Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menerapkan logika preprocessing ke dalam model MLdalam satu titik akhir menggunakan pipeline inferensi di Amazon SageMaker
Mohan Gowda Purushothama, Gabriel Rodriguez Garcia, dan Mateusz Zaremba, Amazon Web Services
Ringkasan
Pola ini menjelaskan cara menerapkan beberapa objek model pipeline dalam satu titik akhir dengan menggunakan pipeline inferensi di Amazon. SageMaker Objek model pipeline mewakili tahapan alur kerja machine learning (ML) yang berbeda, seperti preprocessing, inferensi model, dan postprocessing. Untuk mengilustrasikan penerapan objek model pipeline yang terhubung secara serial, pola ini menunjukkan kepada Anda cara menerapkan wadah Scikit-learn pra-pemrosesan dan model regresi berdasarkan algoritme pembelajar linier yang ada di dalamnya. SageMaker Penerapan di-host di belakang satu titik akhir di. SageMaker
catatan
Penerapan dalam pola ini menggunakan tipe instance ml.m4.2xlarge. Sebaiknya gunakan jenis instans yang sesuai dengan persyaratan ukuran data dan kompleksitas alur kerja Anda. Untuk informasi selengkapnya, lihat SageMaker Harga Amazon
Prasyarat dan batasan
Prasyarat
Akun AWS yang aktif
Peran AWS Identity and Access Management (AWS IAM) dengan SageMaker izin dasar dan izin Amazon Simple Storage Service (Amazon S3)
Versi produk
Arsitektur
Tumpukan teknologi target
Amazon Elastic Container Registry (Amazon ECR)
Amazon SageMaker
SageMaker Studio Amazon
Amazon Simple Storage Service (Amazon S3)
Titik akhir inferensi waktu nyata untuk Amazon SageMaker
Arsitektur target
Diagram berikut menunjukkan arsitektur untuk penyebaran objek model SageMaker pipa Amazon.
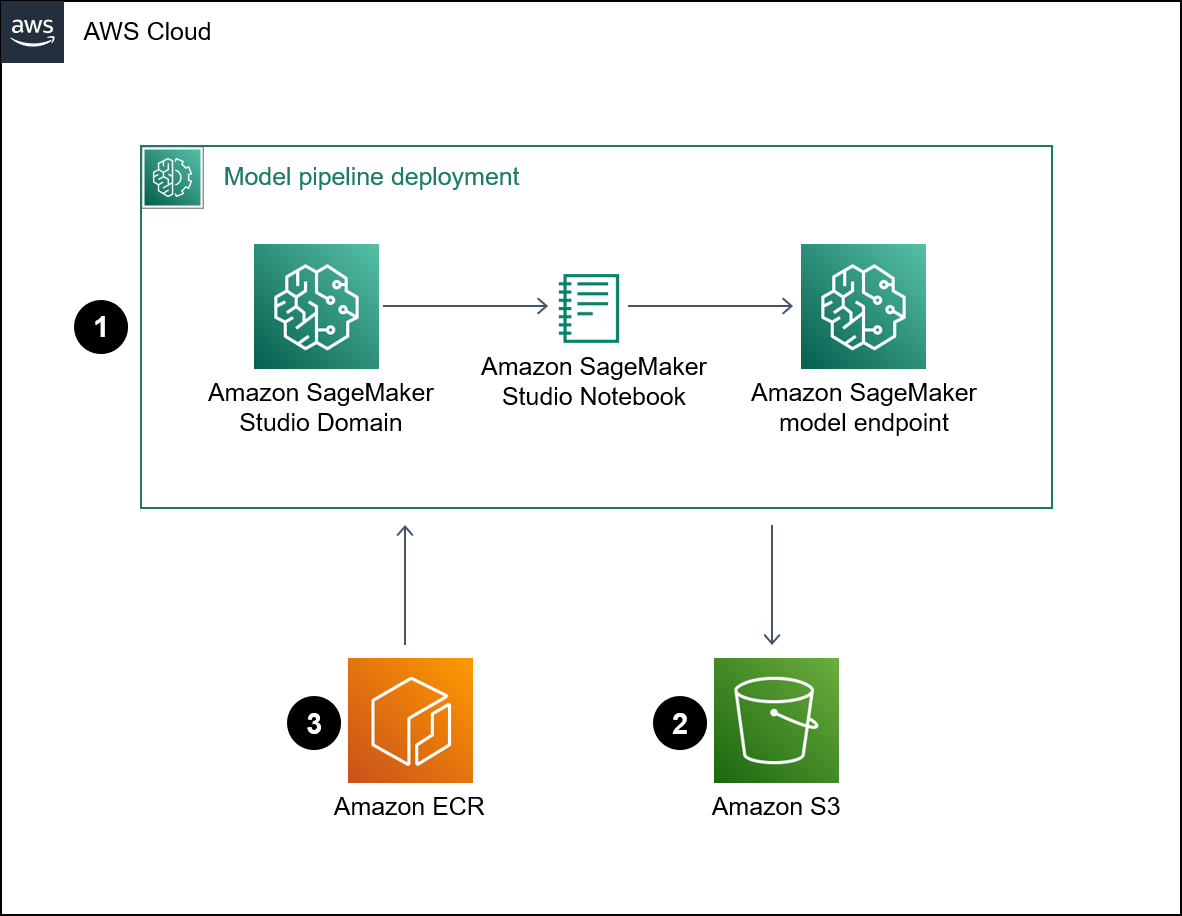
Diagram menunjukkan alur kerja berikut:
SageMaker Notebook menyebarkan model pipa.
