Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Migrating AWS Glue untuk pekerjaan Spark untuk AWS Glue versi 5.0
Topik ini menjelaskan perubahan antara AWS Glue versi 0.9, 1.0, 2.0, 3.0, dan 4.0 untuk memungkinkan Anda memigrasikan aplikasi Spark dan pekerjaan ETL ke 5.0. AWS Glue Ini juga menjelaskan fitur di AWS Glue 5.0 dan keuntungan menggunakannya.
Untuk menggunakan fitur ini dengan pekerjaan AWS Glue ETL Anda, pilih 5.0 Glue version saat membuat pekerjaan Anda.
Topik
Fitur baru
Bagian ini menjelaskan fitur dan keunggulan baru AWS Glue versi 5.0.
-
Pembaruan Apache Spark dari 3.3.0 di AWS Glue 4.0 ke 3.5.4 di 5.0. AWS Glue Lihat Peningkatan utama dari Spark 3.3.0 ke Spark 3.5.4.
-
Spark-native kontrol akses berbutir halus (FGAC) menggunakan Lake Formation. Ini termasuk FGAC untuk tabel Iceberg, Delta dan Hudi. Untuk informasi selengkapnya, lihat Menggunakan AWS Glue dengan AWS Lake Formation untuk kontrol akses berbutir halus.
Perhatikan pertimbangan atau batasan berikut untuk Spark-native FGAC:
Saat ini penulisan data tidak didukung
Menulis ke Gunung Es melalui
GlueContextpenggunaan Lake Formation membutuhkan penggunaan kontrol akses IAM sebagai gantinya
Untuk daftar lengkap batasan dan pertimbangan saat menggunakan Spark-native FGAC, lihat. Pertimbangan dan batasan
-
Support untuk Amazon S3 Access Grants sebagai solusi kontrol akses yang dapat diskalakan untuk data Amazon S3 Anda. AWS Glue Untuk informasi selengkapnya, lihat Menggunakan Hibah Akses Amazon S3 dengan AWS Glue.
-
Format Tabel Terbuka (OTF) diperbarui ke Hudi 0.15.0, Iceberg 1.7.1, dan Delta Lake 3.3.0
-
Dukungan Amazon SageMaker Unified Studio.
-
Amazon SageMaker Lakehouse dan integrasi abstraksi data. Untuk informasi selengkapnya, lihat Menanyakan katalog data metastore dari AWS Glue ETL.
-
Support untuk menginstal pustaka Python tambahan menggunakan.
requirements.txtUntuk informasi selengkapnya, lihat Menginstal pustaka Python tambahan di AWS Glue 5.0 atau lebih tinggi menggunakan requirements.txt. -
AWS Glue 5.0 mendukung garis keturunan data di Amazon. DataZone Anda dapat mengonfigurasi AWS Glue untuk mengumpulkan informasi silsilah secara otomatis selama pekerjaan Spark berjalan dan mengirim peristiwa silsilah untuk divisualisasikan di Amazon. DataZone Untuk informasi selengkapnya, lihat Silsilah data di Amazon. DataZone
Untuk mengonfigurasinya di AWS Glue konsol, aktifkan Hasilkan peristiwa silsilah, dan masukkan ID DataZone domain Amazon Anda di tab Detail pekerjaan.
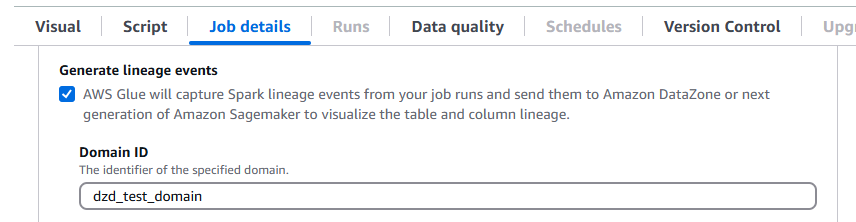
Atau, Anda dapat memberikan parameter pekerjaan berikut (berikan ID DataZone domain Anda):
Kunci:
--confNilai:
extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener —conf spark.openlineage.transport.type=amazon_datazone_api -conf spark.openlineage.transport.domainId=<your-domain-ID>
-
Pembaruan driver konektor dan JDBC. Untuk informasi selengkapnya, lihat Lampiran B: Peningkatan driver JDBC dan Lampiran C: Peningkatan konektor.
