Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membangun arsitektur tanpa server multi-tenant di Amazon Service OpenSearch
Tabby Ward dan Nisha Gambhir, Amazon Web Services
Ringkasan
Amazon OpenSearch Service adalah layanan terkelola yang memudahkan penerapan, pengoperasian, dan skala Elasticsearch, yang merupakan mesin pencari dan analitik sumber terbuka yang populer. OpenSearch Layanan menyediakan pencarian teks gratis serta konsumsi dan dasbor mendekati waktu nyata untuk streaming data seperti log dan metrik.
Penyedia perangkat lunak sebagai layanan (SaaS) sering menggunakan OpenSearch Layanan untuk mengatasi berbagai kasus penggunaan, seperti mendapatkan wawasan pelanggan dengan cara yang terukur dan aman sekaligus mengurangi kompleksitas dan waktu henti.
Menggunakan OpenSearch Layanan di lingkungan multi-penyewa memperkenalkan serangkaian pertimbangan yang memengaruhi partisi, isolasi, penyebaran, dan pengelolaan solusi SaaS Anda. Penyedia SaaS harus mempertimbangkan cara menskalakan cluster Elasticsearch mereka secara efektif dengan beban kerja yang terus berubah. Mereka juga perlu mempertimbangkan bagaimana kondisi tetangga yang berjenjang dan bising dapat memengaruhi model partisi mereka.
Pola ini meninjau model yang digunakan untuk mewakili dan mengisolasi data penyewa dengan konstruksi Elasticsearch. Selain itu, pola berfokus pada arsitektur referensi tanpa server sederhana sebagai contoh untuk menunjukkan pengindeksan dan pencarian menggunakan OpenSearch Layanan di lingkungan multi-penyewa. Ini mengimplementasikan model partisi data pool, yang berbagi indeks yang sama di antara semua penyewa sambil mempertahankan isolasi data penyewa. Pola ini menggunakan AWS layanan berikut: Amazon API Gateway, AWS Lambda, Amazon Simple Storage Service (Amazon S3), dan Service. OpenSearch
Untuk informasi selengkapnya tentang model kumpulan dan model partisi data lainnya, lihat bagian Informasi tambahan.
Prasyarat dan batasan
Prasyarat
Aktif Akun AWS
AWS Command Line Interface (AWS CLI) versi 2.x, diinstal dan dikonfigurasi di macOS, Linux, atau Windows
pip3
— Kode sumber Python disediakan sebagai file.zip untuk digunakan dalam fungsi Lambda. Jika Anda ingin menggunakan kode secara lokal atau menyesuaikannya, ikuti langkah-langkah berikut untuk mengembangkan dan mengkompilasi ulang kode sumber: Hasilkan
requirements.txtfile dengan menjalankan perintah berikut di direktori yang sama dengan skrip Python:pip3 freeze > requirements.txtInstal dependensi:
pip3 install -r requirements.txt
Batasan
Kode ini berjalan dengan Python, dan saat ini tidak mendukung bahasa pemrograman lainnya.
Aplikasi sampel tidak menyertakan dukungan AWS Cross-region atau disaster recovery (DR).
Pola ini dimaksudkan untuk tujuan demonstrasi saja. Ini tidak dimaksudkan untuk digunakan dalam lingkungan produksi.
Arsitektur
Diagram berikut menggambarkan arsitektur tingkat tinggi dari pola ini. Arsitekturnya meliputi:
Lambda untuk mengindeks dan menanyakan konten
OpenSearch Layanan untuk melakukan pencarian
API Gateway untuk menyediakan interaksi API dengan pengguna
Amazon S3 untuk menyimpan data mentah (tidak diindeks)
Amazon CloudWatch untuk memantau log
AWS Identity and Access Management (IAM) untuk membuat peran dan kebijakan penyewa

Otomatisasi dan skala
Untuk kesederhanaan, pola menggunakan AWS CLI untuk menyediakan infrastruktur dan untuk menyebarkan kode sampel. Anda dapat membuat CloudFormation template atau AWS Cloud Development Kit (AWS CDK) skrip untuk mengotomatiskan pola.
