Kami tidak lagi memperbarui layanan Amazon Machine Learning atau menerima pengguna baru untuk itu. Dokumentasi ini tersedia untuk pengguna yang sudah ada, tetapi kami tidak lagi memperbaruinya. Untuk informasi selengkapnya, lihat Apa itu Amazon Machine Learning.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Langkah 2: Buat Sumber Data Pelatihan
Setelah mengunggah banking.csv kumpulan data ke lokasi Amazon Simple Storage Service (Amazon S3), Anda menggunakannya untuk membuat sumber data pelatihan. Sumber data adalah objek Amazon Machine Learning (Amazon ML) yang berisi lokasi data input dan metadata penting tentang data input Anda. Amazon ML menggunakan sumber data untuk operasi seperti pelatihan dan evaluasi model ML.
Untuk membuat sumber data, berikan yang berikut ini:
-
Lokasi Amazon S3 dari data Anda dan izin untuk mengakses data
-
Skema, yang mencakup nama-nama atribut dalam data dan jenis setiap atribut (Numerik, Teks, Kategori, atau Biner)
-
Nama atribut yang berisi jawaban yang Anda ingin Amazon ML pelajari untuk memprediksi, atribut target
catatan
Sumber data tidak benar-benar menyimpan data Anda, itu hanya mereferensikannya. Hindari memindahkan atau mengubah file yang disimpan di Amazon S3. Jika Anda memindahkan atau mengubahnya, Amazon ML tidak dapat mengaksesnya untuk membuat model ML, menghasilkan evaluasi, atau menghasilkan prediksi.
Untuk membuat sumber data pelatihan
Buka konsol Amazon Machine Learning di https://console.aws.amazon.com/machinelearning/
. -
Pilih Mulai.
catatan
Tutorial ini mengasumsikan bahwa ini adalah pertama kalinya Anda menggunakan Amazon ML. Jika Anda pernah menggunakan Amazon ML sebelumnya, Anda dapat menggunakan Create new... daftar drop-down di dasbor Amazon Amazon untuk membuat sumber data baru.
-
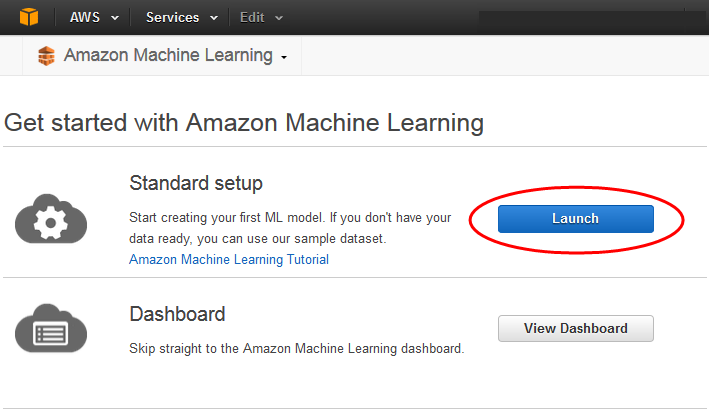
Pada halaman Memulai Amazon Machine Learning, pilih Luncurkan.
-
Pada halaman Input Data, untuk Di mana data Anda berada? , pastikan bahwa S3 dipilih.

-
Untuk Lokasi S3, ketik lokasi lengkap
banking.csvfile dari Langkah 1: Siapkan Data Anda. Sebagai contoh:your-bucket/banking.csv. Amazon MLmenambahkan s3://ke nama bucket Anda untuk Anda. -
Untuk nama Datasource, ketik.
Banking Data 1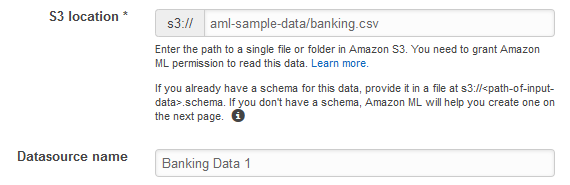
-
Pilih Verifikasi.
-
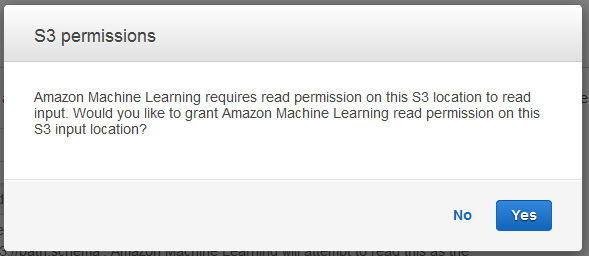
Di kotak dialog izin S3, pilih Ya.
-
Jika Amazon ML dapat mengakses dan membaca file data di lokasi S3, Anda akan melihat halaman yang mirip dengan berikut ini. Tinjau properti, lalu pilih Lanjutkan.