-
Pembaruan Java dari 8 hingga 17.
-
Peningkatan penyimpanan untuk AWS Glue
G.1XdanG.2Xpekerja dengan ruang disk meningkat menjadi 94GB dan 138GB masing-masing. Selain itu, jenis pekerja baruG.12X,G.16X, dan dioptimalkan memoriR.1X,R.2XR.4X,R.8Xtersedia dalam AWS Glue versi 4.0 dan yang lebih baru. Untuk informasi selengkapnya, lihat Lowongan Support untuk AWS SDK for Java, versi 2 AWS Glue - 5.0 pekerjaan dapat menggunakan untuk Java versi
1.12.569 atau 2.28.8 jika pekerjaan mendukung v2. AWS SDK for Java 2.x adalah penulisan ulang utama dari basis kode versi 1.x. Ini dibangun di atas Java 8+ dan menambahkan beberapa fitur yang sering diminta. Ini termasuk dukungan untuk non-pemblokiran I/O, dan kemampuan untuk menyambungkan implementasi HTTP yang berbeda saat runtime. Untuk informasi selengkapnya, termasuk Panduan Migrasi dari SDK for Java v1 ke v2, lihat AWS panduan SDK for Java, versi 2.
Melanggar perubahan
Perhatikan perubahan yang melanggar berikut:
-
Di AWS Glue 5.0, saat menggunakan sistem file S3A dan jika `fs.s3a.endpoint` dan `fs.s3a.endpoint.region` tidak disetel, wilayah default yang digunakan oleh S3A adalah `us-east-2`. Hal ini dapat menyebabkan masalah, seperti kesalahan batas waktu unggah S3, terutama untuk pekerjaan VPC. Untuk mengurangi masalah yang disebabkan oleh perubahan ini, setel konfigurasi Spark `fs.s3a.endpoint.region` saat menggunakan sistem file S3A di 5.0. AWS Glue
-
Kontrol Fine-grained Akses Lake Formation (FGAC)
-
AWS Glue 5.0 hanya mendukung Spark-native FGAC baru menggunakan Spark. DataFrames Itu tidak mendukung penggunaan FGAC. AWS Glue DynamicFrames
-
Penggunaan FGAC di 5.0 membutuhkan migrasi dari ke Spark AWS Glue DynamicFrames DataFrames
-
Jika Anda tidak memerlukan FGAC, maka tidak perlu bermigrasi ke Spark DataFrame dan GlueContext fitur, seperti bookmark pekerjaan dan predikat push down, akan terus berfungsi.
-
-
Pekerjaan dengan Spark-native FGAC membutuhkan minimal 4 pekerja: satu driver pengguna, satu driver sistem, satu eksekutor sistem, dan satu eksekutor pengguna siaga.
-
Untuk informasi selengkapnya, lihat Menggunakan AWS Glue dengan AWS Lake Formation untuk kontrol akses berbutir halus.
-
-
Akses Meja Lengkap Lake Formation (FTA)
-
AWS Glue 5.0 mendukung FTA dengan Spark-native DataFrames (baru) dan GlueContext DynamicFrames (warisan, dengan batasan)
-
Spark-native FTA
-
Jika skrip 4.0 digunakan GlueContext, migrasi ke menggunakan spark asli.
-
Fitur ini terbatas pada tabel sarang dan gunung es
-
Untuk informasi selengkapnya tentang mengonfigurasi pekerjaan 5.0 untuk menggunakan Spark native FTA, lihat. Native Spark FTA di 5.0 AWS Glue
-
-
GlueContext DynamicFrame FTA
-
Tidak ada perubahan kode yang diperlukan
-
Fitur ini terbatas pada tabel non-OTF - tidak akan berfungsi dengan Iceberg, Delta Lake, dan Hudi.
-
-
Pembaca SIMD CSV vektor tidak didukung.
Pencatatan terus menerus ke grup log keluaran tidak didukung. Gunakan grup
errorlog sebagai gantinya.Wawasan AWS Glue pekerjaan yang dijalankan
job-insights-rule-driversudah tidak digunakan lagi. Aliranjob-insights-rca-driverlog sekarang terletak di grup log kesalahan.Athena-based custom/marketplace konektor tidak didukung.
