Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Migrasi di tempat
Migrasi di tempat menghilangkan kebutuhan untuk menulis ulang semua file data Anda. Sebagai gantinya, file metadata Iceberg dibuat dan ditautkan ke file data Anda yang ada. Metode ini biasanya lebih cepat dan lebih hemat biaya, terutama untuk kumpulan data besar atau tabel yang memiliki format file yang kompatibel seperti Parket, Avro, dan ORC.
catatan
Migrasi di tempat tidak dapat digunakan saat bermigrasi ke Tabel Amazon S3.
Iceberg menawarkan dua opsi utama untuk menerapkan migrasi di tempat:
-
Menggunakan prosedur snapshot
untuk membuat tabel Iceberg baru sambil menjaga tabel sumber tidak berubah. Untuk informasi selengkapnya, lihat Tabel Snapshot dalam dokumentasi Gunung Es. -
Menggunakan prosedur migrasi
untuk membuat tabel Iceberg baru sebagai substitusi untuk tabel sumber. Untuk informasi selengkapnya, lihat Memigrasi Tabel di dokumentasi Gunung Es. Meskipun prosedur ini bekerja dengan Hive Metastore (HMS), saat ini tidak kompatibel dengan. AWS Glue Data CatalogReplikasi prosedur migrasi tabel di AWS Glue Data Catalog bagian nanti dalam panduan ini memberikan solusi untuk mencapai hasil yang serupa dengan Katalog Data.
Setelah Anda melakukan migrasi di tempat dengan menggunakan salah satu snapshot ataumigrate, beberapa file data mungkin tetap tidak bermigrasi. Ini biasanya terjadi ketika penulis terus menulis ke tabel sumber selama atau setelah migrasi. Untuk memasukkan file-file yang tersisa ini ke dalam tabel Iceberg Anda, Anda dapat menggunakan prosedur add_files
Katakanlah Anda memiliki products tabel berbasis Parket yang dibuat dan dihuni di Athena sebagai berikut:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
Bagian berikut menjelaskan bagaimana Anda dapat menggunakan snapshot dan migrate prosedur dengan tabel ini.
Opsi 1: prosedur snapshot
snapshotProsedur ini membuat tabel Iceberg baru yang memiliki nama berbeda tetapi mereplikasi skema dan partisi tabel sumber. Operasi ini meninggalkan tabel sumber sama sekali tidak berubah baik selama dan setelah tindakan. Ini secara efektif membuat salinan tabel yang ringan, yang sangat berguna untuk menguji skenario atau eksplorasi data tanpa risiko modifikasi pada sumber data asli. Pendekatan ini memungkinkan periode transisi di mana tabel asli dan tabel Gunung Es tetap tersedia (lihat catatan di akhir bagian ini). Saat pengujian selesai, Anda dapat memindahkan tabel Iceberg baru Anda ke produksi dengan mentransisikan semua penulis dan pembaca ke tabel baru.
Anda dapat menjalankan snapshot prosedur dengan menggunakan Spark di model penyebaran EMR Amazon apa pun (misalnya, Amazon EMR di EC2, Amazon EMR di EKS, EMR EMR Tanpa Server) dan. AWS Glue
Untuk menguji migrasi di tempat dengan prosedur snapshot Spark, ikuti langkah-langkah berikut:
-
Luncurkan aplikasi Spark dan konfigurasikan sesi Spark dengan pengaturan berikut:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Jalankan
snapshotprosedur untuk membuat tabel Iceberg baru yang menunjuk ke file data tabel asli:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)Rangka data keluaran berisi
imported_files_count(jumlah file yang ditambahkan). -
Validasi tabel baru dengan menanyakannya:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
Catatan
-
Setelah Anda menjalankan prosedur, modifikasi file data apa pun pada tabel sumber akan membuat tabel yang dihasilkan tidak sinkron. File baru yang Anda tambahkan tidak akan terlihat di tabel Iceberg, dan file yang Anda hapus akan memengaruhi kemampuan kueri di tabel Iceberg. Untuk menghindari masalah sinkronisasi:
-
Jika tabel Iceberg baru dimaksudkan untuk penggunaan produksi, hentikan semua proses yang menulis ke tabel asli dan arahkan ke tabel baru.
