Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Perencanaan pemulihan bencana
Disaster Recovery (DR) adalah layanan penting untuk kelangsungan dan kepatuhan bisnis perusahaan. AMS bermitra dengan Anda untuk membantu Anda merencanakan, menerapkan, dan mempertahankan strategi DR Anda di AMS.
AMS landing zone (LZ), multi-akun dan akun tunggal, menyediakan asli, Multi-AZ, ketersediaan tinggi untuk komponen infrastruktur AMS yang memenuhi sebagian besar skenario perlindungan bencana. Namun, tergantung pada cakupan geografis bisnis Anda, Anda mungkin memerlukan perlindungan regional. Untuk ketersediaan lintas wilayah dan DR, akun AMS lain diperlukan di wilayah yang berbeda (ini berlaku untuk landing zone multi-akun dan landing zone akun tunggal).
AMS sejalan dengan panduan AWS DR seperti yang dijelaskan di blog ini, Memulihkan sistem kritis misi dengan cepat dalam bencana
Multi Situs (atau Sangat Tersedia)
Siaga Hangat
Lampu Pilot
Pencadangan dan Pemulihan
Opsi ini dan dukungan AMS untuk mereka dijelaskan di bagian berikut.
Multi-site atau sangat tersedia (HA)
Solusi HA biasanya disediakan oleh fungsionalitas bawaan aplikasi, seperti pengelompokan atau replikasi sinkron. Pengguna diarahkan ke Prod dan HA/DR node. DNS menunjuk ke node secara langsung atau melalui penyeimbang beban elastis (ELB).
Arsitek cloud AMS (CA) Anda akan bekerja dengan Anda sebagai bagian dari perencanaan Anda Well-Architected-Review dan DR.
HA DR menggunakan layanan dan fitur aplikasi dan AWS-native, seperti yang diilustrasikan dalam grafik berikut:
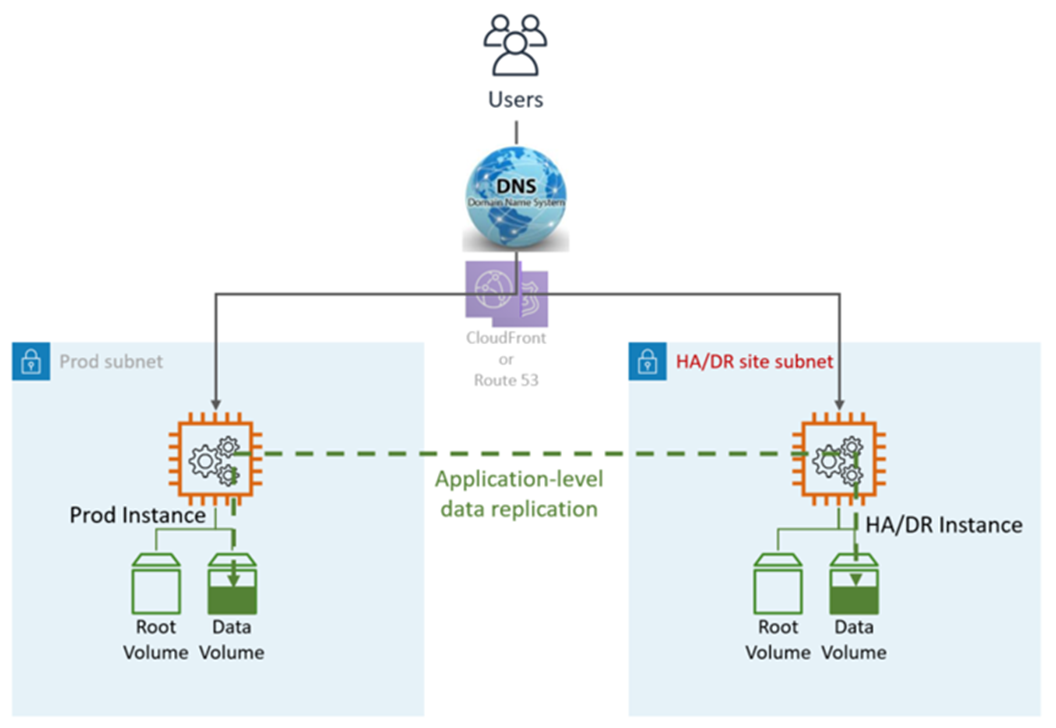
Situs DR bisa sama atau berbeda Wilayah AWS.
catatan
Region (Cross-Region) yang berbeda akan memiliki lingkungan Active Directory yang berbeda.
