Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Merancang arsitektur AI tanpa server
Menerjemahkan prinsip-prinsip AI tanpa server ke dalam sistem dunia nyata membutuhkan arsitektur yang bijaksana. Tujuannya adalah untuk mengintegrasikan secara longgar digabungkan Layanan AWS ke dalam jaringan pipa modular dan cerdas yang berskala elastis dan merespons secara real time.
Bagian ini memberikan panduan preskriptif tentang cara merakit sistem AI cloud-native menggunakan layanan AWS tanpa server, termasuk orkestrasi AI generatif, inferensi waktu nyata, dan komputasi tepi. Setiap pola arsitektur sesuai dengan kasus penggunaan perusahaan umum, memastikan relevansi dan penerapan.
Di bagian ini
Pola arsitektur dasar
Dalam arsitektur aplikasi berbasis peristiwa tradisional, sistem ini disusun menjadi empat lapisan logis yang memisahkan masalah sambil memungkinkan skalabilitas dan responsif. Di bagian atas, lapisan aplikasi menangani interaksi pengguna APIs, dan peristiwa UI, sering memicu peristiwa khusus domain ke dalam sistem. Di bawahnya, lapisan orkestrasi mengelola alur kerja, aturan bisnis, dan pengurutan peristiwa menggunakan alat seperti mesin status atau alur kerja tanpa server. Lapisan layanan berisi fungsi modular yang dapat digunakan kembali atau layanan mikro yang merespons peristiwa dan menjalankan logika inti. Pada dasarnya, lapisan data bertanggung jawab atas persistensi, streaming, dan sumber acara. Lapisan data memanfaatkan layanan seperti database, penyimpanan objek, atau log peristiwa untuk memancarkan dan mengkonsumsi peristiwa perubahan. Bersama-sama, lapisan-lapisan ini mendukung arsitektur yang digabungkan secara longgar, dapat diskalakan, dan dapat dipelihara di mana peristiwa mendorong aliran di seluruh tumpukan.
Sistem AI tanpa server juga terdiri dari layanan berbasis peristiwa yang digabungkan secara longgar yang dapat menskalakan, berkembang, dan pulih secara independen. Untuk merancang sistem ini dengan konsistensi dan skalabilitas, penting untuk melihat arsitektur sebagai lima lapisan yang berbeda. Setiap lapisan melayani fungsi tertentu dan memetakan langsung ke yang dibuat khusus. Layanan AWS Diagram berikut menunjukkan setiap lapisan.
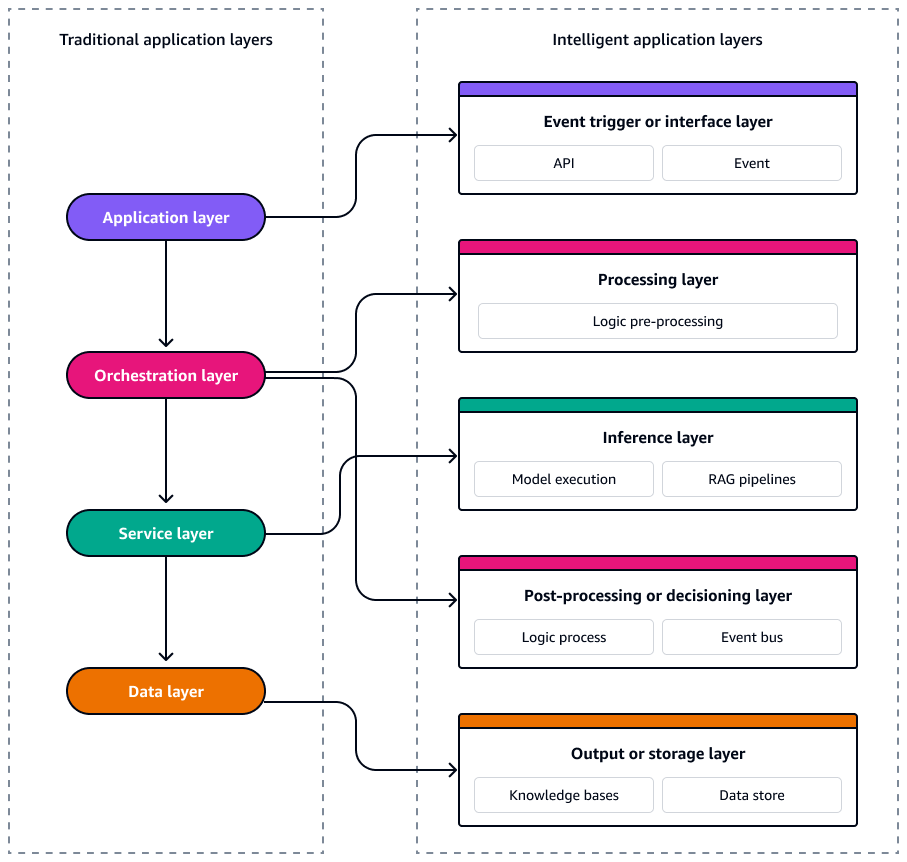
Kelima lapisan ini membentuk cetak biru untuk membangun aplikasi cerdas yang digerakkan oleh peristiwa yang tangguh, dapat diamati, dan dioptimalkan untuk biaya dan kinerja.