Alat
Layanan AWS
AWS CLI
adalah alat terpadu untuk mengelola Layanan AWS dan sumber daya dengan menggunakan perintah di shell baris perintah Anda. Lambda
adalah layanan komputasi yang memungkinkan Anda menjalankan kode tanpa menyediakan atau mengelola server. Lambda menjalankan kode Anda hanya saat diperlukan dan menskalakan secara otomatis, dari beberapa permintaan per hari hingga ribuan per detik. API Gateway
adalah Layanan AWS untuk membuat, menerbitkan, memelihara, memantau, dan mengamankan REST, HTTP, dan WebSocket API pada skala apa pun. Amazon S3
adalah layanan penyimpanan objek yang memungkinkan Anda menyimpan dan mengambil sejumlah informasi kapan saja, dari mana saja di web. OpenSearch Layanan adalah layanan
yang dikelola sepenuhnya yang memudahkan Anda untuk menerapkan, mengamankan, dan menjalankan Elasticsearch dengan biaya efektif dalam skala besar.
Kode
Lampiran menyediakan file sampel untuk pola ini. Ini termasuk:
index_lambda_package.zip— Fungsi Lambda untuk mengindeks data di OpenSearch Layanan dengan menggunakan model pool.search_lambda_package.zip— Fungsi Lambda untuk mencari data di OpenSearch Layanan.Tenant-1-data— Contoh data mentah (tidak diindeks) untuk. Tenant-1Tenant-2-data— Contoh data mentah (tidak diindeks) untuk. Tenant-2
penting
Cerita dalam pola ini mencakup contoh AWS CLI perintah yang diformat untuk Unix, Linux, dan macOS. Untuk Windows, ganti karakter kelanjutan backslash (\) Unix di akhir setiap baris dengan tanda sisipan (^).
catatan
Dalam AWS CLI perintah, ganti semua nilai dalam kurung sudut (<>) dengan nilai yang benar.
Epik
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat ember S3. | Buat ember S3 di. Wilayah AWS Bucket ini akan menyimpan data penyewa yang tidak diindeks untuk aplikasi sampel. Pastikan nama bucket S3 unik secara global, karena namespace dibagikan oleh semua orang. Akun AWS Untuk membuat bucket S3, Anda dapat menggunakan perintah AWS CLI create-bucket
di | Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat domain OpenSearch Layanan. | Jalankan perintah AWS CLI create-elasticsearch-domain untuk membuat domain Service
Jumlah instans diatur ke 1 karena domain adalah untuk tujuan pengujian. Anda perlu mengaktifkan kontrol akses berbutir halus dengan menggunakan Perintah ini membuat nama pengguna master ( Karena domain merupakan bagian dari virtual private cloud (VPC), Anda harus memastikan bahwa Anda dapat menjangkau instance Elasticsearch dengan menentukan kebijakan akses yang akan digunakan. Untuk informasi selengkapnya, lihat Meluncurkan domain OpenSearch Layanan Amazon Anda dalam VPC dalam AWS dokumentasi. | Arsitek cloud, Administrator Cloud |
Siapkan host benteng. | Siapkan instans Windows Amazon Elastic Compute Cloud (Amazon EC2) sebagai host bastion untuk mengakses konsol Kibana. Grup keamanan Elasticsearch harus mengizinkan lalu lintas dari grup keamanan Amazon EC2. Untuk petunjuk, lihat posting blog Mengontrol Akses Jaringan ke Instans EC2 Menggunakan Server Bastion Ketika host bastion telah disiapkan, dan Anda memiliki grup keamanan yang terkait dengan instans yang tersedia, gunakan perintah AWS CLI authorize-security-group-ingress
| Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat peran eksekusi Lambda. | Jalankan perintah AWS CLI create-role
di mana
| Arsitek cloud, Administrator Cloud |
Lampirkan kebijakan terkelola ke peran Lambda. | Jalankan perintah AWS CLI attach-role-policy
| Arsitek cloud, Administrator Cloud |
Buat kebijakan untuk memberikan izin fungsi indeks Lambda untuk membaca objek S3. | Jalankan perintah AWS CLI create-policy