Langkah DR (failover): Failover otomatis, tidak diperlukan langkah manual. Jika terjadi kegagalan pada LZ primer, pengguna akan secara otomatis diarahkan kembali ke node. DR/HA Ini dicapai dengan konfigurasi DNS dan aplikasi.
Metrik HA DR:
Tujuan Titik Pemulihan (RPO): <5 menit
Tujuan Waktu Pemulihan dan (RTO): <5 menit
Pemeliharaan: Tinggi (Perubahan sinkron diperlukan di kedua lingkungan, seperti konfigurasi Aplikasi, tambalan, SG atau ALB, sertifikat, dan sebagainya).
Biaya: Tinggi
Warm standby
Istilah “warm standby” digunakan untuk menggambarkan skenario pemulihan bencana (DR) di mana versi lingkungan yang diperkecil berjalan di cloud.
Replikasi data ditangani oleh lapisan aplikasi, biasanya secara asinkron, ke instance online, sedangkan instance lainnya (misalnya, Application dan Web tier) mungkin dimatikan untuk menghemat biaya. Pengguna diarahkan hanya ke situs Produksi. AWS Sumber daya lain seperti penyeimbang beban elastis (ELB) dapat disediakan sebelumnya di situs DR juga.
AMS Cloud Architect (CA) Anda akan bekerja dengan Anda sebagai bagian dari perencanaan Anda Well-Architected-Review dan DR.
Warm Standby DR menggunakan layanan dan fitur aplikasi dan AWS-native, seperti yang diilustrasikan dalam grafik berikut:
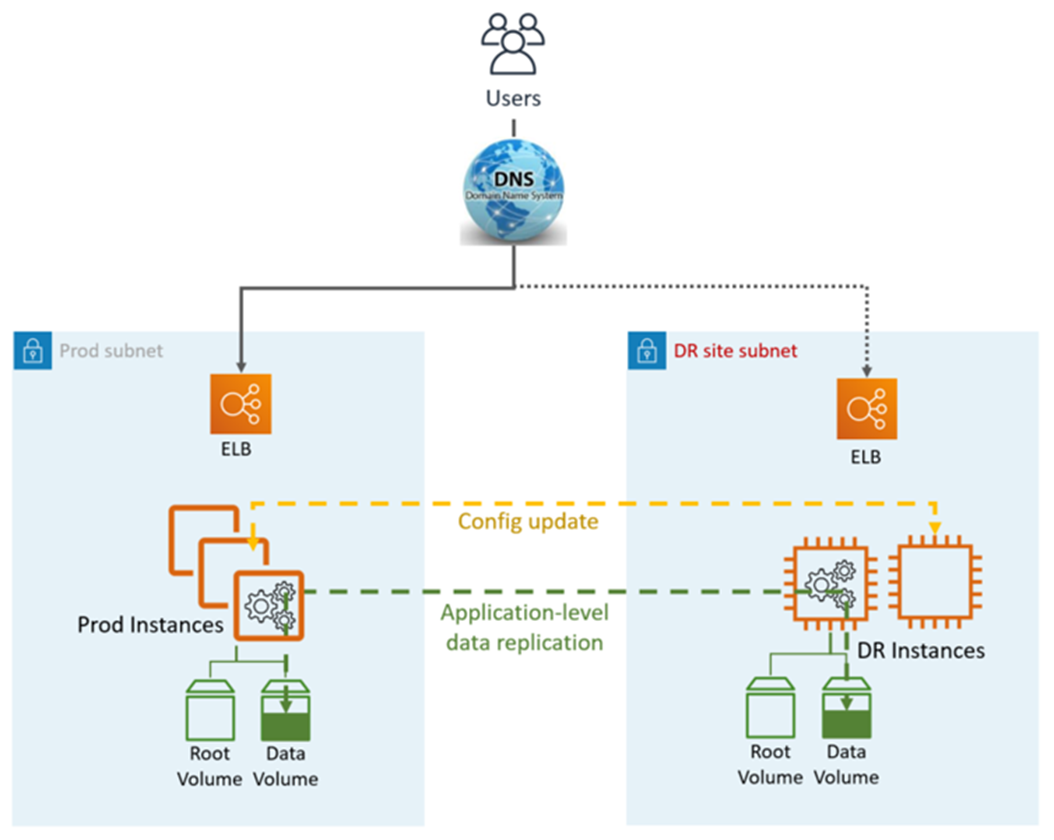
Situs DR bisa sama atau berbeda Wilayah AWS.
catatan
Region (Cross-Region) yang berbeda akan memiliki lingkungan Active Directory yang berbeda.