Adobe Marketo Engage, Iklan Facebook, Google Ads, Google Analytics 4, Google Sheets, Hubspot, Iklan Instagram, Interkom, Jira Cloud, Oracle, Salesforce, Salesforce Marketing Cloud NetSuite, Keterlibatan Akun Cloud Pemasaran Salesforce, SAP OData,, Slack, Iklan Snapchat, Stripe, Zendesk dan Zoho CRM ServiceNow konektor tidak didukung.
Properti log4j kustom tidak didukung di AWS Glue 5.0.
Peningkatan utama dari Spark 3.3.0 ke Spark 3.5.4
Perhatikan penyempurnaan berikut:
-
Klien Python untuk Spark Connect SPARK-39375
(). -
Menerapkan dukungan untuk nilai DEFAULT untuk kolom dalam tabel (SPARK-38334
). -
Dukungan “Referensi Alias Kolom Lateral” (SPARK-27561
). -
Harden penggunaan SQLSTATE untuk kelas kesalahan (). SPARK-41994
-
Aktifkan filter Bloom Bergabung secara default (SPARK-38841
). -
Skalabilitas Spark UI yang lebih baik dan stabilitas driver untuk aplikasi besar () SPARK-41053
. -
Pelacakan Kemajuan Async di Streaming Terstruktur () SPARK-39591
. -
Pemrosesan stateful arbitrer Python dalam streaming terstruktur (). SPARK-40434
-
Peningkatan cakupan API Pandas (SPARK-42882
) dan dukungan NumPy input di PySpark (SPARK-39405 ). -
Menyediakan profiler memori untuk fungsi yang PySpark ditentukan pengguna (). SPARK-40281
-
Melaksanakan PyTorch distributor (SPARK-41589
). -
Publikasikan artefak SBOM () SPARK-41893
. -
Support IPv6-only environment (SPARK-39457
). -
Penjadwal K8s yang disesuaikan (Apache YuniKorn dan Volcano) GA (). SPARK-42802
-
Dukungan klien Scala dan Go di Spark Connect (SPARK-42554
) dan (SPARK-43351 ). -
PyTorch-based Dukungan ML terdistribusi untuk Spark Connect (SPARK-42471
). -
Dukungan streaming terstruktur untuk Spark Connect dengan Python dan SPARK-42938
Scala (). -
Dukungan API Pandas untuk Python Spark Connect Client (). SPARK-42497
-
Perkenalkan Arrow Python UDFs (). SPARK-40307
-
Mendukung fungsi tabel yang ditentukan pengguna Python (). SPARK-43798
-
Migrasikan PySpark kesalahan ke kelas kesalahan (SPARK-42986
). -
PySpark kerangka uji (SPARK-44042
). -
Tambahkan dukungan untuk Datasketches HllSketch (). SPARK-16484
-
Built-in Peningkatan fungsi SQL (SPARK-41231
). -
Klausul IDENTIFIER () SPARK-43205
. -
Tambahkan fungsi SQL ke dalam Scala, Python dan R API (). SPARK-43907
-
Tambahkan dukungan argumen bernama untuk fungsi SQL (SPARK-43922
). -
Hindari tugas yang tidak perlu dijalankan kembali pada eksekutor yang dinonaktifkan hilang jika data acak bermigrasi (). SPARK-41469
-
ML terdistribusi <> spark connect () SPARK-42471
. -
DeepSpeed distributor (SPARK-44264
). -
Menerapkan checkpointing changelog untuk RocksDB state store (). SPARK-43421
-
Perkenalkan propagasi tanda air di antara operator () SPARK-42376
. -
Perkenalkan drop DuplicatesWithinWatermark (SPARK-42931
). -
Peningkatan manajemen memori penyedia penyimpanan status RocksDB (). SPARK-43311
Tindakan untuk bermigrasi ke AWS Glue 5.0
Untuk pekerjaan yang ada, ubah Glue version dari versi sebelumnya ke Glue 5.0 dalam konfigurasi pekerjaan.
-
Di AWS Glue Studio, pilih
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3diGlue version. -
Di API, pilih
GlueVersionparameter5.0dalam operasiUpdateJobAPI.
Untuk pekerjaan baru, pilih Glue 5.0 kapan Anda membuat pekerjaan.
