Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Migrasi cluster Amazon Redshift ke Wilayah AWS di Tiongkok
Jing Yan, Amazon Web Services
Ringkasan
Pola ini menyediakan step-by-step pendekatan untuk memigrasikan cluster Amazon Redshift ke Wilayah AWS di Tiongkok dari Wilayah AWS lainnya.
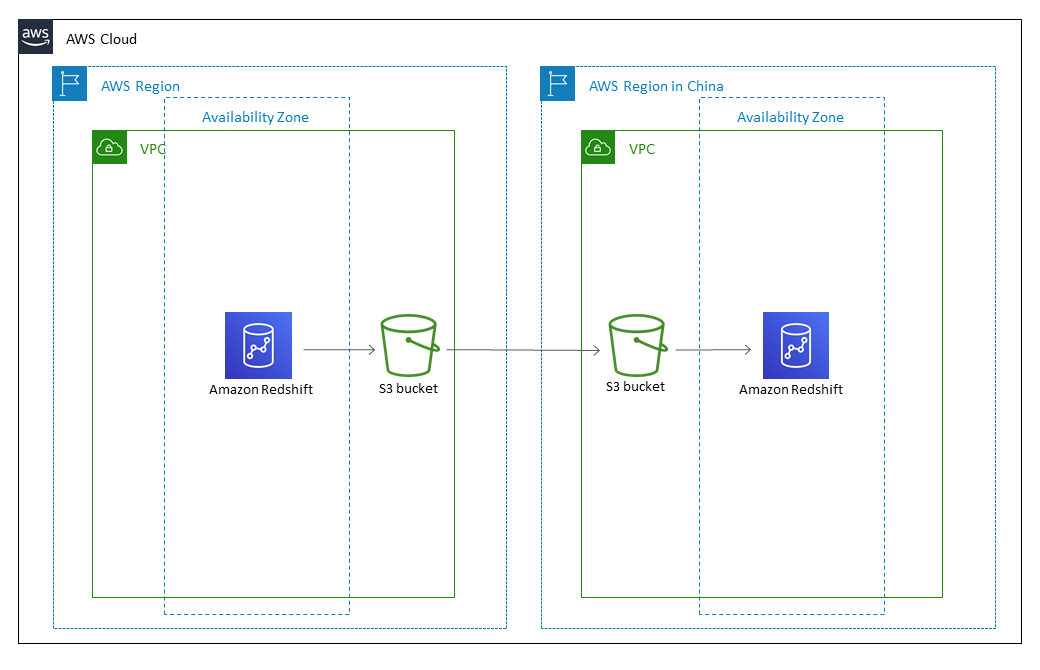
Pola ini menggunakan perintah SQL untuk membuat ulang semua objek database, dan menggunakan perintah UNLOAD untuk memindahkan data ini dari Amazon Redshift ke bucket Amazon Simple Storage Service (Amazon S3) di Wilayah sumber. Data tersebut kemudian dimigrasikan ke bucket S3 di Wilayah AWS di Tiongkok. Perintah COPY digunakan untuk memuat data dari bucket S3 dan mentransfernya ke cluster Amazon Redshift target.
Amazon Redshift saat ini tidak mendukung fitur Lintas wilayah seperti penyalinan snapshot ke Wilayah AWS di Tiongkok. Pola ini menyediakan cara untuk mengatasi batasan itu. Anda juga dapat membalikkan langkah-langkah dalam pola ini untuk memigrasikan data dari Wilayah AWS di Tiongkok ke Wilayah AWS lainnya.
Prasyarat dan batasan
Prasyarat
Akun AWS aktif di Wilayah Tiongkok dan Wilayah AWS di luar Tiongkok
Cluster Amazon Redshift yang ada di Wilayah Tiongkok dan Wilayah AWS di luar Tiongkok
Batasan
Ini adalah migrasi offline, yang berarti cluster Amazon Redshift sumber tidak dapat melakukan operasi tulis selama migrasi.
Arsitektur
Tumpukan teknologi sumber
Cluster Amazon Redshift di Wilayah AWS di luar Tiongkok
Tumpukan teknologi target
Cluster Amazon Redshift di Wilayah AWS di Tiongkok
Arsitektur target
Alat
Alat
Amazon S3 - Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3) adalah layanan penyimpanan objek yang menawarkan skalabilitas, ketersediaan data, keamanan, dan kinerja. Anda dapat menggunakan Amazon S3 untuk menyimpan data dari Amazon Redshift, dan Anda dapat menyalin data dari bucket S3 ke Amazon Redshift.