File tersebut
| Arsitek cloud, Administrator Cloud |
Lampirkan kebijakan izin Amazon S3 ke peran eksekusi Lambda. | Jalankan perintah AWS CLI attach-role-policy
di | Arsitek cloud, Administrator Cloud |
Buat fungsi indeks Lambda. | Jalankan perintah AWS CLI create-function
| Arsitek cloud, Administrator Cloud |
Izinkan Amazon S3 memanggil fungsi indeks Lambda. | Jalankan perintah AWS CLI add-permission
| Arsitek cloud, Administrator Cloud |
Tambahkan pemicu Lambda untuk acara Amazon S3. | Jalankan perintah AWS CLI put-bucket-notification-configuration
File tersebut | Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat peran eksekusi Lambda. | Jalankan perintah AWS CLI create-role
di mana
| Arsitek cloud, Administrator Cloud |
Lampirkan kebijakan terkelola ke peran Lambda. | Jalankan perintah AWS CLI attach-role-policy
| Arsitek cloud, Administrator Cloud |
Buat fungsi pencarian Lambda. | Jalankan perintah AWS CLI create-function
| Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat peran IAM penyewa. | Jalankan perintah AWS CLI create-role
File tersebut
| Arsitek cloud, Administrator Cloud |
Buat kebijakan IAM penyewa. | Jalankan perintah AWS CLI create-policy
File tersebut
| Arsitek cloud, Administrator Cloud |
Lampirkan kebijakan IAM penyewa ke peran penyewa. | Jalankan perintah AWS CLI attach-role-policy
Kebijakan ARN berasal dari output dari langkah sebelumnya. | Arsitek cloud, Administrator Cloud |
Buat kebijakan IAM untuk memberikan izin Lambda untuk mengambil peran. | Jalankan perintah AWS CLI create-policy
File tersebut
Untuk | Arsitek cloud, Administrator Cloud |
Buat kebijakan IAM untuk memberikan izin peran indeks Lambda untuk mengakses Amazon S3. | Jalankan perintah AWS CLI create-policy
File tersebut
| Arsitek cloud, Administrator Cloud |
Lampirkan kebijakan ke peran eksekusi Lambda. | Jalankan perintah AWS CLI attach-role-policy
Kebijakan ARN berasal dari output dari langkah sebelumnya. | Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat REST API di API Gateway. | Jalankan perintah AWS CLI create-rest-api untuk membuat resource REST API
Untuk jenis konfigurasi titik akhir, Anda dapat menentukan Perhatikan nilai | Arsitek cloud, Administrator Cloud |
Buat sumber daya untuk API penelusuran. | Sumber daya API pencarian memulai fungsi pencarian Lambda dengan nama sumber daya.
| Arsitek cloud, Administrator Cloud |
Buat metode GET untuk API pencarian. | Jalankan perintah AWS CLI put-method
Untuk | Arsitek cloud, Administrator Cloud |
Buat respons metode untuk API penelusuran. | Jalankan perintah AWS CLI put-method-response
Untuk | Arsitek cloud, Administrator Cloud |
Siapkan integrasi Lambda proxy untuk API pencarian. | Jalankan perintah AWS CLI put-integration
Untuk | Arsitek cloud, Administrator Cloud |
Berikan izin API Gateway untuk memanggil fungsi pencarian Lambda. | Jalankan perintah AWS CLI add-permission
Ubah | Arsitek cloud, Administrator Cloud |
Terapkan API pencarian. | Jalankan perintah AWS CLI create-deployment
Jika Anda memperbarui API, Anda dapat menggunakan AWS CLI perintah yang sama untuk menerapkannya kembali ke tahap yang sama. | Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Masuk ke konsol Kibana. |
| Arsitek cloud, Administrator Cloud |
Buat dan konfigurasikan peran Kibana. | Untuk memberikan isolasi data dan untuk memastikan bahwa satu penyewa tidak dapat mengambil data penyewa lain, Anda perlu menggunakan keamanan dokumen, yang memungkinkan penyewa untuk mengakses hanya dokumen yang berisi ID penyewa mereka.
