Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Meniru array PL/SQL asosiatif Oracle di Amazon Aurora PostgreSQL dan Amazon RDS untuk PostgreSQL
Rajkumar Raghuwanshi, Bhanu Ganesh Gudivada, dan Sachin Khanna, Amazon Web Services
Ringkasan
Pola ini menjelaskan cara meniru array PL/SQL asosiatif Oracle dengan posisi indeks kosong di Amazon Aurora PostgreSQL dan Amazon RDS untuk lingkungan PostgreSQL
Kami menyediakan alternatif PostgreSQL untuk aws_oracle_ext menggunakan fungsi untuk menangani posisi indeks kosong saat memigrasi database Oracle. Pola ini menggunakan kolom tambahan untuk menyimpan posisi indeks, dan mempertahankan penanganan Oracle terhadap array jarang sambil menggabungkan kemampuan PostgreSQL asli.
Oracle
Di Oracle, koleksi dapat diinisialisasi sebagai kosong dan diisi menggunakan metode EXTEND pengumpulan, yang menambahkan NULL elemen ke array. Saat bekerja dengan array PL/SQL asosiatif yang diindeks olehPLS_INTEGER, EXTEND metode ini menambahkan NULL elemen secara berurutan, tetapi elemen juga dapat diinisialisasi pada posisi indeks nonsequential. Posisi indeks apa pun yang tidak diinisialisasi secara eksplisit tetap kosong.
Fleksibilitas ini memungkinkan struktur array jarang di mana elemen dapat diisi pada posisi arbitrer. Saat melakukan iterasi melalui koleksi menggunakan FOR LOOP with FIRST dan LAST bounds, hanya elemen yang diinisialisasi (baik NULL atau dengan nilai yang ditentukan) yang diproses, sementara posisi kosong dilewati.
PostgreSQL (Amazon Aurora dan Amazon RDS)
PostgreSQL menangani nilai kosong secara berbeda dari nilai. NULL Ini menyimpan nilai kosong sebagai entitas berbeda yang menggunakan satu byte penyimpanan. Ketika sebuah array memiliki nilai kosong, PostgreSQL menetapkan posisi indeks sekuensial seperti nilai non-kosong. Tetapi pengindeksan sekuensial membutuhkan pemrosesan tambahan karena sistem harus mengulangi semua posisi yang diindeks, termasuk yang kosong. Ini membuat pembuatan array tradisional tidak efisien untuk kumpulan data yang jarang.
AWS Schema Conversion Tool
The AWS Schema Conversion Tool (AWS SCT) biasanya menangani Oracle-to-PostgreSQL migrasi menggunakan aws_oracle_ext fungsi. Dalam pola ini, kami mengusulkan pendekatan alternatif yang menggunakan kemampuan PostgreSQL asli, yang menggabungkan tipe array PostgreSQL dengan kolom tambahan untuk menyimpan posisi indeks. Sistem kemudian dapat mengulangi melalui array hanya menggunakan kolom indeks.
Prasyarat dan batasan
Prasyarat
Aktif Akun AWS.
Pengguna AWS Identity and Access Management (IAM) dengan izin administrator.
Instance yang kompatibel dengan Amazon RDS atau Aurora PostgreSQL.
Pemahaman dasar tentang database relasional.
Batasan
Beberapa Layanan AWS tidak tersedia di semua AWS Region. Untuk ketersediaan Wilayah, lihat Layanan AWS berdasarkan Wilayah
. Untuk titik akhir tertentu, lihat halaman titik akhir dan kuota Layanan, dan pilih tautan untuk layanan.
Versi produk
Pola ini diuji dengan versi berikut:
Amazon Aurora PostgreSQL 13.3
Amazon RDS untuk PostgreSQL 13.3
AWS SCT 1.0.674
Oracle 12c EE 12.2
Arsitektur
Tumpukan teknologi sumber
Database Oracle lokal
Tumpukan teknologi target
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
Arsitektur target
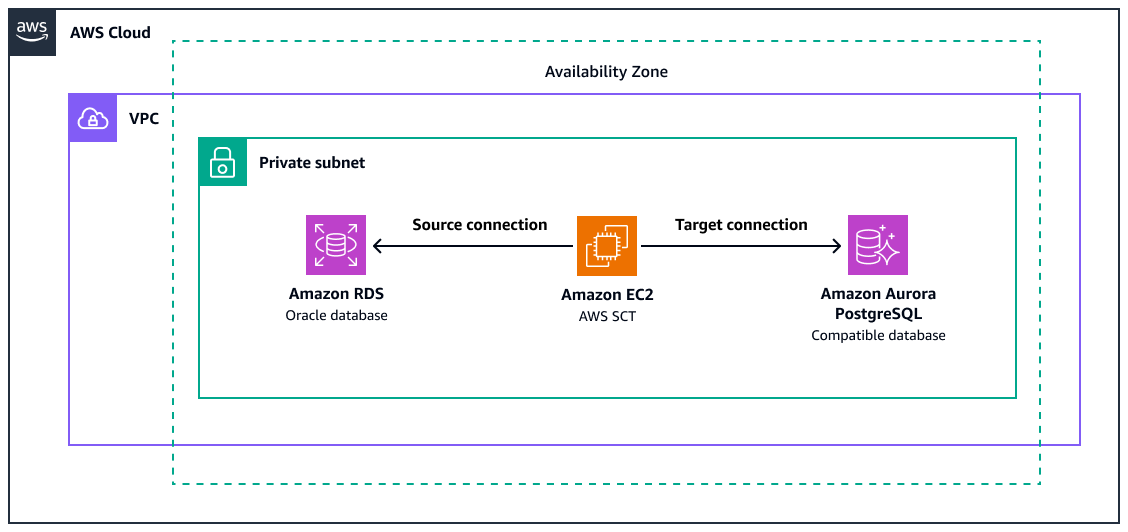
Diagram menunjukkan yang berikut:
Sumber Amazon RDS for Oracle database instance
EC2 Instans Amazon dengan AWS SCT untuk mengonversi fungsi Oracle ke PostgreSQL yang setara
Database target yang kompatibel dengan Amazon Aurora PostgreSQL
Alat
Layanan AWS
Amazon Aurora adalah mesin database relasional yang dikelola sepenuhnya yang dibangun untuk cloud dan kompatibel dengan MySQL dan PostgreSQL.