Pemicu peristiwa atau lapisan antarmuka
Pemicu peristiwa atau lapisan antarmuka adalah titik masuk ke sistem AI tanpa server Anda. Ini menangkap interaksi pengguna, peristiwa sistem, atau perubahan data dan memancarkannya sebagai peristiwa terstruktur ke dalam arsitektur. Ini memungkinkan orkestrasi asinkron dan memisahkan input hulu dari logika pemrosesan hilir.
Tanggung jawab lapisan pemicu peristiwa meliputi:
-
Menangkap tindakan pengguna seperti klik, pesan, dan unggahan
-
Memancarkan peristiwa domain atau mengubah notifikasi
-
Menormalkan data yang masuk untuk konsumsi hilir
Layanan AWS yang biasa digunakan dengan lapisan ini antara lain sebagai berikut:
-
Amazon API Gateway menerima masukan pengguna melalui REST atau WebSocket APIs.
-
Amazon EventBridge merutekan peristiwa internal atau eksternal menggunakan registri skema.
-
Amazon Simple Storage Service (Amazon S3) memicu pembuatan objek seperti unggahan dokumen dan file media.
-
Amazon Kinesis dan Amazon Managed Streaming untuk Apache Kafka (Amazon MSK) menyerap acara streaming dalam skala besar.
Contoh: Permintaan dukungan pelanggan yang dikirimkan melalui formulir web memicu EventBridge aturan, memulai alur kerja agen Amazon Bedrock di hilir.
Lapisan pengolahan
Lapisan pemrosesan mengubah atau memperkaya data sebelum meneruskannya ke model AI. Ini menangani tugas pra-pemrosesan seperti validasi input, pemformatan, penandaan metadata, deteksi bahasa, dan pengayaan data dengan menggunakan tabel pencarian atau eksternal. APIs
Tanggung jawab lapisan pemrosesan meliputi:
-
Validasi dan normalkan input mentah.
-
Ekstrak atau suntikkan metadata seperti bahasa dan ID pelanggan.
-
Rute atau logika cabang berdasarkan atribut data.
Layanan AWS yang biasa digunakan dengan lapisan ini antara lain sebagai berikut:
-
AWS Lambdaadalah komputasi stateless, berbasis peristiwa untuk logika transformasi.
-
AWS Step Functionsmengatur tugas pra-pemrosesan multi-langkah.
-
Amazon Comprehend menyediakan deteksi bahasa, pengenalan entitas, atau analisis sentimen sebagai bagian dari preprocessing.
Contoh: Klaim asuransi yang diunggah dipindai untuk informasi identitas pribadi (PII) dan jenis dokumen dengan menggunakan Lambda dan Amazon Comprehend sebelum ringkasan AI.
Lapisan inferensi
Sebagai inti dari sistem AI, lapisan inferensi menjalankan inferensi machine learning (ML) atau foundation model (FM). Ini mungkin termasuk satu atau lebih model—generatif, prediktif, atau klasifikasi—tergantung pada kasus penggunaan.
Tanggung jawab lapisan inferensi meliputi:
-
Jalankan inferensi model mL atau FM.
-
Hasilkan prediksi, klasifikasi, atau konten yang dihasilkan.
-
Integrasikan konteks Retrieval Augmented Generation (RAG) jika berlaku.
Layanan AWS yang biasa digunakan dengan lapisan ini antara lain sebagai berikut:
-
Amazon Bedrock menyediakan inferensi model dasar (teks, gambar, multimodal) dari penyedia seperti Anthropic, Amazon (untuk Amazon Nova)Meta, dan. Mistral
-
Amazon SageMaker Serverless Inference menjalankan model ML kustom dalam skala besar.
-
Amazon Bedrock Agents menyediakan penalaran berbasis model bahasa besar (LLM) dan orkestrasi berbasis tujuan.
Contoh: Agen Amazon Bedrock menggunakan Amazon Nova Pro untuk menghasilkan respons terhadap kueri dukungan yang kompleks, berdasarkan pengetahuan perusahaan menggunakan RAG.
Lapisan pasca-pemrosesan atau pengambilan keputusan
Lapisan pasca-pemrosesan atau pengambilan keputusan menyempurnakan atau bertindak berdasarkan hasil inferensi. Hal ini dapat memformat respon, log output, memanggil tindakan hilir, atau membuat keputusan berdasarkan kepercayaan model, klasifikasi, atau aturan bisnis eksternal.
Tanggung jawab lapisan pasca-pemrosesan atau pengambilan keputusan meliputi:
-
Format output AI untuk sistem hilir atau tampilan.