-
Jika Anda memerlukan periode transisi atau jika tabel Iceberg baru untuk tujuan pengujian, lihat Menyinkronkan tabel Iceberg setelah migrasi di tempat nanti di bagian ini untuk panduan tentang mempertahankan sinkronisasi tabel.
-
-
Bila Anda menggunakan
snapshotprosedur,gc.enabledproperti diatur kefalsedalam properti tabel tabel Iceberg dibuat. Pengaturan ini melarang tindakan sepertiexpire_snapshots,remove_orphan_files, atauDROP TABLEdenganPURGEopsi, yang secara fisik akan menghapus file data. Operasi penghapusan atau penggabungan gunung es, yang tidak berdampak langsung pada file sumber, masih diperbolehkan. -
Untuk membuat tabel Iceberg baru berfungsi penuh, tanpa batasan tindakan yang menghapus file data secara fisik, Anda dapat mengubah properti
gc.enabledtabel menjadi.trueNamun, pengaturan ini akan memungkinkan tindakan yang memengaruhi file data sumber, yang dapat merusak akses ke tabel asli. Oleh karena itu, ubahgc.enabledproperti hanya jika Anda tidak perlu lagi mempertahankan fungsionalitas tabel asli. Contoh:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
Opsi 2: prosedur migrasi
migrateProsedur ini membuat tabel Iceberg baru yang memiliki nama, skema, dan partisi yang sama dengan tabel sumber. Ketika prosedur ini berjalan, ia mengunci tabel sumber dan mengganti namanya menjadi <table_name>_BACKUP_ (atau nama khusus yang ditentukan oleh parameter backup_table_name prosedur).
catatan
Jika Anda mengatur parameter drop_backup prosedur ketrue, tabel asli tidak akan dipertahankan sebagai cadangan.
Akibatnya, prosedur migrate tabel mengharuskan semua modifikasi yang mempengaruhi tabel sumber untuk dihentikan sebelum tindakan dilakukan. Sebelum Anda menjalankan migrate prosedur:
-
Hentikan semua penulis yang berinteraksi dengan tabel sumber.
-
Ubah pembaca dan penulis yang tidak mendukung Iceberg secara asli untuk mengaktifkan dukungan Iceberg.
Contoh:
-
Athena terus bekerja tanpa modifikasi.
-
Spark membutuhkan:
-
File Iceberg Java Archive (JAR) untuk disertakan dalam classpath (lihat Bekerja dengan Gunung Es di Amazon EMR dan Bekerja dengan Gunung AWS Glue Es di bagian sebelumnya dalam panduan ini).
-
Konfigurasi katalog sesi Spark berikut (menggunakan
SparkSessionCataloguntuk menambahkan dukungan Iceberg sambil mempertahankan fungsionalitas katalog bawaan untuk tabel non-Iceberg):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Setelah Anda menjalankan prosedur, Anda dapat me-restart penulis Anda dengan konfigurasi Iceberg baru mereka.
Saat ini, migrate prosedur tidak kompatibel dengan AWS Glue Data Catalog, karena Katalog Data tidak mendukung RENAME operasi. Oleh karena itu, kami menyarankan Anda menggunakan prosedur ini hanya ketika Anda bekerja dengan Hive Metastore. Jika Anda menggunakan Katalog Data, lihat bagian selanjutnya untuk pendekatan alternatif.
Anda dapat menjalankan migrate prosedur di semua model penyebaran EMR Amazon (Amazon EMR di EC2, Amazon EMR di EKS, EMR EMR Tanpa Server AWS Glue) dan, tetapi memerlukan koneksi yang dikonfigurasi ke Hive Metastore. Amazon EMR di EC2 adalah pilihan yang disarankan karena menyediakan konfigurasi Hive Metastore bawaan, yang meminimalkan kompleksitas penyiapan.