Langkah DR (failover):
Rem replikasi data dan jadikan instance data di situs DR sebagai master
Perbarui konfigurasi aplikasi sesuai kebutuhan (IP baru, nama server, dan sebagainya)
Alihkan DNS ke situs DR (ELB)
Dependensi AD jika diperlukan (Akun layanan, SPN, GPO, dan sebagainya)
Metrik HA DR:
Tujuan Titik Pemulihan (RPO): <1 jam
Tujuan Waktu Pemulihan dan (RTO): <1 jam (tergantung pada jumlah instance dan orkestrasi)
Pemeliharaan: Tinggi (Perubahan sinkron diperlukan di kedua lingkungan, seperti konfigurasi Aplikasi, penambalan, grup keamanan (SG) atau penyeimbang beban aplikasi (ALB), sertifikat, dan sebagainya).
Biaya: Sedang
Pilot light
Dalam pendekatan pemulihan bencana (DR) ini, Anda mereplikasi bagian dari lingkungan Prod Anda untuk serangkaian layanan inti terbatas. Sebagian kecil infrastruktur Anda selalu berjalan, secara bersamaan menyinkronkan data yang dapat berubah (seperti database atau dokumen), sementara bagian lain dari infrastruktur Anda dimatikan dan hanya digunakan selama pengujian. Tidak seperti pendekatan pencadangan dan pemulihan, Anda harus memastikan bahwa elemen inti Anda yang paling penting sudah dikonfigurasi dan berjalan di landing zone DR (lampu pilot).
AMS Cloud Architect Anda akan bekerja dengan Anda sebagai bagian dari perencanaan Anda Well-Architected-Review dan DR.
Pilot Light DR menggunakan aplikasi dan layanan dan fitur AWS asli, seperti yang diilustrasikan dalam grafik berikut:
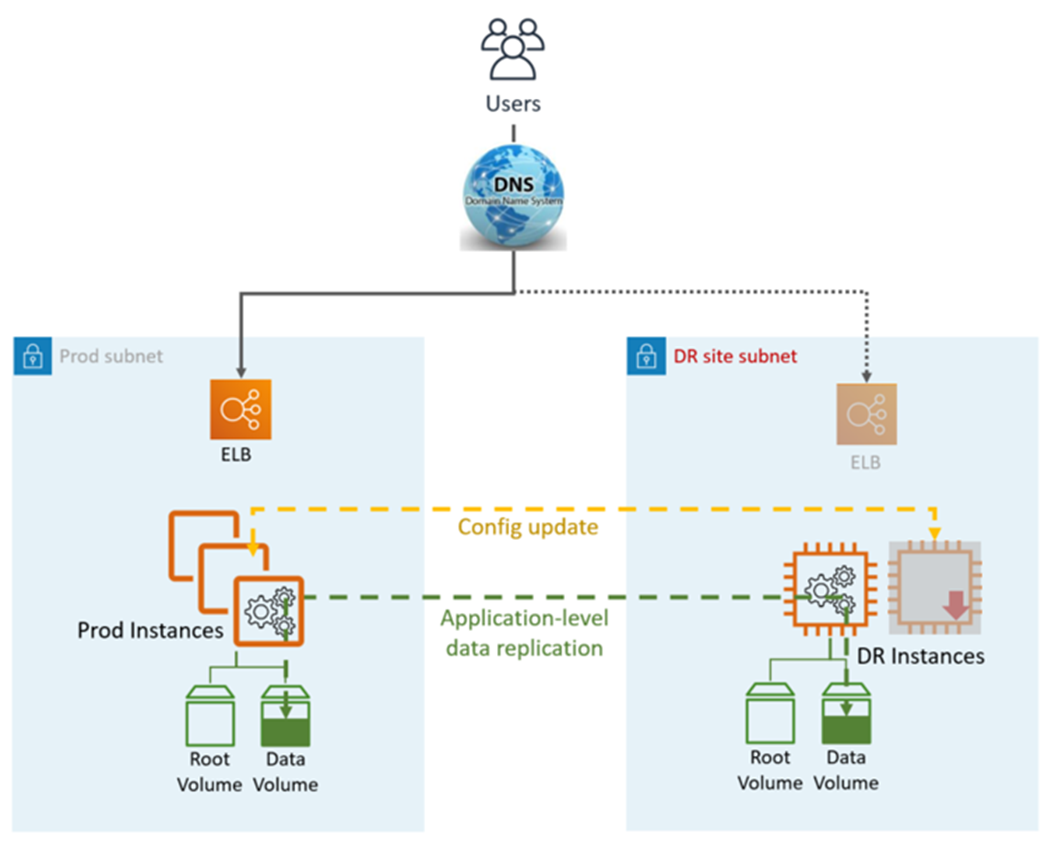
Situs DR bisa sama atau berbeda Wilayah AWS.