Amazon Aurora PostgreSQL Compatible Edition adalah mesin database relasional yang dikelola sepenuhnya dan sesuai dengan ACID yang membantu Anda mengatur, mengoperasikan, dan menskalakan penerapan PostgreSQL.
Amazon Elastic Compute Cloud (Amazon EC2) menyediakan kapasitas komputasi yang dapat diskalakan di. AWS Cloud Anda dapat meluncurkan server virtual sebanyak yang Anda butuhkan dan dengan cepat meningkatkannya ke atas atau ke bawah.
Amazon Relational Database Service (Amazon RDS) membantu Anda menyiapkan, mengoperasikan, dan menskalakan database relasional di. AWS Cloud
Amazon Relational Database Service (Amazon RDS) untuk Oracle membantu Anda mengatur, mengoperasikan, dan menskalakan database relasional Oracle di file. AWS Cloud
Amazon Relational Database Service (Amazon RDS) untuk PostgreSQL membantu Anda mengatur, mengoperasikan, dan menskalakan database relasional PostgreSQL di file. AWS Cloud
AWS Schema Conversion Tool (AWS SCT) mendukung migrasi database heterogen dengan secara otomatis mengonversi skema basis data sumber dan sebagian besar kode kustom ke format yang kompatibel dengan database target.
Alat lainnya
Oracle SQL Developer
adalah lingkungan pengembangan terintegrasi yang menyederhanakan pengembangan dan pengelolaan database Oracle baik dalam penerapan tradisional maupun berbasis cloud. pgAdmin
adalah alat manajemen open source untuk PostgreSQL. Ini menyediakan antarmuka grafis yang membantu Anda membuat, memelihara, dan menggunakan objek database. Dalam pola ini, pgAdmin terhubung ke RDS untuk instance database PostgreSQL dan menanyakan data. Atau, Anda dapat menggunakan klien baris perintah psql.
Praktik terbaik
Uji batas set data dan skenario tepi.
Pertimbangkan untuk menerapkan penanganan kesalahan untuk kondisi out-of-bounds indeks.
Optimalkan kueri untuk menghindari pemindaian kumpulan data yang jarang.
Epik
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat PL/SQL blok sumber di Oracle. | Buat PL/SQL blok sumber di Oracle yang menggunakan array asosiatif berikut:
| DBA |
Jalankan PL/SQL blok. | Jalankan PL/SQL blok sumber di Oracle. Jika ada kesenjangan antara nilai indeks dari array asosiatif, tidak ada data yang disimpan dalam celah tersebut. Hal ini memungkinkan loop Oracle untuk iterasi hanya melalui posisi indeks. | DBA |
Tinjau output. | Lima elemen dimasukkan ke dalam array (
| DBA |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat PL/pgSQL blok target di PostgreSQL. | Buat PL/pgSQL blok target di PostgreSQL yang menggunakan array asosiatif berikut:
| DBA |
Jalankan PL/pgSQL blok. | Jalankan PL/pgSQL blok target di PostgreSQL. Jika ada kesenjangan antara nilai indeks dari array asosiatif, tidak ada data yang disimpan dalam celah tersebut. Hal ini memungkinkan loop Oracle untuk iterasi hanya melalui posisi indeks. | DBA |
Tinjau output. | Panjang array lebih besar dari 5 karena
| DBA |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat PL/pgSQL blok target dengan array dan tipe yang ditentukan pengguna. | Untuk mengoptimalkan kinerja dan mencocokkan fungsionalitas Oracle, kita dapat membuat tipe yang ditentukan pengguna yang menyimpan posisi indeks dan data yang sesuai. Pendekatan ini mengurangi iterasi yang tidak perlu dengan mempertahankan asosiasi langsung antara indeks dan nilai.
| DBA |
Jalankan PL/pgSQL blok. | Jalankan PL/pgSQL blok target. Jika ada kesenjangan antara nilai indeks dari array asosiatif, tidak ada data yang disimpan dalam celah tersebut. Hal ini memungkinkan loop Oracle untuk iterasi hanya melalui posisi indeks. | DBA |
Tinjau output. | Seperti yang ditunjukkan pada output berikut, tipe yang ditentukan pengguna hanya menyimpan elemen data yang terisi, yang berarti bahwa panjang array cocok dengan jumlah nilai. Akibatnya,
| DBA |
Sumber daya terkait
AWS dokumentasi
Dokumentasi lainnya