Untuk menguji migrasi di tempat dengan prosedur migrate Spark dari EMR Amazon di kluster EC2 yang dikonfigurasi dengan Hive Metastore, ikuti langkah-langkah berikut:
-
Luncurkan aplikasi Spark dan konfigurasikan sesi Spark untuk menggunakan implementasi katalog Iceberg Hive. Misalnya, jika Anda menggunakan
pysparkCLI:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Buat
productstabel di Hive Metastore. Ini adalah tabel sumber, yang sudah ada dalam migrasi tipikal.-
Buat tabel Hive
productseksternal di Hive Metastore untuk menunjuk ke data yang ada di Amazon S3:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
Tambahkan partisi yang ada dengan menggunakan
MSCK REPAIR TABLEperintah:spark.sql(f""" MSCK REPAIR TABLE products """ ) -
Konfirmasikan bahwa tabel berisi data dengan menjalankan
SELECTkueri:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)Contoh output:

-
-
Gunakan prosedur Iceberg
migrate:df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()Rangka data keluaran berisi
migrated_files_count(jumlah file yang ditambahkan ke tabel Iceberg):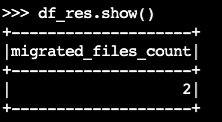
-
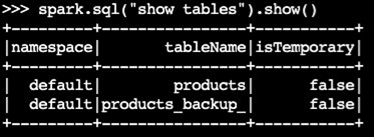
Konfirmasikan bahwa tabel cadangan telah dibuat:
spark.sql("show tables").show()Contoh output:
-
Validasi operasi dengan menanyakan tabel Iceberg:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
Catatan
-
Setelah Anda menjalankan prosedur, semua proses saat ini yang kueri atau tulis ke tabel sumber akan terpengaruh jika tidak dikonfigurasi dengan benar dengan dukungan Iceberg. Oleh karena itu, kami menyarankan Anda mengikuti langkah-langkah ini:
-
Hentikan semua proses dengan menggunakan tabel sumber sebelum migrasi.
-
Lakukan migrasi.
-
Aktifkan kembali proses dengan menggunakan pengaturan Iceberg yang tepat.
-
-
Jika modifikasi file data terjadi selama proses migrasi (file baru ditambahkan atau file dihapus), tabel yang dihasilkan akan tidak sinkron. Untuk opsi sinkronisasi, lihat Menyinkronkan tabel Iceberg setelah migrasi di tempat nanti di bagian ini.
Mereplikasi prosedur migrasi tabel di AWS Glue Data Catalog
Anda dapat mereplikasi hasil prosedur migrasi di AWS Glue Data Catalog (mencadangkan tabel asli dan menggantinya dengan tabel Iceberg) dengan mengikuti langkah-langkah berikut:
-
Gunakan prosedur snapshot untuk membuat tabel Iceberg baru yang menunjuk ke file data tabel asli.
-
Cadangkan metadata tabel asli di Katalog Data:
-
Gunakan GetTableAPI untuk mengambil definisi tabel sumber.
-
Gunakan GetPartitionsAPI untuk mengambil definisi partisi tabel sumber.
-
Gunakan CreateTableAPI untuk membuat tabel cadangan di Katalog Data.
-
Gunakan BatchCreatePartitionAPI CreatePartitionatau untuk mendaftarkan partisi ke tabel cadangan di Katalog Data.
-
-
Ubah properti tabel
gc.enabledIcebergfalseuntuk mengaktifkan operasi tabel lengkap. -
Jatuhkan meja aslinya.
-
Temukan file JSON metadata tabel Iceberg di folder metadata lokasi root tabel.