catatan
Region (Cross-Region) yang berbeda akan memiliki lingkungan Active Directory yang berbeda.
Langkah DR (failover):
Rem replikasi data dan jadikan instance data di situs DR sebagai master
Mulai instance dan infrastruktur yang dimatikan
Perbarui konfigurasi aplikasi sesuai kebutuhan (IP baru, nama server, dan sebagainya)
Tambahkan instance ke ELB sesuai kebutuhan
Alihkan DNS ke situs DR (ELB)
Dependensi AD, jika diperlukan (Akun layanan, SPN, GPO, dan sebagainya)
Metrik DR Pilot Light:
Tujuan Titik Pemulihan (RPO): <1 jam
Tujuan Waktu Pemulihan dan (RTO): ~ 1 jam (tergantung pada jumlah instance dan orkestrasi)
Pemeliharaan: Medium
Biaya: Sedang
Pencadangan dan pemulihan
Pendekatan pemulihan bencana (DR) yang sederhana dan berbiaya rendah ini mencadangkan data dan aplikasi Anda dari mana saja ke landing zone DR untuk digunakan selama pemulihan dari bencana.
Arsitek AMS Cloud Anda bekerja dengan Anda sebagai bagian dari perencanaan Backup dan DR Anda.
Backup and Restore DR menggunakan perkakas dan proses otomatis AMS, seperti yang diilustrasikan dalam grafik berikut:
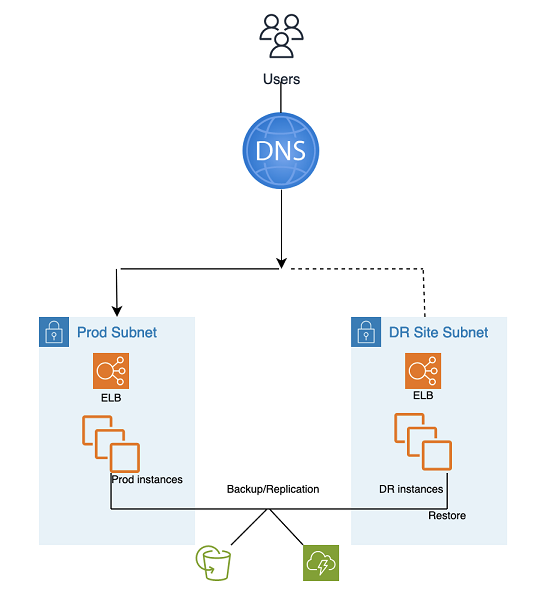
Dua metode pencadangan dan replikasi dapat digunakan:
Snapshot EBS (Recovery Point Objective (RPO) > 1 jam), dikenal sebagai “EBS”
AWS Elastic Disaster Recovery (Recovery Point Objective (RPO) ~ 0,25 jam), yang dikenal sebagai “DRS”
Situs DR bisa sama atau berbeda Wilayah AWS.
catatan
Region (Cross-Region) yang berbeda memiliki lingkungan Active Directory yang berbeda.