-
Di konsol, pilih
Spark 3.5.4, Python 3 (Glue Version 5.0) or Spark 3.5.4, Scala 2 (Glue Version 5.0)diGlue version. -
Di AWS Glue Studio, pilih
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3diGlue version. -
Di API, pilih
GlueVersionparameter5.0dalam operasiCreateJobAPI.
Untuk melihat log peristiwa Spark AWS Glue 5.0 yang berasal dari AWS Glue 2.0 atau sebelumnya, luncurkan server riwayat Spark yang ditingkatkan untuk AWS Glue 5.0 menggunakan CloudFormation atau Docker.
Daftar periksa migrasi
Tinjau daftar periksa ini untuk migrasi:
-
Pembaruan Java 17
-
[Scala] Tingkatkan panggilan AWS SDK dari v1 ke v2
-
Migrasi Python 3.10 hingga 3.11
-
[Python] Perbarui referensi boto dari 1,26 ke 1,34
AWS Glue 5.0 fitur
Bagian ini menjelaskan AWS Glue fitur secara lebih rinci.
Menanyakan katalog data metastore dari AWS Glue ETL
Anda dapat mendaftarkan AWS Glue pekerjaan Anda untuk mengakses AWS Glue Data Catalog, yang membuat tabel dan sumber daya metastore lainnya tersedia untuk konsumen yang berbeda. Katalog Data mendukung hierarki multi-katalog, yang menyatukan semua data Anda di seluruh danau data Amazon S3. Ini juga menyediakan API metastore Hive dan API Apache Iceberg sumber terbuka untuk mengakses data. Fitur-fitur ini tersedia untuk AWS Glue dan layanan berorientasi data lainnya seperti Amazon EMR, Amazon Athena, dan Amazon Redshift.
Saat Anda membuat sumber daya di Katalog Data, Anda dapat mengaksesnya dari mesin SQL apa pun yang mendukung Apache Iceberg REST API. AWS Lake Formation mengelola izin. Setelah konfigurasi, Anda dapat memanfaatkan AWS Glue kemampuan untuk menanyakan data yang berbeda dengan menanyakan sumber daya metastore ini dengan aplikasi yang sudah dikenal. Ini termasuk Apache Spark dan Trino.
Bagaimana sumber daya metadata diatur
Data diatur dalam hierarki logis katalog, database, dan tabel, menggunakan: AWS Glue Data Catalog
Katalog — Wadah logis yang menyimpan objek dari penyimpanan data, seperti skema atau tabel.
Database - Mengatur objek data seperti tabel dan tampilan dalam katalog.
Tabel dan tampilan — Objek data dalam database yang menyediakan lapisan abstraksi dengan skema yang dapat dimengerti. Mereka memudahkan untuk mengakses data yang mendasarinya, yang bisa dalam berbagai format dan di berbagai lokasi.
Migrasi dari AWS Glue 4.0 ke AWS Glue 5.0
Semua parameter pekerjaan yang ada dan fitur utama yang ada di AWS Glue 4.0 akan ada di AWS Glue 5.0, kecuali transformasi pembelajaran mesin.
Parameter baru berikut ditambahkan:
-
--enable-lakeformation-fine-grained-access: Mengaktifkan fitur kontrol akses berbutir halus (FGAC) di tabel Lake Formation. AWS
Lihat dokumentasi migrasi Spark:
Migrasi dari AWS Glue 3.0 ke AWS Glue 5.0
catatan
Untuk langkah-langkah migrasi yang terkait dengan AWS Glue 4.0, lihatMigrasi dari AWS Glue 3.0 ke AWS Glue 4.0.
Semua parameter pekerjaan yang ada dan fitur utama yang ada di AWS Glue 3.0 akan ada di AWS Glue 5.0, kecuali transformasi pembelajaran mesin.
Migrasi dari AWS Glue 2.0 ke AWS Glue 5.0
catatan
Untuk langkah-langkah migrasi yang terkait dengan AWS Glue 4.0 dan daftar perbedaan migrasi antara AWS Glue versi 3.0 dan 4.0, lihatMigrasi dari AWS Glue 3.0 ke AWS Glue 4.0.