Selanjutnya, Anda membuat skema. Skema adalah informasi yang dibutuhkan Amazon untuk menafsirkan data input untuk model ML, termasuk nama atribut dan tipe data yang ditetapkan, dan nama atribut khusus. Ada dua cara untuk menyediakan Amazon ML dengan skema:
-
Berikan file skema terpisah saat Anda mengunggah data Amazon S3 Anda.
-
Izinkan Amazon ML menyimpulkan jenis atribut dan membuat skema untuk Anda.
Dalam tutorial ini, kita akan meminta Amazon ML untuk menyimpulkan skema.
Untuk informasi tentang membuat file skema terpisah, lihatMembuat Skema Data untuk Amazon ML.
Untuk memungkinkan Amazon ML menyimpulkan skema
-
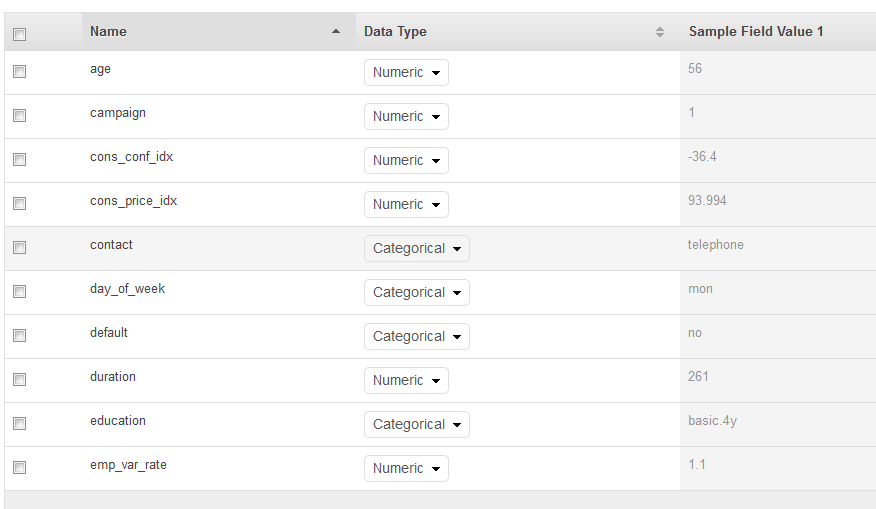
Pada halaman Skema, Amazon ML menunjukkan skema yang disimpulkan. Tinjau tipe data yang disimpulkan Amazon ML untuk atribut. Penting bahwa atribut diberikan tipe data yang benar untuk membantu Amazon ML menyerap data dengan benar dan untuk mengaktifkan pemrosesan fitur yang benar pada atribut.
-
Atribut yang hanya memiliki dua kemungkinan status, seperti ya atau tidak, harus ditandai sebagai Biner.
-
Atribut yang merupakan angka atau string yang digunakan untuk menunjukkan kategori harus ditandai sebagai Kategoris.
-
Atribut yang merupakan besaran numerik yang urutannya bermakna harus ditandai sebagai Numerik.
-
Atribut yang merupakan string yang ingin Anda perlakukan sebagai kata yang dibatasi oleh spasi harus ditandai sebagai Teks.
-
-
Dalam tutorial ini, Amazon ML telah mengidentifikasi tipe data untuk semua atribut dengan benar, jadi pilih Lanjutkan.
Selanjutnya, pilih atribut target.
Ingat bahwa targetnya adalah atribut yang harus dipelajari model ML untuk diprediksi. Atribut y menunjukkan apakah seseorang telah berlangganan kampanye di masa lalu: 1 (ya) atau 0 (tidak).
catatan
Pilih atribut target hanya jika Anda akan menggunakan sumber data untuk melatih dan mengevaluasi model ML.
Untuk memilih y sebagai atribut target
-
Di kanan bawah tabel, pilih panah tunggal untuk maju ke halaman terakhir tabel, di mana atribut bernama
ymuncul.
-
Di kolom Target, pilih
y.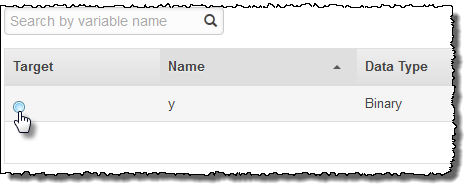
Amazon ML mengonfirmasi bahwa y dipilih sebagai target Anda.
-
Pilih Lanjutkan.
-
Pada halaman ID Baris, untuk Apakah data Anda berisi pengenal? , pastikan bahwa Tidak, default, dipilih.
-
Pilih Tinjau, lalu pilih Lanjutkan.
Sekarang setelah Anda memiliki sumber data pelatihan, Anda siap untuk membuat model Anda.