Amazon Redshift — Amazon Redshift adalah layanan gudang data skala petabyte yang dikelola sepenuhnya di cloud.
psql — psql
adalah front-end berbasis terminal untuk PostgreSQL.
Epik
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Luncurkan dan konfigurasikan EC2 instance di Wilayah sumber. | Masuk ke AWS Management Console dan buka konsol Amazon Elastic Compute Cloud (Amazon EC2). Wilayah Anda saat ini ditampilkan di bilah navigasi di bagian atas layar. Wilayah ini tidak bisa menjadi Wilayah AWS di Tiongkok. Dari dasbor EC2 konsol Amazon, pilih “Luncurkan instance”, lalu buat dan konfigurasikan EC2 instance. Penting: Pastikan grup EC2 keamanan Anda untuk aturan masuk mengizinkan akses tidak terbatas ke port TCP 22 dari mesin sumber Anda. Untuk petunjuk tentang cara meluncurkan dan mengonfigurasi EC2 instance, lihat bagian “Sumber daya terkait”. | DBA, Pengembang |
Instal alat psql. | Unduh dan instal PostgreSQL. Amazon Redshift tidak menyediakan alat psql, itu diinstal dengan PostgreSQL. Untuk informasi selengkapnya tentang menggunakan psql dan menginstal alat PostgreSQL, lihat bagian “Sumber daya terkait”. | DBA |
Rekam detail cluster Amazon Redshift. | Buka konsol Amazon Redshift, dan pilih “Clusters” di panel navigasi. Kemudian pilih nama cluster Amazon Redshift dari daftar. Pada tab “Properti”, di bagian “Konfigurasi basis data”, catat “Nama basis data” dan “Port.” Buka bagian “Detail koneksi” dan rekam “Titik Akhir”, yang ada dalam format “titik akhir:<port>/<databasename>”. Penting: Pastikan grup keamanan Amazon Redshift untuk aturan masuk mengizinkan akses tidak terbatas ke port TCP 5439 dari instans Anda. EC2 | DBA |
Hubungkan psql ke cluster Amazon Redshift. | <userid><databasename><port>Pada prompt perintah, tentukan informasi koneksi dengan menjalankan perintah “psql -h <endpoint>-U -d -p”. Pada prompt kata sandi psql, masukkan kata sandi untuk pengguna <userid>"”. Anda kemudian terhubung ke cluster Amazon Redshift dan dapat memasukkan perintah secara interaktif. | DBA |
Buat ember S3. | Buka konsol Amazon S3, dan buat bucket S3 untuk menyimpan file yang diekspor dari Amazon Redshift. Untuk petunjuk tentang cara membuat bucket S3, lihat bagian “Sumber daya terkait”. | DBA, AWS Umum |
Buat kebijakan IAM yang mendukung pembongkaran data. | Buka konsol AWS Identity and Access Management (IAM) dan pilih “Kebijakan.” Pilih “Buat kebijakan,” dan pilih tab “JSON”. Salin dan tempel kebijakan IAM untuk membongkar data dari bagian “Informasi tambahan”. Penting: Ganti “s3_bucket_name” dengan nama bucket S3 Anda. Pilih “Kebijakan tinjau”, lalu masukkan nama dan deskripsi untuk kebijakan tersebut. Pilih “Buat kebijakan.” | DBA |
Buat peran IAM untuk memungkinkan operasi UNLOAD untuk Amazon Redshift. | Buka konsol IAM dan pilih “Peran.” Pilih “Buat peran,” dan pilih “Layanan AWS” di “Pilih jenis entitas tepercaya.” Pilih “Redshift” untuk layanan, pilih “Redshift - Customizable,” dan kemudian pilih “Next.” Pilih kebijakan “Bongkar” yang Anda buat sebelumnya, dan pilih “Berikutnya.” Masukkan “Nama peran,” dan pilih “Buat peran.” | DBA |
Kaitkan peran IAM dengan cluster Amazon Redshift. | Buka konsol Amazon Redshift, dan pilih “Kelola peran IAM.” Pilih “Peran yang tersedia” dari menu tarik-turun dan pilih peran yang Anda buat sebelumnya. Pilih “Terapkan perubahan.” Ketika “Status” untuk peran IAM pada “Kelola peran IAM” ditampilkan sebagai “In-sync”, Anda dapat menjalankan perintah UNLOAD. | DBA |
