikan satu kueri.
-
-
Pembuatan rencana kueri:
-
Pengoptimal menghasilkan rencana kueri (atau beberapa rencana, jika diperlukan) untuk dieksekusi.
-
Rencana kueri menentukan opsi eksekusi, seperti tipe gabungan, urutan gabungan, metode agregasi, dan persyaratan distribusi data.
-
-
Terjemahan mesin eksekusi:
-
Mesin eksekusi menerjemahkan rencana kueri ke dalam langkah, segmen, dan aliran diskrit:
-
Langkah - Merupakan operasi individual yang diperlukan selama eksekusi kueri. Langkah-langkah dapat digabungkan untuk memungkinkan node komputasi untuk melakukan query, bergabung, atau operasi database lainnya.
-
Segmen — Menggabungkan beberapa langkah yang dapat dijalankan oleh satu proses. Ini adalah unit kompilasi terkecil yang dapat dieksekusi oleh irisan node komputasi. (Sepotong adalah unit pemrosesan paralel di Amazon Redshift.)
-
Stream — Kumpulan segmen yang didistribusikan di seluruh irisan node komputasi yang tersedia.
-
-
Mesin eksekusi menghasilkan kode yang dikompilasi berdasarkan langkah, segmen, dan aliran ini. Kode yang dikompilasi berjalan lebih cepat daripada kode yang ditafsirkan dan mengkonsumsi lebih sedikit kapasitas komputasi.
-
Node pemimpin menyiarkan kode yang dikompilasi ke node komputasi.
-
-
Eksekusi paralel:
-
Langkah ini terjadi satu kali untuk setiap aliran.
-
Hitung irisan node menjalankan segmen kueri secara paralel.
-
Selama proses ini, Amazon Redshift mengoptimalkan komunikasi jaringan, penggunaan memori, dan manajemen disk untuk meneruskan hasil perantara dari satu langkah rencana kueri ke langkah berikutnya.
-
Pengoptimalan ini berkontribusi pada eksekusi kueri yang lebih cepat.
-
-
Pemrosesan aliran:
-
Langkah ini terjadi satu kali untuk setiap aliran.
-
Mesin menciptakan segmen yang dapat dieksekusi untuk setiap aliran, untuk pemrosesan paralel yang efisien.
-
-
Penyortiran dan agregasi akhir:
-
Node pemimpin membahas penyortiran atau agregasi akhir apa pun yang dibutuhkan kueri.
-
Setelah selesai, node pemimpin mengembalikan hasilnya ke klien.
-
Untuk informasi tentang komponen arsitektur, lihat Arsitektur sistem gudang data dalam dokumentasi Amazon Redshift.