Ember S3 menyimpan artefak model.
Amazon ECR mendapatkan gambar wadah sumber dari bucket S3.
Alat
Alat AWS
Amazon Elastic Container Registry (Amazon ECR) adalah layanan registri gambar kontainer terkelola yang aman, terukur, dan andal.
Amazon SageMaker adalah layanan ML terkelola yang membantu Anda membuat dan melatih model ML, lalu menerapkannya ke lingkungan host yang siap produksi.
Amazon SageMaker Studio adalah lingkungan pengembangan terintegrasi (IDE) berbasis web untuk ML yang memungkinkan Anda membuat, melatih, men-debug, menerapkan, dan memantau model ML Anda.
Amazon Simple Storage Service (Amazon S3) adalah layanan penyimpanan objek berbasis cloud yang membantu Anda menyimpan, melindungi, dan mengambil sejumlah data.
Kode
Kode untuk pola ini tersedia di GitHub Inference Pipeline dengan repositori Scikit-learn dan
Epik
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Siapkan dataset untuk tugas regresi Anda. | Buka buku catatan di Amazon SageMaker Studio. Untuk mengimpor semua pustaka yang diperlukan dan menginisialisasi lingkungan kerja Anda, gunakan kode contoh berikut di buku catatan Anda:
Untuk mengunduh kumpulan data sampel, tambahkan kode berikut ke buku catatan Anda:
catatanContoh dalam pola ini menggunakan Abalone Data Set | Ilmuwan data |
Unggah kumpulan data ke bucket S3. | Di buku catatan tempat Anda menyiapkan kumpulan data sebelumnya, tambahkan kode berikut untuk mengunggah data sampel ke bucket S3:
| Ilmuwan data |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Siapkan skrip preprocessor.py. |
| Ilmuwan data |
Buat objek SKLearn preprocessor. | Untuk membuat objek SKLearn preprocessor (disebut SKLearn Estimator) yang dapat Anda masukkan ke dalam pipeline inferensi akhir, jalankan kode berikut di buku catatan Anda: SageMaker
| Ilmuwan data |
Uji inferensi preprocessor. | Untuk mengonfirmasi bahwa preprosesor Anda didefinisikan dengan benar, luncurkan pekerjaan transformasi batch dengan memasukkan kode berikut di SageMaker buku catatan Anda:
|
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat objek model. | Untuk membuat objek model berdasarkan algoritme pembelajar linier, masukkan kode berikut di SageMaker buku catatan Anda:
Kode sebelumnya mengambil image Amazon ECR Docker yang relevan dari Amazon ECR Registry publik untuk model, membuat objek estimator, dan kemudian menggunakan objek tersebut untuk melatih model regresi. | Ilmuwan data |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Menyebarkan model pipa. | Untuk membuat objek model pipeline (yaitu objek preprocessor) dan menyebarkan objek, masukkan kode berikut di buku catatan Anda SageMaker :
catatanAnda dapat menyesuaikan jenis instance yang digunakan dalam objek model untuk memenuhi kebutuhan Anda. | Ilmuwan data |
Uji inferensi. | Untuk mengonfirmasi bahwa titik akhir berfungsi dengan benar, jalankan contoh kode inferensi berikut di buku catatan Anda SageMaker :
| Ilmuwan data |
Sumber daya terkait