| Arsitek cloud, Administrator Cloud |
Memetakan pengguna ke peran. |
Kami menyarankan Anda mengotomatiskan pembuatan peran penyewa dan Kibana pada saat orientasi penyewa. | Arsitek cloud, Administrator Cloud |
Buat indeks data penyewa. | Di panel navigasi, di bawah Manajemen, pilih Alat Pengembang, lalu jalankan perintah berikut. Perintah ini membuat
| Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Buat titik akhir VPC untuk Amazon S3. | Jalankan perintah AWS CLI create-vpc-endpoint untuk membuat titik akhir
Untuk | Arsitek cloud, Administrator Cloud |
Buat titik akhir VPC untuk. AWS STS | Jalankan perintah AWS CLI create-vpc-endpoint untuk membuat titik akhir
Untuk | Arsitek cloud, Administrator Cloud |
| Tugas | Deskripsi | Keterampilan yang dibutuhkan |
|---|---|---|
Perbarui file Python untuk fungsi indeks dan pencarian. |
Anda bisa mendapatkan titik akhir Elasticsearch dari tab Ikhtisar konsol Layanan. OpenSearch Ini memiliki format | Arsitek cloud, Pengembang aplikasi |
Perbarui kode Lambda. | Gunakan AWS CLI perintah update-function-code
| Arsitek cloud, Pengembang aplikasi |
Unggah data mentah ke bucket S3. | Gunakan perintah AWS CLI cp
Bucket S3 diatur untuk menjalankan fungsi indeks Lambda setiap kali data diunggah sehingga dokumen diindeks di Elasticsearch. | Arsitek cloud, Administrator Cloud |
Cari data dari konsol Kibana. | Di konsol Kibana, jalankan kueri berikut:
Kueri ini menampilkan semua dokumen yang diindeks di Elasticsearch. Dalam hal ini, Anda akan melihat dua dokumen terpisah untuk Tenant-1 dan Tenant-2. | Arsitek cloud, Administrator Cloud |
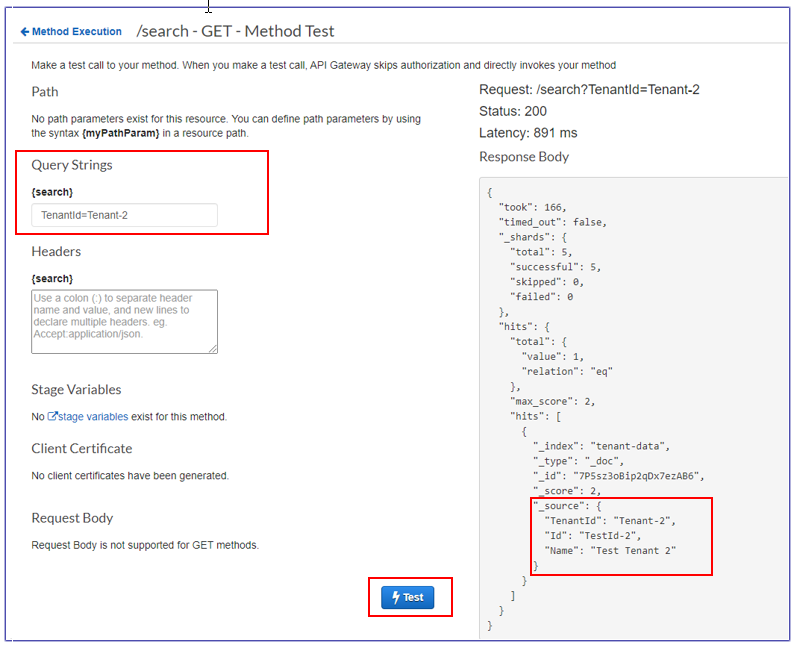
Uji API pencarian dari API Gateway. |
Untuk ilustrasi layar, lihat bagian Informasi tambahan. | Arsitek cloud, Pengembang aplikasi |
Pembersihan sumber daya | Bersihkan semua sumber daya yang Anda buat untuk mencegah biaya tambahan ke akun Anda. | AWS DevOps, Arsitek Cloud, Administrator Cloud |
Sumber daya terkait
Informasi tambahan
Model partisi data
Ada tiga model partisi data umum yang digunakan dalam sistem multi-tenant: silo, pool, dan hybrid. Model yang Anda pilih tergantung pada kepatuhan, tetangga yang bising, operasi, dan kebutuhan isolasi lingkungan Anda.
