Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Interpretasi lokal
Metode yang paling populer untuk interpretasi lokal model kompleks didasarkan pada Shapley Additive Explanations (SHAP) [8] atau gradien terintegrasi [11]. Setiap metode memiliki sejumlah varian yang spesifik untuk jenis model.
Untuk model ansambel pohon, gunakan SHAP pohon
Dalam kasus model berbasis pohon, pemrograman dinamis memungkinkan perhitungan cepat dan tepat dari nilai Shapley
Untuk jaringan saraf dan model yang dapat dibedakan, gunakan gradien dan konduktansi terintegrasi
Gradien terintegrasi menyediakan cara langsung untuk menghitung atribusi fitur di jaringan saraf. Konduktansi dibangun di atas gradien terintegrasi untuk membantu Anda menafsirkan atribusi dari bagian jaringan saraf seperti lapisan dan neuron individu. (Lihat [3,11], implementasi ada di https://captum.ai/
Untuk semua kasus lainnya, gunakan Kernel SHAP
Anda dapat menggunakan Kernel SHAP untuk menghitung atribusi fitur untuk model apa pun, tetapi ini adalah perkiraan untuk menghitung nilai Shapley penuh dan tetap mahal secara komputasi (lihat [8]). Sumber daya komputasi yang diperlukan untuk Kernel SHAP tumbuh dengan cepat dengan jumlah fitur. Ini membutuhkan metode pendekatan yang dapat mengurangi kesetiaan, pengulangan, dan kekokohan penjelasan. Amazon SageMaker AI Clarify menyediakan metode kemudahan yang menerapkan kontainer bawaan untuk menghitung nilai SHAP Kernal dalam instance terpisah. (Sebagai contoh, lihat GitHub Repositori Fairness and Explainability
Untuk model pohon tunggal, variabel split dan nilai daun memberikan model yang segera dapat dijelaskan, dan metode yang dibahas sebelumnya tidak memberikan wawasan tambahan. Demikian pula, untuk model linier, koefisien memberikan penjelasan yang jelas tentang perilaku model. (SHAP dan metode gradien terintegrasi keduanya mengembalikan kontribusi yang ditentukan oleh koefisien.)
Baik SHAP dan metode berbasis gradien terintegrasi memiliki kelemahan. SHAP mengharuskan atribusi diturunkan dari rata-rata tertimbang dari semua kombinasi fitur. Atribusi yang diperoleh dengan cara ini dapat menyesatkan ketika memperkirakan pentingnya fitur jika ada interaksi yang kuat antara fitur. Metode yang didasarkan pada gradien terintegrasi bisa sulit untuk ditafsirkan karena banyaknya dimensi yang ada dalam jaringan saraf besar, dan metode ini sensitif terhadap pilihan titik dasar. Secara lebih umum, model dapat menggunakan fitur dengan cara yang tidak terduga untuk mencapai tingkat kinerja tertentu dan ini dapat bervariasi dengan model—kepentingan fitur selalu bergantung pada model.
Visualisasi yang direkomendasikan
Bagan berikut menyajikan beberapa cara yang direkomendasikan untuk memvisualisasikan interpretasi lokal yang telah dibahas di bagian sebelumnya. Untuk data tabular, kami menyarankan grafik batang sederhana yang menunjukkan atribusi, sehingga dapat dengan mudah dibandingkan dan digunakan untuk menyimpulkan bagaimana model membuat prediksi.
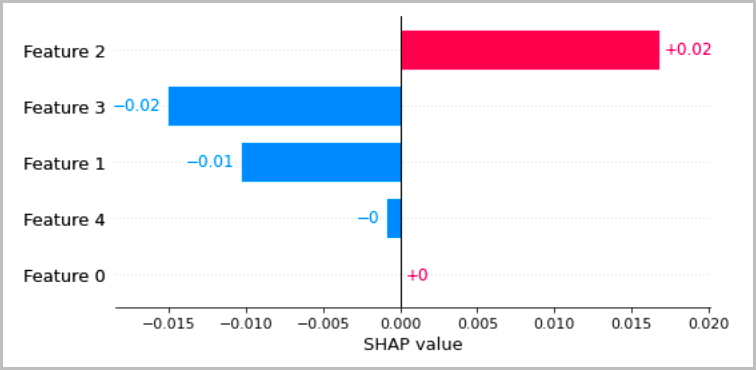
Untuk data teks, menyematkan token mengarah ke sejumlah besar input skalar. Metode yang direkomendasikan di bagian sebelumnya menghasilkan atribusi untuk setiap dimensi penyematan dan untuk setiap output. Untuk menyaring informasi ini menjadi visualisasi, atribusi untuk token tertentu dapat dijumlahkan. Contoh berikut menunjukkan jumlah atribusi untuk model penjawab pertanyaan berbasis BERT yang dilatih pada dataset SQUAD. Dalam hal ini, label yang diprediksi dan benar adalah token untuk kata “perancis.”