Perhatikan juga perbedaan migrasi berikut antara AWS Glue versi 3.0 dan 2.0:
Semua parameter pekerjaan yang ada dan fitur utama yang ada di AWS Glue 2.0 akan ada di AWS Glue 5.0, kecuali transformasi pembelajaran mesin.
Beberapa perubahan Spark saja mungkin memerlukan revisi skrip Anda untuk memastikan fitur yang dihapus tidak direferensikan. Misalnya, Spark 3.1.1 dan yang lebih baru tidak mengaktifkan Scala-untyped UDF tetapi Spark 2.4 mengizinkannya.
Python 2.7 tidak didukung.
Setiap stoples tambahan yang disediakan dalam pekerjaan AWS Glue 2.0 yang ada dapat membawa dependensi yang bertentangan karena ada peningkatan di beberapa dependensi. Anda dapat menghindari konflik classpath dengan parameter
--user-jars-firstpekerjaan.Perubahan perilaku stempel waktu file from/to parket. loading/saving Untuk detail selengkapnya, lihat Upgrade dari Spark SQL 3.0 ke 3.1.
Paralelisme tugas Spark yang berbeda untuk konfigurasi. driver/executor Anda dapat menyesuaikan paralelisme tugas dengan meneruskan argumen
--executor-corespekerjaan.
Perubahan perilaku logging di AWS Glue 5.0
Berikut ini adalah perubahan perilaku logging di AWS Glue 5.0. Untuk informasi selengkapnya, lihat Logging untuk AWS Glue lowongan kerja.
-
Semua log (log sistem, log daemon Spark, log pengguna, dan log Glue Logger) sekarang ditulis ke grup
/aws-glue/jobs/errorlog secara default. -
Grup
/aws-glue/jobs/logs-v2log yang digunakan untuk pencatatan berkelanjutan di versi sebelumnya tidak lagi digunakan. -
Anda tidak dapat lagi mengganti nama atau menyesuaikan grup log atau nama aliran log menggunakan argumen logging berkelanjutan yang dihapus. Sebagai gantinya, lihat argumen pekerjaan baru di AWS Glue 5.0.
Dua argumen pekerjaan baru diperkenalkan di AWS Glue 5.0
-
––custom-logGroup-prefix: Memungkinkan Anda menentukan awalan khusus untuk grup/aws-glue/jobs/errordan/aws-glue/jobs/outputlog. -
––custom-logStream-prefix: Memungkinkan Anda menentukan awalan khusus untuk nama aliran log dalam grup log.Aturan validasi dan batasan untuk awalan kustom meliputi:
-
Seluruh nama log stream harus antara 1 dan 512 karakter.
-
Awalan khusus untuk nama aliran log dibatasi hingga 400 karakter.
-
Karakter yang diizinkan dalam awalan termasuk karakter alfanumerik, garis bawah (`_`), tanda hubung (`-`), dan garis miring maju (`/`).
-
Argumen logging berkelanjutan yang tidak digunakan lagi di AWS Glue 5.0
Argumen pekerjaan berikut untuk logging berkelanjutan telah tidak digunakan lagi di 5.0 AWS Glue
-
––enable-continuous-cloudwatch-log -
––continuous-log-logGroup -
––continuous-log-logStreamPrefix -
––continuous-log-conversionPattern -
––enable-continuous-log-filter
Konektor dan migrasi driver JDBC untuk AWS Glue 5.0
Untuk versi JDBC dan konektor data lake yang ditingkatkan, lihat:
Perubahan berikut berlaku untuk versi konektor atau driver yang diidentifikasi dalam lampiran untuk Glue 5.0.
Amazon Redshift
Perhatikan perubahan berikut:
Menambahkan dukungan untuk nama tabel tiga bagian untuk memungkinkan konektor menanyakan tabel berbagi data Redshift.
Mengoreksi pemetaan Spark
ShortTypeuntuk menggunakan RedshiftSMALLINTalih-alih lebih cocok dengan ukuran data yangINTEGERdiharapkan.Menambahkan dukungan untuk Nama Cluster Kustom (CNAME) untuk Amazon Redshift Tanpa Server.
Apache Hudi
Perhatikan perubahan berikut:
Support indeks tingkat catatan.
Support auto generasi kunci rekam. Sekarang Anda tidak perlu menentukan bidang kunci rekam.