Langkah DR (failover):
Kembalikan instance dari snapshot (proses dua langkah dengan instance placeholder terlebih dahulu)
Perbarui konfigurasi aplikasi (IP baru, nama server, dan sebagainya)
Siapkan infrastruktur lain sesuai kebutuhan (SG, ELB, dan sebagainya)
Alihkan DNS ke situs DR (ELB)
Perbarui atau pulihkan dependensi AD jika diperlukan (akun layanan, nama utama layanan (SPN), objek kebijakan grup (GPO), dan sebagainya)
Backup dan Restore metrik DR:
Tujuan Titik Pemulihan (RPO): > 1 jam atau ~ 0,25 jam (tergantung pada solusi yang dipilih - EBS atau DRE)
Tujuan Waktu Pemulihan dan (RTO): ~ 1 jam (tergantung pada jumlah instance dan orkestrasi)
Pemeliharaan: Tinggi (Perubahan sinkron diperlukan di kedua lingkungan, seperti konfigurasi aplikasi, tambalan, grup keamanan atau penyeimbang beban aplikasi, sertifikat, dan sebagainya.
Biaya: Sedang
Perlindungan bencana untuk EC2 dengan snapshot EBS di AMS
Prasyarat:
Zona Pendaratan AMS Prod (sumber)
Zona Pendaratan AMS DR (target DR)
Snapshot EBS diaktifkan untuk instans EC2 ()AWS Backup
Solusi replikasi snapshot:
Cross AZ: Tidak berlaku - Snapshot EBS sangat tersedia di Wilayah berdasarkan desain
Cross-Region: AWS Backup
Diagram berikut mewakili proses pemulihan EC2 dari snapshot EBS di AMS:
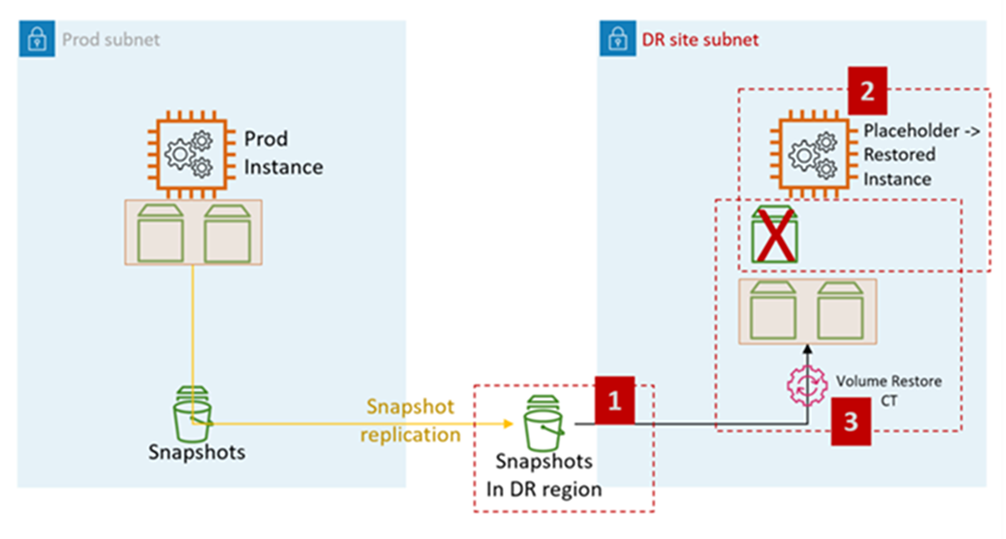
Langkah EC2 DR pada AMS:
Naikkan RFC untuk membagikan snapshot EBS dengan akun target (diperlukan untuk Cross-Region DR).
: Manajemen, Komponen Stack Tingkat Lanjut, Snapshot EBS, Bagikan
Buat tumpukan EC2 AMS placeholder di subnet tujuan (subnet situs DR). Rekomendasinya adalah menggunakan konsumsi CFN untuk membuat tumpukan karena pelanggan dapat menggabungkan langkah-langkah penetapan grup keamanan dan lainnya (seperti menambahkan instance ke ELB) di tumpukan yang sama.
Ubah jenis: Deployment, Ingestion, Stack from Template, Create CloudFormation
Naikkan RFC untuk melakukan pemulihan volume tumpukan EC2.
Ubah jenis: Manajemen, Komponen Tumpukan Tingkat Lanjut, tumpukan instans EC2, Kembalikan volume.
CT mengembalikan volume dari snapshot yang dibagikan di langkah 1 dan menempel pada instance placeholder yang dibuat pada langkah 2.