Hentikan operasi penulisan ke cluster Amazon Redshift. | Anda harus ingat untuk menghentikan semua operasi penulisan ke cluster Amazon Redshift sumber hingga migrasi selesai. | DBA |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Luncurkan dan konfigurasikan EC2 instance di Wilayah target. | Masuk ke AWS Management Console untuk Wilayah di Tiongkok, baik Beijing maupun Ningxia. Dari EC2 konsol Amazon, pilih “Luncurkan instance,” dan buat serta konfigurasikan EC2 instance. Penting: Pastikan grup EC2 keamanan Amazon Anda untuk aturan masuk mengizinkan akses tidak terbatas ke port TCP 22 dari mesin sumber Anda. Untuk petunjuk lebih lanjut tentang cara meluncurkan dan mengonfigurasi EC2 instance, lihat bagian “Sumber daya terkait”. | DBA |
Rekam detail cluster Amazon Redshift. | Buka konsol Amazon Redshift, dan pilih “Clusters” di panel navigasi. Kemudian pilih nama cluster Amazon Redshift dari daftar. Pada tab “Properti”, di bagian “Konfigurasi basis data”, catat “Nama basis data” dan “Port.” Buka bagian “Detail koneksi” dan rekam “Titik Akhir”, yang ada dalam format “titik akhir:<port>/<databasename>”. Penting: Pastikan grup keamanan Amazon Redshift untuk aturan masuk mengizinkan akses tidak terbatas ke port TCP 5439 dari instans Anda. EC2 | DBA |
Hubungkan psql ke cluster Amazon Redshift. | <userid><databasename><port>Pada prompt perintah, tentukan informasi koneksi dengan menjalankan perintah “psql -h <endpoint>-U -d -p”. Pada prompt kata sandi psql, masukkan kata sandi untuk pengguna <userid>"”. Anda kemudian terhubung ke cluster Amazon Redshift dan dapat memasukkan perintah secara interaktif. | DBA |
Buat ember S3. | Buka konsol Amazon S3, dan buat bucket S3 untuk menyimpan file yang diekspor dari Amazon Redshift. Untuk bantuan dengan ini dan cerita lainnya, lihat bagian “Sumber daya terkait”. | DBA |
Buat kebijakan IAM yang mendukung penyalinan data. | Buka konsol IAM dan pilih “Kebijakan.” Pilih “Buat kebijakan,” dan pilih tab “JSON”. Salin dan tempel kebijakan IAM untuk menyalin data dari bagian “Informasi tambahan”. Penting: Ganti “s3_bucket_name” dengan nama bucket S3 Anda. Pilih “Kebijakan peninjauan”, masukkan nama dan deskripsi untuk kebijakan tersebut. Pilih “Buat kebijakan.” | DBA |
Buat peran IAM untuk memungkinkan operasi COPY untuk Amazon Redshift. | Buka konsol IAM dan pilih “Peran.” Pilih “Buat peran,” dan pilih “Layanan AWS” di “Pilih jenis entitas tepercaya.” Pilih “Redshift” untuk layanan, pilih “Redshift - Customizable,” dan kemudian pilih “Next.” Pilih kebijakan “Salin” yang Anda buat sebelumnya, dan pilih “Berikutnya.” Masukkan “Nama peran,” dan pilih “Buat peran.” | DBA |
Kaitkan peran IAM dengan cluster Amazon Redshift. | Buka konsol Amazon Redshift, dan pilih “Kelola peran IAM.” Pilih “Peran yang tersedia” dari menu tarik-turun dan pilih peran yang Anda buat sebelumnya. Pilih “Terapkan perubahan.” Ketika “Status” untuk peran IAM pada “Kelola peran IAM” ditampilkan sebagai “In-sync”, Anda dapat menjalankan perintah “COPY”. | DBA |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Verifikasi baris di tabel Amazon Redshift sumber. | Gunakan skrip di bagian “Informasi tambahan” untuk memverifikasi dan mencatat jumlah baris di tabel Amazon Redshift sumber. Ingatlah untuk membagi data secara merata untuk skrip UNLOAD dan COPY. Ini akan meningkatkan efisiensi bongkar muat dan pemuatan data, karena kuantitas data yang dicakup oleh setiap skrip akan seimbang. | DBA |
Verifikasi jumlah objek database di cluster Amazon Redshift sumber. | Gunakan skrip di bagian “Informasi tambahan” untuk memverifikasi dan mencatat jumlah database, pengguna, skema, tabel, tampilan, dan fungsi yang ditentukan pengguna (UDFs) di kluster Amazon Redshift sumber Anda. | DBA |
Verifikasi hasil pernyataan SQL sebelum migrasi. | Beberapa pernyataan SQL untuk validasi data harus diurutkan menurut situasi bisnis dan data yang sebenarnya. Ini untuk memverifikasi data yang diimpor untuk memastikannya konsisten dan ditampilkan dengan benar. | DBA |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Hasilkan skrip DDL Amazon Redshift. | Hasilkan skrip Data Definition Language (DDL) dengan menggunakan tautan dari bagian “SQL statement to query Amazon Redshift” di bagian “Informasi tambahan”. Skrip DDL ini harus mencakup “buat pengguna,” “buat skema,” “hak istimewa skema untuk pengguna,” “buat tabel/tampilan,” “hak istimewa pada objek ke pengguna,” dan “buat fungsi” kueri. | DBA |