Gunung Es Apache
Perhatikan perubahan berikut:
Support kontrol akses berbutir halus dengan. AWS Lake Formation
Support percabangan dan penandaan yang diberi nama referensi ke snapshot dengan siklus hidup independennya sendiri.
Menambahkan prosedur tampilan changelog yang menghasilkan tampilan yang berisi perubahan yang dibuat pada tabel selama periode tertentu atau di antara snapshot tertentu.
Danau Delta
Perhatikan perubahan berikut:
Support Delta Universal Format (UniForm) yang memungkinkan akses tanpa batas melalui Apache Iceberg dan Apache Hudi.
Support Deletion Vectors yang mengimplementasikan paradigma. Merge-on-Read
AzureCosmos
Perhatikan perubahan berikut:
Menambahkan dukungan kunci partisi hierarkis.
Ditambahkan pilihan untuk menggunakan Skema kustom dengan StringType (json mentah) untuk properti bersarang.
Menambahkan opsi konfigurasi
spark.cosmos.auth.aad.clientCertPemBase64untuk memungkinkan menggunakan otentikasi SPN (ServicePrincipal nama) dengan sertifikat alih-alih rahasia klien.
Untuk informasi selengkapnya, lihat log perubahan konektor Azure Cosmos DB Spark
Microsoft SQL Server
Perhatikan perubahan berikut:
Enkripsi TLS diaktifkan secara default.
Ketika enkripsi = false tetapi server memerlukan enkripsi, sertifikat divalidasi berdasarkan pengaturan
trustServerCertificatekoneksi.aadSecurePrincipalIddanaadSecurePrincipalSecretusang.getAADSecretPrincipalIdAPI dihapus.Ditambahkan resolusi CNAME ketika ranah ditentukan.
MongoDB
Perhatikan perubahan berikut:
Support untuk mode micro-batch dengan Spark Structured Streaming.
Support untuk tipe data BSON.
Ditambahkan dukungan untuk membaca beberapa koleksi saat menggunakan micro-batch atau mode streaming kontinu.
Jika nama koleksi yang digunakan dalam opsi
collectionkonfigurasi Anda berisi koma, Konektor Spark memperlakukannya sebagai dua koleksi berbeda. Untuk menghindari hal ini, Anda harus melarikan diri dari koma dengan mendahuluinya dengan garis miring terbalik (\).Jika nama koleksi yang digunakan dalam opsi
collectionkonfigurasi Anda adalah “*”, Konektor Spark menafsirkannya sebagai spesifikasi untuk memindai semua koleksi. Untuk menghindari hal ini, Anda harus melarikan diri dari tanda bintang dengan mendahuluinya dengan garis miring terbalik (\).Jika nama koleksi yang digunakan dalam opsi
collectionkonfigurasi Anda berisi garis miring terbalik (\), Konektor Spark memperlakukan garis miring terbalik sebagai karakter escape, yang mungkin mengubah cara menafsirkan nilai. Untuk menghindari hal ini, Anda harus melarikan diri dari garis miring terbalik dengan mendahuluinya dengan garis miring terbalik lainnya.
Untuk informasi selengkapnya, lihat konektor MongoDB untuk catatan rilis
Kepingan salju
Perhatikan perubahan berikut:
Memperkenalkan
trim_spaceparameter baru yang dapat Anda gunakan untuk memangkas nilaiStringTypekolom secara otomatis saat menyimpan ke tabel Snowflake. Default:false.Menonaktifkan
abort_detached_queryparameter pada tingkat sesi secara default.Menghapus persyaratan
SFUSERparameter saat menggunakan OAUTH.Menghapus fitur Advanced Query Pushdown. Alternatif untuk fitur ini tersedia. Misalnya, alih-alih memuat data dari tabel Snowflake, pengguna dapat langsung memuat data dari kueri Snowflake SQL.