Model silo
Dalam model silo, setiap data penyewa disimpan di area penyimpanan yang berbeda di mana tidak ada percampuran data penyewa. Anda dapat menggunakan dua pendekatan untuk mengimplementasikan model silo dengan OpenSearch Layanan: domain per penyewa dan indeks per penyewa.
Domain per penyewa — Anda dapat menggunakan domain OpenSearch Layanan terpisah (identik dengan cluster Elasticsearch) per penyewa. Menempatkan setiap penyewa di domainnya sendiri memberikan semua manfaat yang terkait dengan memiliki data dalam konstruksi mandiri. Namun, pendekatan ini memperkenalkan tantangan manajemen dan kelincahan. Sifatnya yang terdistribusi membuat lebih sulit untuk mengumpulkan dan menilai kesehatan operasional dan aktivitas penyewa. Ini adalah opsi mahal yang mengharuskan setiap domain OpenSearch Layanan memiliki tiga node master dan dua node data untuk beban kerja produksi seminimal mungkin.

Indeks per penyewa — Anda dapat menempatkan data penyewa dalam indeks terpisah dalam kluster Layanan. OpenSearch Dengan pendekatan ini, Anda menggunakan pengenal penyewa saat membuat dan memberi nama indeks, dengan mengawali pengenal penyewa ke nama indeks. Pendekatan indeks per penyewa membantu Anda mencapai tujuan silo Anda tanpa memperkenalkan cluster yang benar-benar terpisah untuk setiap penyewa. Namun, Anda mungkin mengalami tekanan memori jika jumlah indeks bertambah, karena pendekatan ini membutuhkan lebih banyak pecahan, dan node master harus menangani lebih banyak alokasi dan penyeimbangan kembali.

Isolasi dalam model silo — Dalam model silo, Anda menggunakan kebijakan IAM untuk mengisolasi domain atau indeks yang menyimpan data setiap penyewa. Kebijakan ini mencegah satu penyewa mengakses data penyewa lain. Untuk menerapkan model isolasi silo, Anda dapat membuat kebijakan berbasis sumber daya yang mengontrol akses ke sumber daya penyewa. Ini sering merupakan kebijakan akses domain yang menentukan tindakan mana yang dapat dilakukan prinsipal pada sub-sumber daya domain, termasuk indeks Elasticsearch dan API. Dengan kebijakan berbasis identitas IAM, Anda dapat menentukan tindakan yang diizinkan atau ditolak pada domain, indeks, atau API dalam Layanan. OpenSearch ActionElemen kebijakan IAM menjelaskan tindakan atau tindakan spesifik yang diizinkan atau ditolak oleh kebijakan, dan Principal elemen tersebut menentukan akun, pengguna, atau peran yang terpengaruh.