Buat objek di cluster Amazon Redshift untuk Wilayah target. | Jalankan skrip DDL dengan menggunakan AWS Command Line Interface (AWS CLI) Interface (AWS CLI) di Wilayah AWS di Tiongkok. Skrip ini akan membuat objek di cluster Amazon Redshift untuk Wilayah target. | DBA |
Bongkar sumber data cluster Amazon Redshift ke bucket S3. | Jalankan perintah UNLOAD untuk membongkar data dari cluster Amazon Redshift di Wilayah sumber ke bucket S3. | DBA, Pengembang |
Transfer sumber data bucket Region S3 ke bucket Region S3 target. | Transfer data dari bucket Region S3 sumber Anda ke bucket S3 target. Karena perintah “$ aws s3 sync” tidak dapat digunakan, pastikan Anda menggunakan proses yang diuraikan dalam artikel “Mentransfer data Amazon S3 dari Wilayah AWS ke Wilayah AWS di Tiongkok” di bagian “Sumber daya terkait”. | Developer |
Muat data ke cluster Amazon Redshift target. | Di alat psql untuk Wilayah target Anda, jalankan perintah COPY untuk memuat data dari bucket S3 ke cluster Amazon Redshift target. | DBA |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Verifikasi dan bandingkan jumlah baris dalam tabel sumber dan target. | Verifikasi dan bandingkan jumlah baris tabel di wilayah sumber dan target untuk memastikan semua dimigrasikan. | DBA |
Verifikasi dan bandingkan jumlah objek basis data sumber dan target. | Verifikasi dan bandingkan semua objek database di daerah sumber dan target untuk memastikan semua dimigrasikan. | DBA |
Verifikasi dan bandingkan hasil skrip SQL di daerah sumber dan target. | Jalankan skrip SQL yang disiapkan sebelum migrasi. Verifikasi dan bandingkan data untuk memastikan bahwa hasil SQL benar. | DBA |
Setel ulang kata sandi semua pengguna di cluster Amazon Redshift target. | Setelah migrasi selesai dan semua data diverifikasi, Anda harus mengatur ulang semua kata sandi pengguna untuk klaster Amazon Redshift di Wilayah AWS di Tiongkok. | DBA |
Sumber daya terkait
Informasi tambahan
Kebijakan IAM untuk membongkar data
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::s3_bucket_name"] }, { "Effect": "Allow", "Action": ["s3:GetObject", "s3:DeleteObject"], "Resource": ["arn:aws:s3:::s3_bucket_name/*"] } ] }
Kebijakan IAM untuk menyalin data
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::s3_bucket_name"] }, { "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": ["arn:aws:s3:::s3_bucket_name/*"] } ] }
Pernyataan SQL untuk menanyakan Amazon Redshift
##Database select * from pg_database where datdba>1; ##User select * from pg_user where usesysid>1; ##Schema SELECT n.nspname AS "Name", pg_catalog.pg_get_userbyid(n.nspowner) AS "Owner" FROM pg_catalog.pg_namespace n WHERE n.nspname !~ '^pg_' AND n.nspname <> 'information_schema' ORDER BY 1; ##Table select count(*) from pg_tables where schemaname not in ('pg_catalog','information_schema'); select schemaname,count(*) from pg_tables where schemaname not in ('pg_catalog','information_schema') group by schemaname order by 1; ##View SELECT n.nspname AS schemaname,c.relname AS viewname,pg_catalog.pg_get_userbyid(c.relowner) as "Owner" FROM pg_catalog.pg_class AS c INNER JOIN pg_catalog.pg_namespace AS n ON c.relnamespace = n.oid WHERE relkind = 'v' and n.nspname not in ('information_schema','pg_catalog'); ##UDF SELECT n.nspname AS schemaname, p.proname AS proname, pg_catalog.pg_get_userbyid(p.proowner) as "Owner" FROM pg_proc p LEFT JOIN pg_namespace n on n.oid = p.pronamespace WHERE p.proowner != 1;
Skrip SQL untuk menghasilkan pernyataan DDL
