Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memisahkan hubungan tabel selama dekomposisi database
Bagian ini memberikan panduan untuk memecah hubungan tabel yang kompleks dan operasi JOIN selama dekomposisi basis data monolitik. Gabungan tabel menggabungkan baris dari dua atau lebih tabel berdasarkan kolom terkait di antara mereka. Tujuan memisahkan hubungan ini adalah untuk mengurangi kopling tinggi antar tabel sambil mempertahankan integritas data di seluruh layanan mikro.
Bagian ini berisi topik berikut:
Strategi denormalisasi
Denormalisasi adalah strategi desain database yang melibatkan sengaja memperkenalkan redundansi dengan menggabungkan atau menduplikasi data di seluruh tabel. Ketika memecah database besar menjadi database kecil, mungkin masuk akal untuk menduplikasi beberapa data di seluruh layanan. Misalnya, menyimpan detail pelanggan dasar, seperti nama dan alamat email, baik dalam layanan pemasaran maupun layanan pesanan menghilangkan kebutuhan akan pencarian lintas layanan yang konstan. Layanan pemasaran mungkin memerlukan preferensi pelanggan dan informasi kontak untuk penargetan kampanye, sementara layanan pesanan memerlukan data yang sama untuk pemrosesan pesanan dan pemberitahuan. Meskipun ini menciptakan beberapa redundansi data, ini dapat secara signifikan meningkatkan kinerja dan kemandirian layanan, memungkinkan tim pemasaran untuk mengoperasikan kampanye mereka tanpa bergantung pada pencarian layanan pelanggan waktu nyata.
Saat menerapkan denormalisasi, fokuslah pada bidang yang sering diakses yang Anda identifikasi melalui analisis pola akses data yang cermat. Anda dapat menggunakan alat, Oracle AWR laporan semacam itu ataupg_stat_statements, untuk memahami data mana yang biasanya diambil bersama. Pakar domain juga dapat memberikan wawasan berharga tentang pengelompokan data alami. Ingatlah bahwa denormalisasi bukanlah all-or-nothing pendekatan—hanya data duplikat yang terbukti meningkatkan kinerja sistem atau mengurangi dependensi kompleks.
Reference-by-key strategi
reference-by-key Strategi adalah pola desain database di mana hubungan antar entitas dipertahankan melalui kunci unik daripada menyimpan data terkait yang sebenarnya. Alih-alih hubungan kunci asing tradisional, layanan mikro modern sering hanya menyimpan pengidentifikasi unik dari data terkait. Misalnya, daripada menyimpan semua detail pelanggan di tabel pesanan, layanan pesanan hanya menyimpan ID pelanggan dan mengambil informasi pelanggan tambahan melalui panggilan API bila diperlukan. Pendekatan ini menjaga independensi layanan sambil memastikan akses ke data terkait.
Pola CQRS
Pola Command Query Responsibility Segregation (CQRS) memisahkan operasi baca dan tulis dari penyimpanan data. Pola ini sangat berguna dalam sistem yang kompleks dengan persyaratan kinerja tinggi, terutama yang memiliki beban asimetris read/write . Jika aplikasi Anda sering membutuhkan data yang digabungkan dari berbagai sumber, Anda dapat membuat model CQRS khusus alih-alih gabungan yang kompleks. Misalnya, daripada bergabungProduct,Pricing, dan Inventory tabel pada setiap permintaan, pertahankan Product Catalog tabel konsolidasi yang berisi data yang diperlukan. Manfaat dari pendekatan ini bisa lebih besar daripada biaya tabel tambahan.