Untuk informasi lebih lanjut, lihat Konektor Kepingan Salju untuk catatan rilis Spark
Lampiran A: Peningkatan ketergantungan penting
Berikut ini adalah peningkatan ketergantungan:
| Dependensi | Versi dalam AWS Glue 5.0 | Versi dalam AWS Glue 4.0 | Versi dalam AWS Glue 3.0 | Versi dalam AWS Glue 2.0 | Versi dalam AWS Glue 1.0 |
|---|---|---|---|---|---|
| Java | 17 | 8 | 8 | 8 | 8 |
| Spark | 3.5.4 | 3.3.0-amzn-1 | 3.1.1-amzn-0 | 2.4.3 | 2.4.3 |
| Hadoop | 3.4.1 | 3.3.3-amzn-0 | 3.2.1-amzn-3 | 2.8.5-amzn-5 | 2.8.5-amzn-1 |
| Skala | 2.12.18 | 2.12 | 2.12 | 2.11 | 2.11 |
| Jackson | 2.15.2 | 2.12 | 2.12 | 2.11 | 2.11 |
| Hive | 2.3.9-amzn-4 | 2.3.9-amzn-2 | 2.3.7-amzn-4 | 1.2 | 1.2 |
| EMRFS | 2.69.0 | 2.54.0 | 2.46.0 | 2.38.0 | 2.30.0 |
| JSON4 | 3.7.0-M11 | 3.7.0-M11 | 3.6.6 | 3.5.x | 3.5.x |
| Panah | 12.0.1 | 7.0.0 | 2.0.0 | 0.10.0 | 0.10.0 |
| AWS Glue Klien Katalog Data | 4.5.0 | 3.7.0 | 3.0.0 | 1.10.0 | N/A |
| AWS SDK for Java | 2.29.52 | 1.12 | 1.12 | ||
| Python | 3.11 | 3.10 | 3.7 | 2.7 & 3.6 | 2.7 & 3.6 |
| Boto | 1.34.131 | 1.26 | 1.18 | 1.12 | N/A |
| Konektor EMR DynamoDB | 5.6.0 | 4.16.0 |
Lampiran B: Peningkatan driver JDBC
Berikut ini adalah upgrade driver JDBC:
| Driver | Versi driver JDBC di 5.0 AWS Glue | Versi driver JDBC di 4.0 AWS Glue | Versi driver JDBC di 3.0 AWS Glue | Versi driver JDBC di versi sebelumnya AWS Glue |
|---|---|---|---|---|
| MySQL | 8.0.33 | 8.0.23 | 8.0.23 | 5.1 |
| Microsoft SQL Server | 10.2.0 | 9.4.0 | 7.0.0 | 6.1.0 |
| Database Oracle | 23.3.0.23.09 | 21.7 | 21.1 | 11.2 |
| PostgreSQL | 42.7.3 | 42.3.6 | 42.2.18 | 42.1.0 |
| Amazon Redshift |
redshift-jdbc42-2.1.0.29 |
redshift-jdbc42-2.1.0.16 |
redshift-jdbc41-1.2.12.1017 |
redshift-jdbc41-1.2.12.1017 |
| SAP Hana | 2.20.17 | 2.17.12 | ||
| Teradata | 20.00.00.33 | 20.00.00.06 |
Lampiran C: Peningkatan konektor
Berikut ini adalah upgrade konektor:
| Driver | Versi konektor di AWS Glue 5.0 | Versi konektor di AWS Glue 4.0 | Versi konektor di AWS Glue 3.0 |
|---|---|---|---|
| Konektor EMR DynamoDB | 5.6.0 | 4.16.0 | |
| Amazon Redshift | 6.4.0 | 6.1.3 | |
| OpenSearch | 1.2.0 | 1.0.1 | |
| MongoDB | 10.3.0 | 10.0.4 | 3.0.0 |
| Kepingan salju | 3.0.0 | 2.12.0 | |
| Google BigQuery | 0.32.2 | 0.32.2 | |
| AzureCosmos | 4.33.0 | 4.22.0 | |
| AzureSQL | 1.3.0 | 1.3.0 | |
| Vertica | 3.3.5 | 3.3.5 |
Lampiran D: Buka peningkatan format tabel
Berikut ini adalah upgrade format tabel terbuka:
| OTF | Versi konektor di AWS Glue 5.0 | Versi konektor di AWS Glue 4.0 | Versi konektor di AWS Glue 3.0 |
|---|---|---|---|
| Hudi | 0.15.0 | 0.12.1 | 0.10.1 |
| Danau Delta | 3.3.0 | 2.1.0 | 1.0.0 |
| Gunung es | 1.7.1 | 1.0.0 | 0.13.1 |