-
Memicu logika atau panggilan APIs bersyarat.
-
Rute data yang diperkaya untuk penyimpanan atau analitik.
Layanan AWS yang biasa digunakan dengan lapisan ini antara lain sebagai berikut:
-
Lambda dapat memformat hasil, menerapkan transformasi, atau menelepon. APIs
-
Amazon Simple Notification Service (Amazon SNS) dan EventBridge memancarkan peristiwa lebih lanjut berdasarkan keluaran model.
-
Step Functions menerapkan logika rantai, misalnya, meningkatkan kasus dukungan jika sentimen sama dengan “marah”.
Contoh: Rekomendasi produk dari LLM divalidasi silang terhadap inventaris real-time dengan menggunakan fungsi Lambda sebelum rekomendasi dikirim ke pengguna.
Output atau lapisan penyimpanan
Terakhir, lapisan output atau penyimpanan menangani pengiriman hasil ke pengguna atau sistem dan mempertahankan output terstruktur untuk audit, analitik, atau loop umpan balik.
Tanggung jawab lapisan output atau penyimpanan meliputi:
-
Kembalikan hasil AI ke pengguna akhir melalui APIs atau UIs.
-
Pertahankan output dan log terstruktur.
-
Umpan ke danau data atau jaringan pipa pelatihan ulang.
Layanan AWS yang biasa digunakan dengan lapisan ini antara lain sebagai berikut:
-
Amazon S3 menyimpan log inferensi, ringkasan, atau konten yang dihasilkan.
-
Amazon DynamoDB menyediakan penyimpanan nilai kunci latensi rendah untuk output AI khusus sesi.
-
Amazon OpenSearch Service menyediakan output terstruktur indeks untuk penelusuran dan analitik.
-
API Gateway dan WebSocket APIs memberikan respons kembali ke klien frontend atau seluler.
Contoh: Ringkasan dokumen hukum, yang dihasilkan oleh Amazon Bedrock, disimpan di Amazon S3 dan diindeks OpenSearch di Layanan untuk mengaktifkan pencarian perusahaan semantik.
Pertimbangan desain lintas lapisan
Pertimbangan dan pola desain utama berikut berlaku di semua lapisan arsitektur:
-
Ketahanan - Setiap lapisan harus gagal dan mencoba lagi secara independen (misalnya, antrian huruf mati () di Lambda). DLQs
-
Observabilitas — Memancarkan log, jejak, dan metrik terstruktur dari setiap tahap ke Amazon CloudWatch untuk mendeteksi penyimpangan perilaku.
-
Keamanan — Gunakan pemisahan peran AWS Identity and Access Management(IAM) dan AWS Key Management Service(AWS KMS) untuk enkripsi data lintas lapisan.
-
Optimalisasi biaya — Gunakan eksekusi asinkron jika memungkinkan dan pilih model berukuran tepat.
-
Ekstensibilitas - Desain modular memungkinkan layanan diganti atau ditingkatkan secara independen.
Kelima lapisan ini membentuk arsitektur referensi modular, skalabel, dan tanpa server untuk beban kerja yang didukung AI. AWS Setiap lapisan dapat dikembangkan, digunakan, dan dioptimalkan secara independen, memungkinkan iterasi cepat, keunggulan operasional, dan pemisahan masalah yang jelas di seluruh domain bisnis.
Dengan menggunakan pola berlapis ini sebagai perancah desain, perusahaan dapat membakukan pendekatan mereka terhadap AI tanpa server dan mempercepat jalur dari prototipe ke produksi dengan percaya diri.
Pertimbangan desain arsitektur
Arsitektur AI tanpa server AWS memungkinkan Anda membangun aplikasi cerdas yang modular, dapat diskalakan, dan tingkat produksi. Baik Anda menerapkan model di edge, mengatur jalur inferensi multi-langkah, atau membangun asisten AI generatif, dapat memberi daya pada aplikasi asli AI generasi berikutnya. Layanan AWS
Saat merancang arsitektur AI tanpa server, ingatlah fokus desain utama dan praktik terbaik berikut:
-
Keamanan — Gunakan peran IAM berbutir halus, enkripsi prompt dan output, dan batasi akses API.
-
Observabilitas — Integrasikan CloudWatch AWS X-Ray,, dan log kustom untuk setiap tahap pipeline.
-
Skalabilitas — Gunakan komponen tanpa server saja, seperti Lambda, Amazon Bedrock, dan Inferensi Tanpa Server. SageMaker
-
Latensi — Manfaatkan Lambda @Edge, konkurensi yang disediakan, atau inferensi asinkron.
-
Modularitas — Desain pipeline menggunakan pemicu peristiwa dan fungsi terisolasi untuk setiap tugas.
-
Reusability — Parameterize prompt, gunakan layer Lambda bersama, dan pisahkan logika dengan menggunakan Step Functions.