Pertimbangkan skenario di manaProduct,Price, dan Inventory layanan sering membutuhkan informasi produk. Alih-alih mengonfigurasi layanan ini untuk mengakses tabel bersama secara langsung, buat Product Catalog layanan khusus. Layanan ini memelihara basis datanya sendiri yang berisi informasi produk terkonsolidasi. Ini bertindak sebagai sumber kebenaran tunggal untuk pertanyaan terkait produk. Ketika detail produk, harga, atau tingkat inventaris berubah, masing-masing layanan dapat mempublikasikan acara untuk memperbarui Product Catalog layanan. Ini memberikan konsistensi data sambil mempertahankan independensi layanan. Gambar berikut menunjukkan konfigurasi ini, di mana Amazon EventBridge
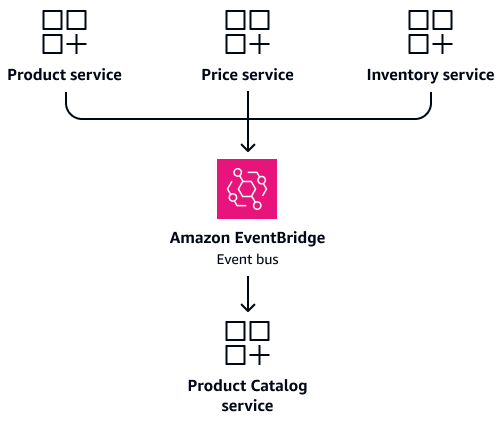
Seperti yang dibahas diSinkronisasi data berbasis peristiwa, bagian selanjutnya, perbarui model CQRS melalui acara. Ketika detail produk, harga, atau tingkat inventaris berubah, masing-masing layanan mempublikasikan acara. Product CatalogLayanan berlangganan acara ini dan memperbarui tampilan konsolidasinya. Ini memberikan pembacaan cepat tanpa gabungan yang rumit, dan mempertahankan kemandirian layanan.
Sinkronisasi data berbasis peristiwa
Sinkronisasi data berbasis peristiwa adalah pola di mana perubahan data ditangkap dan disebarkan sebagai peristiwa, yang memungkinkan sistem atau komponen yang berbeda untuk mempertahankan status data yang disinkronkan. Saat data berubah, alih-alih segera memperbarui semua database terkait, publikasikan acara untuk memberi tahu layanan berlangganan. Misalnya, ketika pelanggan mengubah alamat pengiriman mereka di Customer layanan, sebuah CustomerUpdated acara memulai pembaruan ke Order layanan dan Delivery layanan pada jadwal setiap layanan. Pendekatan ini menggantikan gabungan tabel kaku dengan pembaruan berbasis peristiwa yang fleksibel dan dapat diskalakan. Beberapa layanan mungkin secara singkat memiliki data yang sudah ketinggalan zaman, tetapi trade-off adalah peningkatan skalabilitas sistem dan independensi layanan.
Menerapkan alternatif untuk bergabung tabel
Mulailah dekomposisi database Anda dengan operasi baca karena biasanya lebih mudah untuk dimigrasi dan divalidasi. Setelah jalur baca stabil, atasi operasi penulisan yang lebih kompleks. Untuk persyaratan kritis dan kinerja tinggi, pertimbangkan untuk menerapkan pola CQRS. Gunakan database terpisah yang dioptimalkan untuk membaca sambil mempertahankan database lain untuk menulis.
Bangun sistem tangguh dengan menambahkan logika coba lagi untuk panggilan lintas layanan dan menerapkan lapisan caching yang sesuai. Pantau interaksi layanan dengan cermat, dan siapkan peringatan untuk masalah konsistensi data. Tujuan akhirnya bukanlah konsistensi sempurna di mana-mana—itu menciptakan layanan independen yang berkinerja baik sambil mempertahankan akurasi data yang dapat diterima untuk kebutuhan bisnis Anda.
Sifat layanan mikro yang dipisahkan memperkenalkan kompleksitas baru berikut dalam manajemen data:
-
Data didistribusikan. Data sekarang berada di database terpisah, yang dikelola oleh layanan independen.
-
Sinkronisasi real-time di seluruh layanan seringkali tidak praktis, memerlukan model konsistensi akhirnya.
-
Operasi yang sebelumnya terjadi dalam satu transaksi database sekarang menjangkau beberapa layanan.