Fungsi Volume Restore CT:
Matikan instance placeholder
Kembalikan volume dari snapshot
Tukar volume
Mulai instance
Tinggalkan domain lama
Mengubah nama host
Nyalakan ulang. Skrip bootstrap AMS bergabung dengan instance ke domain target (DR) saat memulai
Volume mengembalikan input CT:
InstanceId (ID contoh placeholder)
RootDeviceSnapshotId, snapshot EBS untuk volume root yang dipulihkan
KMSKeyId, pengidentifikasi kunci KMS, atau ARN, untuk mengenkripsi semua volume yang dipulihkan pada instans EC2
DeviceNames, hingga 25 (opsional)
SnapshotIds, hingga 25 (opsional). Daftar snapshot dari volume yang akan dipulihkan
Perlindungan Bencana untuk EC2 dengan Elastic Disaster Recovery di AMS
Prasyarat:
Zona Pendaratan AMS Prod (sumber)
Zona Pendaratan AMS DR (target DR)
Anda harus terlebih dahulu menginisialisasi layanan Elastic Disaster Recovery untuk semua Wilayah AWS yang Anda rencanakan untuk menggunakannya.
Buat peran IAM di DR landing zone (LZ) Anda untuk akses konsol Elastic Disaster Recovery.
Penting: Dokumen SSM dibuat sebagai Post Launch Action dalam DRS. Tindakan ini harus diaktifkan di semua server Anda pada PostLaunch pengaturan.
instance tujuan (placeholder) harus memiliki kunci tag: “AWSDRS”, value: "”. AllowLaunchingIntoThisInstance Instans placeholder harus dalam keadaan berhenti. Jika tidak, AMS tidak dapat memilih instance placeholder di bawah pengaturan peluncuran dan Elastic Disaster Recovery tidak dapat memulihkan di atas instance placeholder.
Untuk diagram proses penyiapan dan pemulihan Elastic Disaster Recovery untuk EC2 di AMS, lihat arsitektur umum AWS Elastic Disaster Recovery (AWS DRS).
Langkah-langkah EC2 DR dengan Pemulihan Bencana Elastis di AMS:
Buat tumpukan EC2 AMS placeholder di subnet tujuan (subnet situs DR) dengan tag yang tepat, untuk informasi lebih lanjut, lihat bagian sebelumnya. Sebaiknya gunakan konsumsi CFN untuk membuat tumpukan karena Anda dapat menggabungkan langkah-langkah penetapan grup keamanan dan menandai instance, volume EBS, dan lainnya (seperti menambahkan instance ke ELB) di tumpukan yang sama.
Ubah jenis: Deployment, Ingestion, Stack from Template, Create CloudFormation
Hentikan instance placeholder.
Ubah jenis: Manajemen, Komponen tumpukan lanjutan, instans EC2, Berhenti
Jika tidak dilakukan pada langkah 1, beri tag instance placeholder dan volume EBS-nya dengan kunci: “AWSDRS”, value: "”. AllowLaunchingIntoThisInstance
Ubah jenis: Manajemen, Komponen tumpukan lanjutan, Tag, Perbarui.
Gunakan instance placeholder dari langkah 1 sebagai target di bawah Launch into instance ID, DRS Launch Settings untuk server sumber. Memulai latihan pemulihan instans dari konsol Elastic Disaster Recovery untuk Source Server.
catatan
Volume instance placeholder disimpan di akun. Untuk menghapus volume ini, kirimkan Manajemen | Komponen tumpukan lanjutan | Volume EBS | Hapus jenis perubahan (ct-3e3h8u0sp5z80) di akhir operasi pemulihan bencana.
Elastic Disaster Recovery memulihkan alur kerja:
Instance target (placeholder) harus dalam status berhenti
Tukar volume dan hapus volume root sumber (placeholder)
Mulai instance
Jalankan Tindakan Peluncuran Pos untuk menyelesaikan item berikut:
Aktifkan Agen SSM.
Tukar volume dan hapus volume root sumber (placeholder).
Mulai instance
Jalankan Dokumen PostLaunchScript SSM. Dokumen ini melakukan berikut:
Meninggalkan domain lama.
Mengubah nama host.
Nyalakan ulang. Skrip bootstrap AMS bergabung dengan instance ke domain target (DR) selama startup.