-
Daftarkan tabel baru di Katalog Data dengan menggunakan prosedur register_table
dengan nama tabel asli dan lokasi metadata.jsonfile yang dibuat oleh prosedur:snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
Menyimpan tabel Iceberg tetap sinkron setelah migrasi di tempat
add_filesProsedur ini menyediakan cara yang fleksibel untuk memasukkan data yang ada ke dalam tabel Iceberg. Secara khusus, ia mendaftarkan file data yang ada (seperti file Parquet) dengan mereferensikan jalur absolutnya di lapisan metadata Iceberg. Secara default, prosedur menambahkan file dari semua partisi tabel ke tabel Iceberg, tetapi Anda dapat secara selektif menambahkan file dari partisi tertentu. Pendekatan selektif ini sangat berguna dalam beberapa skenario:
-
Ketika partisi baru ditambahkan ke tabel sumber setelah migrasi awal.
-
Ketika file data ditambahkan ke atau dihapus dari partisi yang ada setelah migrasi awal. Namun, menambahkan kembali partisi yang dimodifikasi membutuhkan penghapusan partisi terlebih dahulu. Informasi lebih lanjut tentang ini disediakan nanti di bagian ini.
Berikut adalah beberapa pertimbangan untuk menggunakan add_file prosedur setelah migrasi di tempat (snapshotataumigrate) dilakukan, agar tabel Iceberg baru tetap sinkron dengan file data sumber:
-
Ketika data baru ditambahkan ke partisi baru di tabel sumber, gunakan
add_filesprosedur denganpartition_filteropsi untuk secara selektif memasukkan penambahan ini ke dalam tabel Iceberg:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)atau:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
add_filesProsedur memindai file baik di seluruh tabel sumber atau di partisi tertentu ketika Anda menentukanpartition_filteropsi, dan mencoba untuk menambahkan semua file yang ditemukan ke tabel Iceberg. Secara default, properticheck_duplicate_filesprosedur diatur ketrue, yang mencegah prosedur berjalan jika file sudah ada di tabel Iceberg. Ini penting karena tidak ada opsi bawaan untuk melewati file yang ditambahkan sebelumnya, dan menonaktifkancheck_duplicate_filesakan menyebabkan file ditambahkan dua kali, membuat duplikat. Saat file baru ditambahkan ke tabel sumber, ikuti langkah-langkah berikut:-
Untuk partisi baru, gunakan
add_filesdengan apartition_filteruntuk mengimpor hanya file dari partisi baru. -
Untuk partisi yang ada, pertama-tama hapus partisi dari tabel Iceberg, dan kemudian jalankan kembali
add_filesuntuk partisi itu, dengan menentukan.partition_filterContoh:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
catatan
Setiap add_files operasi menghasilkan snapshot tabel Iceberg baru dengan data yang ditambahkan.
Memilih strategi migrasi di tempat yang tepat
Untuk memilih strategi migrasi terbaik di tempat, pertimbangkan pertanyaan dalam tabel berikut.
Pertanyaan |
Rekomendasi |
Penjelasan |
|---|---|---|
Apakah Anda ingin bermigrasi dengan cepat tanpa menulis ulang data sambil menjaga tabel Hive dan Iceberg dapat diakses untuk pengujian atau transisi bertahap? |
|
Gunakan |
Apakah Anda menggunakan Hive Metastore dan apakah Anda ingin segera mengganti tabel Hive Anda dengan tabel Iceberg, tanpa menulis ulang data? |
|
Gunakan Catatan: Opsi ini kompatibel dengan Hive Metastore tetapi tidak dengan. AWS Glue Data Catalog Gunakan |
Apakah Anda menggunakan AWS Glue Data Catalog dan apakah Anda ingin segera mengganti tabel Hive Anda dengan tabel Iceberg, tanpa menulis ulang data? |
Adaptasi |
Mereplikasi perilaku
Catatan: Opsi ini memerlukan penanganan manual panggilan AWS Glue API untuk pencadangan metadata. Gunakan |