Untuk mengatasi tantangan ini, lakukan hal berikut:
-
Menerapkan arsitektur berbasis peristiwa — Gunakan antrian pesan dan penerbitan acara untuk menyebarkan perubahan data di seluruh layanan. Untuk informasi selengkapnya, lihat Membangun Arsitektur Berbasis Acara
di Tanah Tanpa Server. -
Mengadopsi pola orkestrasi saga — Pola ini membantu Anda mengelola transaksi terdistribusi dan menjaga integritas data di seluruh layanan. Untuk informasi selengkapnya, lihat Membangun aplikasi terdistribusi tanpa server menggunakan pola orkestrasi saga
di Blog. AWS -
Desain untuk kegagalan — Menggabungkan mekanisme coba lagi, pemutus sirkuit, dan transaksi kompensasi untuk menangani masalah jaringan atau kegagalan layanan.
-
Gunakan stamping versi — Lacak versi data untuk mengelola konflik dan pastikan pembaruan terbaru diterapkan.
-
Regular rekonsiliasi — Menerapkan proses sinkronisasi data periodik untuk menangkap dan memperbaiki ketidakkonsistenan apa pun.
Contoh berbasis skenario
Contoh skema berikut memiliki dua tabel, Customer tabel dan Order tabel:
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
Berikut ini adalah contoh bagaimana Anda dapat menggunakan pendekatan denormalisasi:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
OrderTabel baru memiliki nama pelanggan dan alamat email yang didenormalisasi. customer_idIni direferensikan, dan tidak ada kendala kunci asing dengan tabel. Customer Berikut ini adalah manfaat dari pendekatan denormalisasi ini:
-
OrderLayanan ini dapat menampilkan riwayat pesanan dengan detail pelanggan, dan tidak memerlukan panggilan API keCustomerlayanan mikro. -
Jika
Customerlayanan sedang down,Orderlayanan tetap berfungsi penuh. -
Kueri untuk pemrosesan dan pelaporan pesanan berjalan lebih cepat.
Diagram berikut menunjukkan aplikasi monolitik yang mengambil data pesanan menggunakangetOrder(customer_id), getOrder(order_id)getCustomerOders(customer_id), dan panggilan createOrder(Order
order) API ke layanan mikro. Order
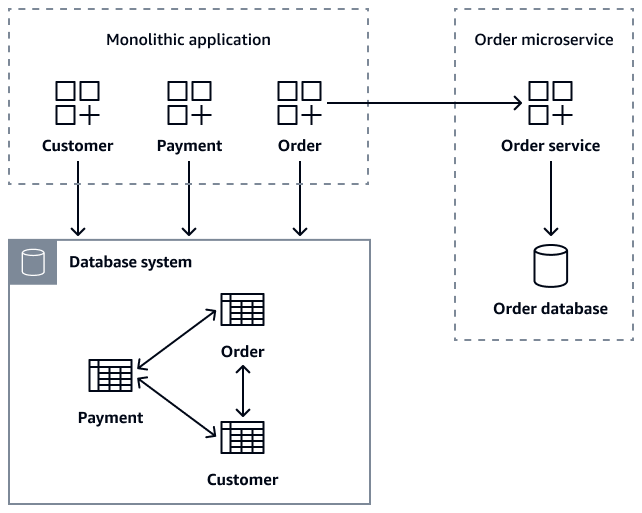
Selama migrasi layanan mikro, Anda dapat mempertahankan Order tabel dalam database monolitik sebagai tindakan keamanan transisi, memastikan bahwa aplikasi lama tetap berfungsi. Namun, sangat penting bahwa semua operasi terkait pesanan baru dirutekan melalui API Order layanan mikro, yang memelihara basis datanya sendiri sambil secara bersamaan menulis ke database lama sebagai cadangan. Pola penulisan ganda ini menyediakan jaring pengaman. Hal ini memungkinkan untuk migrasi bertahap sambil menjaga stabilitas sistem. Setelah semua pelanggan berhasil bermigrasi ke layanan mikro baru, Anda dapat menghentikan tabel lama Order di database monolitik. Setelah menguraikan aplikasi monolitik dan database-nya menjadi Order layanan terpisah Customer dan mikro, menjaga konsistensi data menjadi tantangan utama.