Jika tidak, norma vektor atribusi token dapat ditetapkan sebagai nilai atribusi total, seperti yang ditunjukkan pada contoh berikut.

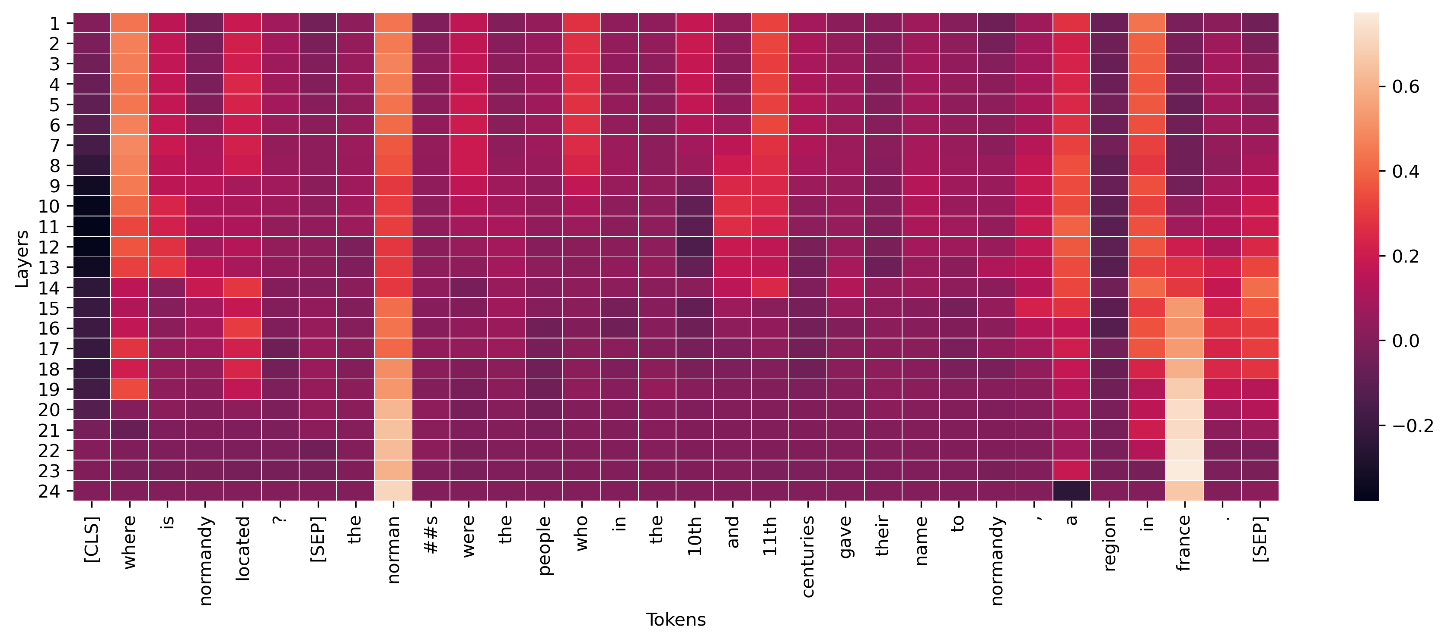
Untuk lapisan menengah dalam model pembelajaran mendalam, agregasi serupa dapat diterapkan pada konduktansi untuk visualisasi, seperti yang ditunjukkan pada contoh berikut. Norma vektor konduktansi token untuk lapisan transformator ini menunjukkan aktivasi akhirnya untuk prediksi token akhir (“perancis”).
Vektor aktivasi konsep menyediakan metode untuk mempelajari jaringan saraf dalam secara lebih rinci [6]. Metode ini mengekstrak fitur dari lapisan dalam jaringan yang sudah terlatih dan melatih pengklasifikasi linier pada fitur-fitur tersebut untuk membuat kesimpulan tentang informasi di lapisan. Misalnya, Anda mungkin ingin menentukan lapisan mana dari model bahasa berbasis BERT yang berisi informasi paling banyak tentang bagian-bagian pidato. Dalam hal ini, Anda dapat melatih part-of-speech model linier pada setiap output lapisan dan membuat perkiraan kasar bahwa pengklasifikasi berkinerja terbaik dikaitkan dengan lapisan yang memiliki part-of-speech informasi paling banyak. Meskipun kami tidak merekomendasikan ini sebagai metode utama untuk menafsirkan jaringan saraf, ini dapat menjadi pilihan untuk studi yang lebih rinci dan bantuan dalam desain arsitektur jaringan.