Kebijakan contoh berikut memberikan akses Tenant-1 penuh (seperti yang ditentukan olehes:*) ke sub-sumber daya pada tenant-1 domain saja. Bagian tambahan /* dalam Resource elemen menunjukkan bahwa kebijakan ini berlaku untuk sub-sumber daya domain, bukan untuk domain itu sendiri. Ketika kebijakan ini berlaku, penyewa tidak diizinkan untuk membuat domain baru atau mengubah setelan pada domain yang sudah ada.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:<Region>:<account-id>:domain/tenant-1/*" } ] }
Untuk mengimplementasikan model silo penyewa per indeks, Anda perlu memodifikasi kebijakan sampel ini untuk membatasi lebih lanjut Tenant-1 ke indeks atau indeks yang ditentukan, dengan menentukan nama indeks. Kebijakan sampel berikut Tenant-1 membatasi tenant-index-1 indeks.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:<Region>:<account-id>:domain/test-domain/tenant-index-1/*" } ] }
Model kolam
Dalam model pool, semua data penyewa disimpan dalam indeks dalam domain yang sama. Pengidentifikasi penyewa disertakan dalam data (dokumen) dan digunakan sebagai kunci partisi, sehingga Anda dapat menentukan data mana yang menjadi milik penyewa mana. Model ini mengurangi overhead manajemen. Mengoperasikan dan mengelola indeks gabungan lebih mudah dan lebih efisien daripada mengelola beberapa indeks. Namun, karena data penyewa bercampur dalam indeks yang sama, Anda kehilangan isolasi penyewa alami yang disediakan oleh model silo. Pendekatan ini mungkin juga menurunkan kinerja karena efek tetangga yang bising.

Isolasi penyewa dalam model kolam — Secara umum, isolasi penyewa menantang untuk diterapkan dalam model kolam renang. Mekanisme IAM yang digunakan dengan model silo tidak memungkinkan Anda untuk menggambarkan isolasi berdasarkan ID penyewa yang disimpan dalam dokumen Anda.
Pendekatan alternatif adalah dengan menggunakan dukungan kontrol akses halus (FGAC) yang disediakan oleh Open Distro untuk Elasticsearch. FGAC memungkinkan Anda mengontrol izin pada tingkat indeks, dokumen, atau bidang. Dengan setiap permintaan, FGAC mengevaluasi kredensi pengguna dan mengautentikasi pengguna atau menolak akses. Jika FGAC mengautentikasi pengguna, FGAC mengambil semua peran yang dipetakan ke pengguna tersebut dan menggunakan set lengkap izin untuk menentukan cara menangani permintaan.
Untuk mencapai isolasi yang diperlukan dalam model gabungan, Anda dapat menggunakan keamanan tingkat dokumen
{ "bool": { "must": { "match": { "tenantId": "Tenant-1" } } } }
Model hibrida
Model hibrida menggunakan kombinasi model silo dan kolam renang di lingkungan yang sama untuk menawarkan pengalaman unik untuk setiap tingkat penyewa (seperti tingkatan gratis, standar, dan premium). Setiap tingkatan mengikuti profil keamanan yang sama yang digunakan dalam model pool.

Isolasi penyewa dalam model hybrid — Dalam model hybrid, Anda mengikuti profil keamanan yang sama seperti pada model pool, di mana menggunakan model keamanan FGAC pada tingkat dokumen menyediakan isolasi penyewa. Meskipun strategi ini menyederhanakan manajemen cluster dan menawarkan kelincahan, ini memperumit aspek lain dari arsitektur. Misalnya, kode Anda memerlukan kompleksitas tambahan untuk menentukan model mana yang terkait dengan setiap penyewa. Anda juga harus memastikan bahwa kueri penyewa tunggal tidak memenuhi seluruh domain dan menurunkan pengalaman untuk penyewa lain.
Pengujian di API Gateway
Jendela uji untuk Tenant-1 kueri

Jendela uji untuk Tenant-2 kueri
Lampiran
